
Track
Developing Large Language Models
16 hr
Phi-4-reasoning is a 14-billion parameter open-weight model designed for complex reasoning tasks, rivaling much larger models through meticulous fine-tuning on curated datasets. It generates detailed reasoning chains and leverages inference-time compute to achieve exceptional performance.
Its enhanced version, Phi-4-reasoning-plus, uses reinforcement learning and 1.5x more tokens for even greater accuracy. Despite their smaller size, both models outperform larger counterparts like DeepSeek-R1-Distill-70B and even surpass the 671-billion parameter DeepSeek-R1 on benchmarks.
In this tutorial, we will be using the Phi-4-reasoning-plus model and fine-tuning it on the Financial Q&A reasoning dataset. This guide will include setting up the Runpod environment, loading the model, tokenizer, and dataset, preparing the data for model training, configuring the model for training, running model evaluations, and saving the fine-tuned model adopter.
You can learn about Phi 4 and build a multimodal language tutor by following the tutorial, Phi-4-Multimodal: A Guide With Demo Project.

Image by Author
In this tutorial, we will use RunPod as our computational environment. Follow these steps to set up your environment:
1. Go to the RunPod Dashboard and click on “Deploy On-Demand” to create a new pod.
2. Select the A100 GPU, which is sufficient for loading and fine-tuning the model.
3. Customize your deployment:
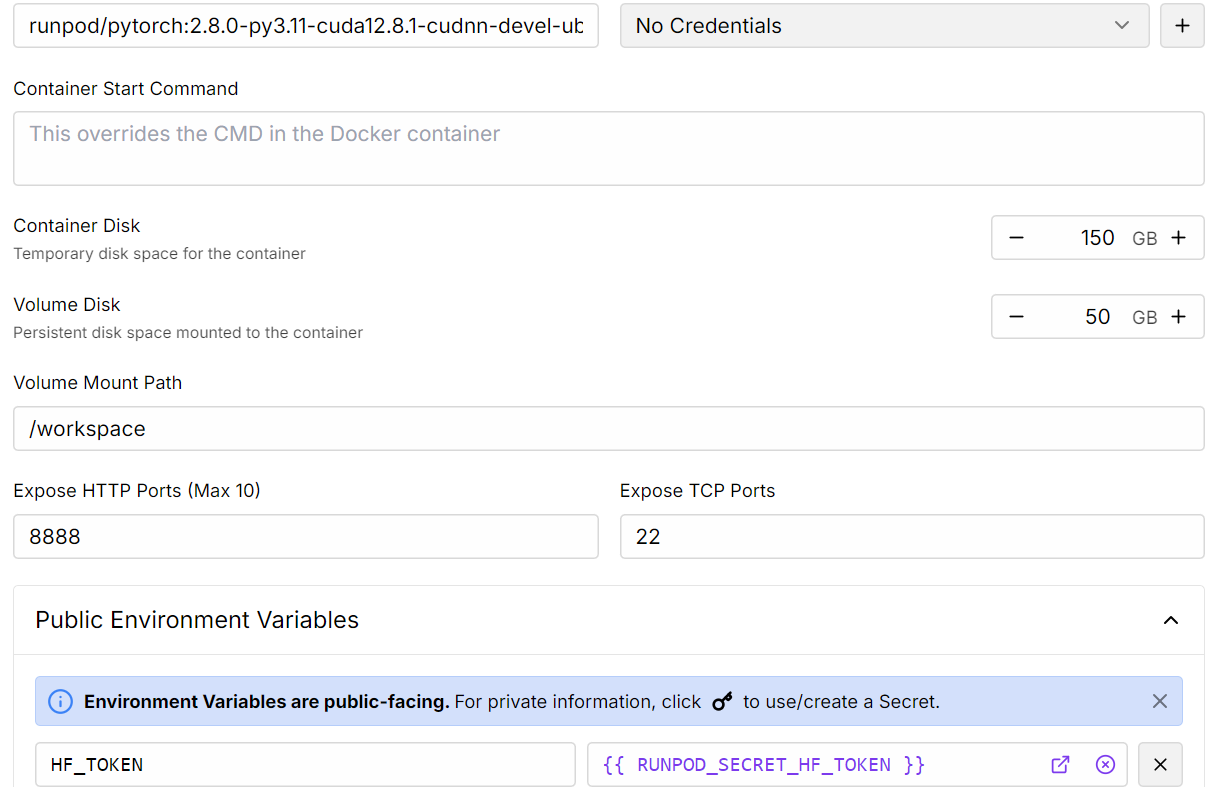
4. Once the pod is deployed, click the Connect button to launch the JupyterLab instance.
5. Inside JupyterLab, create a new notebook and install all the necessary Python packages.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]6. Next, log in to the Hugging Face CLI using the token you saved earlier.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)In this guide, we will load the full microsoft/Phi-4-reasoning-plus model from Hugging Face, along with its tokenizer.
