
programa
Desarrollar grandes modelos lingüísticos
16 h
El razonamiento Phi-4 es un modelo de peso abierto de 14.000 millones de parámetros diseñado para tareas de razonamiento complejas, que rivaliza con modelos mucho mayores mediante un meticuloso ajuste fino en conjuntos de datos curados. Genera cadenas de razonamiento detalladas y aprovecha el cálculo en tiempo de inferencia para conseguir un rendimiento excepcional.
Su versión mejorada, Phi-4-reasoning-plus, utiliza el aprendizaje por refuerzo y 1,5 veces más fichas para una precisión aún mayor. A pesar de su menor tamaño, ambos modelos superan a sus homólogos de mayor tamaño, como el DeepSeek-R1-Distill-70B, e incluso superan el parámetro 671 mil millones DeepSeek-R1 en los puntos de referencia.
En este tutorial, utilizaremos el modelo de razonamiento Phi-4-plus y lo pondremos a punto en el conjunto de datos de razonamiento de preguntas y respuestas financieras. Esta guía incluirá la configuración del entorno Runpod, la carga del modelo, el tokenizador y el conjunto de datos, la preparación de los datos para el entrenamiento del modelo, la configuración del modelo para el entrenamiento, la ejecución de las evaluaciones del modelo y el guardado del adoptador del modelo afinado.
Puedes aprender sobre Phi 4 y construir un tutor lingüístico multimodal siguiendo el tutorial, Phi-4-Multimodal: Una guía con proyecto de demostración.

Imagen del autor
En este tutorial, utilizaremos RunPod como entorno de cálculo. Sigue estos pasos para configurar tu entorno:
