Table of Contents
- Introduction
- Use-case: Training Machine Learning Models In-Database
- Databases Supporting In-Database Machine Learning
- Microsoft SQL Server Machine Learning Services
- PyCaret: An Open-Source, Low-Code Machine Learning Library in Python
- End-to-End Demo of Training ML Models in SQL
- Download and install SQL Server
- Create a new database and import CSV file
- Configure Python Environment
- Train an unsupervised clustering model
- Conclusion
Introduction
Python and R are widely used programming languages adopted by data scientists, data engineers, and machine learning engineers. Being able to run Python code as a SQL script opens up endless possibilities for data operations including in-database machine learning capabilities when dealing with large amounts of data. The go-to tools for performing machine learning experiments are integrated development environments (IDE) like VS Code or Notebooks, which are interactive in nature. However, these tools may pose limitations when the data size gets very large, or when the ML model is required to be put into production. There has been a dire need to have the ability to program and train models where data reside; in this tutorial, you will learn about several ways to achieve this.
Use-Case: Training Machine Learning Models In-Database
A lot of databases these days come with built-in machine learning services (see next section). This means that you do not have to go out and acquire a data science platform, as you can use in-database machine learning capabilities to train and deploy your models in the database. A typical machine learning workflow looks like this:
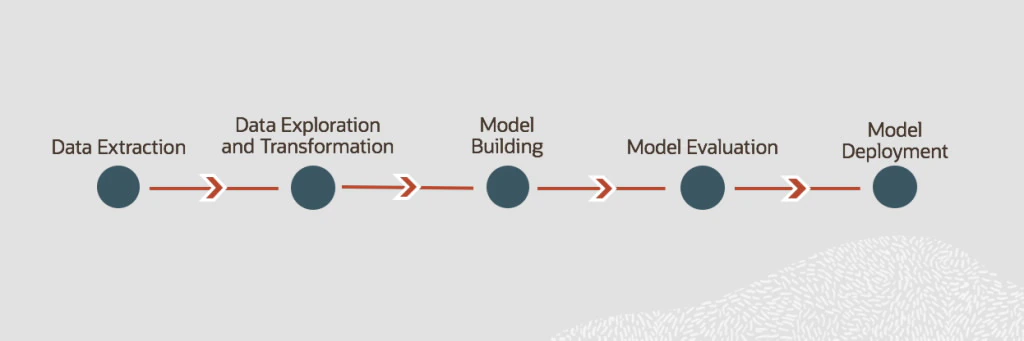
When you are training a machine learning model in-database, you do not need a stand-alone ETL process since your data is already in the database. This saves a lot of time. For subsequent steps such as Model Building and Deployment, you also do not need to transfer to any external machine learning platform as you will be using in-database capabilities to train and deploy an ML solution. As per Oracle Big Data Blog, there are three benefits in doing this:
Overall process is simplified
It can often take hours or days just to move the data to another platform where the algorithms reside. Despite this process introducing complications such as potential data loss, it is actually still standard for most other companies.
You save time/costs
It is more logical to move the algorithms over to the database instead of moving data to algorithms. Thus, pairing machine learning with the database is more practical not only in terms of simplicity but also speed. You save time and a lot of effort, which eventually impact the bottom line by saving costs.
You get the results (value) faster
The fact is that although it may take a lot of time and effort to build a machine learning model, train it, get the results, and analyze them, businesses are not usually interested in machine learning until the model is deployed into production so that the departments in charge of organization (Finance, HR, Supply Chain, Marketing, Sales, etc.) can make use of the results.
Because deployment and integration into applications like business intelligence (BI) dashboards, call centers, ATMs, websites, and mobile devices can be a very big challenge for IT, operationalization can either be simple or very complex.
If your model has been in the database all along, the amount of complicated deployment work is greatly reduced. This makes the process much easier and the results are obtained much faster.
Databases Supporting In-Database Machine Learning
Microsoft SQL Server
Microsoft SQL Server Machine Learning Services supports R, Python, Java, the PREDICT T-SQL command, and the rx_Predict stored procedure in the SQL Server RDBMS, and SparkML in SQL Server Big Data Clusters. In the R and Python languages, Microsoft includes several packages and libraries for machine learning. You can store your trained models in the database or externally. Azure SQL Managed Instance supports Machine Learning Services for Python and R as a preview. Learn More.
