
Curso
Fundamentos de Inferência em R
4 h
38.7K
Se você já trabalhou com estatística inferencial, especialmente com testes de hipóteses e regressão, provavelmente já ouviu falar do valor p. E se você já trabalhou com valores p, provavelmente sabe, ou pelo menos tem uma ideia, que eles são vulneráveis e podem ser manipulados, e você está certo.
Na verdade, essa manipulação tem até um nome. Isso é p-hacking. Às vezes, também é chamado de “ ”, “data dredging”, “data snooping”, “data fishing” e “inflation bias”. E é nisso que este artigo vai se aprofundar.
Primeiro, vamos dar uma refrescada na memória sobre o que é um valor p. O “p” em valor p significa probabilidade. Especificamente, o valor p é a probabilidade de ver resultados tão extremos quanto os que você obteve, supondo que a hipótese nula seja verdadeira. Essa rejeição errada também é chamada de Erro Tipo I ou erro falso positivo. Normalmente, é obtido para ser comparado com o nível de significância (denotado como α), que é a probabilidade tolerada de rejeitar a hipótese nula quando ela é verdadeira.
Logicamente, se o valor p for maior que o nível de significância, a gente não consegue rejeitar a hipótese nula e fica com ela. Por outro lado, se o valor p for menor ou igual ao nível de significância, podemos rejeitar a hipótese nula em favor da alternativa e, nesse caso, dizemos que os resultados são estatisticamente significativos.
Se alguma coisa nessa breve revisão sobre valores p não fizer sentido pra você, não se preocupe! Você pode fazer nosso curso teórico Introdução à Estatística e entender rapidinho os fundamentos necessários .
Chegar a resultados “estatisticamente significativos” parece muito com sucesso e, por isso, é tentador. Nos negócios, isso quer dizer que você tem algo novo, interessante ou legal pra contar. No mundo acadêmico, você descobriu algo e isso pode ser publicado em revistas especializadas.
E como isso é a chave pra todo esse mundo de emoção, os profissionais de dados e pesquisadores ficam tentados a se concentrar demais nos valores p dos seus estudos e não pensar em mais nada, nem mesmo no nível de significância. E como o nível de significância mais comum nas últimas décadas tem sido 0,05, ficou fácil dizer que, se você chegar a um valor p abaixo de 0,05, pode tirar o paletó e comemorar na hora.
Como resultado adicional, alguns pesquisadores cometem o erro de manipular os valores p, às vezes de propósito, mas geralmente sem querer, usando métodos que podem diminuir o valor p para que ele seja estatisticamente significativo, em casos em que testes adequados teriam mostrado o contrário.
Seja de propósito ou não, tem várias maneiras de as coisas darem errado, levando ao p-hacking. Os métodos que levam ao p-hacking podem ser chamados de p-hacks e podem acontecer em qualquer fase dos experimentos.
