
Curso
Inferência para Regressão Linear em R
4 h
15.9K
Imagina que você está tentando prever a nota de alguém em uma prova com base em quantas horas ele estudou. E aí, como tá a sua previsão em relação aos resultados reais? É isso que o coeficiente de determinação, também conhecido comoR² (R-quadrado), nos diz.
Isso mostra quanto da mudança em uma coisa (como notas em provas) pode ser explicada por mudanças em outra (como horas de estudo). Assim, você consegue entender como o seu modelo “se encaixa” nos dados.
Neste artigo, vamos te ajudar a entender o que éR², por que é importante e como calcular e interpretar, mesmo que você seja novo no mundo da estatística.
O coeficiente de determinação, geralmente escrito comoR² (R-quadrado), é um número que nos diz o quão bem um modelo de regressão explica o que está acontecendo nos dados. Isso mostra o quanto da mudança no resultado (variável dependente) pode ser explicada pelas coisas que estamos usando para prever isso (variável(is) independente(s)).
Imagina que você quer adivinhar o peso de alguém com base na altura dele. SeR² estiver perto de 1, sua previsão está indo muito bem. A maioria das diferenças de peso pode ser por causa das diferenças de altura. SeR² estiver perto de 0, então sua previsão é basicamente um palpite, porque, nesse caso, a altura não explica muito da mudança no peso.
A gente espera valoresde R² entre 0 e 1:
0 quer dizer que o modelo não explica nada da variação nos dados.
1 significa que o modelo explica toda a variabilidade.
Valores mais próximos de 1 significam um ajuste melhor, o que mostra que seu modelo está capturando mais do padrão nos dados.
Quando você tá trabalhando só com uma variável independente, o modelo é chamado de regressão linear simples. Nesse caso,R² tem uma relação direta com o coeficiente de correlação de Pearson (r): R² = r²
Isso quer dizer que, se tiver uma forte correlação positiva ou negativa entre o seu preditor e o resultado,o R² vai ser alto.
Observação: Em modelos com mais de um preditor (chamados de regressão múltipla),R² ainda mostra a variação explicada, mas não é mais sór², porque agora você está juntando os efeitos de várias variáveis.
R² geralmente varia de 0 a 1. Mas, às vezes, você pode ver um R² negativo. Isso pode acontecer se:
UmR² negativo quer dizer que seu modelo tá indo pior do que adivinhar a média. Em outras palavras, não combina com os dados de jeito nenhum, o que acaba sendo meio enganador.
Tem duas maneiras comuns de calcularo R²:
Vamos ver os dois.
A fórmula mais comum paraR² é:

Aqui, a soma residual dos quadrados (a parte que não foi explicada) mostra o quanto os valores reais estão longe dos valores previstos pelo seu modelo. É o erro que o seu modelo faz.
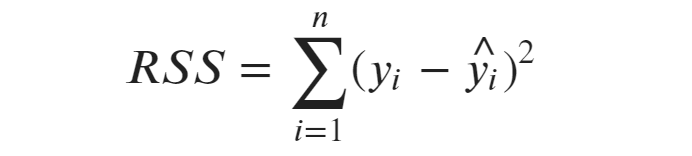
A soma total dos quadrados é a variação total nos dados observados. Isso mostra o quanto os valores reais estão longe da média da variável dependente.
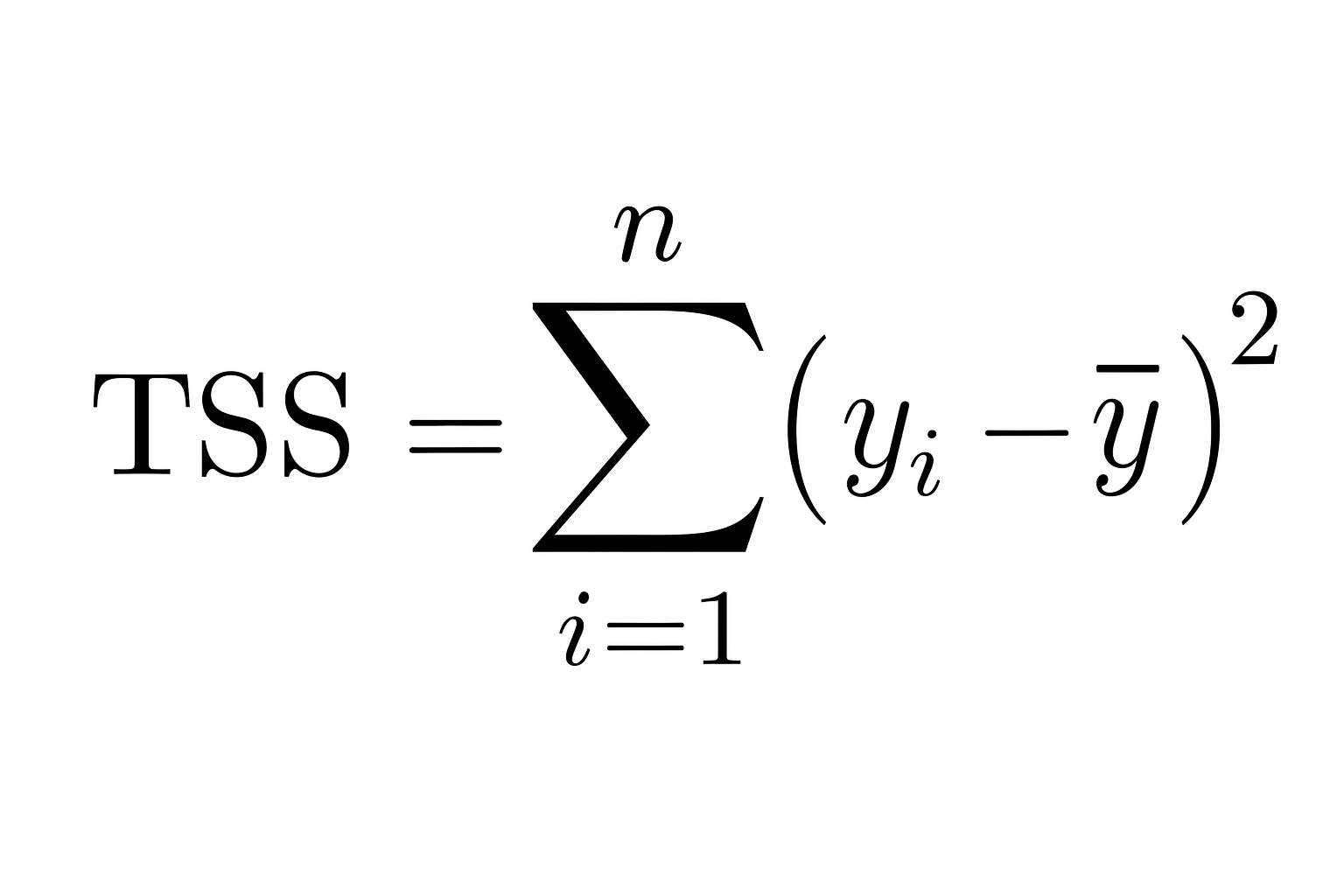
Então, quanto menor a soma dos quadrados residuais em relação à soma dos quadrados totais, melhor o seu modelo se encaixa nos dados e mais próximo de 1 ficao R ².
Vamos entender isso com um exemplo:
Imagina que você tem um pequeno conjunto de dados com os seguintes valores:
|
Observação |
Real |
Previsão |
|
1 |
10 |
12 |
|
2 |
12 |
11 |
|
3 |
14 |
13 |
Primeiro, calcula a média dos valores reais:
Depois, soma a soma dos quadrados (a distância dos valores reais da média):
Depois, calcula a soma dos quadrados residuais (a diferença entre os valores reais e os valores previstos):
Agora, junta isso à fórmula:
Então,R² = 0,25, o que quer dizer que o modelo explica 25% da variação nos dados.