We don’t use the 4-bit quantization here because the hardware can comfortably handle full-precision weights. An A100 with 80 GB of VRAM leaves plenty of headroom, as the complete Phi-4-Reasoning model occupies only about 28 GB, so there’s still more than 50 GB free for activations, optimizer states, and other training overhead.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "microsoft/Phi-4-reasoning-plus"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1
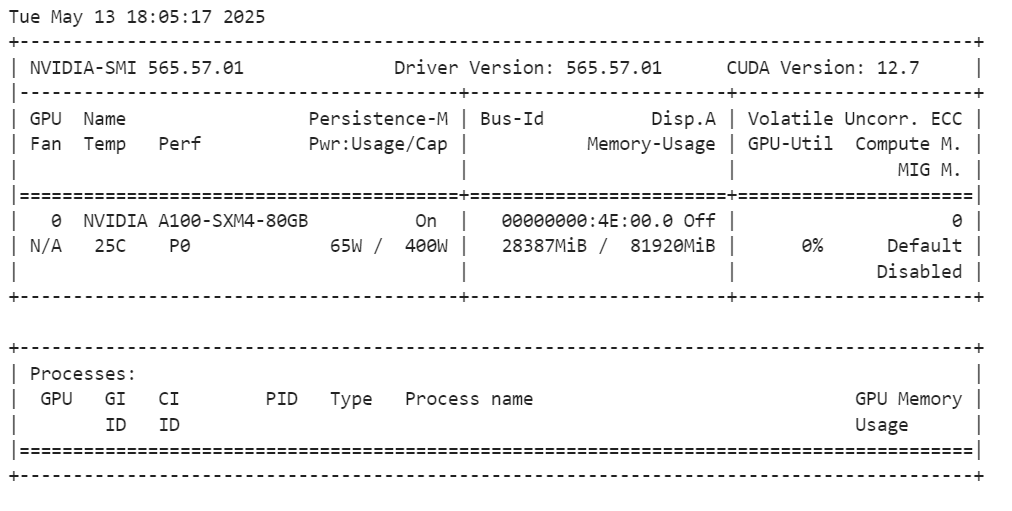
After loading the model, you can check how much GPU memory it consumes by running the following command:
!nvidia-smiThe full model uses about 28GB of VRAM. The A100 GPU has 80GB of VRAM, so you still have 55GB of free memory for fine-tuning tasks.
Before we load the dataset, we will define a training prompt style. This prompt includes:
This prompt style is designed to encourage the model to think critically and produce a reasoning process along with the final response.
train_prompt_style="""
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
</think>
{}
"""We will create a Python function to apply the dataset's columns (questions, reasoning, and responses) to the prompt template. This function will generate a new column called “text”, which includes all the prompt components.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs,complex_cots,outputs):
text = train_prompt_style.format(input,cot,output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Now, we will download the dataset (TheFinAI/Fino1_Reasoning_Path_FinQA), load 1000 samples, apply the formatting function, and create the new “text” column.
from datasets import load_dataset
dataset = load_dataset(
"TheFinAI/Fino1_Reasoning_Path_FinQA", split="train[0:1000]", trust_remote_code=True
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][20]The "text" column of the dataset includes system instructions, the user question, a step-by-step reasoning chain, and the final answer. This structured format ensures the model understands the task and generates high-quality responses.

The new STF trainer function does not accept a tokenizer directly. Therefore, we need to convert the tokenizer into a data collator using the DataCollatorForLanguageModeling from Transformers.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Before fine-tuning, we will run inference on a question from the dataset to compare the model's performance after fine-tuning. The inference prompt style is similar to the training prompt style but excludes the reasoning part and the answer.
inference_prompt_style = """
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
"""We will select the 21st question from the dataset, format it, and tokenize it for inference:
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])The model generates a long reasoning part but fails to provide a clear answer. Increasing max_new_tokens to 2000 might yield an answer, but this approach is inefficient and unreliable. The reasoning is scattered, and the conclusion is inaccurate.

In this section, we will implement LoRA (Low-Rank Adaptation), a parameter-efficient fine-tuning technique designed to adapt large language models (LLMs) to new tasks. LoRA works by freezing the majority of the model's parameters and introducing a small set of trainable parameters in the form of low-rank matrices. These matrices are added to the model in a low-rank decomposition format, allowing the model to adapt to new tasks without modifying or storing the full set of model weights.
