Course
Machine Learning for Time Series Data in Python
4 hr
53.3K
During my studies I had the opportunity to work on several machine learning research projects. These projects ranged from studying probabilistic models, to more practical scenario’s in natural language processing. A common element in the work I did, was the availability of well-defined problems and the abundance of clean datasets.
The past year, I have been working as a Data Scientist at Microsoft, solving problems of enterprise customers. The experience I gained from working across industries tested my skills in a wide variety of ways, both from a data science perspective and from a problem solving perspective. A large portion of the time is typically spent defining the problem, creating a dataset and cleaning the data and large datasets are almost always harder to come by.

In this blog post I share some of the lessons learned and pitfalls you might experience when working on data science projects ‘in the wild’. A lot of these pitfalls are almost always present, and it is often necessary to be ‘creative’ in order to solve them.
There are several different ways data can be leveraged to improve business processes. The assignment you typically get from a customer is to ‘solve business problem X’. A concrete example is e.g. ‘improve the profitability of the marketing campaigns’.
A common pitfall is not tackling problems in the ‘right’ order. If you want to improve a process, you need to properly understand it, before even thinking of automating parts of it. Customers typically have limited knowledge on their own data and no experience with data science. It is thus very important to clearly explain to them what the different options are from a data science perspective.
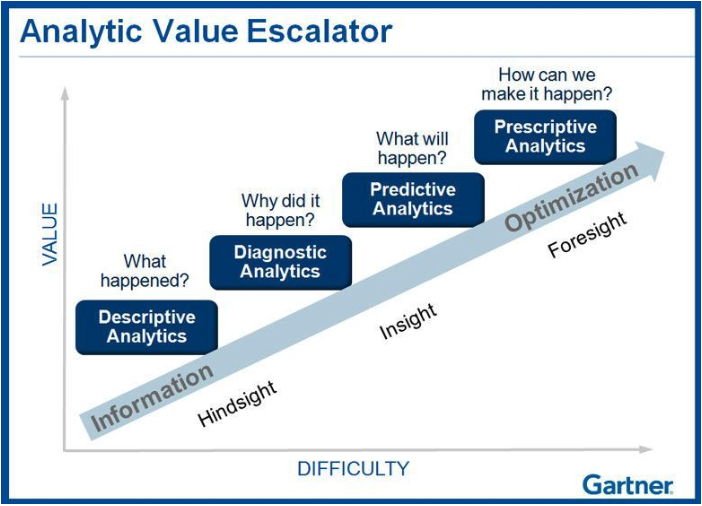
Often, you start the project by cleaning and analyzing the data. The terms ‘descriptive and diagnostic’ analytics are used when you aim to build summaries of the data and try understand how the different variables in the data relate. You build visualizations and use (unsupervised) machine learning techniques to cluster data points or find correlated variables. Based on the outcome of the process, you can e.g. build a report or dashboard, which lists and investigates a set of KPI’s that are useful for the business problem. With marketing campaigns, you could correlate sales and marketing data in order to understand why campaigns are successful. The conclusions (e.g. a lower price results in more sales) might not always be ‘rocket science’, but they allow the customer to validate their hypothesis using their data. In addition, it also allows them to spot anomalous behavior and whether they have the right type of data.
Predictive and prescriptive analytics are about predicting the future and taking actions based on these predictions. With predictive analytics you take the historical data, and build a machine learning model to predict future data points (within a certain error range). In marketing, novel campaign ideas are often validated by estimating the expected sales using a predictive model. By having done the previous descriptive and diagnostic phase, you should have a clear idea of what you can expect in terms of performance. If the data quality is not good enough to build a robust model, this can be flagged to the customer and you can backup your claims using the data they provided.
With prescriptive analytics, the goal is to take actions based on predictions, and optimize certain aspects of the proces. Instead of validating campaign ideas, you could e.g. build an optimisation engine that can generate the list of ‘best future campaigns’. Building this system requires large amounts of high quality data. Note that data science is all about underpromising and over delivering, so start small and build big!