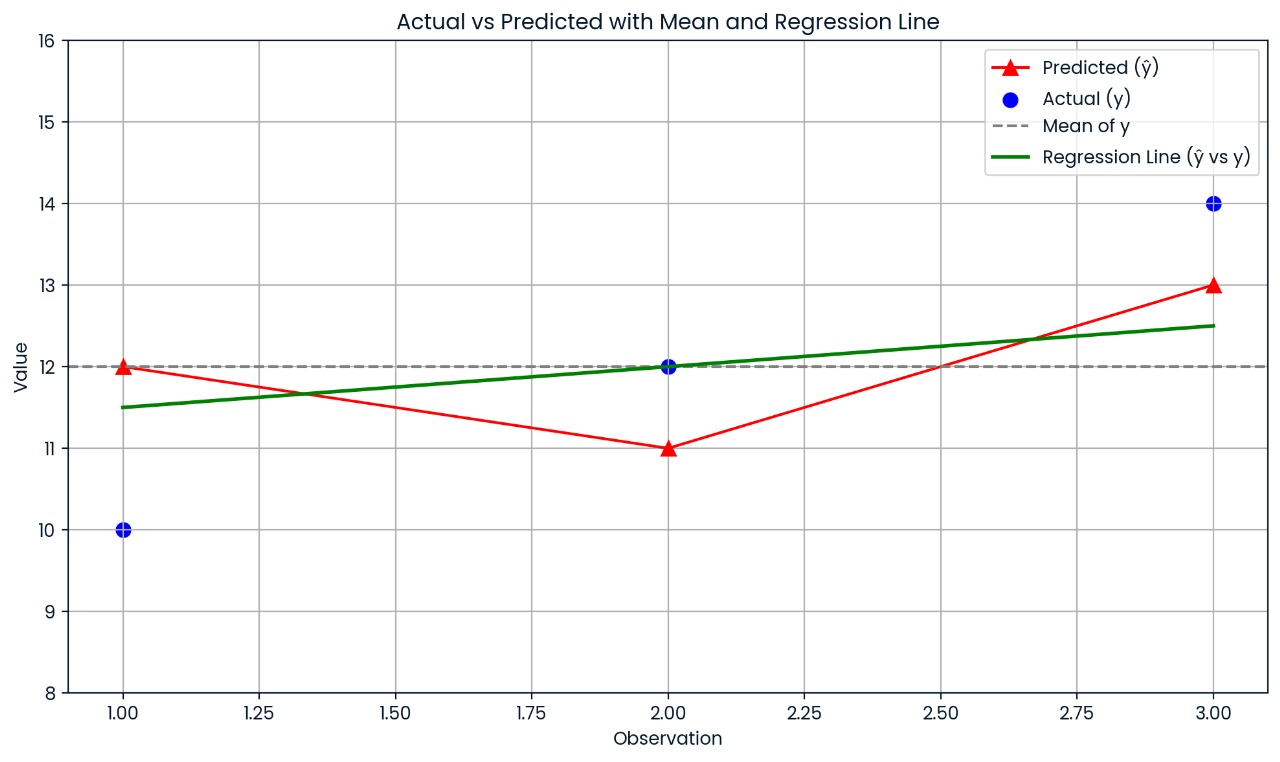
Esse gráfico mostra a distância entre cada valor real e o valor previsto. As previsões do modelo estão bem erradas, e é por isso que o R² é só 0,25; só 25% da variação é explicada.
Se você estiver usando regressão linear simples (apenas uma variável independente), use esta fórmula:
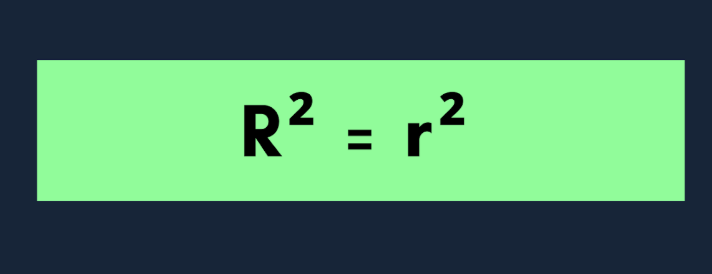
Aqui, r é o coeficiente de correlação de Pearson entre os valores reais e os valores previstos. Esse atalho só funciona quando tem um único preditor.
Digamos que a correlação entre X e Y seja: r = −0,8
Mesmo que a correlação seja negativa (o que significa que as variáveis se movem em direções opostas),R² é positivo: R² = (−0,8)² = 0,64
Então, 64% da variação no resultado ainda pode ser explicada pelo preditor, mesmo que a relação seja negativa. É por isso queR² é sempre positivo ou zero; representa a quantidade de variação explicada, não a direção.
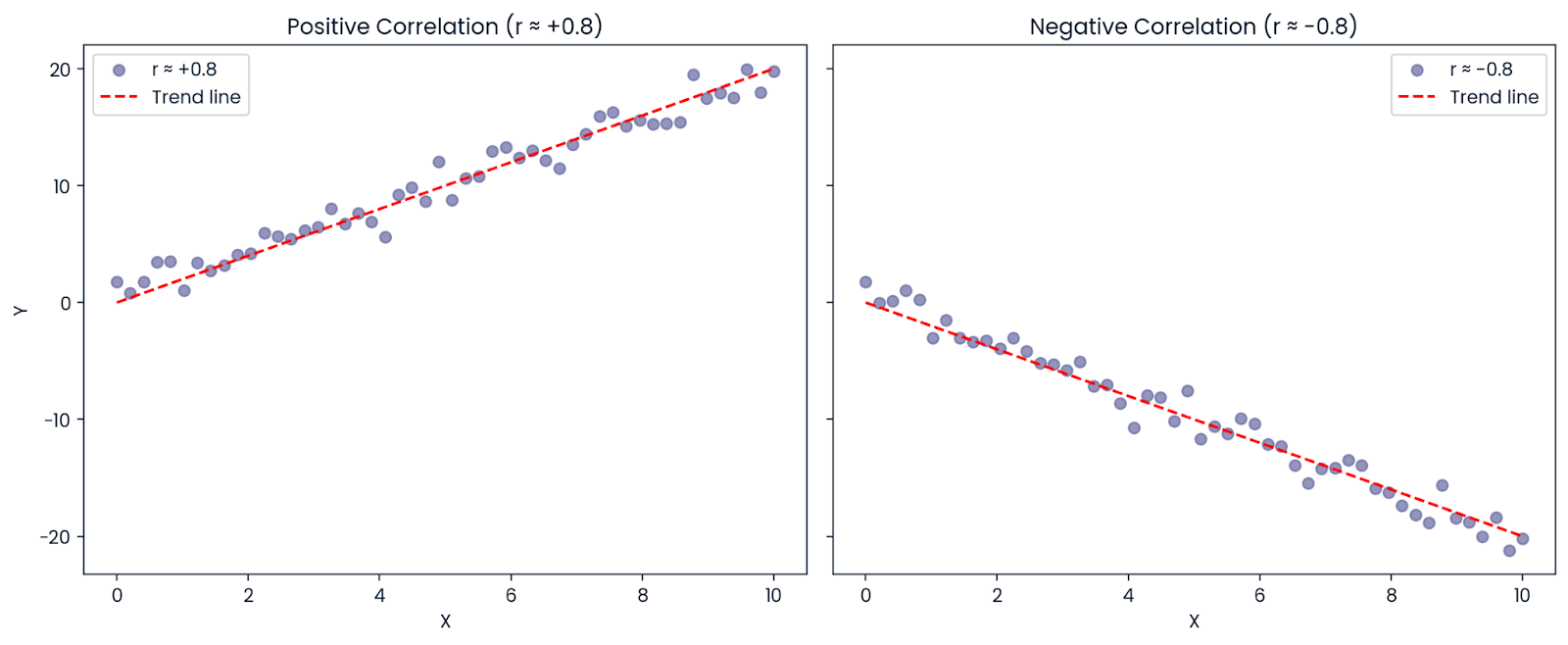
Correlação positiva e negativa. Imagem do autor.
O coeficiente de determinação mostra quanto da variação no resultado (variável dependente) é explicada pelo nosso modelo. Em termos simples, é como perguntar: “Quanto das mudanças que estou tentando prever podem ser explicadas pelos dados que estou usando?”
Digamos que você está criando um modelo pra prever as notas dos alunos nos exames com base em quantas horas eles estudam. Se o seu modelo te der: R² = 0,90
Isso quer dizer que 90% das diferenças nas notas dos exames podem ser explicadas pelas diferenças no tempo de estudo. Os outros 10% vêm de outros fatores que seu modelo não incluiu, como sono, habilidade natural, conhecimento prévio ou dificuldade do teste.