By using LoRA we can significantly reduce VRAM consumption and training time while maintaining accuracy comparable to full fine-tuning.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)We will now set up the SFTTrainer, which simplifies the fine-tuning process by combining essential components, such as the dataset, model, data collator, training arguments, and LoRA configuration into a single, streamlined workflow. This approach makes fine-tuning efficient, user-friendly, and highly customizable.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Before starting the training process, we will free up RAM and GPU VRAM to avoid out-of-memory (OOM) issues. This ensures smooth execution during training.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
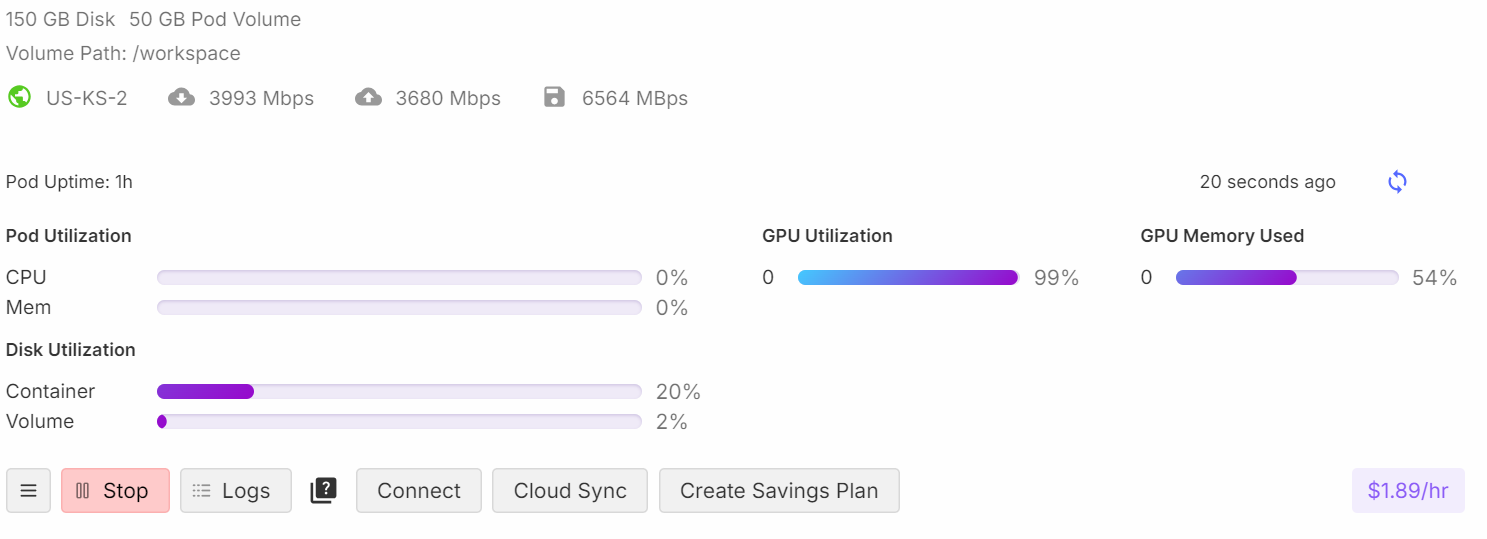
trainer.train()During training, the process utilizes approximately 54% of memory and achieves 99% GPU utilization, ensuring efficient resource usage.
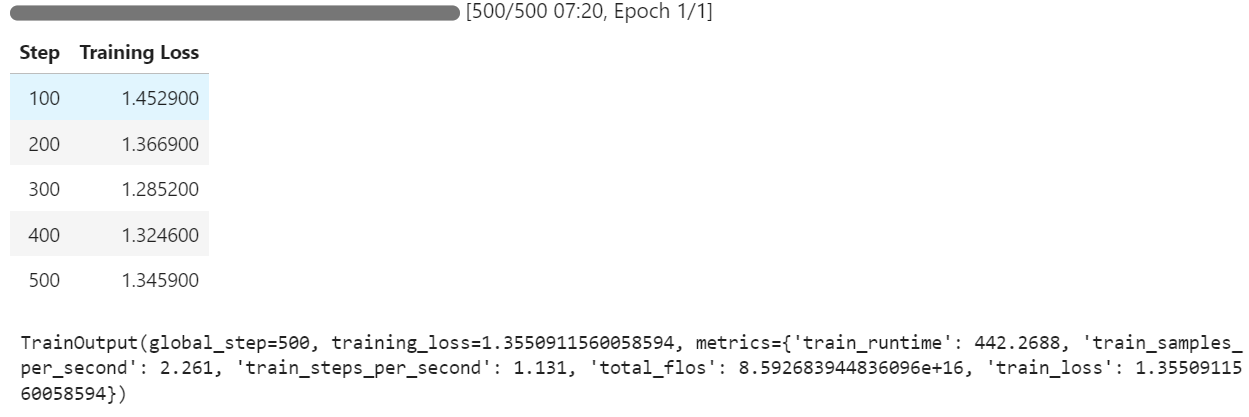
You can observe that the training loss decreases with each step, indicating that the model is learning and fine-tuning effectively.