Customers often like to work with a Proof of Concept in order to investigate what is possible with ‘data science’. Typically, this means that they provide a subset of the data, and they want to determine some preliminary results. Although a customer typically understands you won’t get good performance on with the PoC, it is still a common request. The downside however of a PoC is that a subset of the data is often not representative of the full dataset and problem. You might get extremely good performance out of the PoC, but you might be unable to replicate this on the full dataset. Customers select the dataset by e.g. looking at only a small time segment, which could heavily bias the PoC model.
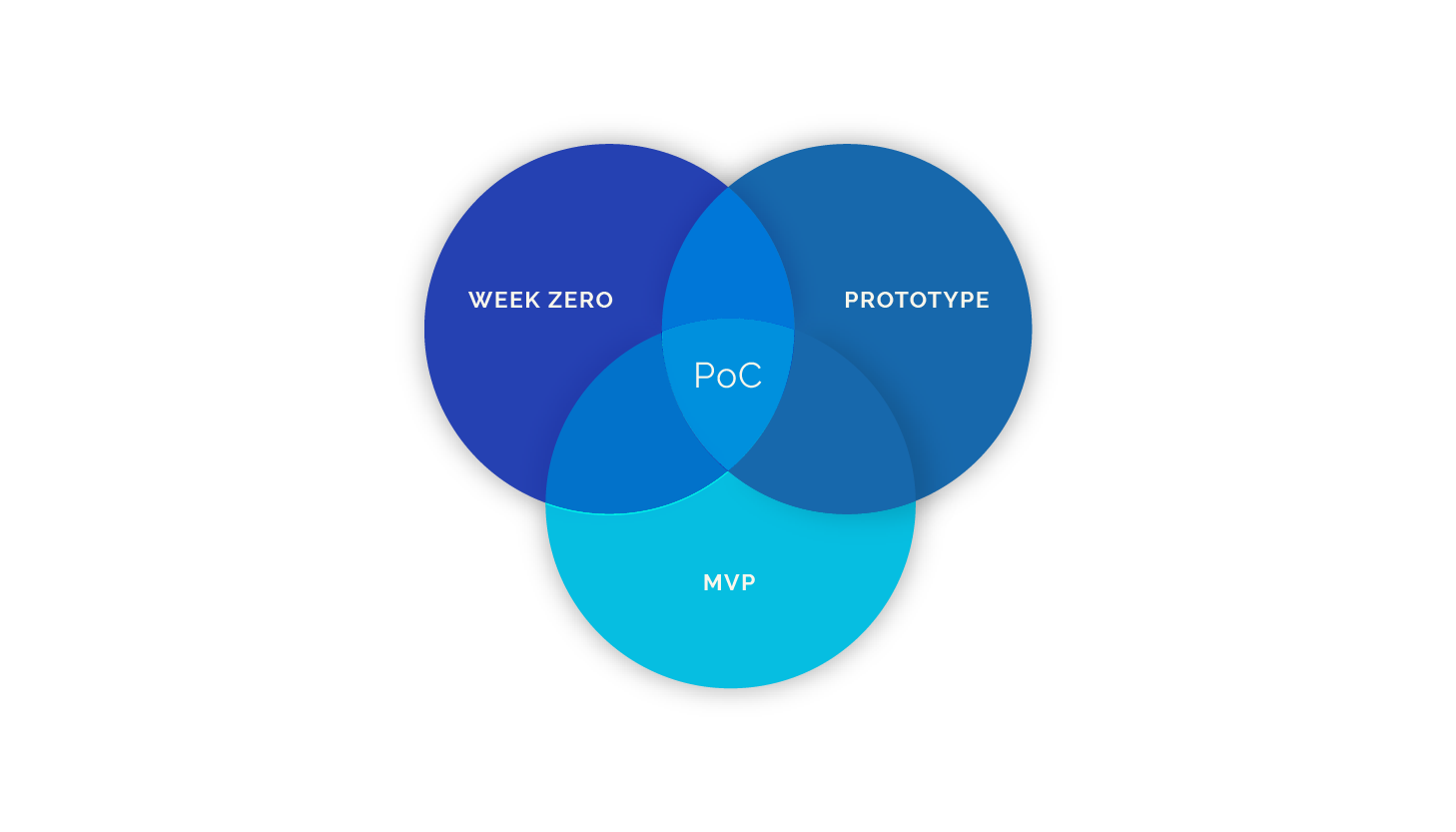
A better option, if the customer wants to experiment, is to work with pilots. In pilots, you work with the full dataset, and you run through an initial iteration of the data science pipeline (data cleaning, modeling, etc). Working with the full dataset mitigates a lot of risk in the project. The model performance will still not be optimal, as you only got limited time, but at least you should have been able to get a representative picture.