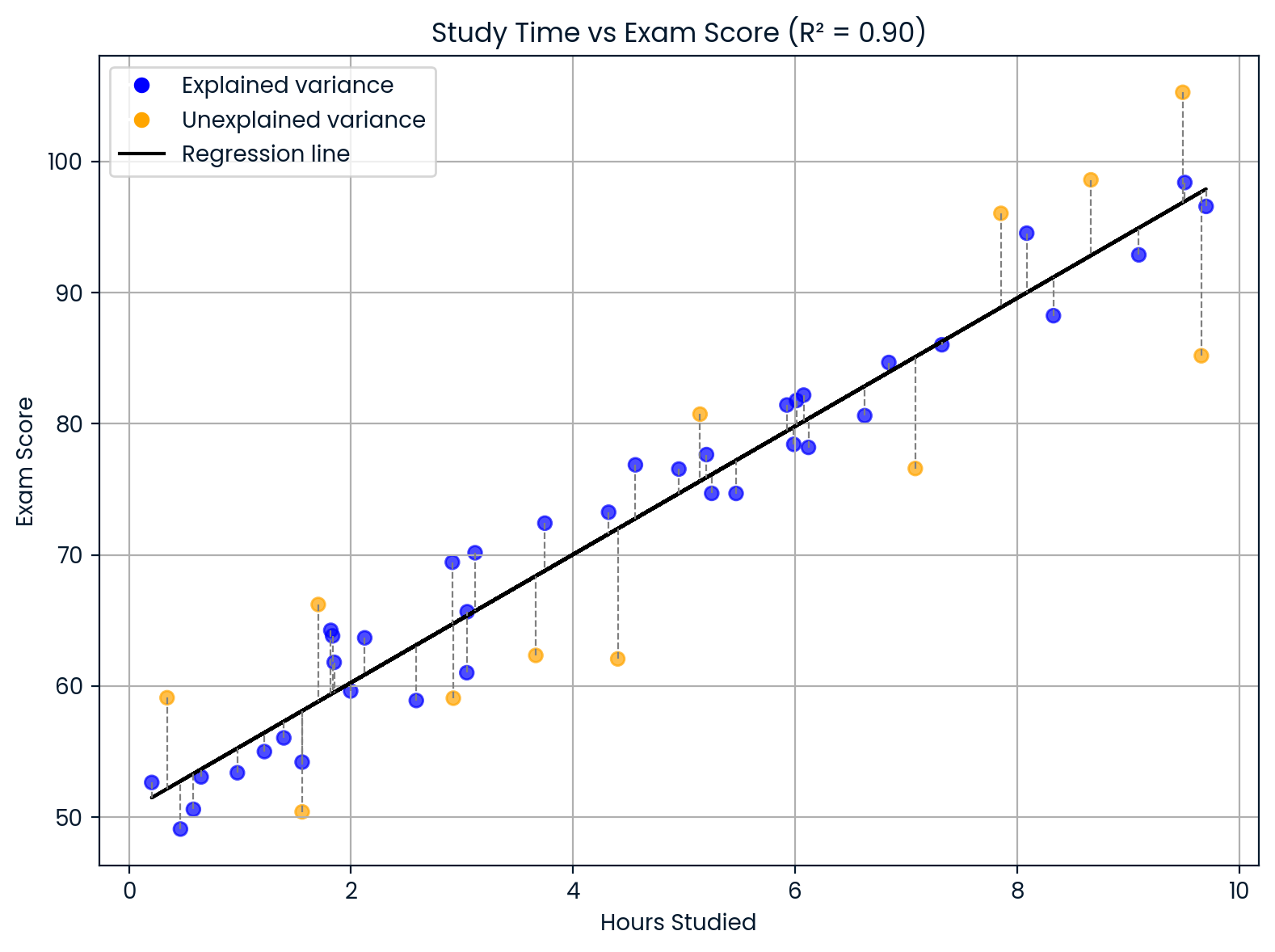
Interpretando o coeficiente de determinação. Imagem do autor.
Esse gráfico mostra como o tempo de estudo afeta as notas dos exames.
Jacob Cohen criou um guia super útil pra ajudar a entender o que os diferentes valoresde R² podem significar quando a gente tá interpretando a força de uma relação.
Aqui estão os parâmetros de referência aproximados de Cohen paraR²:
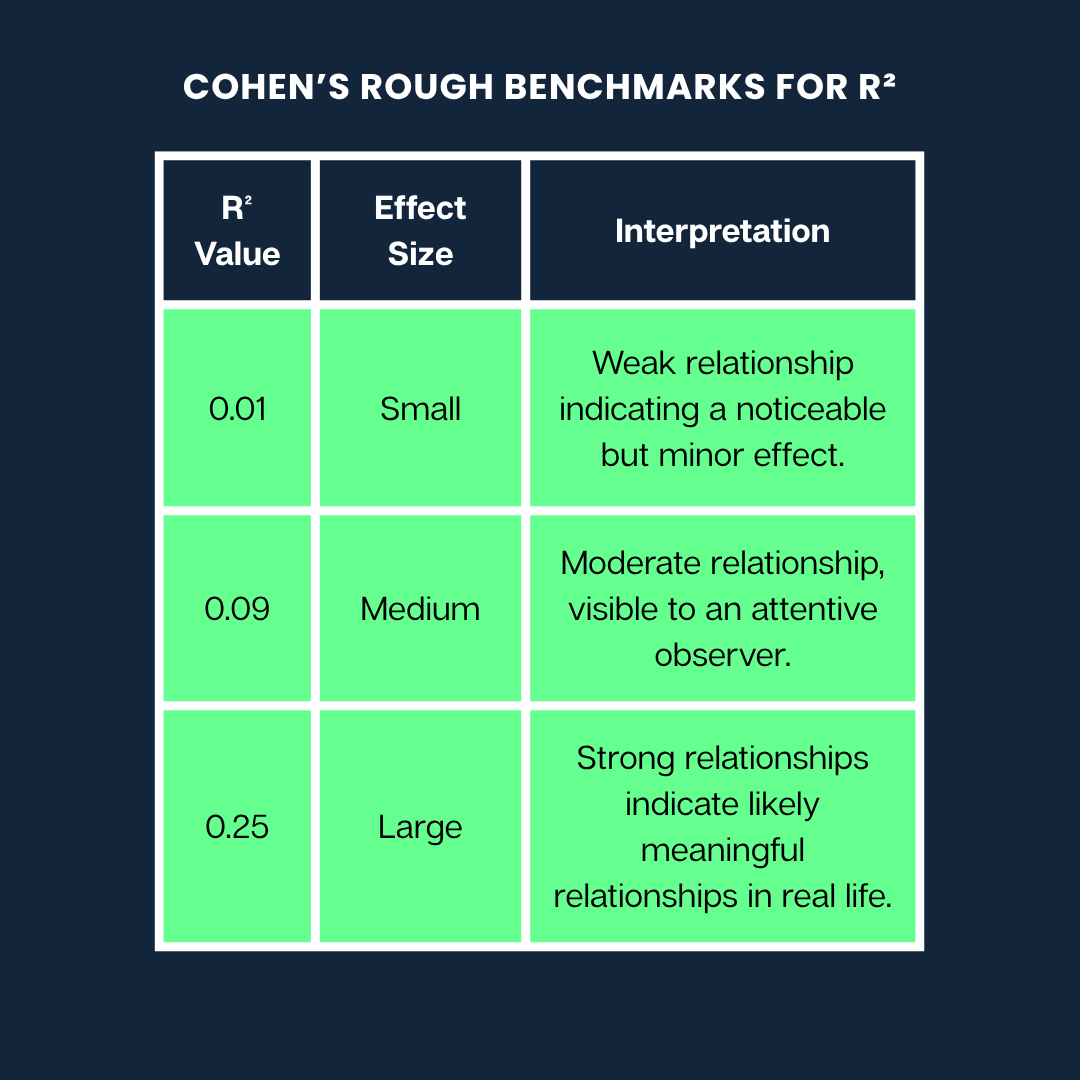
Os parâmetros aproximados de Cohen. Imagem do autor
Observação: Essas são só algumas dicas gerais. O que é considerado um efeito “grande” ou “pequeno” pode variar bastante dependendo da área (por exemplo, psicologia versus engenharia) e do contexto da pesquisa.
Emborao R² seja útil, é importante entender o que ele pode e não pode dizer. Aqui estão alguns equívocos e limitações comuns a serem observados:
Pode parecer que umR² mais alto sempre significa um modelo melhor, mas isso não é necessariamente verdade. O R² sempre aumenta ou fica igual quando você adiciona mais variáveis a um modelo, mesmo que essas variáveis não tenham nada a ver com ele.
Por quê?
Porque o modelo tem mais flexibilidade para se ajustar aos dados de treinamento, mesmo que seja apenas ajustando ruídos aleatórios. Isso pode fazer com que o modelo fique superajustado, ou seja, ele vai parecer ótimo nos dados que usou pra treinar, mas vai funcionar mal com dados novos.
Dica: Ue o R² ajustado ao comparar modelos com diferentes números de preditores. Isso penaliza a complexidade desnecessária e pode ajudar a detectar o sobreajuste.
R² só mede o quão bem o modelo descreve os dados que você já tem. Não diz:
UmR² alto pode até acontecer por acaso se você estiver usando muitos preditores. Portanto, sempre dê uma olhada em outras métricas de avaliação de modelos (como RMSE ou MAE para qualidade de previsão) e lembre-se: correlação não é causalidade.
Às vezes, em sistemas complexos (como prever o comportamento humano ou os mercados financeiros), é normal ter umR² baixo.
Por exemplo, se você estiver modelando algo influenciado por muitos fatores imprevisíveis ou não mensuráveis, seu modelo ainda pode ser útil, mesmo com umR² baixo. Pode capturar uma tendência importante ou dar uma ideia, mesmo que não explique grande parte da variação.
Em pesquisas médicas ou psicológicas, é comum ver valores baixosde R², porque os resultados das pessoas dependem de muitas variáveis que interagem entre si.
EmboraR² ajude a entender como o modelo se encaixa na regressão linear, existem outras variantes e generalizações que ajudam em diferentes contextos de modelagem.
Assim como oR² normal,o R² ajustado mostra quanto da variação na variável dependente é explicada pelo modelo. Mas vai além, penalizando a complexidade desnecessária. Em outras palavras, isso evita que você encha seu modelo com preditores extras que não ajudam em nada.