We will now test the fine-tuned model by comparing its responses to the dataset. Using the same question from the previous section, we generate a response:
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])The reasoning part is detailed and accurate, and the answer closely matches the dataset.
<think><|im_end|>First, I need to figure out what the employee contributions were for the years 2002 and 2003. Okay, looking at the numbers, I see that the company contributed $979,000 in 2002 and $825,000 in 2003. So, those are my two key figures.
Next, I'll calculate the change in the contribution amount. To find this, I subtract the 2003 contribution from the 2002 contribution. Let me do that: $979,000 minus $825,000 equals $154,000. So, there's a decrease of $154,000 from 2002 to 2003.
Now, I need to understand what this decrease means in terms of percentage. Percentage change is usually calculated by taking the change, dividing it by the original number, and then multiplying by 100. So, I'll take that $154,000 change and divide it by the 2002 amount, $979,000.
Let me do that math: $154,000 divided by $979,000... Hmm, this gives me a value of approximately 0.1573.
Finally, I multiply that by 100 to convert it to a percentage. That gives me about 15.73%.
Oh, wait, let me make sure everything makes sense. I calculated the change in contributions correctly by subtracting the 2003 amount from the 2002 amount. Then I used the original amount from 2002 as the base for the percentage calculation.
Yes, that all seems right. So, the employee contribution decreased by approximately 15.73% from 2002 to 2003.</think>The percentage decrease in the employee contribution from 2002 to 2003 was approximately 15.73%.<|im_end|>Let’s test another example:
question = dataset[200]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])The result is impressive, with the model successfully generating accurate reasoning and answers in the dataset's style:
<think><|im_end|>Okay, let's figure out how much of the long-term debt should be considered current liabilities. So, the total long-term debt at the end of 2011 was $1859 million. Now, I remember that there's some information about the timing of cash payments related to this debt. In particular, there's a chunk of $29 million that is due in 2012. Hmm, that's the part that's likely to become a current liability.
Let’s check the table again to make sure. It says total long-term debt is $1859 million, and the breakdown of estimated cash payments includes $29 million for 2012. Yep, that seems to align. So, this $29 million should be classified as a current liability because it's due within the next year.
But wait, let me double-check. The table is pretty straightforward: long-term debt is $1859 million and the breakdown clearly shows $29 million due in 2012. So, that $29 million is the part that should be on the current liabilities section of the balance sheet.
Alright, so I'm confident that the portion of the long-term debt that's included in current liabilities as of December 31, 2011, is $29 million. That's it!</think>The portion of the long-term debt included in the current liabilities on the balance sheet as of December 31, 2011, is $29 million. This $29 million represents the amount of debt due within the next year, making it a current liability.<|im_end|>To make the fine-tuned model accessible for future use and for others to download, we will save the model adapter and tokenizer and push them to the Hugging Face Hub:
new_model_name = "Phi-4-Reasoning-Plus-FinQA-COT"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)The model is now publicly available at: kingabzpro/Phi-4-Reasoning-Plus-FinQA-COT.
Source: kingabzpro/Phi-4-Reasoning-Plus-FinQA-COT · Hugging Face
If you encounter any issues running the fine-tuning script, refer to the companion notebook: fine-tuning-phi-4-reasoning.ipynb.
The Phi-4 Reasoning model represents a significant step forward for the open-source community. Instead of relying on massive 685B-parameter models, Phi-4 Reasoning achieves better results with a smaller, more efficient architecture. This demonstrates that focusing on high-quality datasets and reinforcement learning can lead to even better performance in smaller models.
One of the best aspects of fine-tuning the Phi-4 Reasoning model is its affordability and efficiency. Fine-tuning this model on 20K samples or more will cost you less than $10 and only take a few hours, thanks to its smaller size and optimized architecture.
Smaller models like Phi-4 Reasoning not only reduce fine-tuning costs but also save on cloud infrastructure expenses for model inference. This makes it an excellent choice for projects requiring high performance without the overhead of massive models.
For more information, please refer to our guides on fine-tuning various large language models:
Top DataCamp Courses
Track
Track
Course
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
