Course
Understanding ChatGPT
1 hr
425.7K
OpenAI's most advanced model, Generative Pre-trained Transformer 4 (GPT-4), launched in March 2023, is a leap forward in artificial intelligence, introducing a new benchmark for AI capabilities. Available through ChatGPT Plus, OpenAI's API, and Microsoft Copilot, GPT-4 stands out for its multimodal abilities, notably through GPT-4V, which enables it to process images alongside text, paving the way for innovative applications in various fields.
At the core of GPT-4's advancement is its transformer-based framework, extensively pre-trained on a vast array of data from the internet and licensed sources and fine-tuned with a blend of human feedback and AI-driven reinforcement learning. This unique approach aims to enhance the model's alignment with human ethical standards and policy compliance.
While GPT-4 marks an improvement over its precursor, GPT-3, it inherits some of the latter's limitations, underscoring the intricate challenges in Large Language Models and Generative AI. Some of those challenges can be addressed through a process called Fine-tuning, which is what the topic of this tutorial is. The objectives of this tutorial are:
However, it’s worth noting that GPT-4 fine-tuning is currently only in experimental access, and eligible developers can request access via the fine-tuning UI. That being said, the fine-tuning techniques covered are applicable to all GPT models.
Fine-tuning represents a sophisticated process that refines pre-trained models (like GPT-4) for specific tasks or domains, leveraging the model's extensive foundational knowledge acquired during initial training on diverse datasets. This involves adjusting the model's parameters based on task-specific data, enhancing its performance, and enabling it to handle particular applications with greater precision and efficiency.
One illustrative example of fine-tuning's impact is the enhancement of a model's responses to specialized queries. For instance, a pre-trained model might offer a basic explanation when asked why the sky is blue. Through fine-tuning, this response can be enriched to include detailed scientific context, making it more suitable for specialized applications such as educational platforms.
Fine-tuning methods range from instruction fine-tuning, where models are trained using specific examples that demonstrate the desired responses, to parameter-efficient fine-tuning (PEFT), which updates only a subset of the model's parameters to conserve computational resources and prevent catastrophic forgetting.
In contrast, Retrieval Augmented Generation (RAG) represents a different approach. RAG combines elements of retrieval-based and generative models to enhance the quality of generated content by incorporating information retrieved from external sources during the generation process.
While fine-tuning focuses on optimizing pre-existing models for specific tasks, RAG integrates external knowledge to enrich the content generation process.
The choice between fine-tuning and RAG depends on the specific requirements of the application, including the need for up-to-date information, computational resources available, and the desired level of task specialization. Fine-tuning offers a direct way to leverage pre-trained models' vast knowledge base for specific tasks, while RAG provides a dynamic approach to ensuring the relevance and accuracy of the information the model uses.
Fine-tuning OpenAI's text generation models is a powerful method to tailor them to specific needs, but it demands significant time and resources. Before jumping into fine-tuning, it's advisable to try maximizing the model's performance through prompt engineering, prompt chaining (dividing complex tasks into simpler, sequential prompts), and utilizing functions. This approach is recommended for several reasons:
Fine-tuning can be particularly beneficial in the following scenarios:
Due to the proprietary nature of OpenAI's models, you must utilize a fine-tuning API from OpenAI if you want to fine-tune any of the OpenAI models. This process involves uploading your data to OpenAI's servers to train the model.
Currently, only the following models are supported for fine-tuning via API.
GPT-4 fine-tuning is in experimental access, and eligible developers can request access via the fine-tuning UI. Regardless of the model used, the process of fine-tuning and the code in this tutorial does not change.
This is the most important step. The quality of a fine-tuned model is directly dependent on the data that you will create to fine-tune the model. For the OpenAI API, the data must be stored in jsonl format.
JSONL format is a text format where each line is a separate JSON object, making it suitable for processing large datasets line by line. This format is particularly useful for handling data that can be easily divided into individual records without losing structure.
Example:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
For this tutorial, I have created sample data with only five examples. The data consists of questions on various topics in machine learning and answers in the style of Shakespeare.