A fórmula é:
Adjusted R² = 1 - [ (1 - R²) × (n - 1) / (n - p - 1) ]Aqui:
n é o número de observações (pontos de dados)
p é o número de preditores (variáveis independentes)
A fórmula ajustao R² pra baixo se uma nova variável não melhorar o modelo. Essa penalidade fica mais forte conforme você adiciona mais preditores.
Por exemplo, se você adicionar uma nova variável que melhora a precisão do seu modelo,o R² ajustado vai subir. Mas se essa variável não mudar quase nada ou só ajudar por acaso,o R² ajustado vai cair, te alertando sobre um possível sobreajuste.
Isso tornao R² ajustado útil para comparar modelos.
Digamos que você queira escolher entre um modelo mais simples com três preditores e um mais complexo com seis. Mesmo que o modelo complexo tenha umR² um pouco maior, oR² ajustado pode ser menor, o que mostra que não vale a pena ter mais complexidade.
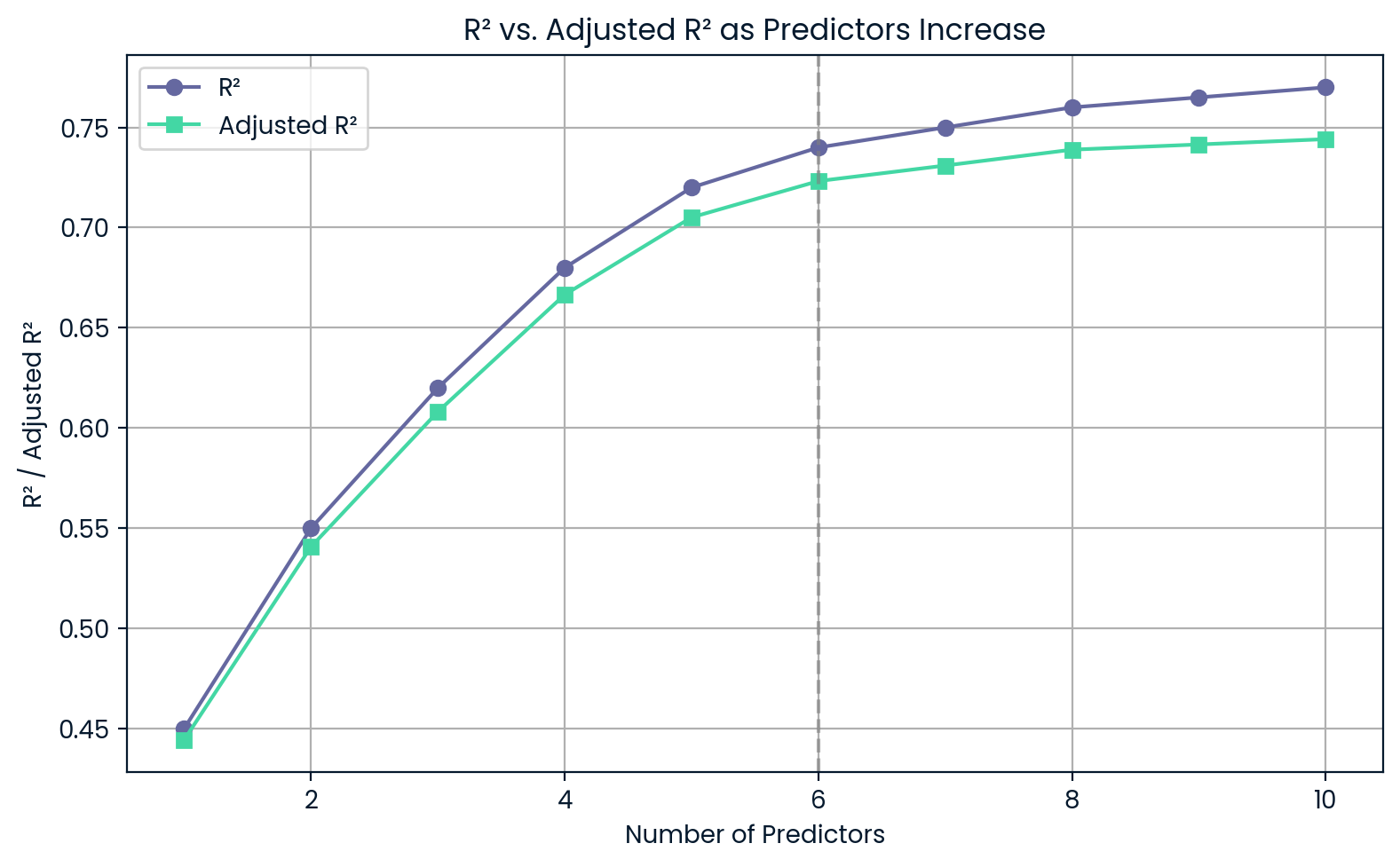
R² versus R² ajustado à medida que os preditores aumentam. Imagem do autor.
Esse gráfico mostra que, conforme você adiciona mais preditores,o R² continua subindo, mesmo que esses preditores não sejam muito úteis. Por outro lado,o R² ajustado cai se você adicionar demais, alertando você sobre o excesso de ajuste.
O R² parcial (ou coeficiente de determinação parcial) mostra quanto da variação adicional na variável dependente é explicada ao adicionar um preditor específico a um modelo que já inclui outros.
Para calcularo R² parcial, a gente compara dois modelos:
A fórmula parao R² parcial é baseada na redução da Soma dos Erros Quadrados (SSE) quando a nova variável é adicionada. Uma forma comum é:
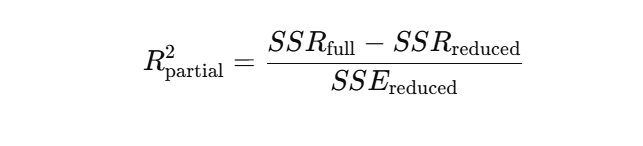
Ou em termos de somas dos quadrados da regressão:
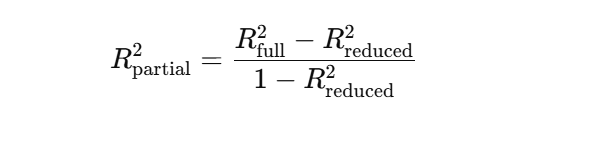
Imagina que você tá criando um modelo pra prever as vendas de um produto.
Você já tem “preço do produto” e “temporada” no modelo. Agora, você quer ver se adicionar “gastos com marketing” melhora as previsões. O R² parcial mostra quanto mais da variação nas vendas pode ser explicada incluindo os “gastos com marketing”.
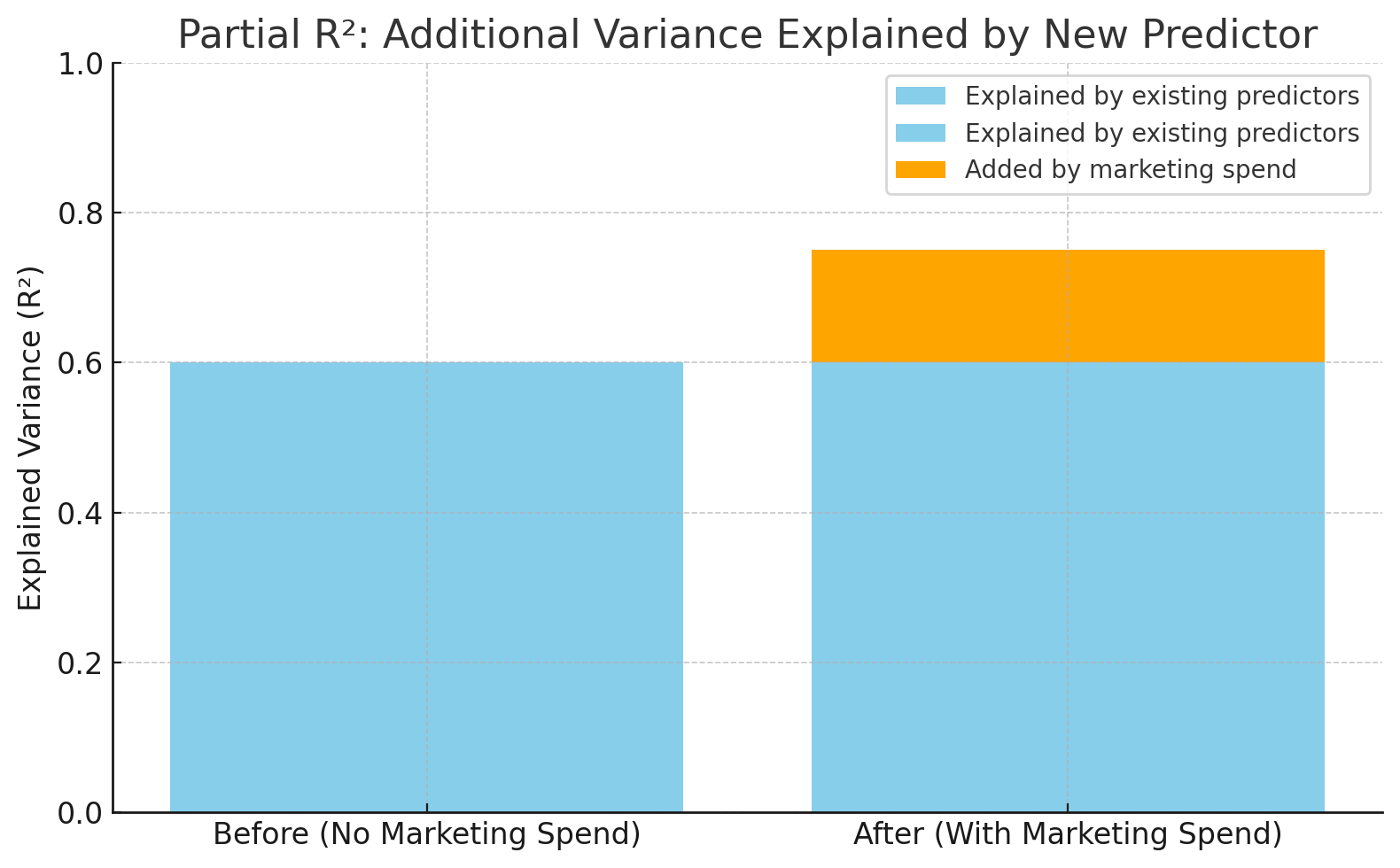
O R² aumentou de 0,60 para 0,75 depois de adicionar os gastos com marketing. Imagem do autor.
Esse gráfico mostra como o modelo fica mais preciso quando a gente adiciona os “gastos com marketing”. R² vai de 0,60 para 0,75, o que significa que a nova variável explica 15% a mais da variação nas vendas — isso é o R² parcial.
Na regressão logística, a variável de resultado é categórica, tipo sim/não, aprovado/reprovado, entãoo R² tradicional não rola. Em vez disso, usamos métricaspseudo-R², que têm uma função parecida: estimar o quão bem o modelo explica a variação nos resultados.
Dois valorespseudo-R² comuns são:
Imagina que você tá tentando descobrir se um cliente vai clicar num anúncio (sim/não). Como o resultado é binário, você não pode usar o R² normal. Mas valorespseudo-R², como o de Nagelkerke, ajudam a comparar modelos logísticos e avaliar seu poder preditivo, mesmo que não sejam diretamente equivalentes aoR² na regressão linear.
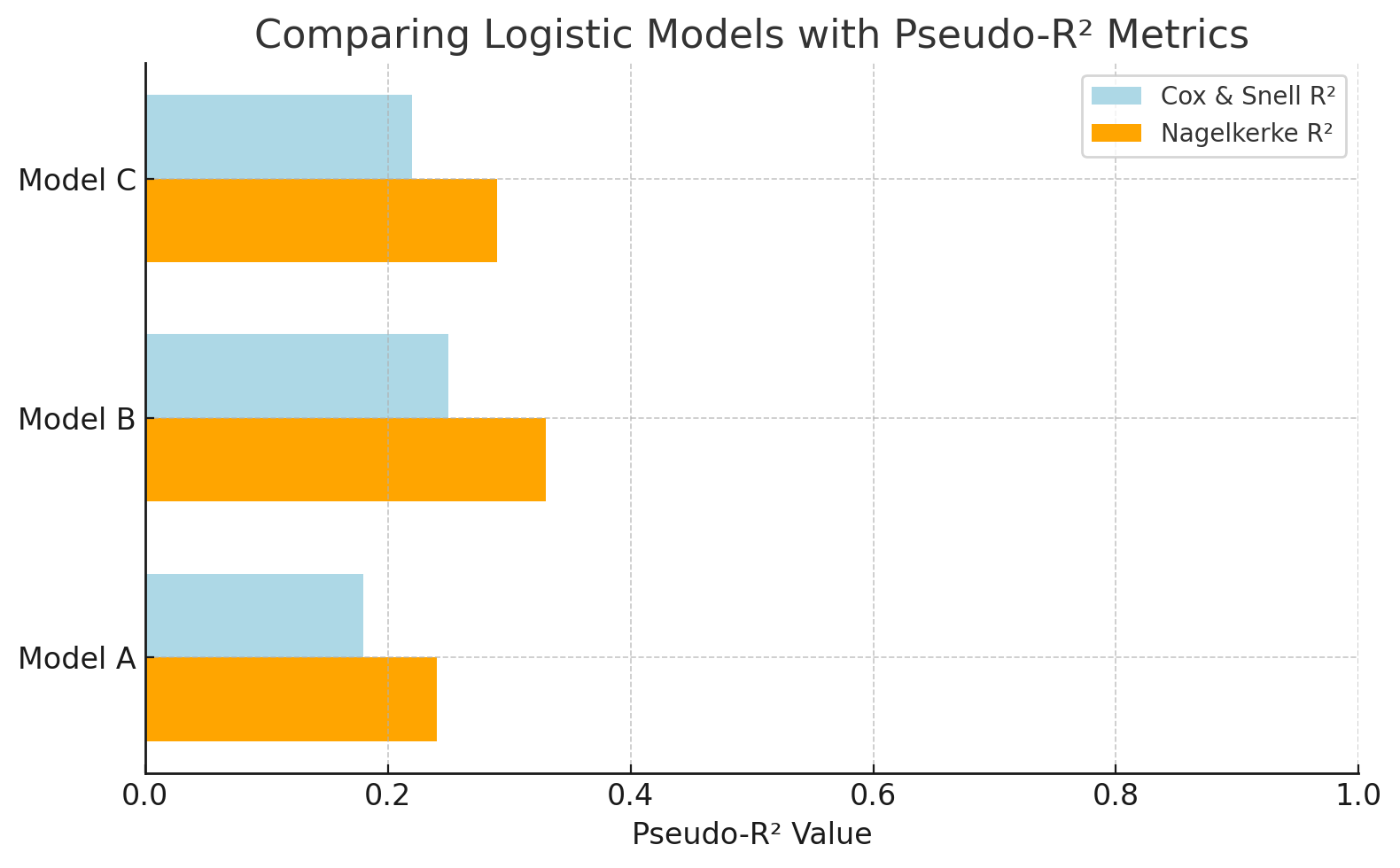
Compare modelos de logística com métricaspseudo-R ². Imagem do autor.
Este gráfico compara modelos de regressão logística usando valorespseudo-R ². O R² de Nagelkerke é uma escala mais fácil de entender do que a de Cox e Snell. Isso facilita a avaliação do desempenho de cada modelo na explicação do resultado (por exemplo, previsão de cliques em anúncios).
EmboraR² seja útil para entender quanta variação é explicada, ele não mede o quão distantes estão suas previsões. É aí que entram métricas baseadas em erros, como RMSE, MAE e MAPE.
Aqui vai uma comparação rápida:
|
Metrico |
O que isso te diz |
Melhor usado quando |
Cuidado com |
|
R² |
% da variação explicada |
Comparando modelos lineares, interpretabilidade |
Pode ser enganoso se os resíduos não estiverem normais ou se o modelo não for linear. |
|
RMSE |
Punir erros graves |
Priorizar erros que causam um grande impacto (por exemplo, ciência, ML) |
Sensível a valores atípicos |
|
MAE |
Erro médio (absoluto) |
Rastreamento de erros simples e robusto (por exemplo, finanças) |
Menos sensível a erros grandes |
|
MAPE |
% de erro em relação ao valor real |
Previsão, configurações de negócios |
Interrompe quando os valores reais estão próximos de zero. |
|
Resíduos normalizados |
Erro ajustado pela variação |
Regressão ponderada, confiabilidade variável da medição |
Precisa saber as variações de erro |
|
Qui-quadrado |
Resíduos vs. variância conhecida |
Ciências, testes de adequação |
Presume normalidade e estrutura de erro conhecida. |
Agora, vamos dar uma olhada em alguns dos muitos casos em que o coeficiente de determinação foi usado.
Em economia,o R² é usado pra explicar mudanças em indicadores gerais, tipo o Produto Interno Bruto (PIB). Por exemplo, um modelo pode incluir variáveis como taxas de juros, gastos do consumidor e balanças comerciais para prever o PIB.
Se esse modelo der umR² de 0.83, quer dizer que 83% da variação no PIB pode ser explicada por esses fatores econômicos. Isso ajuda os economistas a entender quanto das altas e baixas do PIB pode ser atribuído a fatores conhecidos.
Um estudo da Associação Nacional de Centros de Recursos para a Saúde ( ) usou dados do U.S. e do PIB como variável independente para prever o índice S&P 500 e encontrou umR² de 0.83. Isso mostrou uma forte relação entre a atividade econômica e as tendências do mercado de ações.
