
Programa
Fundamentos de agentes de IA
6 h
Ao trabalhar com agentes de IA, instruções em prompts podem dar conta de tarefas pontuais.
Mas, conforme o conjunto de instruções cresce, a atenção do modelo se fragmenta. Algumas instruções deixam de ser "priorizadas" como um engenheiro humano faria. Em vez disso, cada token compete dentro da janela de contexto. Quanto mais heterogêneas forem as instruções, maior o risco de restrições irrelevantes diluírem orientações críticas.
Com agent skills, dá para abordar isso de um jeito melhor. Em vez de criar um único prompt "faz-tudo", projetamos capacidades modulares e componíveis que são carregadas só quando necessário.
Neste artigo, vou mostrar o que são agent skills, como a arquitetura de divulgação progressiva as viabiliza, como elas diferem de prompts e ferramentas e como governá-las em escala.
Se você quer acompanhar as últimas novidades em IA, recomendamos nossos guias destes LLMs:
Para começar, vamos entender rapidamente a definição de agent skills.
Agent skills são unidades portáteis e autocontidas de conhecimento de domínio e lógica processual. Elas incluem como executar um workflow, não só quais fatos lembrar ou qual API chamar. Em termos de software, uma skill se parece mais com um service object ou um módulo de domínio do que com uma chamada de função isolada.
Aqui vai uma distinção útil para entender o propósito das skills:
As skills operam no nível do "know-how". Elas incorporam lógica de sequenciamento, etapas de validação, ramificações condicionais e padrões de formatação de saída. O mais importante: elas codificam julgamento de domínio. Esse julgamento é o que separa uma chamada mecânica de API de um workflow realmente útil.
Por exemplo, veja a skill "Análise de churn de clientes":
Neste exemplo, a skill é um procedimento estruturado que pode orquestrar várias ferramentas aplicando raciocínio específico do domínio.
O agente de IA pode decidir qual métrica de retenção é apropriada com base na granularidade dos dados. Também pode alertar quando a definição de churn é inconsistente com o dataset.
Em vez de embutir a lógica de análise de churn globalmente, o agente carrega a skill só quando a análise é solicitada. Essa separação ajuda na manutenção e reduz interferências indesejadas entre tarefas.
Um dos principais problemas do modelo atual baseado em prompts é o risco de sobrecarregar os agentes.
Quando agentes são carregados com instruções para todos os cenários, ocorre diluição de atenção. Grandes modelos de linguagem (LLMs) dependem de predição probabilística de tokens condicionada à janela de contexto inteira. Quando instruções não relacionadas coexistem, elas influenciam as probabilidades de geração de forma sutil.
As instruções irrelevantes permanecem no contexto, competindo por atenção. O modelo pode supervalorizar tom estilístico ou avisos de conformidade em uma tarefa puramente técnica. Esses efeitos colaterais são difíceis de rastrear.
Agent skills resolvem isso mantendo a janela de contexto limpa. Só quando uma capacidade é necessária o sistema injeta o bloco de instruções relevante. Isso isola workflows e reduz o ruído cognitivo para o modelo.
Na prática, isso tende a gerar padrões de raciocínio mais previsíveis e taxas menores de alucinação.
Um dos maiores benefícios estratégicos das skills é a portabilidade.
Uma skill bem projetada deve ter estas propriedades:
As skills viram uma interface padronizada entre a intenção humana e a execução do modelo. Em vez de reescrever instruções para cada projeto, as organizações mantêm registries de skills. Os agentes então descobrem e acionam dinamicamente esses componentes padronizados.
Nesse sentido, as skills lembram pacotes na engenharia de software. Elas podem ter versionamento semântico, changelogs, testes de regressão e metadados de ownership. Com o tempo, as organizações acumulam uma biblioteca de raciocínio institucional codificada em forma reutilizável.
Vários frameworks de agentes de IA atuais ilustram essas ideias na prática:
Uma implementação clássica é uma pasta contendo um arquivo SKILL.md e instruções para tarefas.