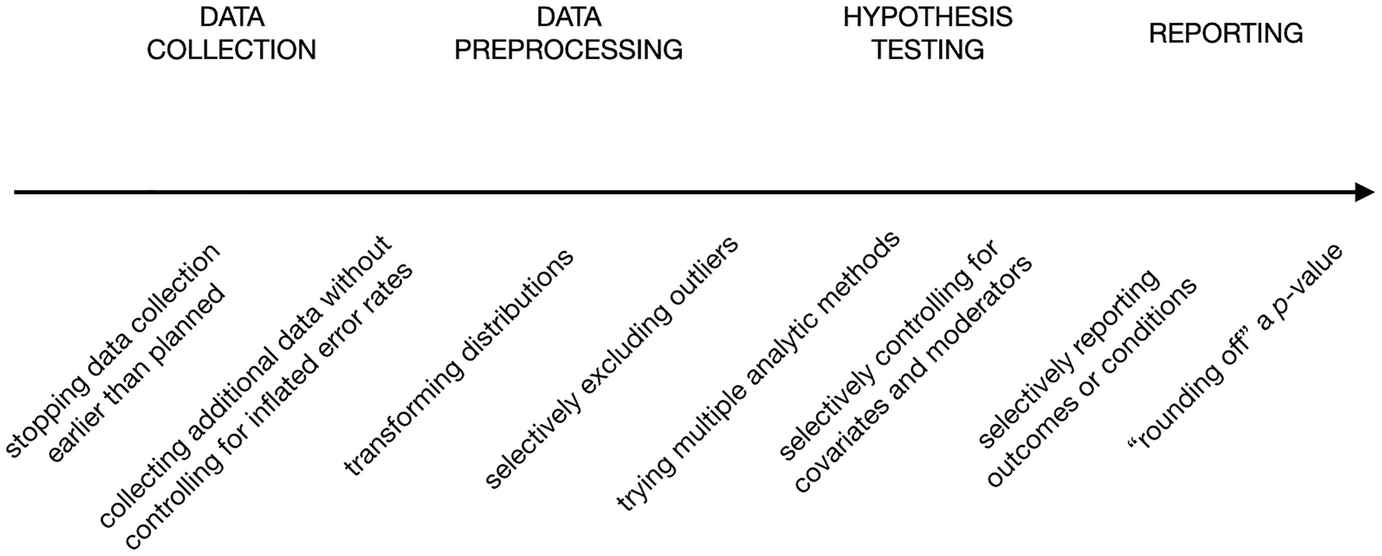
No capítulo do livro The Myriad Forms of p-Hacking, Dorota Reis e Malte Friese mostram uma lista que não é completa de p-hacks nas diferentes etapas dos experimentos, desde a coleta de dados até a apresentação dos resultados, representada no gráfico a seguir.
Exemplos de p-hacks. Fonte: Como evitar práticas de pesquisa duvidosas na psicologia aplicada.
Vamos ver o que cada um significa, da esquerda para a direita:
Observe que a maioria desses p-hacks depende da repetição do experimento várias vezes, ajustando cada vez o que deveria ser uma base pré-determinada para o experimento.
Mas mesmo sem ajustes, repetir o mesmo experimento e só divulgar o resultado quando ele for estatisticamente significativo pode ser um p-hack, porque sempre existe a chance de que, se qualquer experimento for feito várias vezes, ele vai dar um valor p baixo em algum momento. A história em quadrinhos below do xkcd mostra bem essa ideia.

Quadrinhos “incríveis”. Fonte: xkcd.
O P-hacking é um fenômeno muito comum. No começo dos anos 2010, vários estudos começaram a descobrir que uma grande parte das pesquisas publicadas em revistas respeitadas de várias áreas provavelmente tinha sido manipulada, especialmente nas áreas de psicologia e medicina, mas também nas ciências sociais e humanas.
Por exemplo, em 2015, um estudo feito por um pesquisador da Universidade da Virgínia analisou 100 estudos de psicologia publicados em revistas importantes em 2008 e descobriu que menos da metade desses estudos podiam ser repetidos. A falta de reprodutibilidade quer dizer que os estudos, quando feitos de novo, não chegam ao mesmo resultado, às vezes por causa do p-hacking.
Outro projeto que analisou estudos sobre o câncer descobriu que só 50 dos 193 experimentos podem ser repetidos. Já em 2009, um estudo notou um número suspeito de experimentos na área da neurociência que mostravam correlações bem altas entre emoções, personalidade, cognição social e a atividade do cérebro através da ressonância magnética funcional (fMRI). Depois de dar uma olhada nos autores desses experimentos, descobrimos que eles usavam uma estratégia de escolher partes dos dados e só falar sobre os que davam um resultado legal, tipo um p-hack parecido com o que chamamos de substituição post hoc.