Amazon Redshift
Amazon Redshift is a managed, petabyte-scale data warehouse service designed to make it simple and cost-effective to analyze all of your data using your existing business intelligence tools. It is optimized for datasets ranging from a few hundred gigabytes to a petabyte or more and costs less than $1,000 per terabyte per year. Learn More.
Oracle Database
Oracle Cloud Infrastructure (OCI) Data Science is a managed and serverless platform for data science teams to build, train, and manage machine learning models using Oracle Cloud Infrastructure including Oracle Autonomous Database and Oracle Autonomous Data Warehouse. It includes Python-centric tools, libraries, and packages developed by the open source community and the Oracle Accelerated Data Science (ADS) Library, which supports the end-to-end lifecycle of predictive models. Learn More.
Google Cloud BigQuery
BigQuery is Google Cloud’s managed, petabyte-scale data warehouse that lets you run analytics over vast amounts of data in near real time. BigQuery ML lets you create and execute machine learning models in BigQuery using SQL queries. BigQuery ML supports linear regression for forecasting; binary and multi-class logistic regression for classification; K-means clustering for data segmentation; matrix factorization for creating product recommendation systems and time series for performing time-series forecasts. Learn More.
IBM Db2 Warehouse
IBM Db2 Warehouse on Cloud is a managed public cloud service. You can also set up IBM Db2 Warehouse on premises with your own hardware or in a private cloud. As a data warehouse, it includes features such as in-memory data processing and columnar tables for online analytical processing. Its Netezza technology provides a robust set of analytics that are designed to efficiently bring the query to the data. Learn More.
BlazingSQL
BlazingSQL is a GPU-accelerated SQL engine built on top of the RAPIDS ecosystem; it exists as an open-source project and a paid service. RAPIDS, which uses CUDA and is based on the Apache Arrow columnar memory format, is a suite of open-source software libraries and APIs, incubated by Nvidia - CuDF, a part of RAPIDS, is a Pandas-like GPU DataFrame library for loading, joining, aggregating, filtering, and otherwise manipulating data. Learn More.
Microsoft SQL Server Machine Learning Services
Machine Learning Services is a feature in SQL Server that gives you the ability to run Python and R scripts with relational data. You can use open-source packages and frameworks, and the Microsoft Python and R packages, for predictive analytics and machine learning. The scripts are executed in-database without moving data outside SQL Server or over the network. This article explains the basics of SQL Server Machine Learning Services and how to get started.
SQL Server Machine Learning Services lets you execute Python and R scripts in-database. You can use it to prepare and clean data, do feature engineering, and train, evaluate, and deploy machine learning models within a database. The feature runs your scripts where the data resides and eliminates having to transfer the data across the network to another server.
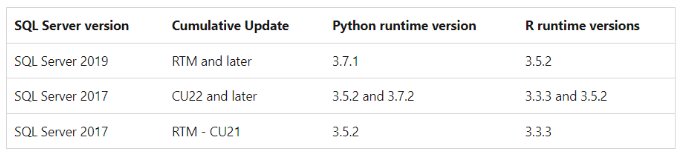
Python and R versions supported
As of now, the following Python and R versions are supported in SQL Machine Learning Services.
