
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Phi-4-reasoning ist ein 14-Milliarden-Parameter-Modell mit offenem Gewicht, das für komplexe Schlussfolgerungen entwickelt wurde und durch sorgfältige Feinabstimmung an kuratierten Datensätzen mit viel größeren Modellen mithalten kann. Sie erzeugt detaillierte Schlussfolgerungsketten und nutzt die Inferenzzeitberechnung, um eine außergewöhnliche Leistung zu erzielen.
Seine verbesserte Version, Phi-4-reasoning-plus, verwendet Reinforcement Learning und 1,5x mehr Token für noch höhere Genauigkeit. Trotz ihrer geringeren Größe übertreffen beide Modelle größere Gegenstücke wie DeepSeek-R1-Distill-70B und übertreffen sogar den 671-Milliarden-Parameter DeepSeek-R1 bei Benchmarks.
In diesem Tutorial werden wir das Phi-4-Reasoning-Plus-Modell verwenden und es mit dem Financial Q&A Reasoning-Datensatz feinabstimmen. Diese Anleitung umfasst das Einrichten der Runpod-Umgebung, das Laden des Modells, des Tokenizers und des Datensatzes, das Vorbereiten der Daten für das Modelltraining, das Konfigurieren des Modells für das Training, das Ausführen von Modellevaluierungen und das Speichern des feinabgestimmten Modelladapters.
Du kannst mehr über Phi 4 erfahren und einen multimodalen Sprachtutor erstellen, indem du dem Tutorial Phi-4-Multimodal folgst : Ein Leitfaden mit Demo-Projekt.

Bild vom Autor
In diesem Lernprogramm werden wir RunPod als Rechenumgebung verwenden. Befolge diese Schritte, um deine Umgebung einzurichten:
1. Gehe zum RunPod Dashboard und klicke auf "On-Demand bereitstellen", um einen neuen Pod.
2. Wähle den A100-Grafikprozessor, der für das Laden und die Feinabstimmung des Modells ausreicht.
3. Passe deinen Einsatz an:
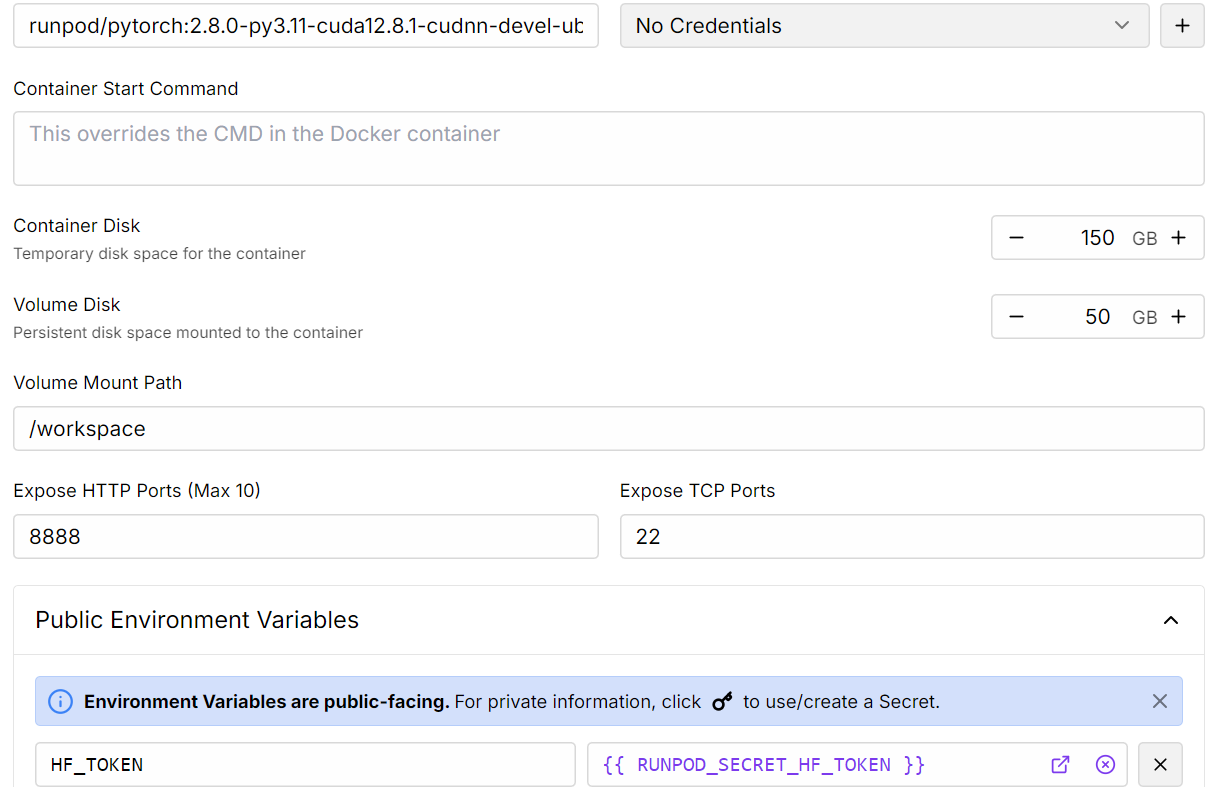
4. Sobald der Pod bereitgestellt ist, klicke auf die Schaltfläche Verbinden, um die JupyterLab-Instanz zu starten.
5. Erstelle in JupyterLab ein neues Notizbuch und installiere alle notwendigen Python-Pakete.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]6. Als Nächstes loggst du dich bei der Hugging Face CLI mit dem Token an, den du zuvor gespeichert hast.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)In dieser Anleitung laden wir die vollständige microsoft/Phi-4-reasoning-plus Modell von Hugging Face zusammen mit seinem Tokenizer.
Wir verwenden nicht die 4-Bit Quantisierung hier nicht, weil die Hardware problemlos mit vollpräzisen Gewichten umgehen kann. Ein A100 mit 80 GB VRAM lässt viel Spielraum, denn das komplette Phi-4-Reasoning-Modell belegt nur etwa 28 GB, so dass immer noch mehr als 50 GB für Aktivierungen, Optimierungszustände und anderen Trainings-Overhead zur Verfügung stehen.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "microsoft/Phi-4-reasoning-plus"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1
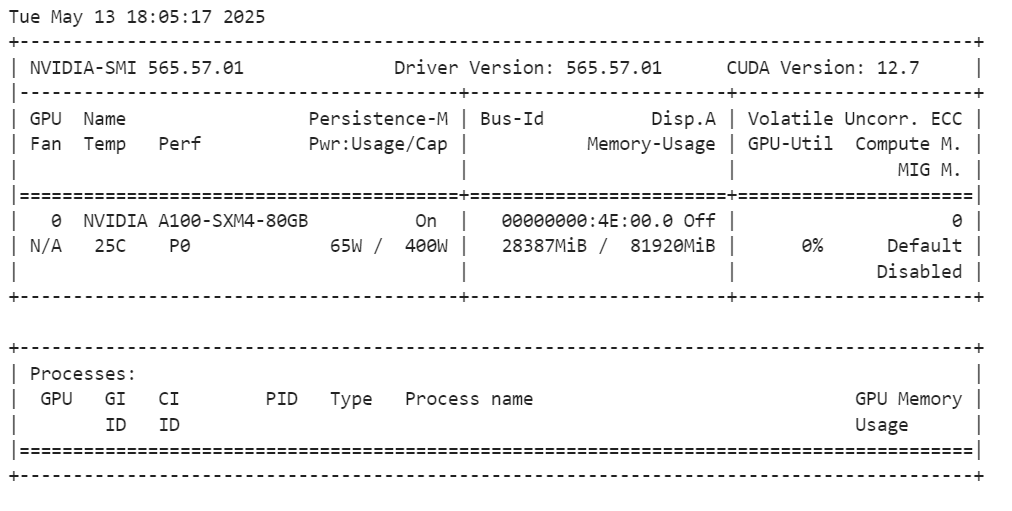
Nachdem du das Modell geladen hast, kannst du überprüfen, wie viel GPU-Speicher es verbraucht, indem du den folgenden Befehl ausführst:
!nvidia-smiDas vollständige Modell nutzt etwa 28 GB VRAM. Die A100-GPU verfügt über 80 GB VRAM, so dass dir immer noch 55 GB freier Speicher für Feinabstimmungen zur Verfügung stehen.
Bevor wir den Datensatz laden, legen wir einen Trainings-Prompt-Stil fest. Diese Aufforderung beinhaltet:
Diese Aufforderung ist so gestaltet, dass sie das Modell dazu anregt, kritisch zu denken und zusammen mit der endgültigen Antwort eine Argumentation zu erstellen.
train_prompt_style="""
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
</think>
{}
"""Wir erstellen eine Python-Funktion, mit der wir die Spalten des Datensatzes (Fragen, Argumente und Antworten) auf die Prompt-Vorlage anwenden. Diese Funktion erzeugt eine neue Spalte mit dem Namen "Text", die alle Komponenten der Eingabeaufforderung enthält.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs,complex_cots,outputs):
text = train_prompt_style.format(input,cot,output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Jetzt laden wir den Datensatz herunter (TheFinAI/Fino1_Reasoning_Path_FinQA), laden 1000 Stichproben, wenden die Formatierungsfunktion an und erstellen die neue Spalte "Text".
from datasets import load_dataset
dataset = load_dataset(
"TheFinAI/Fino1_Reasoning_Path_FinQA", split="train[0:1000]", trust_remote_code=True
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][20]Die Spalte "Text" des Datensatzes enthält die Anweisungen des Systems, die Frage des Nutzers, eine Schritt-für-Schritt-Überlegungskette und die endgültige Antwort. Dieses strukturierte Format stellt sicher, dass das Modell die Aufgabe versteht und qualitativ hochwertige Antworten erzeugt.

Die neue STF-Trainerfunktion akzeptiert nicht direkt einen Tokenizer. Deshalb müssen wir den Tokenizer in einen DataCollator umwandeln, indem wir den DataCollatorForLanguageModeling von Transformers verwenden.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Vor der Feinabstimmung führen wir eine Inferenz für eine Frage aus dem Datensatz durch, um die Leistung des Modells nach der Feinabstimmung zu vergleichen. Der Stil der Schlussfolgerungsaufforderung ähnelt dem der Trainingsaufforderung, schließt aber den Argumentationsteil und die Antwort aus.
inference_prompt_style = """
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
"""Wir werden die 21. Frage aus dem Datensatz auswählen, sie formatieren und für die Inferenz in Token umwandeln:
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])Das Modell erzeugt einen langen Argumentationsteil, liefert aber keine klare Antwort. Die Erhöhung von max_new_tokens auf 2000 könnte eine Antwort bringen, aber dieser Ansatz ist ineffizient und unzuverlässig. Die Argumentation ist verstreut und die Schlussfolgerung ist ungenau.

In diesem Abschnitt werden wir Folgendes implementieren LoRA (Low-Rank Adaptation)eine parameter-effiziente Feinabstimmungstechnik, die entwickelt wurde, um große Sprachmodelle (LLMs) an neue Aufgaben anzupassen. LoRA funktioniert, indem es die meisten Parameter des Modells einfriert und einen kleinen Satz trainierbarer Parameter in Form von Low-Rank-Matrizen einführt. Diese Matrizen werden dem Modell in einem Low-Rank-Decomposition-Format hinzugefügt, so dass sich das Modell an neue Aufgaben anpassen kann, ohne dass der vollständige Satz von Modellgewichten geändert oder gespeichert werden muss.
Durch den Einsatz von LoRA können wir den VRAM-Verbrauch und die Trainingszeit erheblich reduzieren und gleichzeitig eine Genauigkeit erreichen, die mit der einer vollständigen Feinabstimmung vergleichbar ist.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Wir werden nun den SFTTrainer einrichten, der den Feinabstimmungsprozess vereinfacht, indem er wichtige Komponenten wie den Datensatz, das Modell, den Datensammler, die Trainingsargumente und die LoRA-Konfiguration in einem einzigen, optimierten Arbeitsablauf zusammenfasst. Dieser Ansatz macht die Feinabstimmung effizient, benutzerfreundlich und in hohem Maße anpassbar.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Bevor wir mit dem Trainingsprozess beginnen, geben wir den Arbeitsspeicher und den VRAM der GPU frei, um OOM-Probleme (Out-of-Memory) zu vermeiden. Das sorgt für einen reibungslosen Ablauf während der Ausbildung.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
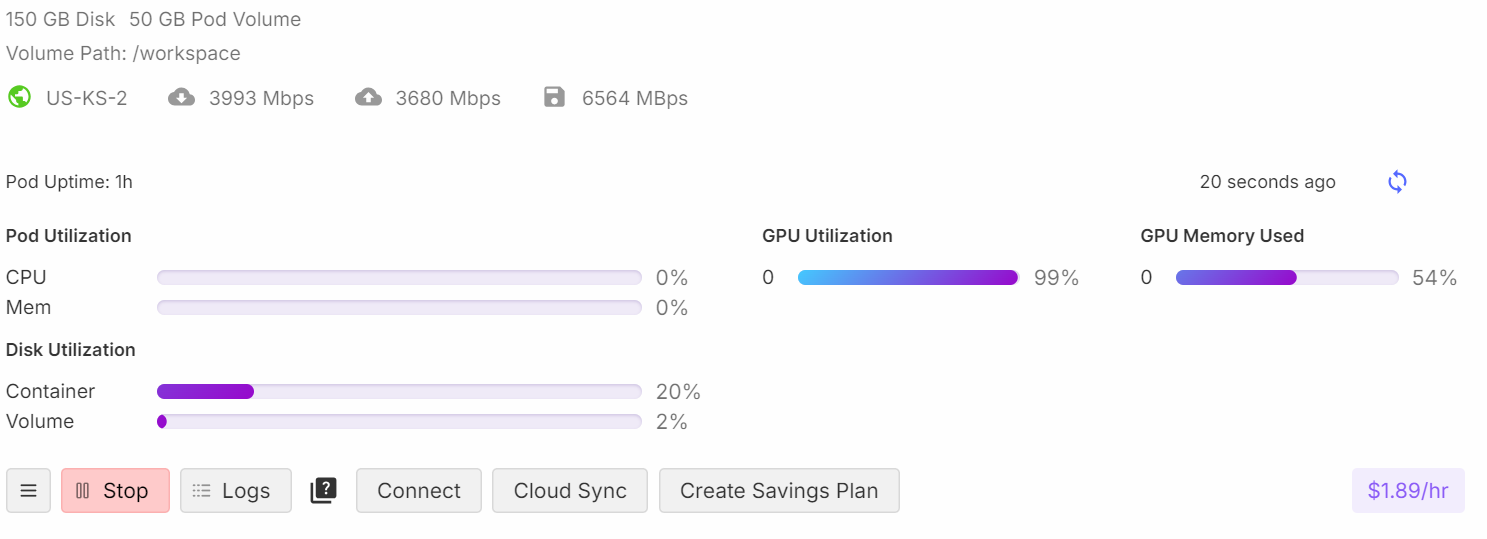
trainer.train()Während des Trainings nutzt der Prozess etwa 54% des Speichers und erreicht eine 99%ige GPU-Auslastung, was eine effiziente Ressourcennutzung gewährleistet.
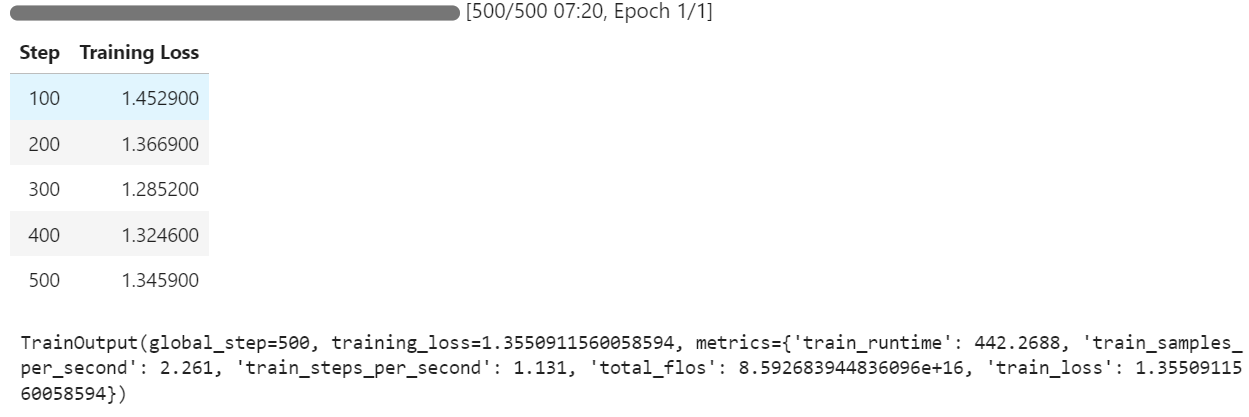
Du kannst beobachten, dass der Trainingsverlust mit jedem Schritt abnimmt, was darauf hindeutet, dass das Modell effektiv lernt und fein abgestimmt wird.
Wir werden nun das fein abgestimmte Modell testen, indem wir seine Antworten mit dem Datensatz vergleichen. Wir verwenden dieselbe Frage aus dem vorherigen Abschnitt, um eine Antwort zu generieren:
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])Der Argumentationsteil ist detailliert und genau, und die Antwort stimmt genau mit dem Datensatz überein.
<think><|im_end|>First, I need to figure out what the employee contributions were for the years 2002 and 2003. Okay, looking at the numbers, I see that the company contributed $979,000 in 2002 and $825,000 in 2003. So, those are my two key figures.
Next, I'll calculate the change in the contribution amount. To find this, I subtract the 2003 contribution from the 2002 contribution. Let me do that: $979,000 minus $825,000 equals $154,000. So, there's a decrease of $154,000 from 2002 to 2003.
Now, I need to understand what this decrease means in terms of percentage. Percentage change is usually calculated by taking the change, dividing it by the original number, and then multiplying by 100. So, I'll take that $154,000 change and divide it by the 2002 amount, $979,000.
Let me do that math: $154,000 divided by $979,000... Hmm, this gives me a value of approximately 0.1573.
Finally, I multiply that by 100 to convert it to a percentage. That gives me about 15.73%.
Oh, wait, let me make sure everything makes sense. I calculated the change in contributions correctly by subtracting the 2003 amount from the 2002 amount. Then I used the original amount from 2002 as the base for the percentage calculation.
Yes, that all seems right. So, the employee contribution decreased by approximately 15.73% from 2002 to 2003.</think>The percentage decrease in the employee contribution from 2002 to 2003 was approximately 15.73%.<|im_end|>Lass uns ein anderes Beispiel testen:
question = dataset[200]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])Das Ergebnis ist beeindruckend: Das Modell generiert erfolgreich genaue Argumente und Antworten im Stil des Datensatzes:
<think><|im_end|>Okay, let's figure out how much of the long-term debt should be considered current liabilities. So, the total long-term debt at the end of 2011 was $1859 million. Now, I remember that there's some information about the timing of cash payments related to this debt. In particular, there's a chunk of $29 million that is due in 2012. Hmm, that's the part that's likely to become a current liability.
Let’s check the table again to make sure. It says total long-term debt is $1859 million, and the breakdown of estimated cash payments includes $29 million for 2012. Yep, that seems to align. So, this $29 million should be classified as a current liability because it's due within the next year.
But wait, let me double-check. The table is pretty straightforward: long-term debt is $1859 million and the breakdown clearly shows $29 million due in 2012. So, that $29 million is the part that should be on the current liabilities section of the balance sheet.
Alright, so I'm confident that the portion of the long-term debt that's included in current liabilities as of December 31, 2011, is $29 million. That's it!</think>The portion of the long-term debt included in the current liabilities on the balance sheet as of December 31, 2011, is $29 million. This $29 million represents the amount of debt due within the next year, making it a current liability.<|im_end|>Um das feinabgestimmte Modell für die zukünftige Nutzung und für andere zum Herunterladen zugänglich zu machen, speichern wir den Modelladapter und den Tokenizer und stellen sie in den Hugging Face Hub:
new_model_name = "Phi-4-Reasoning-Plus-FinQA-COT"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Das Modell ist jetzt öffentlich zugänglich unter: kingabzpro/Phi-4-Reasoning-Plus-FinQA-COT.
Quelle: kingabzpro/Phi-4-Reasoning-Plus-FinQA-COT - Hugging Face
Wenn du bei der Ausführung des Feinabstimmungsskripts auf Probleme stößt, sieh dir das Begleitheft an: fine-tuning-phi-4-reasoning.ipynb.
Das Phi-4 Reasoning Modell ist ein bedeutender Schritt nach vorne für die Open-Source-Gemeinschaft. Anstatt sich auf massive 685B-Parameter-Modelle zu verlassen, erzielt Phi-4 Reasoning bessere Ergebnisse mit einer kleineren, effizienteren Architektur. Dies zeigt, dass die Konzentration auf qualitativ hochwertige Datensätze und Reinforcement Learning zu einer noch besseren Leistung bei kleineren Modellen führen kann.
Einer der besten Aspekte der Feinabstimmung des Phi-4 Reasoning Modells ist seine Erschwinglichkeit und Effizienz. Die Feinabstimmung dieses Modells mit 20.000 Proben oder mehr kostet dich weniger als 10 US-Dollar und dauert dank seiner geringen Größe und optimierten Architektur nur wenige Stunden.
Kleinere Modelle wie Phi-4 Reasoning reduzieren nicht nur die Kosten für die Feinabstimmung, sondern sparen auch die Kosten für die Cloud-Infrastruktur für die Modellinferenz. Das macht ihn zu einer ausgezeichneten Wahl für Projekte, die eine hohe Leistung erfordern, ohne den Overhead von großen Modellen.
Weitere Informationen findest du in unseren Anleitungen zur Feinabstimmung verschiedener großer Sprachmodelle:
Top DataCamp Kurse
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