Os resultados desses estudos revelaram como o p-hacking, junto com outras práticas de pesquisa meio duvidosas, está deixando a base da pesquisa científica, que sempre foi respeitada, meio instável e cheia de falhas. Uma crise que tem sido chamada de crise da replicabilidade, queainda estárolando em meio a muitas discussões e esforços para encontrar uma saída.
Então, afinal, por que o p-hacking é um problema?

“P-hackingte torna um mago”. Fonte: SMBC Comics.
A pergunta pode parecer óbvia demais pra responder, mas uma análise das razões pelas quais o p-hacking é errado e antiético também pode nos ajudar a entender melhor a “importância” do problema da significância falsificada.
No fundo, o P-hacking é só o resultado de mexer na metodologia ou nos resultados. Se for de propósito, isso seria tipo mentir sem motivo, só pra se dar bem (como ser publicado ou reconhecido). Se isso for feito sem querer, vai ser como pegar o caminho errado e acabar chegando a nada além de uma miragem de falsos positivos.
Experimentos, seja no mundo da ciência ou nos negócios, têm consequências. São feitas para tomar decisões ou para desenvolver ainda mais os resultados. Se os resultados da experiência forem falsificados, as decisões dependentes serão infundadas e, às vezes, isso pode levar a consequências desastrosas.
Por exemplo, pesquisas em áreas sensíveis como oncologia e neurologia podem ajudar no desenvolvimento de tratamentos e remédios. Seria um desastre se algumas das pesquisas iniciais fossem manipuladas.
Nos negócios, decisões erradas podem levar a várias coisas, desde lançar um produto que não dá certo, esgotar recursos, até alguém ser demitido ou a empresa ir à falência. Um simples p-hack pode criar um efeito borboleta.
A crise da replicabilidade gerou um ceticismo geral sobre a ciência como um todo, até mesmo no discurso político. Embora o pensamento crítico sempre possa ser útil, mesmo quando se recebe descobertas científicas, descartar todas as descobertas empíricas pode levar ao desespero da ignorância e a decisões sem fundamento.
Nos negócios, em menor escala, o p-hacking e práticas questionáveis semelhantes podem levar os líderes empresariais a deixar de tomar decisões baseadas em dados e voltar a depender apenas da intuição, o que é exatamente o oposto do que o domínio da ciência de dados como um todo promete e pode realmente cumprir.
Todo o conhecimento humano é baseado na sua natureza acumulativa. Cada pequena experiência é um tijolo que constrói uma estrutura de conhecimento maior. Quando um número cada vez maior desses blocos de construção fica instável por causa de práticas duvidosas, como o p-hacking, o potencial dessa acumulação fica comprometido. Até mesmo a simples tarefa de encontrar literatura anterior para construir um novo experimento se torna uma missão complicada, como encontrar um caminho em um campo minado.
Com base no que sabemos agora sobre p-hacking e seus métodos, podemos ver alguns sinais de alerta que podem ajudar a detectar p-hacks. A maioria desses sinais de alerta ainda precisa de uma mente curiosa, pensamento crítico e olhos atentos para serem percebidos. Alguns até dependem de um conhecimento bem profundo do assunto.
Resultados sensacionais de experimentos geralmente são muito suspeitos para serem aceitos sem questionamentos. Normalmente divulgados pela imprensa e pelas redes sociais, estudos que dizem coisas como “chocolate pode ajudar a perder peso” não parecem muito confiáveis.
No mundo dos negócios, um teste que promete um aumento de 100% no lucro por causa de uma pequena mudança num site pode ser visto como algo igualmente incrível.
Quando você se deparar com um estudo assim, se ele te preocupar, sempre dá uma conferida na metodologia e nos resultados antes de aceitar as conclusões.
Cuidado com experimentos que não deixam clara a metodologia ou que não falam sobre alguns componentes da metodologia. Ser transparente sobre as hipóteses iniciais, o nível de significância, o tamanho da amostra, as variáveis coletadas, o tipo de teste escolhido e as etapas de preparação dos dados é essencial para um procedimento científico sólido. Não ter clareza sobre qualquer um desses pontos é um sinal de alerta.