Sample data I created for this tutorial:
{"messages": [{"role": "system", "content": "You are teaching assistant for Machine Learning. You should help to user to answer on his question."}, {"role": "user", "content": "What is machine learning?"}, {"role": "assistant", "content": "'Tis but the art of teaching machines to think, to learn from data most fine, and decisions to link."}]}
{"messages": [{"role": "system", "content": "You are teaching assistant for Machine Learning. You should help to user to answer on his question."}, {"role": "user", "content": "How doth neural networks work?"}, {"role": "assistant", "content": "They're like the brains of yon digital beast, with layers many, and nodes that cease."}]}The first step of creating a fine-tuning job using OpenAI API is to upload the file. To use this API, you must have the openai library in python installed.
!pip install openaiNow login into your platform.openai.com account and generate an API token:
You can then set the token as an environment variable using the os library.
import os
# Set the OPENAI_API_KEY environment variable
os.environ['OPENAI_API_KEY'] = '...'Your training file must be in jsonl format. Once you've uploaded the file, processing might take a while. The maximum size for file uploads is 1 GB. To upload a file on the OpenAI server:
from openai import OpenAI
client = OpenAI()
client.files.create(
file=open("train.jsonl", "rb"),
purpose="fine-tune"
)
Output:
FileObject(id='file-rIua39sJX1O64gzxTYfpvJx7', bytes=11165, created_at=1709499930, filename='train.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)After ensuring the file has been successfully uploaded, the next step is to create a fine-tuning job. training_file is the file ID that was returned when the training file was uploaded to the OpenAI API. To start a fine-tuning job:
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-rIua39sJX1O64gzxTYfpvJx7",
model="gpt-3.5-turbo" #change to gpt-4-0613 if you have access
)
For configuring extra fine-tuning settings, such as the validation_file or hyperparameters, check out the API documentation on fine-tuning.
Fine-tuning jobs vary in time to complete, ranging from minutes to hours, depending on the model and dataset size. For instance, with just 50 examples in our train.jsonl dataset and using the gpt-3.5-turbo model, the job finished in just 7 minutes.
Once the job finishes, an email confirmation will also be sent.
Besides setting up a fine-tuning job, you have the option to view a list of current jobs, check the status of a specific job, or cancel a job.
from openai import OpenAI
client = OpenAI()
# List 10 fine-tuning jobs
client.fine_tuning.jobs.list(limit=10)
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve("...")
# Cancel a job
client.fine_tuning.jobs.cancel("...")
# List up to 10 events from a fine-tuning job
client.fine_tuning.jobs.list_events(fine_tuning_job_id="...", limit=10)
# Delete a fine-tuned model (must be an owner of the org the model was created in)
client.models.delete("ft:gpt-3.5-turbo:xxx:xxx")\OpenAI offers key training metrics such as training loss, token accuracy for training, test loss, and test token accuracy. These metrics help ensure training is progressing as expected, with loss decreasing and token accuracy improving. You can view these useful metrics in an event object during an active fine-tuning job.
{
"object": "fine_tuning.job.event",
"id": "ftjob-Na7BnF5y91wwGJ4EgxtzVyDD",
"created_at": 1693582679,
"level": "info",
"message": "Step 100/100: training loss=0.00",
"data": {
"step": 100,
"train_loss": 1.805623287509661e-5,
"train_mean_token_accuracy": 1.0
},
"type": "metrics"
}
You can also see this information on the UI as well.