1. Ve al Panel de control de RunPod y haz clic en "Despliegue a petición" para crear un nuevo pod nuevo pod.
2. Selecciona la GPU A100, que es suficiente para cargar y ajustar el modelo.
3. Personaliza tu despliegue:
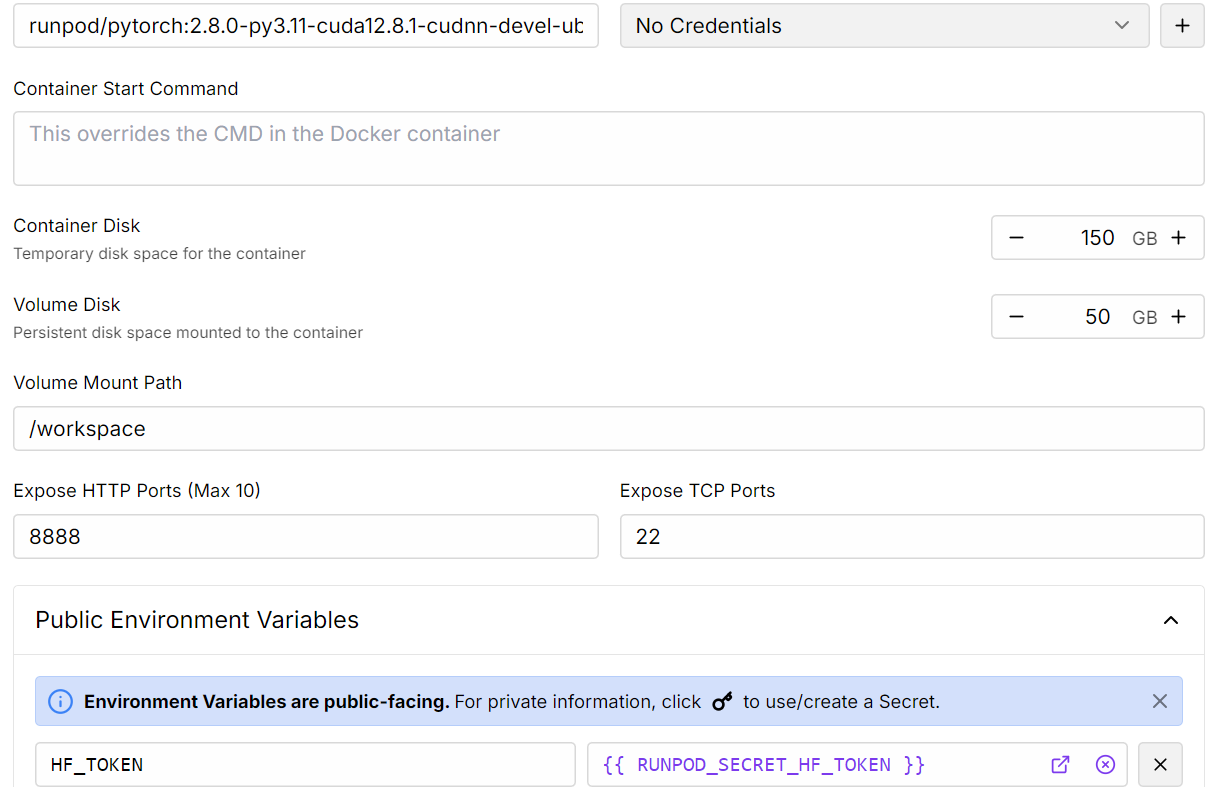
4. Una vez desplegado el pod, haz clic en el botón Conectar para iniciar la instancia de JupyterLab.
5. Dentro de JupyterLab, crea un cuaderno nuevo e instala todos los paquetes de Python necesarios.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]6. A continuación, inicia sesión en Hugging Face CLI utilizando el token que guardaste anteriormente.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)En esta guía, cargaremos la versión completa de microsoft/Phi-4-razonamiento-plus de Hugging Face, junto con su tokenizador.
No utilizamos la cuantificación de 4 bits cuantificación porque el hardware puede manejar cómodamente pesos de precisión completa. Un A100 con 80 GB de VRAM deja mucho espacio libre, ya que el modelo completo de razonamiento Phi-4 sólo ocupa unos 28 GB, por lo que aún quedan más de 50 GB libres para activaciones, estados del optimizador y otros gastos generales de entrenamiento.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "microsoft/Phi-4-reasoning-plus"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1
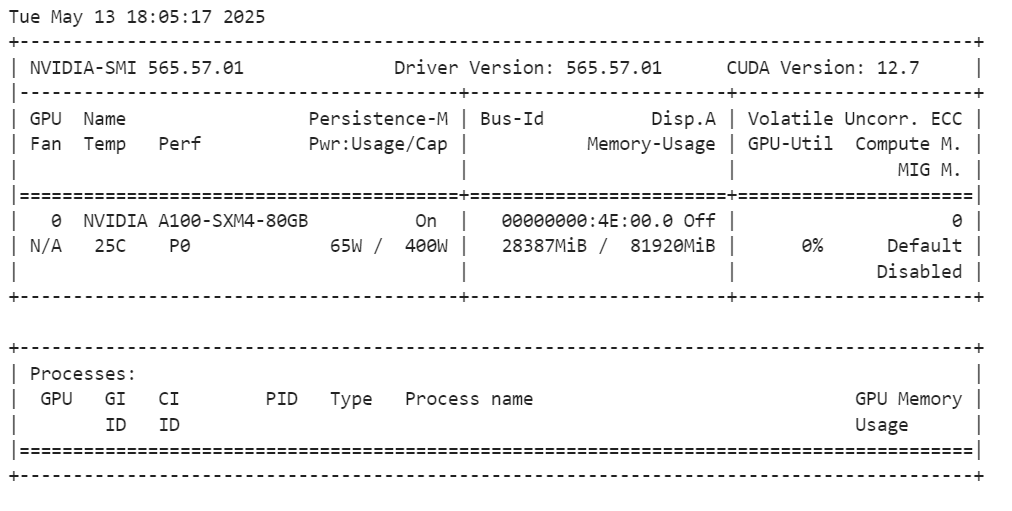
Después de cargar el modelo, puedes comprobar cuánta memoria de GPU consume ejecutando el siguiente comando:
!nvidia-smiEl modelo completo utiliza unos 28 GB de VRAM. La GPU A100 tiene 80 GB de VRAM, por lo que aún te quedan 55 GB de memoria libre para tareas de ajuste.
Antes de cargar el conjunto de datos, definiremos un estilo de aviso de entrenamiento. Este aviso incluye:
Este estilo de estímulo está diseñado para animar al modelo a pensar de forma crítica y producir un proceso de razonamiento junto con la respuesta final.
train_prompt_style="""
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
</think>
{}
"""Crearemos una función Python para aplicar las columnas del conjunto de datos (preguntas, razonamientos y respuestas) a la plantilla de preguntas. Esta función generará una nueva columna llamada "texto", que incluye todos los componentes del aviso.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs,complex_cots,outputs):
text = train_prompt_style.format(input,cot,output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Ahora, descargaremos el conjunto de datos (LaFinAI/Fino1_Razonamiento_Ruta_FinQA), cargaremos 1000 muestras, aplicaremos la función de formato y crearemos la nueva columna "texto".
from datasets import load_dataset
dataset = load_dataset(
"TheFinAI/Fino1_Reasoning_Path_FinQA", split="train[0:1000]", trust_remote_code=True
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][20]La columna "texto" del conjunto de datos incluye las instrucciones del sistema, la pregunta del usuario, una cadena de razonamiento paso a paso y la respuesta final. Este formato estructurado garantiza que el modelo comprenda la tarea y genere respuestas de alta calidad.