Se a preparação dos dados da experiência incluir transformação de variáveis, dá uma olhada no motivo por trás da medida, pois a justificativa precisa ser declarada. Se não for assim, ou se não for convincente, isso pode ser um sinal direto de p-hacking.
Uma amostra pequena diminui o poder estatístico do estudo, aumentando o risco de falsos negativos. Mas, quando misturados com relatórios seletivos ou p-hacking, estudos com pouca potência também podem aumentar a taxa de resultados falsos positivos na literatura publicada.
Em algumas áreas, amostras pequenas são aceitáveis e comuns, tipo em pesquisas clínicas, estudos ambientais, engenharia e controle de qualidade. Mas, de um modo geral, amostras maiores levam a melhores inferências e, portanto, menos chances de falsos positivos e valores p significativos que não são verdadeiros.
De qualquer forma, se uma amostra pequena não for justificada, isso pode indicar falta de poder estatístico, o que aumenta o risco de resultados falsos positivos. Em alguns casos, acho que isso também pode sugerir uma interrupção precoce, a prática específica de p-hacking que mencionei anteriormente, em que a coleta de dados termina assim que se atinge a significância, em vez de quando se atinge o tamanho da amostra planejado.
O tamanho do efeito mede a força ou magnitude da relação entre variáveis, dando contexto à significância estatística de um resultado. Se um estudo mostra que algo é estatisticamente significativo, mas não dá um tamanho de efeito claro ou significativo, isso levanta suspeitas.
Um valor p pode indicar que o resultado é improvável por acaso, mas sem um tamanho do efeito, é difícil determinar o significado prático das descobertas. Em estudos manipulados, não deixar claro o tamanho do efeito pode indicar que os pesquisadores se concentraram demais em conseguir significância estatística, sem se importar com outras coisas.
Quando os resultados de um estudo são bem diferentes da hipótese original, isso deve levantar algumas questões. Isso pode ser um sinal de que os pesquisadores mudaram suas hipóteses ou métodos depois de coletar os dados para que eles combinassem com os resultados — uma prática conhecida como HARKing (HypothesizingAfter Results are Known, ou “formular hipóteses depois que os resultados são conhecidos”).
Por exemplo, se um experimento diz que testou uma hipótese específica, mas a análise final parece focar em variáveis ou resultados que não têm nada a ver, isso pode ser um sinal de p-hacking. Sempre compare a hipótese declarada com os resultados finais para garantir que eles estejam alinhados.
Um tamanho do efeito super alto pode ser um sinal de alerta para p-hacking. Em muitos casos, os efeitos no mundo real são pequenos a moderados, especialmente em áreas como psicologia, medicina ou ciências sociais. Assim como avaliar o tamanho adequado da amostra, entender como um tamanho de efeito é plausível exige um conhecimento profundo do assunto.
Se um estudo mostra um efeito muito grande, pode ser que os dados tenham sido manipulados ou que a amostra tenha algum tipo de viés. Os pesquisadores podem, de propósito ou sem querer, deixar de fora dados que diminuiriam o tamanho do efeito para fazer suas descobertas parecerem mais impressionantes do que realmente são (o p-hack de substituição pós-hoc).
Quando o valor p relatado está logo abaixo do limite de significância (por exemplo, p = 0,049 em um estudo em que p < 0,05 é o limite para significância), isso pode indicar que os pesquisadores fizeram p-hacking.
Isso porque fazer testes várias vezes ou mexer nas variáveis pode fazer com que o resultado passe do limite de significância por acaso. Um padrão de resultados que fica sempre um pouco abaixo do nível de significância sugere que os pesquisadores podem ter parado de coletar dados assim que chegaram ao resultado que queriam (interrupção precoce) ou relatado só algumas análises (substituição pós-hoc).