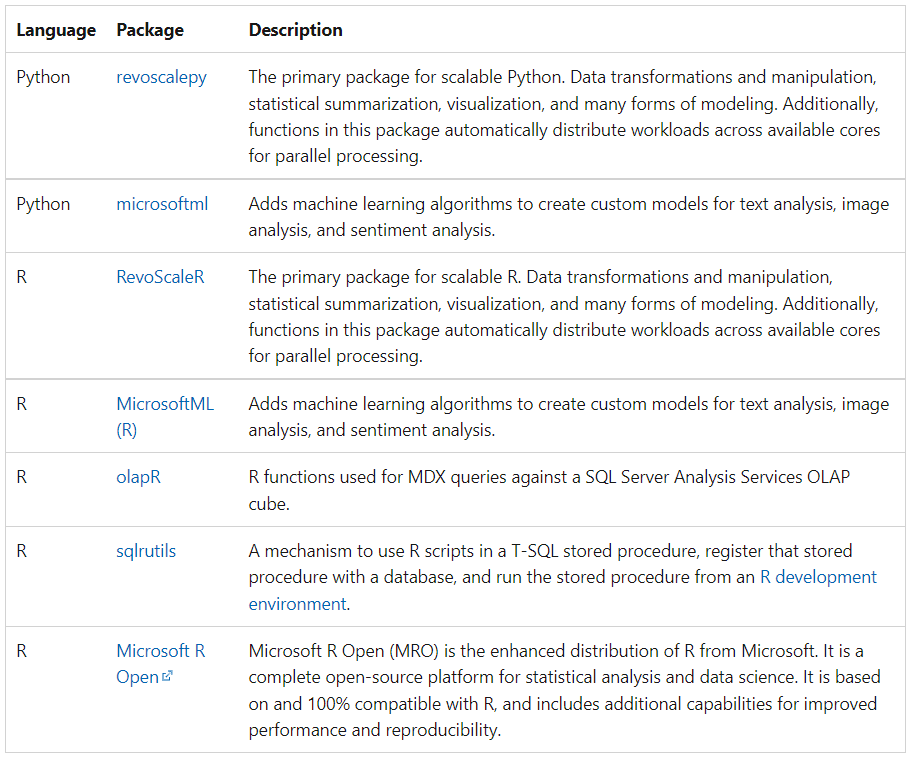
Python and R libraries installed by default
You can use any open-source packages and frameworks you like, but the following Python and R packages come installed by default:
PyCaret: An Open-Source, Low-Code ML Library
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that exponentially speeds up the experiment cycle and improves productivity.
Compared with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with only a few lines. This makes experiments exponentially fast and efficient. PyCaret is essentially a Python wrapper around several machine learning libraries and frameworks such as scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray, and a few more.
The design and simplicity of PyCaret were inspired by the emerging role of citizen data scientists, a term first used by Gartner. Citizen data scientists are power users who can perform both simple and moderately sophisticated analytical tasks that would previously have required more technical expertise. Check out this link to learn more about PyCaret.
In the following section, we will install Microsoft SQL Server and enable SQL Machine Learning Services. We will then enable the Python environment, install PyCaret (ML library) and get into model training. Let’s see how.
End-to-End Demo of Training ML Models in SQL
Download and install SQL Server and Microsoft SSMS
Microsoft SQL Server is a Microsoft relational database management system. As a database server, it performs the primary function of storing and retrieving data as requested by different applications. In this tutorial, we will use SQL Server 2019 Developer for training an unsupervised machine learning model through PyCaret.
If you have used SQL Server before, it is likely that you have it installed and have access to the database. If not, click here to download SQL Server 2019 Developer editions.
Click on the “Download now” button below the Developer edition and open the installer file. Click on “Custom” installation type.
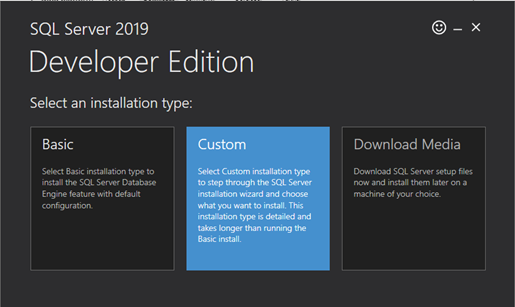
Choose New SQL Server stand-alone installation.

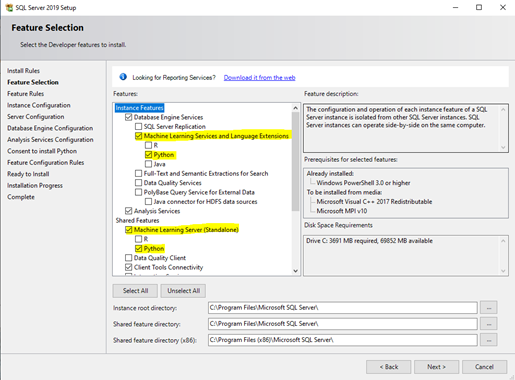
In the Instance Features option, select the features including “Python” under Machine Learning Services and Language Extensions and Machine Learning Server.