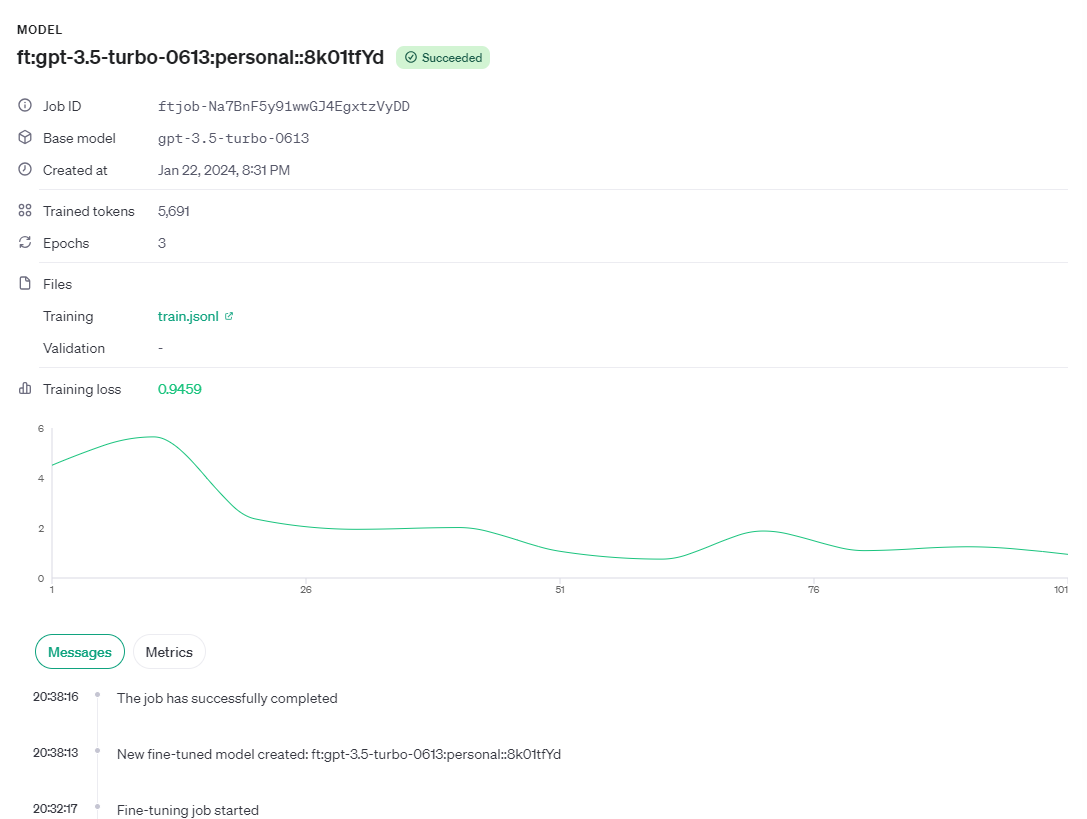
Upon successful completion of a job, the job details will include the fine_tuned_model field, displaying the name of the model. You can make an API call to this model and get a response from the model that we just tuned.
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0613:personal::8k01tfYd",
messages=[
{"role": "system", "content": "You are a teaching assistant for Machine Learning. You should help to user to answer on his question."},
{"role": "user", "content": "What is a loss function?"}
]
)
print(completion.choices[0].message)Output:
ChatCompletionMessage(content="To measure how far we falter, it guides our way, our hope's defaulter.", role='assistant', function_call=None, tool_calls=None)This tutorial has guided you through the process of fine-tuning OpenAI's GPT model, an advanced step in leveraging the LLM's vast capabilities for specialized domain applications. Fine-tuning allows us to refine the language model’s responses, making them more adept at handling specific tasks, styles, or domains with greater precision and efficiency.
This tutorial uses OpenAI Python API for fine-tuning a model. If you prefer to learn how to do the same thing through a UI without writing a single line of code, you can check out How to Fine Tune GPT 3.5 tutorial on Datacamp.
Since GPT is not an open-source model the process of fine-tuning is rather simple and just involves making an API call. This is very different when it comes to fine-tuning open-source models like llama-2, Mistral, Stable diffusion, etc. If you are interested in learning how to fine-tune various open-source models, you can check out these blogs on DataCamp:
For more beginner resources on fine-tuning LLM, check out An Introductory Guide to Fine-Tuning LLMs on Datacamp.
Start Your AI Journey Today!
Course
Course
Course
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
code-along
Zoumana Keita