Although this pitfall is similar to the previous one, it is not the same. Especially if you work with unstructured data (e.g. images, text data, etc), a customer might have already collected data before you start the project. A critical, but often overlooked element of the dataset is whether it is representative of the use case. If datasets need to be collected, it should be done in the same fashion as the model will ultimately be used.
For example, if you want to do inventory management using computer vision, it is important to have images of objects in the store or the fridge, where the model will be used. Catalogue type images will not result in a robust model, as they don’t represent the use case. The model must learn robust features in order to detect the object in the environment.

It is hard to imagine the fridge of the end-users will be this clean!

The golden rule of data science is to be suspicious when you get extremely good performance (>90%) at the start of the problem. Good performance at the start of the project could be an indicator of ‘leaky’ variables or a ‘leaky’ dataset. Leaky variables are variables that are highly correlated with the target variable, and that are unlikely to be available at inference time. If the goal is to predict sales, you are not able to use the sales of other products as features because this data won’t be available. A ‘leaky’ dataset happens when the dataset only reflects a certain (time) segment. The problem that needs solving is typically significantly easier, and it is quite likely that the model would fit towards noise in the data, instead of the actual signal.
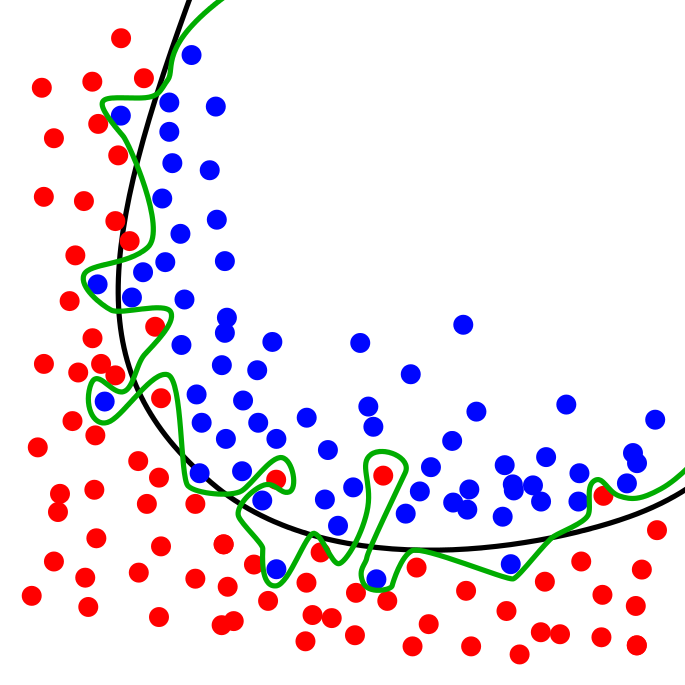
A model with high performance is great, but only if it performs equally well on a completely new and random dataset!
I highly enjoyed this blog post on statistical fallacies. Interpreting correlation as causation is only one of the type of errors that is often made, and getting a strong understanding of the statistics behind them is key.
If a customer uses the model as a basis for actions, they will always prefer solutions that are interpretable and understandable. In this blog post, I went in-depth into the reasons why model interpretability is key. I also provided a more-in depth look at the different techniques that you can use.
I only touched on 6 potential data science pit falls, but I am convinced that I probably made significantly more errors in the past year. If you have any experience on data science projects, and want to share your commonly encountered problems, I’ll be happy to read them in the comments. Follow me on Medium or Twitter if you want to receive updates on my blog posts!
Take a look at DataCamp's tutorial on Preventing Overfitting in Machine Learning.
If you are interested in learning more about data science, check out DataCamp's Intro to R and Intro to Python courses.
Learn more about Machine Learning
Course
Course
Course
blog
Richie Cotton
8 min
blog
DataCamp Team
4 min
blog
Javier Canales Luna
13 min
podcast
Tutorial
Nishant Singh
Tutorial
Moez Ali