Um dos sinais mais fortes de p-hacking é quando os resultados de um estudo não podem ser repetidos. Se pesquisadores independentes não conseguirem reproduzir os resultados de um estudo usando a mesma metodologia, isso pode indicar que as conclusões originais foram resultado de p-hacking ou relatórios seletivos.
A replicabilidade é uma pedra fundamental da integridade científica, e resultados que não podem ser reproduzidos de forma consistente sugerem que a análise original pode ter sido falha ou manipulada.
Ao inverter os sinais de alerta acima, também podemos pensar em maneiras de evitar o p-hacking. Essas formas já estão aparecendo no papo da galera científica na última década, como uma resposta à crise da replicabilidade.
É essencial ter uma boa compreensão dos princípios estatísticos para evitar o p-hacking. Quando os analistas têm o conhecimento necessário, eles ficam mais preparados pra evitar armadilhas comuns, como interpretar mal os valores p ou lidar de forma errada com várias comparações.
Por exemplo, em testes A/B para um recurso de um site, um analista que sabe das coisas vai entender que o valor p não é o objetivo final, porque mesmo que o teste tenha um valor p baixo, ele ainda pode ter um tamanho de efeito que não é grande o suficiente e, por isso, não tem importância prática. Entender a diferença entre significância estatística e prática pode ajudar os analistas a não se concentrarem demais no valor p, o que pode levar a práticas de p-hacking e, assim, diminuir a chance de manipular os resultados para um resultado mais favorável.
A pré-registração em pesquisa científica envolve descrever o plano de pesquisa ou teste, incluindo hipóteses, métodos e técnicas de análise, antes de coletar qualquer dado. Esse processo evita o p-hacking, garantindo as decisões sobre como a análise vai ser feita, o que torna mais difícil alterar a análise depois pra conseguir um resultado significativo.
Nos negócios, práticas parecidas podem ser feitas até mesmo no nível das equipes de dados. Por exemplo, antes de fazer um experimento pra medir o impacto de um novo modelo de preços, a equipe pode documentar antes e declarar internamente a hipótese, dizendo quais variáveis vão ser testadas (por exemplo, receita, taxa de aquisição de clientes), o nível de significância e o tamanho da amostra. Isso garante que a equipe siga o plano original e não mude a análise depois de ver os resultados iniciais, evitando práticas de substituição pós-hoc e seleção seletiva apenas dos dados que mostram um resultado favorável.
Ciência aberta é quando a gente deixa dados, métodos e análises disponíveis para outras pessoas darem uma olhada e copiarem. No mundo dos negócios, mesmo que o termo “ciência aberta” não seja usado direto, práticas de transparência parecidas são importantes pra garantir a integridade das análises.
Por exemplo, uma empresa que está fazendo uma análise de mercado pode compartilhar seus dados brutos e etapas da análise internamente com outras equipes, auditores ou pessoas interessadas, ou documentar tudo de forma organizada para usar de novo no futuro. Essa transparência desestimula o p-hacking, porque qualquer pessoa pode verificar se tem alguma discrepância ou falha na metodologia. Em uma organização, ser aberto sobre métodos e resultados promove a responsabilidade e ajuda a garantir que as conclusões sejam tiradas de dados sólidos e reproduzíveis.
As etapas de preparação e transformação dos dados devem sempre ser bem justificadas. Sem uma boa razão, tirar os dados que estão muito diferentes ou mudar as variáveis pode ser usado pra manipular os resultados e criar uma história que não é verdadeira.
Por exemplo, ao analisar os dados de compras dos clientes, um analista pode deixar de lado alguns pontos de dados (como valores muito diferentes dos outros) que não parecem se encaixar no modelo. Mas, sem um motivo válido — tipo, identificar esses dados como anomalias de verdade, e não como parte da distribuição normal —, isso pode ser uma forma de p-hacking. Para evitar isso, cada etapa da preparação dos dados (como excluir certos períodos ou aplicar transformações de log) deve ser explicitamente justificada no relatório de análise, garantindo transparência.
Além da importância estatística, é essencial relatar e entender o tamanho dos efeitos. Isso garante que os resultados sejam significativos na prática e não estejam apenas aproveitando a importância estatística por causa do tamanho grande da amostra.
Nos negócios, pense em um teste A/B em que uma nova descrição de produto aumenta as taxas de conversão em 0,5%, mas a amostra é grande o suficiente para tornar o resultado estatisticamente significativo. Sem contexto, essa mudança pode ser mal interpretada como algo importante. Mas, se a gente focar no tamanho do efeito e perguntar se um aumento de 0,5% justifica o custo de mudar todas as descrições dos produtos, as empresas podem evitar tomar decisões só com base nos valores p.
Dissemos que fazer o mesmo teste (ou testes diferentes) nos mesmos dados pode levar a um resultado significativo por acaso e, por isso, consideramos isso como um p-hack. Mas, na verdade, fazer o mesmo teste várias vezes com os mesmos dados pode ser uma boa maneira de evitar e ficar atento ao p-hacking, se — e só se — for junto com métodos de correção, que são técnicas estatísticas que ajustam o fato de que várias comparações estão sendo feitas. Os dois tipos mais comuns de métodos de correção são o método de correção de Bonferroni e o procedimento de Benjamini-Hochberg (BH).
O Bonferroni envolve ajustar o limite do valor p (o nível de significância) pra baixo, dividindo-o pelo número de testes realizados. Embora seja eficaz na redução das chances de falsos positivos, pode ser excessivamente conservador, aumentando a probabilidade de falsos negativos.
Já o BH é uma das técnicas de controle da Taxa de Descobertos Falsos (FDR) que tenta equilibrar a chance de acontecer os dois tipos de erro. Resumindo, o procedimento BH funciona classificando primeiro todos os valores p de vários testes, do menor para o maior. Cada valor p é então comparado com um limite que aumenta com a sua classificação. O maior valor p que ainda está abaixo do seu limite é identificado, e todos os valores p até esse ponto são considerados significativos.
No mundo dos negócios, se uma empresa está testando várias versões de uma página de destino, dá vontade de fazer vários testes A/B e parar quando uma versão parece funcionar bem melhor. Para evitar isso, o analista pode fazer uns ajustes para levar em conta os vários testes que estão sendo feitos. Ao fazer isso, eles garantem que qualquer descoberta importante não seja só resultado de testes repetidos.
Por fim, é importante reconhecer e relatar resultados não significativos, em vez de simplesmente ignorá-los. Tem havido pedidos na comunidade científica para permitir a publicação de experimentos com resultados insignificantes, desde que sigam uma metodologia rigorosa pré-registrada, porque a ausência de resultados também pode ser um resultado! A mesma sabedoria pode ser seguida nos negócios.
Por exemplo, se uma campanha de marketing não tiver um impacto significativo nas vendas, a empresa ainda deve relatar e considerar essa constatação. Ele traz informações importantes e evita relatórios errados que podem levar a decisões de negócios sem sentido. Ser sincero sobre resultados que não são importantes ajuda a fazer uma análise mais honesta e evita a tentação de mexer nos dados só para mostrar que deu certo.
Neste artigo, a gente explorou a fundo o mundo do p-hacking, onde o valor p pode ser vulnerável à manipulação. A gente deu uma olhada nos vários p-hacks, como eles podem ser detectados e como podem ser evitados.
Como você pode ver, e como já falamos, uma grande parte de estar atento ao p-hacking é ter um bom conhecimento de estatística. Você pode conseguir isso com nossos vários cursos sobre estatística, como nosso curso teórico “Introdução à Estatística” ou nossos cursos práticos “Introdução à Estatística em planilhas do Google”, “Introdução à Estatística em Python” e “Introdução à Estatística em R”.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Abid Ali Awan
7 min
blog
Tim Lu
12 min
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Amberle McKee