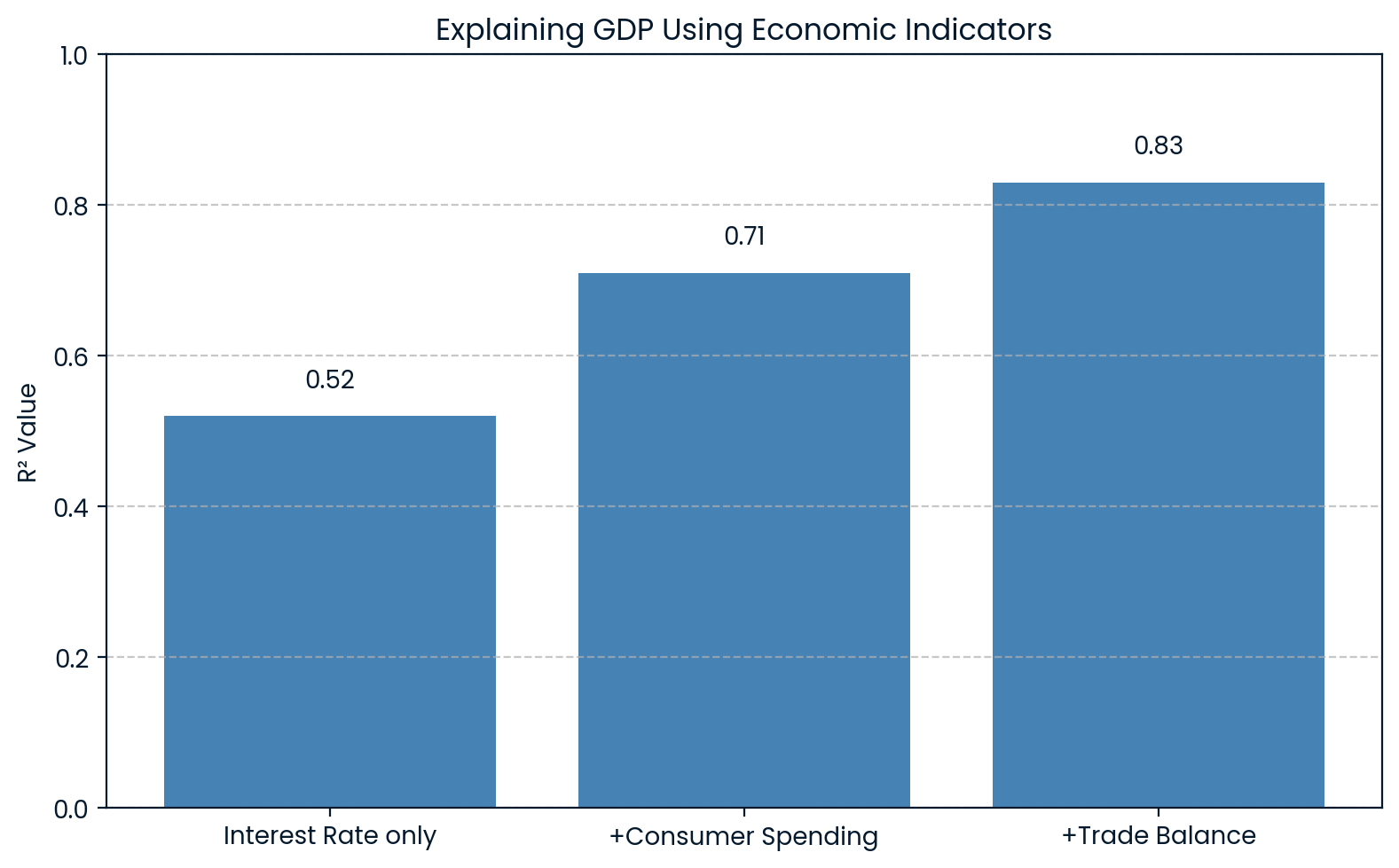
R² explicando a economia do PIB. Imagem do autor.
O gráfico mostra que, à medida que mais indicadores econômicos são adicionados ao modelo, oR² aumenta, de 0.52 para 0.83 com todas as três variáveis. Isso deixa claro que cada fator adicionado explica melhor as flutuações no PIB.
Em finanças,R² é usado pra medir o quanto os retornos de uma ação são explicados pelos movimentos gerais do mercado. Isso é feito comparando o retorno de uma ação com um índice de mercado, tipo o S&P 500.
Por exemplo, se você comparar os retornos da Apple (AAPL) com o S&P 500 e chegara R² = 0, 0.82, isso quer dizer que 85% dos movimentos dos retornos da Apple são explicados pelo mercado em geral.
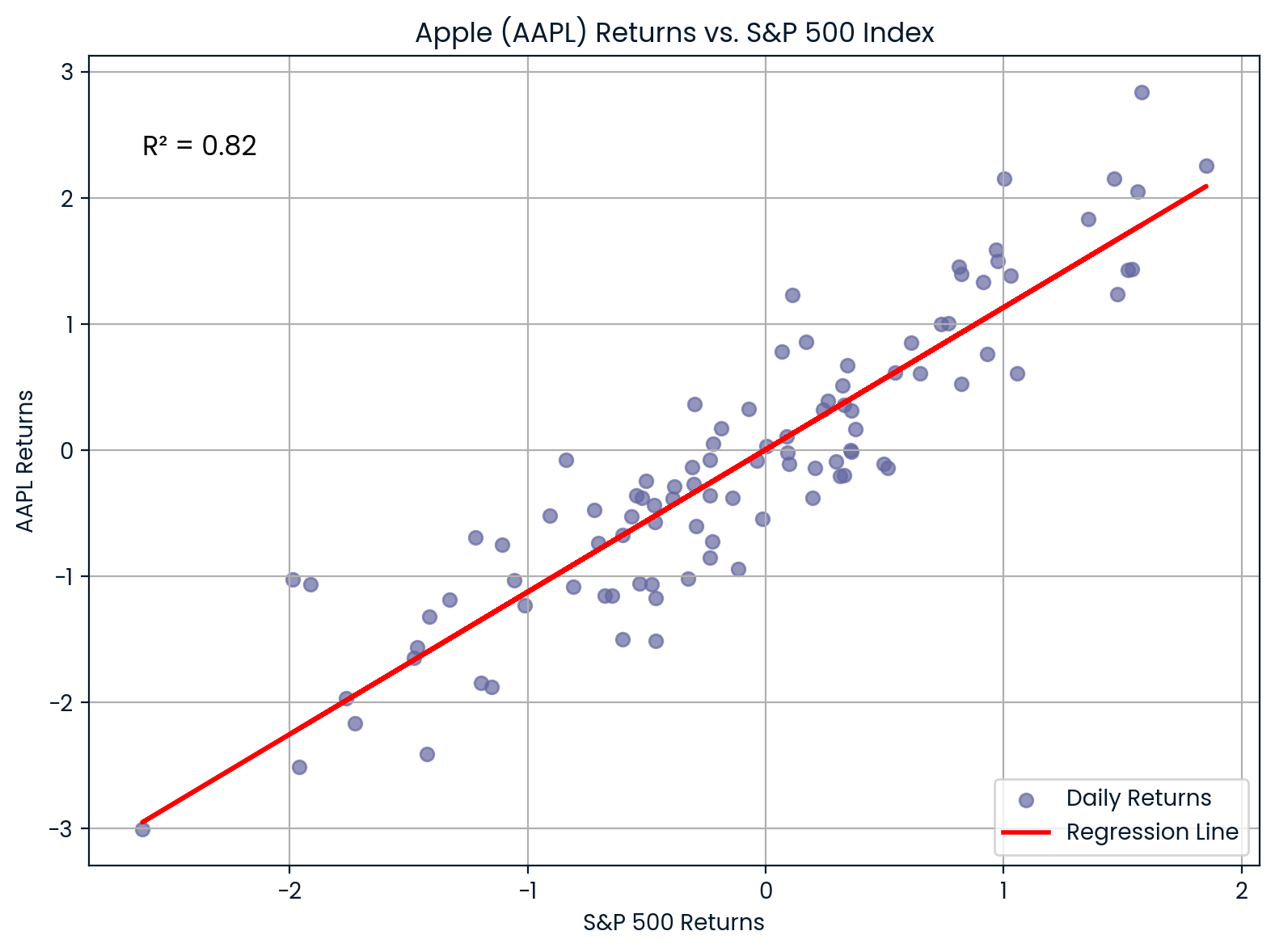
Correlação entre AAPL e S&P 500. Imagem do autor.
O gráfico mostra a forte correlação entre a Apple (AAPL) e o S&P 500. Com umR² de 0.82, a maioria dos movimentos de preço da Apple está bem alinhada com as tendências do mercado, mostrando uma alta sensibilidade ao mercado.
No marketing,R² mostra como os gastos com publicidade explicam as taxas de conversão dos clientes.
Imagina que você trabalha numa empresa de comércio eletrônico e quer saber se aumentar os gastos mensais com publicidade melhora as taxas de conversão. Você faz uma regressão linear e descobre queR² = 0,98. Isso quer dizer que 98% da variação na taxa de conversão é explicada pelo seu gasto com anúncios, o que mostra uma relação bem forte.
Essas informações ajudam os profissionais de marketing a:
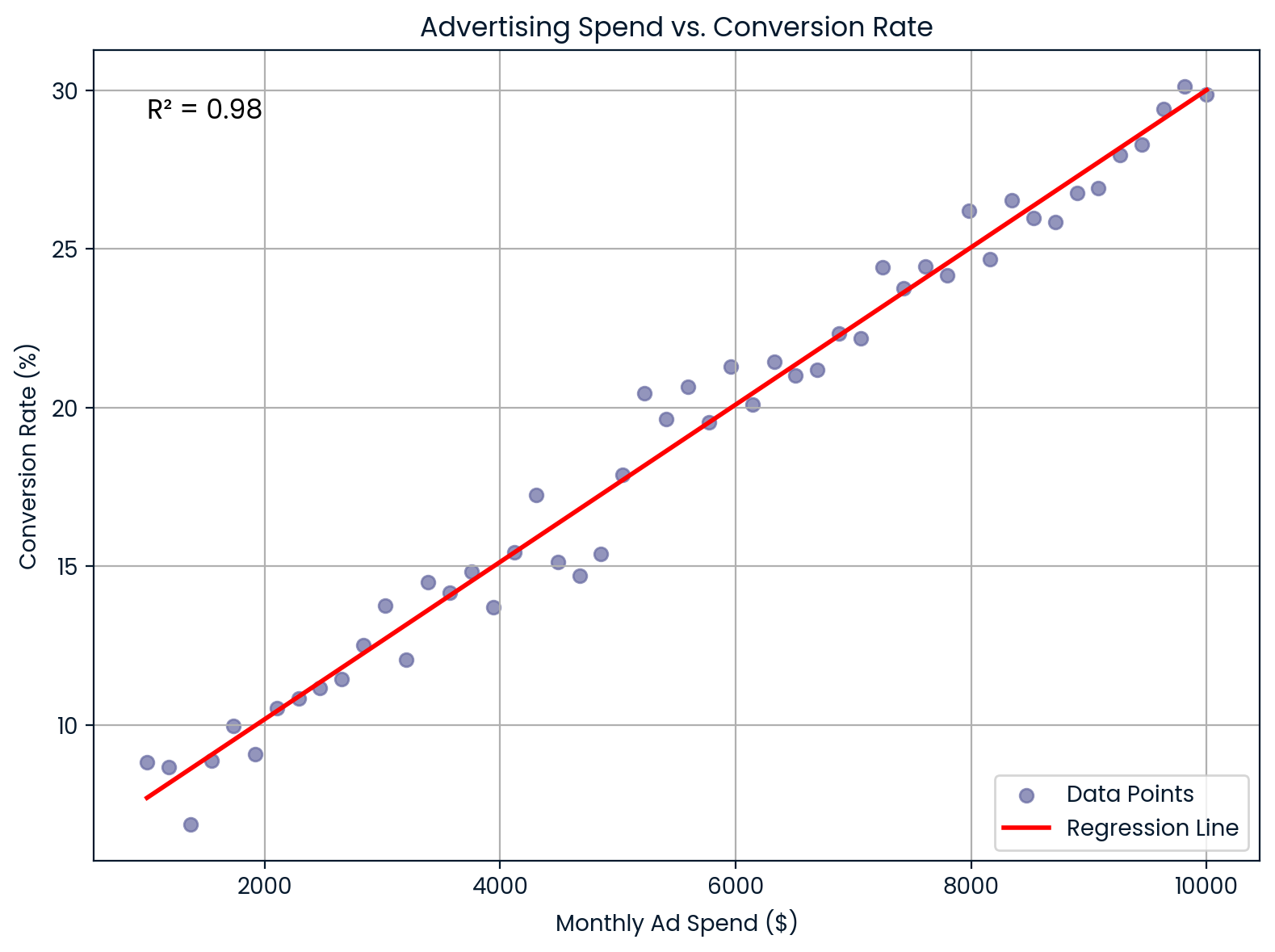
Gastos mensais com publicidade versus taxa de conversão. Imagem do autor.
Esse gráfico mostra uma relação quase perfeita entre os gastos mensais com publicidade e a taxa de conversão. Ele ajuda a prever o retorno do investimento e a planejar o orçamento.
No machine learning,R² é usado como uma métrica de desempenho para tarefas de regressão. Bibliotecas como scikit-learn têm a função r2_score() pra calcular isso.
Isso mostra como o seu modelo explica a variação nos dados:
R² perto de 1 significa um bom ajuste e baixo erro.
R² perto de 0, 0 significa que o ajuste é ruim.
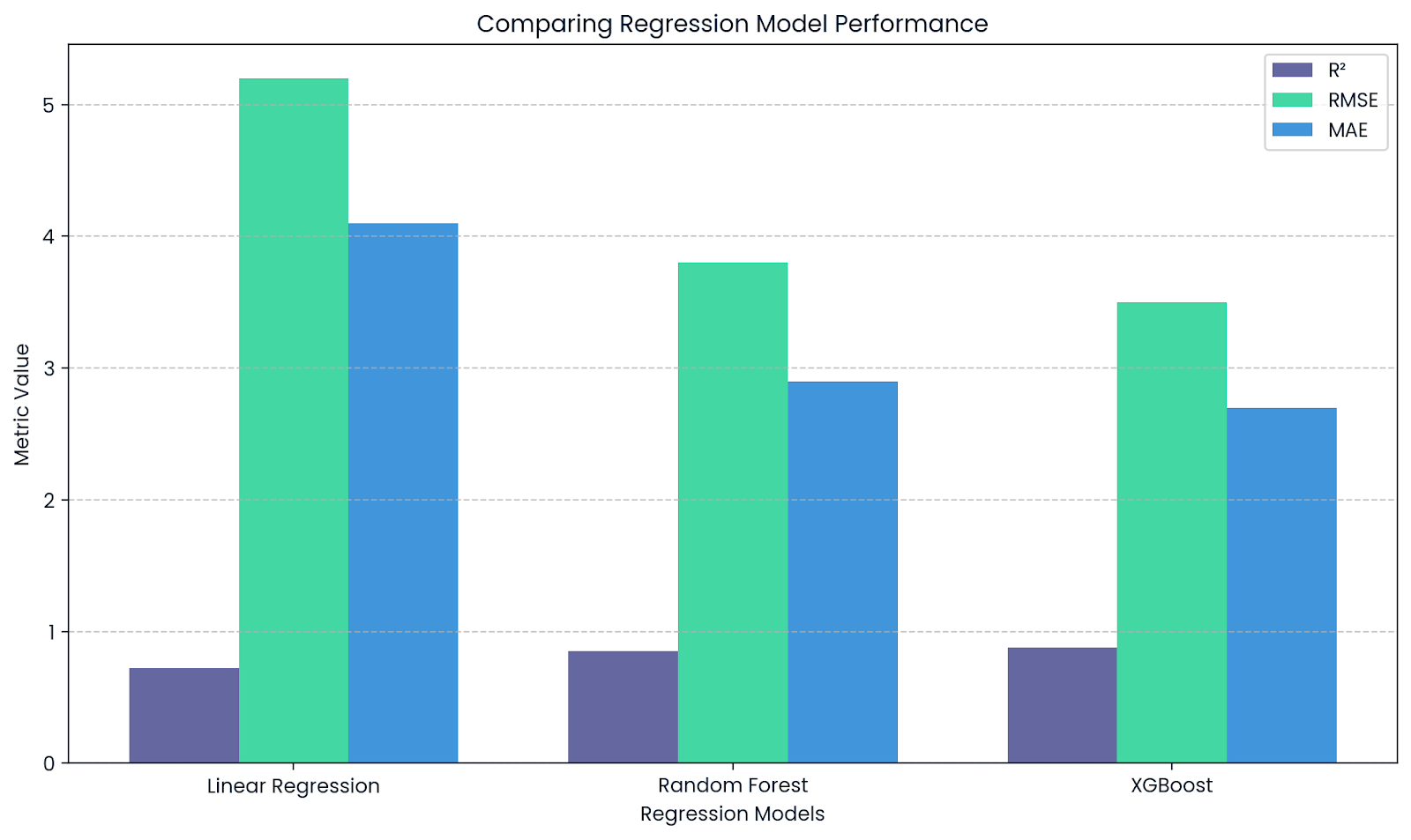
R² complementa RMSE e MAE. Imagem do autor.
Este gráfico mostra como o R² complementa outras métricas, como RMSE e MAE, na hora de avaliar modelos de regressão. EnquantoR² mostra o poder explicativo, RMSE e MAE dão uma ideia do tamanho real dos erros de previsão.
Se você estiver incluindoR² em um artigo científico ou projeto, tem algumas regras de formatação que é bom lembrar:
Se você está usandoR² como parte de uma análise de regressão ou ANOVA e quer saber se seu modelo é significativo, inclua mais algumas coisas: a estatística F, os graus de liberdade e o valor p. Isso mostra ao leitor o quanto a gente pode confiar que o seu modelo explica algo importante.
Então, quando você estiver relatando os resultados, pode ficar mais ou menos assim:
“O modelo explicou uma parte significativa da variação nas vendas,R² = 0,73, F(2, 97) = 25,42, p < 0,001.”
Mas, se você não estiver fazendo um teste de hipótese, tipo, se estiver fazendo uma análise exploratória ou avaliando o desempenho de um modelo com validação cruzada, então tá tudo certo em só reportar o valor R².
Vamos ver como calcularR² de três maneiras diferentes: Python, R e Excel através de um mini-projeto onde a gente tenta adivinhar as notas dos alunos com base no tempo que eles estudam.
Vamos usar o seguinte conjunto de dados para todos os três exemplos:
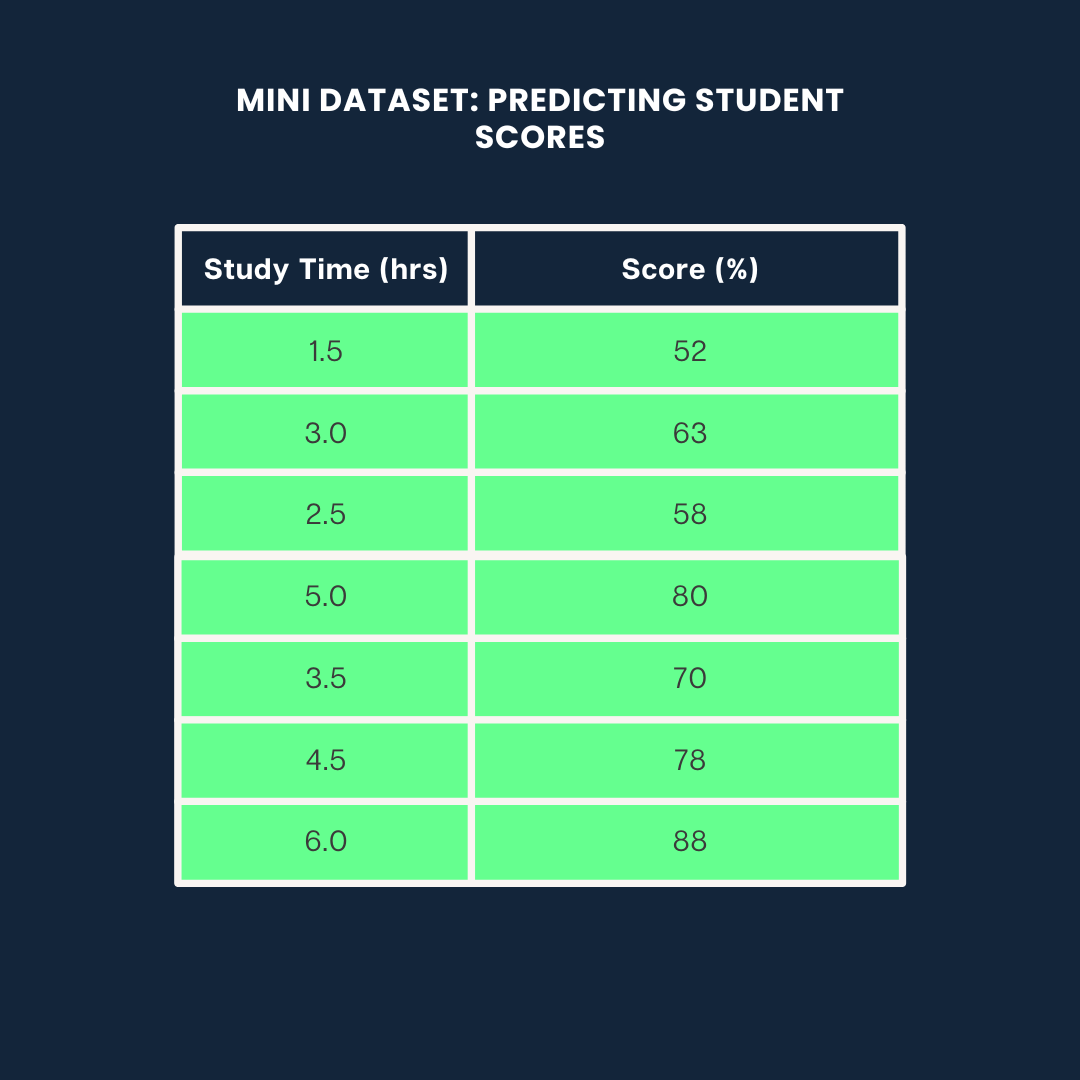
Conjunto de dados de exemplo. Imagem do autor
Veja como calcularR² em Python usando scikit-learn:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import numpy as np
# Data
study_time = np.array([1.5, 3.0, 2.5, 5.0, 3.5, 4.5, 6.0]).reshape(-1, 1)
scores = np.array([52, 63, 58, 80, 70, 78, 88])
# Model
model = LinearRegression()
model.fit(study_time, scores)
predicted_scores = model.predict(study_time)
# R² score
r2 = r2_score(scores, predicted_scores)
print(f"R² = {r2:.2f}")0.99Isso quer dizer que 99% da diferença nas notas é por causa do tempo que a galera estudou.
Se você quiser saber mais sobre regressão e modelos estatísticos, dá uma olhada no nosso guia Introdução à regressão com statsmodels em Python.
No R, você pode calcular R² com algumas linhas usando a função lm():
# Data
study_time <- c(1.5, 3.0, 2.5, 5.0, 3.5, 4.5, 6.0)
scores <- c(52, 63, 58, 80, 70, 78, 88)
# Linear model
model <- lm(scores ~ study_time)
# R-squared
summary(model)$r.squared0.9884718Cerca de 98% da variação nas notas é explicada pelo tempo de estudo. Se você quiser saber mais sobre regressão no R, dá uma olhada no nosso curso Introdução à regressão no R.
No Excel, você pode calcular o R² usando a função embutida “ RSQ() ”. Supondo que:
A hora de estudar está nas células A2:A8
As pontuações estão nas células B2:B8
A sintaxe é:
RSQ(known_y's,known_x's)Usei a seguinte fórmula:
=RSQ(B2:B8,A2:A8)Isso diz ao Excel para calcular o valorR² entre a variável dependente (notas) e a variável independente (tempo de estudo).
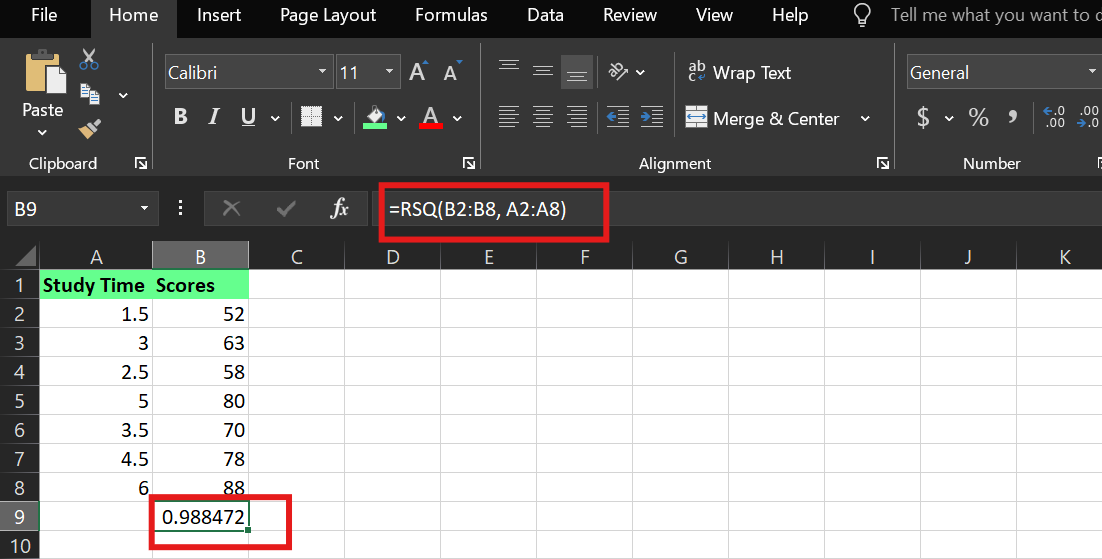
Exemplo deR² no Excel. Imagem do autor.
Se você está prevendo notas de alunos, retornos de ações ou comportamento de clientes, o coeficiente de determinação mostra o quanto do resultado seu modelo realmente entende.
Um coeficiente de determinação alto pode parecer incrível, mas não se deixe enganar achando que o modelo é perfeito ou que prova causa e efeito. E um coeficiente de determinação baixo nem sempre significa que deu errado; pode ser que seu sistema seja complexo ou que suas variáveis estejam incompletas.
Então, se você está criando ou analisando modelos, pergunte a si mesmo:
Comece com essa mentalidade e você vai usar o coeficiente de determinação como uma lente para tomar melhores decisões.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Summer Worsley
15 min
Tutorial
Vidhi Chugh
Tutorial
Eladio Montero Porras
Tutorial
Avinash Navlani
Tutorial
Zoumana Keita
Tutorial
DataCamp Team