La nueva función de entrenador STF no acepta un tokenizador directamente. Por tanto, tenemos que convertir el tokenizador en un recopilador de datos utilizando el DataCollatorForLanguageModeling de Transformers.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Antes del ajuste fino, realizaremos una inferencia sobre una pregunta del conjunto de datos para comparar el rendimiento del modelo tras el ajuste fino. El estilo de pregunta de inferencia es similar al estilo de pregunta de entrenamiento, pero excluye la parte de razonamiento y la respuesta.
inference_prompt_style = """
<|im_start|>system<|im_sep|>
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
<|im_end|>
<|im_start|>user<|im_sep|>
{}<|im_end|>
<|im_start|>assistant<|im_sep|>
<think>
{}
"""Seleccionaremos la 21ª pregunta del conjunto de datos, la formatearemos y la tokenizaremos para la inferencia:
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])El modelo genera una larga parte de razonamiento, pero no consigue dar una respuesta clara. Aumentar max_new_tokens a 2000 podría dar una respuesta, pero este enfoque es ineficaz y poco fiable. El razonamiento es disperso y la conclusión inexacta.

En esta sección, pondremos en práctica LoRA (Adaptación de bajo rango)una técnica de ajuste fino con parámetros eficientes diseñada para adaptar grandes modelos lingüísticos (LLM) a nuevas tareas. LoRA funciona congelando la mayoría de los parámetros del modelo e introduciendo un pequeño conjunto de parámetros entrenables en forma de matrices de bajo rango. Estas matrices se añaden al modelo en un formato de descomposición de bajo rango, lo que permite al modelo adaptarse a nuevas tareas sin modificar ni almacenar el conjunto completo de pesos del modelo.
Utilizando LoRA podemos reducir significativamente el consumo de VRAM y el tiempo de entrenamiento, manteniendo una precisión comparable a la del ajuste fino completo.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Ahora configuraremos el SFTTrainer, que simplifica el proceso de ajuste combinando componentes esenciales, como el conjunto de datos, el modelo, el cotejador de datos, los argumentos de entrenamiento y la configuración de LoRA en un flujo de trabajo único y racionalizado. Este enfoque hace que el ajuste sea eficaz, fácil de usar y altamente personalizable.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Antes de iniciar el proceso de entrenamiento, liberaremos RAM y VRAM de la GPU para evitar problemas de falta de memoria (OOM). Esto garantiza una ejecución fluida durante el entrenamiento.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Durante el entrenamiento, el proceso utiliza aproximadamente el 54% de la memoria y alcanza un 99% de utilización de la GPU, lo que garantiza un uso eficiente de los recursos.
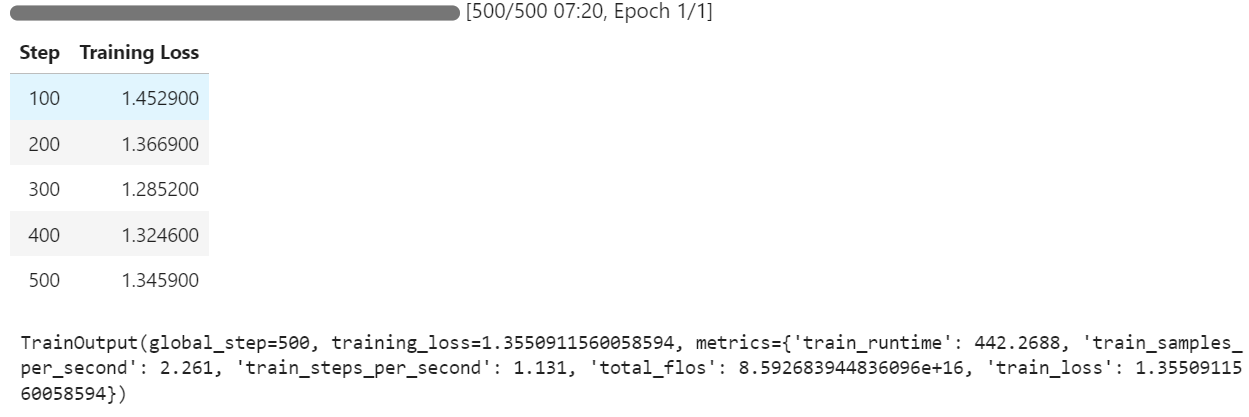
Puedes observar que la pérdida de entrenamiento disminuye con cada paso, lo que indica que el modelo está aprendiendo y afinando eficazmente.
Ahora probaremos el modelo afinado comparando sus respuestas con el conjunto de datos. Utilizando la misma pregunta del apartado anterior, generamos una respuesta:
question = dataset[20]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])La parte de razonamiento es detallada y precisa, y la respuesta se ajusta al conjunto de datos.