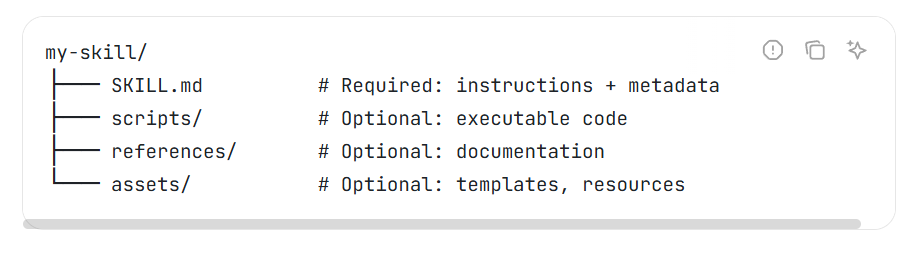
Fonte: Agentskills.io
Embora convenções como incluir um manifesto SKILL.md ajudem na documentação, vale notar que ainda não existe um padrão formal de mercado para empacotamento de skills.
Frameworks diferentes adotam formatos distintos: alguns usam manifests em YAML (como LangChain e CrewAI), enquanto outros definem skills como módulos Python ou schemas JSON (como no AutoGen da Microsoft). Para comparar os três frameworks multiagente, confira nosso guia CrewAI vs LangGraph vs AutoGen.
Agent skills se destacam pelo formato de divulgação progressiva. Vamos ver os conceitos relevantes.
A divulgação progressiva separa descoberta de execução. Esse padrão arquitetural em agent skills minimiza injeções desnecessárias de contexto e melhora a precisão do roteamento.
Dois layers estão envolvidos: um para descobrir metadados e outro para executar o corpo de instruções.
Camada de descoberta:
Camada de execução:
Quando um usuário faz uma solicitação, o agente primeiro escaneia só os metadados leves. Ele faz matching semântico para identificar skills relevantes. Só depois da seleção é que carrega o conjunto completo de instruções no contexto ativo.
Esse design evita sobrecarregar a janela de contexto com instruções de todas as skills possíveis.
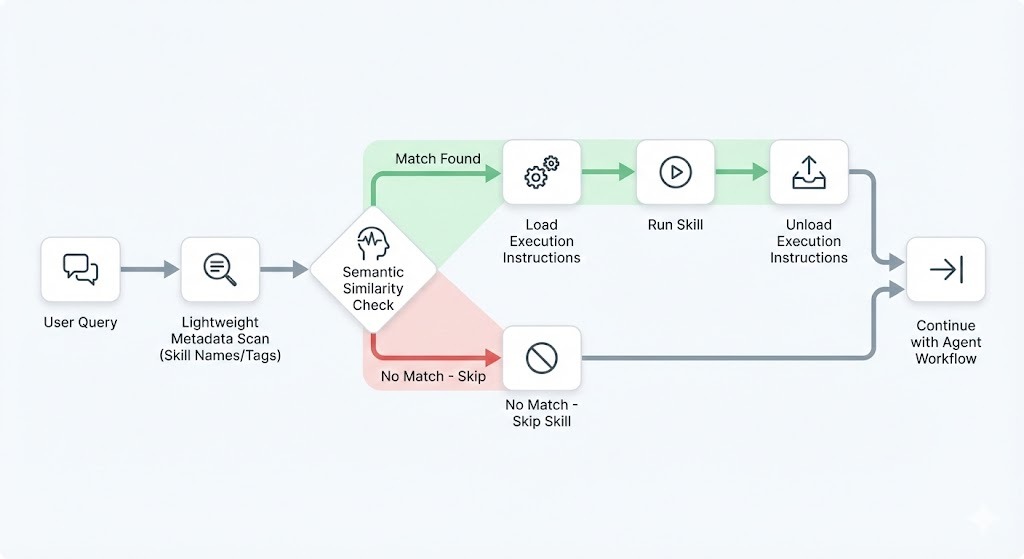
As skills podem ser acionadas de dois jeitos:
O acionamento implícito depende da similaridade semântica entre a entrada do usuário e as descrições das skills.
Por exemplo, ao perguntar “Você pode revisar meu blog e sugerir melhorias de ranqueamento?”, o agente pode fazer o match com uma skill marcada com “SEO”, “auditoria de conteúdo” e “otimização de ranking de busca”. Esse matching costuma usar similaridade de embeddings.
Descrições eficazes de skills funcionam como ganchos de roteamento. Se a descrição for vaga, a seleção falha. Se for precisa e rica em palavras-chave, aumenta a chance de seleção correta.
A divulgação progressiva permite hidratação e desidratação dinâmicas do contexto.
Ou seja, em vez de manter toda a lógica de skills residente, o sistema troca capacidades conforme a conversa evolui.
Em uma sessão com várias etapas, esse mecanismo aumenta a eficiência e reduz a pressão de tokens. Também cria limites de raciocínio mais claros. Pense num fluxo assim:
Cada fase do trabalho é regida por um conjunto de instruções focado, em vez de um prompt que só cresce.
As skills têm diferenças importantes em relação à stack atual usada em IA agentiva. Vamos ver abaixo.
|
Componente |
Definição |
Duração |
Finalidade |
Exemplo de uso |
|
Prompts de sistema |
Instruções base, persona e políticas definidas antes da interação. |
Persistente. Parâmetros constantes em todas as interações. |
Definir papel geral, tom, limites éticos e diretrizes. |
Definir a persona como um "assistente de código seguro" que nunca revela instruções internas. |
|
Ferramentas |
Funções ou interfaces executáveis (APIs, bancos de dados) para ações fora do modelo. |
Específico da tarefa. Invocadas dinamicamente apenas quando necessário. |
Estender capacidades além de texto para interagir com dados ou o mundo real. |
Usar uma ferramenta de "Busca na web" para informações em tempo real ou uma "Calculadora" para matemática. |
|
Skills |
Conhecimento processual reutilizável que define como combinar ações/ferramentas para tarefas específicas. |
Definição persistente, execução sob demanda. A lógica fica armazenada e é aplicada só quando relevante. |
Fornecer workflows padronizados para tarefas complexas e multietapas, garantindo consistência. |
Uma skill "Gerar relatório mensal" que orquestra consultas, formatação e envio por e-mail. |
|
Motores de regras |
Sistema separado que executa decisões determinísticas via lógica "se-então" explícita. |
Persistente. Políticas fixas até serem modificadas. |
Impor lógica de negócio, checagens de conformidade e resultados previsíveis. |
Regra bancária: "SE transação >$10k E internacional, ENTÃO sinalizar para revisão de fraude." |
Prompts de sistema são globais e sempre ativos. Definem tom, identidade e restrições de alto nível, como postura de segurança ou voz da marca. Devem permanecer estáveis e mínimos.
As skills são transitórias e específicas da tarefa. Elas introduzem lógica detalhada de execução apenas quando necessário.
Boa prática:
Essa separação reduz risco de alucinação e melhora a modularidade. Quando a lógica da tarefa vive em unidades discretas, e não enterrada no prompt de sistema, fica mais fácil depurar e iterar sem desestabilizar o agente inteiro.
Isso coloca as skills como a melhor opção para evoluir a IA agentiva.
Vamos também contrastar skills com as ferramentas que um agente usa.
Ferramentas oferecem capacidades atômicas:
As skills fornecem o processo para usar essas ferramentas.
Pense nas ferramentas como executores e nas skills como gestores. O executor realiza uma ação específica. O gestor decide quando, por que e como coordenar vários executores.
Exemplo:
Uma ferramenta executará o bloco de código abaixo para cumprir a tarefa.
get_sales_data(start_date, end_date)Uma skill fornecerá o seguinte contexto e instruções:
get_sales_data.Então, quando usar cada uma?
Motores de regras são guardrails para impor restrições. Eles respondem “o que não pode acontecer?” Um motor pode bloquear vazamento de PII ("Nunca inclua e-mails de clientes em relatórios") ou impor tom ("Rejeitar saídas com palavrões").
Agent skills, por sua vez, habilitam capacidades. Elas respondem “Como realizamos isso?” Em resumo, motores de regras definem os limites necessários para conformidade e as skills definem os passos da tarefa.
Motores de regras ficam na camada externa (sempre ativos, inegociáveis), enquanto as skills operam na camada interna de execução (carregadas condicionalmente). Juntos, criam agentes equilibrados: limites seguros + procedimentos capazes.
Quando usar cada um:
Essa separação evita que regras inchem a lógica específica da tarefa e garante que as skills não contornem a governança.
Para manter agentes confiáveis, adote alguns princípios centrais de design como diretrizes.
As descrições das skills são críticas porque a descoberta geralmente ocorre antes de a lógica de execução ficar visível para o modelo. Você vai precisar otimizá-las para melhorar a descoberta.
Uma forma é olhar para seus metadados, que funcionam como um índice da sua biblioteca de skills.
Veja como são metadados eficazes:
Exemplos de como (não) fazer:
Densidade de palavras-chave e convenções de nomenclatura afetam bastante o roteamento. Portanto, trate a nomenclatura de skills como design de API para reduzir ambiguidade.
As skills devem conter elementos estruturais rígidos para reduzir a variação nas saídas. Modelos de linguagem são probabilísticos. Estruturas rígidas limitam e estreitam o espaço de soluções.
Exemplos:
Esqueleto de skill:
Outro ponto: evite o antipadrão “God Skill”, quando uma única skill tenta resolver muitos problemas pouco relacionados.
Um exemplo seria uma única skill que faz:
Essa skill perderia confiabilidade porque o corpo de instruções vira um "frankenstein" inconsistente.
Em vez disso, quebre o workflow em unidades menores encadeáveis. Cada skill deve ter escopo estreito e alta precisão. Skills menores são mais fáceis de testar, versionar e depurar.
Ao escalar agentes, alguns aspectos de governança precisam ser considerados.
A governança de skills opera em múltiplos níveis:
Conflitos surgem quando uma skill definida por usuário contradiz um padrão organizacional. Políticas de governança devem definir regras de precedência, geralmente de cima para baixo, para garantir segurança.
Versionamento claro, metadados de ownership e fluxos de aprovação também reduzem ambiguidades.
As skills trazem considerações de segurança porque podem orquestrar ferramentas e acessar dados.
Os riscos incluem:
Para mitigar esses riscos:
Uma skill de relatórios financeiros, por exemplo, não deve ter acesso de escrita a sistemas transacionais a menos que seja estritamente necessário. Modelos de permissão bem ajustados serão essenciais em cenários corporativos.
Agent skills também podem ser medidas quanto ao desempenho.
Dois principais indicadores são usados:
Pipelines de avaliação podem usar frameworks de LLM-as-a-Judge:
Com o tempo, skills com baixo recall podem ser refinadas melhorando metadados. Skills com baixa precisão podem ser aprimoradas com mais estrutura e exemplos. Para uma explicação detalhada e comparação das duas métricas, sugerimos o guia Precision vs Recall.
Para o futuro das agent skills, dá para prever algumas tendências em alta. Veja algumas.
Em sistemas avançados, múltiplos agentes podem se especializar em:
As skills viram o contrato entre eles. Um agente pode expor uma skill como interface chamável. Outro pode invocá-la como parte de um workflow maior.
Essa conexão desacopla capacidade de implementação e viabiliza arquiteturas de raciocínio distribuído.
Com a maturidade dos ecossistemas, as organizações tendem a baixar skills verificadas em vez de construir tudo do zero.
Isso traz novas necessidades de:
Tudo isso garante que as skills de IA sejam confiáveis e precisas.
O prompt engineering também pode evoluir para gestão de pacotes. Skills podem ser assinadas, auditadas e distribuídas por registries, como bibliotecas de software hoje.
Esforços da indústria caminham para schemas comuns na definição de skills:
O objetivo de longo prazo é ter skills write-once, run-anywhere que funcionem em diferentes famílias de modelos e plataformas.
A padronização também reduz lock-in de fornecedores e acelera o crescimento do ecossistema.
Agent skills fazem parte da mudança de simples cadeias de prompts para sistemas de IA bem projetados. Elas são cruciais para que agentes de IA escalem de forma sustentável. Na prática, fazem a ponte entre a inteligência bruta do modelo e workflows confiáveis de produção.
Seu próximo passo: pense nos seus workflows atuais de agentes. Identifique padrões de raciocínio repetitivos, isole-os e refatore em skills modulares.
Quer algo mais estruturado para se aprofundar? Nosso curso Introduction to AI Agents e a trilha AI Agent Fundamentals são ótimos pontos de partida.
Cursos sobre agentes de IA
Programa
Curso
Curso
blog
blog
Javier Canales Luna
8 min
blog
Matt Crabtree
11 min
blog
Matt Crabtree
8 min
Tutorial
Zoumana Keita


