
Cursus
Développer des LLM
16 h
Phi-4-reasoning est un modèle ouvert de 14 milliards de paramètres conçu pour des tâches de raisonnement complexes, rivalisant avec des modèles beaucoup plus grands grâce à un ajustement méticuleux sur des ensembles de données. Il génère des chaînes de raisonnement détaillées et exploite le calcul de l'inférence pour atteindre des performances exceptionnelles.
Sa version améliorée, Phi-4-reasoning-plus, utilise l'apprentissage par renforcement et 1,5 fois plus de jetons pour une précision encore plus grande. Malgré leur taille réduite, les deux modèles sont plus performants que leurs homologues plus grands, comme DeepSeek-R1-Distill-70B, et dépassent même le paramètre de 671 milliards d'euros. DeepSeek-R1 à 671 milliards de paramètres.
Dans ce tutoriel, nous utiliserons le modèle Phi-4-reasoning-plus et l'ajusterons sur l'ensemble de données de raisonnement Q&R financier. Ce guide comprend la configuration de l'environnement Runpod, le chargement du modèle, du tokenizer et de l'ensemble de données, la préparation des données pour l'entraînement du modèle, la configuration du modèle pour l'entraînement, l'exécution des évaluations du modèle et l'enregistrement de l'adopteur du modèle affiné.
Vous pouvez vous familiariser avec Phi 4 et construire un tuteur linguistique multimodal en suivant le tutoriel, Phi-4-Multimodal : Un guide avec projet de démonstration.

Image par l'auteur
Dans ce tutoriel, nous utiliserons RunPod comme environnement de calcul. Suivez les étapes suivantes pour configurer votre environnement :
1. Allez dans le tableau de bord RunPod et cliquez sur "Deploy On-Demand" pour créer un nouveau pod.
2. Sélectionnez le GPU A100, qui est suffisant pour charger et affiner le modèle.
3. Personnalisez votre déploiement :
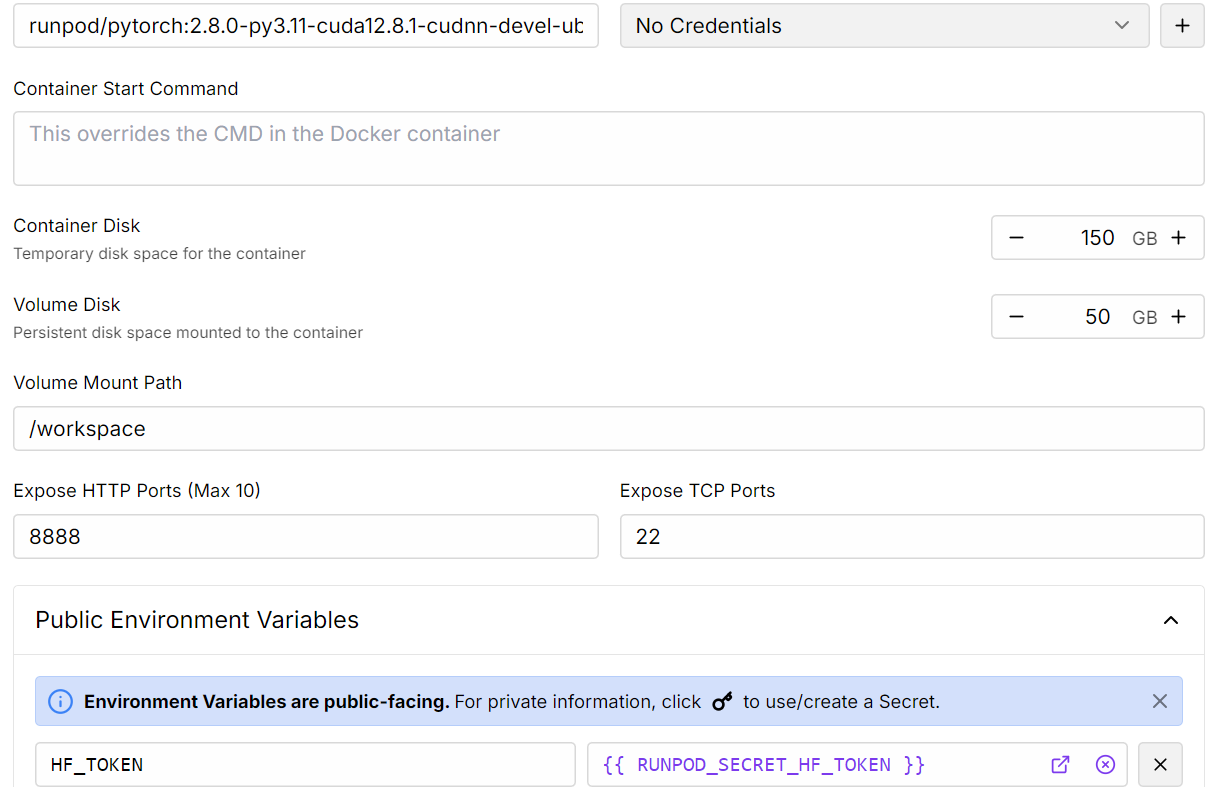
4. Une fois le pod déployé, cliquez sur le bouton Connect pour lancer l'instance de JupyterLab.
5. À l'intérieur de Python, créez un nouveau notebook et installez tous les paquets Python nécessaires.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]6. Ensuite, connectez-vous à la page Hugging Face à l'aide du jeton que vous avez enregistré précédemment.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Dans ce guide, nous chargerons la version complète de microsoft/Phi-4-reasoning-plus de Hugging Face, ainsi que son tokenizer.
Nous n'utilisons pas la quantification car le matériel peut aisément gérer des poids de pleine précision. Un A100 avec 80 Go de VRAM laisse une grande marge de manœuvre, car le modèle Phi-4-Reasoning complet n'occupe qu'environ 28 Go. Il reste donc plus de 50 Go pour les activations, les états de l'optimiseur et d'autres frais généraux d'entraînement.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "microsoft/Phi-4-reasoning-plus"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1
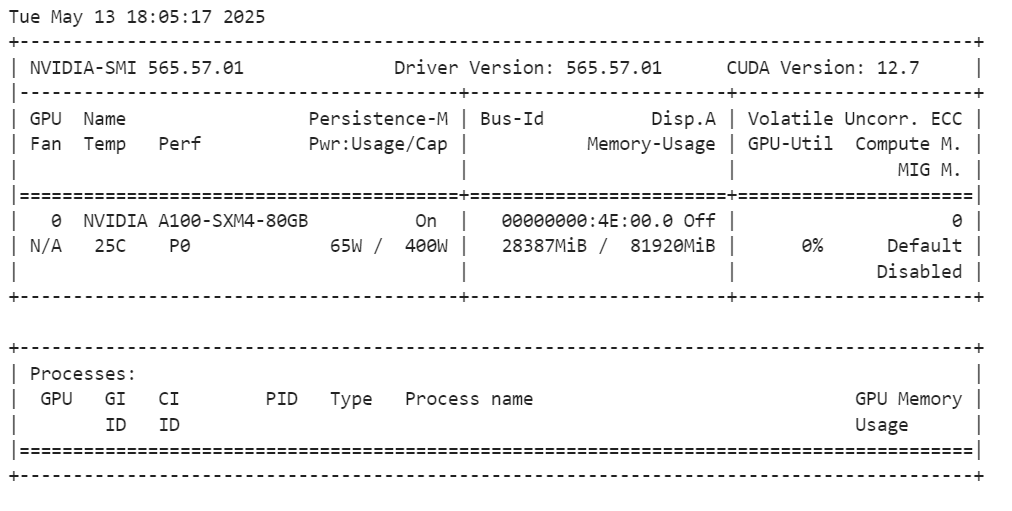
Après avoir chargé le modèle, vous pouvez vérifier la quantité de mémoire GPU qu'il consomme en exécutant la commande suivante :
!nvidia-smiLe modèle complet utilise environ 28 Go de VRAM. Le GPU A100 dispose de 80 Go de VRAM, ce qui vous laisse 55 Go de mémoire libre pour effectuer des réglages précis.
Avant de charger l'ensemble de données, nous allons définir un style d'invite de formation. Cet appel comprend :
Ce type d'invite est conçu pour encourager le modèle à penser de manière critique et à produire un processus de raisonnement en même temps que la réponse finale.
train_prompt_style="""
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
</think>
{}
"""Nous allons créer une fonction Python pour appliquer les colonnes de l'ensemble de données (questions, raisonnement et réponses) au modèle d'invite. Cette fonction génère une nouvelle colonne appelée "texte", qui comprend tous les composants de l'invite.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs,complex_cots,outputs):
text = train_prompt_style.format(input,cot,output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Nous allons maintenant télécharger l'ensemble de données (TheFinAI/Fino1_Reasoning_Path_FinQA), charger 1000 échantillons, appliquer la fonction de formatage et créer la nouvelle colonne "texte".
from datasets import load_dataset
dataset = load_dataset(
"TheFinAI/Fino1_Reasoning_Path_FinQA", split="train[0:1000]", trust_remote_code=True
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][20]La colonne "texte" de l'ensemble de données comprend les instructions du système, la question de l'utilisateur, une chaîne de raisonnement étape par étape et la réponse finale. Ce format structuré garantit que le modèle comprend la tâche et génère des réponses de haute qualité.

La nouvelle fonction d'entraînement STF n'accepte pas directement de tokenizer. Par conséquent, nous devons convertir le tokenizer en un collateur de données à l'aide de DataCollatorForLanguageModeling from Transformers.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Avant de procéder au réglage fin, nous exécuterons l'inférence sur une question de l'ensemble de données afin de comparer les performances du modèle après le réglage fin. Le style de l'invite de déduction est similaire au style de l'invite d'entraînement, mais exclut la partie raisonnement et la réponse.
inference_prompt_style = """
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
"""Nous sélectionnerons la 21e question de l'ensemble de données, la formaterons et la codifierons pour l'inférence :
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])Le modèle génère une longue partie de raisonnement mais ne fournit pas de réponse claire. L'augmentation de max_new_tokens à 2000 pourrait apporter une réponse, mais cette approche est inefficace et peu fiable. Le raisonnement est dispersé et la conclusion est inexacte.

Dans cette section, nous allons mettre en œuvre LoRA (Low-Rank Adaptation)une technique de réglage fin efficace en termes de paramètres, conçue pour adapter les grands modèles de langage (LLM) à de nouvelles tâches. LoRA fonctionne en gelant la majorité des paramètres du modèle et en introduisant un petit ensemble de paramètres entraînables sous la forme de matrices de faible rang. Ces matrices sont ajoutées au modèle dans un format de décomposition de rang faible, ce qui permet au modèle de s'adapter à de nouvelles tâches sans modifier ou stocker l'ensemble des poids du modèle.
En utilisant LoRA, nous pouvons réduire de manière significative la consommation de VRAM et le temps de formation tout en maintenant une précision comparable à celle d'un réglage fin complet.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Nous allons maintenant mettre en place le SFTTrainer, qui simplifie le processus de réglage fin en combinant les composants essentiels, tels que l'ensemble de données, le modèle, le collecteur de données, les arguments d'entraînement et la configuration de LoRA en un seul flux de travail rationalisé. Cette approche rend le réglage fin efficace, convivial et hautement personnalisable.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Avant de commencer le processus de formation, nous libérons la RAM et la VRAM du GPU afin d'éviter les problèmes de mémoire insuffisante (OOM). Cela permet d'assurer une exécution en douceur pendant la formation.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
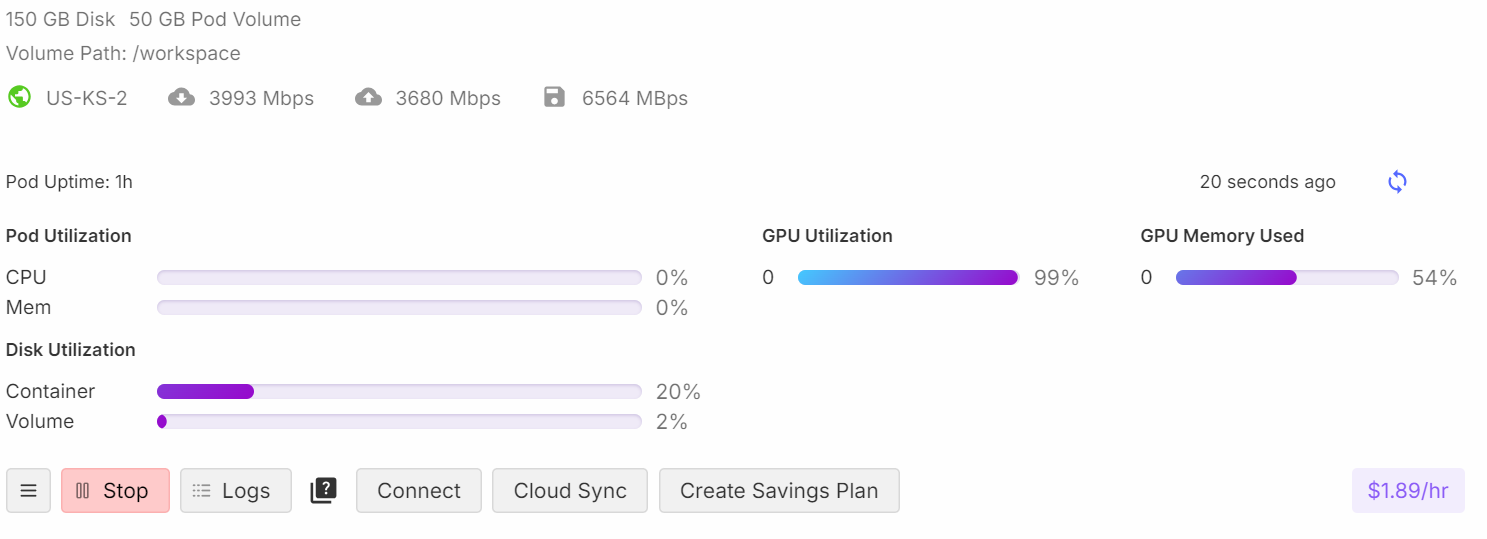
model.config.use_cache = False
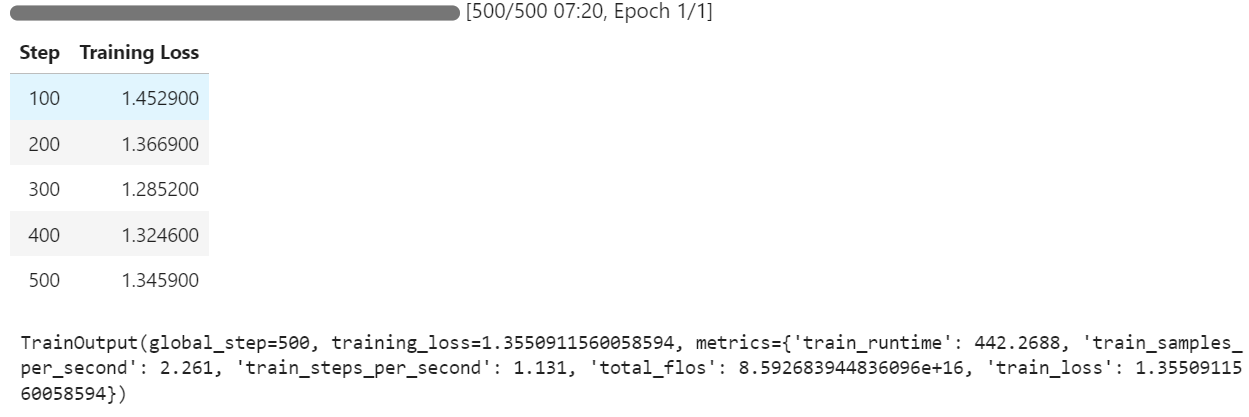
trainer.train()Pendant la formation, le processus utilise environ 54 % de la mémoire et atteint 99 % d'utilisation du GPU, ce qui garantit une utilisation efficace des ressources.
Vous pouvez observer que la perte d'apprentissage diminue à chaque étape, ce qui indique que le modèle apprend et s'ajuste efficacement.
Nous allons maintenant tester le modèle affiné en comparant ses réponses à l'ensemble des données. En utilisant la même question que dans la section précédente, nous générons une réponse :
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])Le raisonnement est détaillé et précis, et la réponse correspond bien à l'ensemble de données.
<think><|im_end|>First, I need to figure out what the employee contributions were for the years 2002 and 2003. Okay, looking at the numbers, I see that the company contributed $979,000 in 2002 and $825,000 in 2003. So, those are my two key figures.
Next, I'll calculate the change in the contribution amount. To find this, I subtract the 2003 contribution from the 2002 contribution. Let me do that: $979,000 minus $825,000 equals $154,000. So, there's a decrease of $154,000 from 2002 to 2003.
Now, I need to understand what this decrease means in terms of percentage. Percentage change is usually calculated by taking the change, dividing it by the original number, and then multiplying by 100. So, I'll take that $154,000 change and divide it by the 2002 amount, $979,000.
Let me do that math: $154,000 divided by $979,000... Hmm, this gives me a value of approximately 0.1573.
Finally, I multiply that by 100 to convert it to a percentage. That gives me about 15.73%.
Oh, wait, let me make sure everything makes sense. I calculated the change in contributions correctly by subtracting the 2003 amount from the 2002 amount. Then I used the original amount from 2002 as the base for the percentage calculation.
Yes, that all seems right. So, the employee contribution decreased by approximately 15.73% from 2002 to 2003.</think>The percentage decrease in the employee contribution from 2002 to 2003 was approximately 15.73%.<|im_end|>Testons un autre exemple :
question = dataset[200]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])Le résultat est impressionnant : le modèle parvient à générer des raisonnements et des réponses précis dans le style de l'ensemble de données :
<think><|im_end|>Okay, let's figure out how much of the long-term debt should be considered current liabilities. So, the total long-term debt at the end of 2011 was $1859 million. Now, I remember that there's some information about the timing of cash payments related to this debt. In particular, there's a chunk of $29 million that is due in 2012. Hmm, that's the part that's likely to become a current liability.
Let’s check the table again to make sure. It says total long-term debt is $1859 million, and the breakdown of estimated cash payments includes $29 million for 2012. Yep, that seems to align. So, this $29 million should be classified as a current liability because it's due within the next year.
But wait, let me double-check. The table is pretty straightforward: long-term debt is $1859 million and the breakdown clearly shows $29 million due in 2012. So, that $29 million is the part that should be on the current liabilities section of the balance sheet.
Alright, so I'm confident that the portion of the long-term debt that's included in current liabilities as of December 31, 2011, is $29 million. That's it!</think>The portion of the long-term debt included in the current liabilities on the balance sheet as of December 31, 2011, is $29 million. This $29 million represents the amount of debt due within the next year, making it a current liability.<|im_end|>Pour rendre le modèle affiné accessible pour une utilisation future et pour que d'autres puissent le télécharger, nous enregistrerons l'adaptateur de modèle et le tokenizer et les pousserons vers le Hugging Face Hub :
new_model_name = "Phi-4-Reasoning-Plus-FinQA-COT"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Le modèle est désormais accessible au public à l'adresse suivante kingabzpro/Phi-4-Raisonnement-Plus-FinQA-COT.
Source : kingabzpro/Phi-4-Raisonnement-Plus-FinQA-COT - Hugging Face
Si vous rencontrez des problèmes lors de l'exécution du script de réglage fin, reportez-vous au cahier d'accompagnement : fine-tuning-phi-4-reasoning.ipynb.
Le modèle de raisonnement Phi-4 représente une avancée significative pour la communauté des logiciels libres. Au lieu de s'appuyer sur des modèles massifs de 685B paramètres, Phi-4 Reasoning obtient de meilleurs résultats avec une architecture plus petite et plus efficace. Cela démontre que le fait de se concentrer sur des ensembles de données de haute qualité et sur l'apprentissage par renforcement peut permettre d'obtenir des performances encore meilleures avec des modèles plus petits.
L'un des meilleurs aspects de la mise au point du modèle de raisonnement Phi-4 est son prix abordable et son efficacité. La mise au point de ce modèle sur 20 000 échantillons ou plus vous coûtera moins de 10 dollars et ne prendra que quelques heures, grâce à sa taille réduite et à son architecture optimisée.
Des modèles plus petits comme Phi-4 Reasoning permettent non seulement de réduire les coûts de réglage fin, mais aussi d'économiser sur les dépenses d'infrastructure cloud pour l'inférence des modèles. Il s'agit donc d'un excellent choix pour les projets nécessitant des performances élevées sans les frais généraux des modèles massifs.
Pour plus d'informations, veuillez consulter nos guides sur l'affinement de divers modèles linguistiques de grande taille :
Les meilleurs cours de DataCamp
Cursus
Cursus
Cours