<think><|im_end|>First, I need to figure out what the employee contributions were for the years 2002 and 2003. Okay, looking at the numbers, I see that the company contributed $979,000 in 2002 and $825,000 in 2003. So, those are my two key figures.
Next, I'll calculate the change in the contribution amount. To find this, I subtract the 2003 contribution from the 2002 contribution. Let me do that: $979,000 minus $825,000 equals $154,000. So, there's a decrease of $154,000 from 2002 to 2003.
Now, I need to understand what this decrease means in terms of percentage. Percentage change is usually calculated by taking the change, dividing it by the original number, and then multiplying by 100. So, I'll take that $154,000 change and divide it by the 2002 amount, $979,000.
Let me do that math: $154,000 divided by $979,000... Hmm, this gives me a value of approximately 0.1573.
Finally, I multiply that by 100 to convert it to a percentage. That gives me about 15.73%.
Oh, wait, let me make sure everything makes sense. I calculated the change in contributions correctly by subtracting the 2003 amount from the 2002 amount. Then I used the original amount from 2002 as the base for the percentage calculation.
Yes, that all seems right. So, the employee contribution decreased by approximately 15.73% from 2002 to 2003.</think>The percentage decrease in the employee contribution from 2002 to 2003 was approximately 15.73%.<|im_end|>Probemos otro ejemplo:
question = dataset[200]['Open-ended Verifiable Question']
inputs = tokenizer(
[inference_prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("<|im_start|>assistant<|im_sep|>")[1])El resultado es impresionante, ya que el modelo genera con éxito razonamientos y respuestas precisas al estilo del conjunto de datos:
<think><|im_end|>Okay, let's figure out how much of the long-term debt should be considered current liabilities. So, the total long-term debt at the end of 2011 was $1859 million. Now, I remember that there's some information about the timing of cash payments related to this debt. In particular, there's a chunk of $29 million that is due in 2012. Hmm, that's the part that's likely to become a current liability.
Let’s check the table again to make sure. It says total long-term debt is $1859 million, and the breakdown of estimated cash payments includes $29 million for 2012. Yep, that seems to align. So, this $29 million should be classified as a current liability because it's due within the next year.
But wait, let me double-check. The table is pretty straightforward: long-term debt is $1859 million and the breakdown clearly shows $29 million due in 2012. So, that $29 million is the part that should be on the current liabilities section of the balance sheet.
Alright, so I'm confident that the portion of the long-term debt that's included in current liabilities as of December 31, 2011, is $29 million. That's it!</think>The portion of the long-term debt included in the current liabilities on the balance sheet as of December 31, 2011, is $29 million. This $29 million represents the amount of debt due within the next year, making it a current liability.<|im_end|>Para que el modelo ajustado sea accesible para su uso futuro y para que otros puedan descargarlo, guardaremos el adaptador del modelo y el tokenizador y los enviaremos al Hub de Hugging Face:
new_model_name = "Phi-4-Reasoning-Plus-FinQA-COT"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)El modelo ya está disponible públicamente en kingabzpro/Phi-4-Reasoning-Plus-FinQA-COT.
Fuente: kingabzpro/Phi-4-Reasoning-Plus-FinQA-COT - Hugging Face
Si tienes algún problema al ejecutar el script de ajuste fino, consulta el cuaderno complementario: ajuste-fino-phi-4-razonamiento.ipynb.
El modelo de Razonamiento Phi-4 representa un importante paso adelante para la comunidad de código abierto. En lugar de basarse en modelos masivos de 685B parámetros, el Razonamiento Phi-4 consigue mejores resultados con una arquitectura más pequeña y eficiente. Esto demuestra que centrarse en conjuntos de datos de alta calidad y en el aprendizaje por refuerzo puede conducir a un rendimiento aún mejor en modelos más pequeños.
Uno de los mejores aspectos de la puesta a punto del modelo de Razonamiento Phi-4 es su asequibilidad y eficacia. Poner a punto este modelo con 20.000 muestras o más te costará menos de 10 $ y sólo te llevará unas horas, gracias a su menor tamaño y a su arquitectura optimizada.
Los modelos más pequeños, como el Razonamiento Phi-4, no sólo reducen los costes de ajuste, sino que también ahorran gastos de infraestructura en la nube para la inferencia de modelos. Esto lo convierte en una opción excelente para proyectos que requieren un alto rendimiento sin la sobrecarga de los modelos masivos.
Para más información, consulta nuestras guías sobre el ajuste fino de varios modelos lingüísticos de gran tamaño:
Los mejores cursos de DataCamp
programa
programa
Curso
blog
Matt Crabtree
13 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan