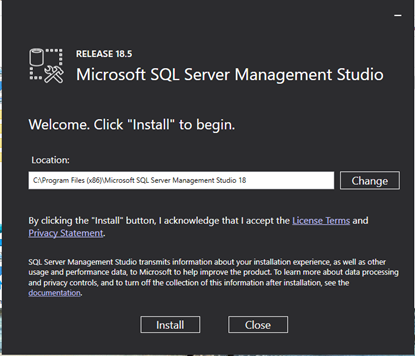
Once SQL Server is successfully installed, we need to work with an Integrated Development Environment (IDE). There are many options available; however, in this tutorial I will be using Microsoft SQL Server Management Studio. Download the installer and follow the instructions. Installing SSMS is straightforward.
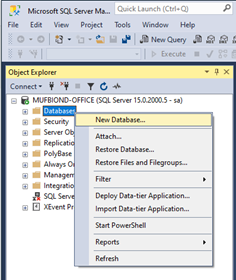
Create a new database and import CSV
Once SQL Server and SSMS are installed, we will have to create a new database and import a CSV file to work with it. In the Object Explorer panel, right-click on Databases, and choose “New Database”. Enter the database name and other information. This may take a few minutes.
Once the database is successfully created, let’s import a CSV file that we will work with in the next few steps. You can download the sample file on your computer and then follow the instructions.
Right-click on “Tables” → New → Table. You can name it whatever you like. In this example, I am naming this table “jewelry”.
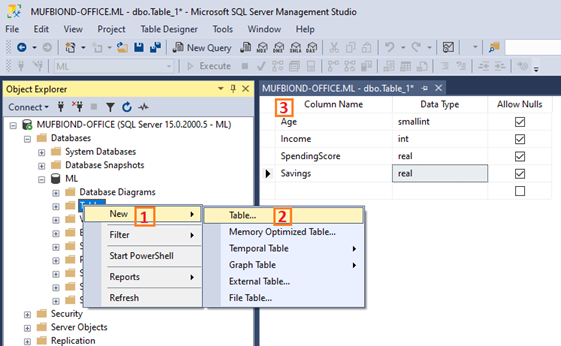
Now that the table has been created we can give it some content. Let’s import the CSV file into this table. Right-click the database and select Tasks -> Import Data
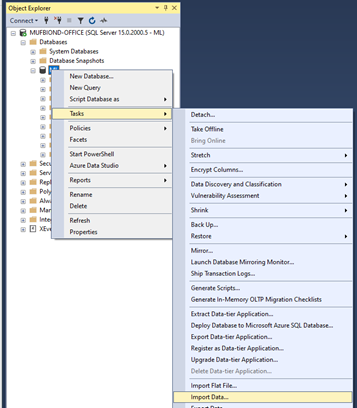
For Data Source, select “Flat File Source”, then use the Browse button to select the CSV file. Spend some time configuring the data import before clicking the Next button.
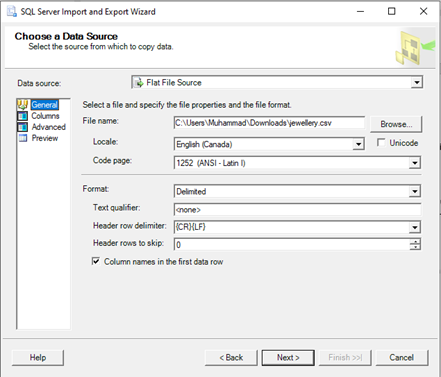
Click on Next and enter the database details (server name, username and password) and follow the instructions on the following screens. Finally, Click the Finish button to complete the import.
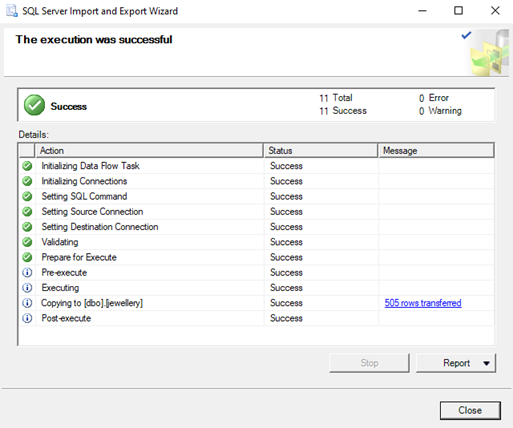
Now, we have a table “jewelry” with imported data.
Configure Python Environment
Before we start training machine learning models in SQL, we will have to configure Python script in SQL. We will run Python “inside” the SQL Server by using the sp_execute_external_script system stored procedure. To begin, click on a “New Query” and execute the following code to enable the use of the procedure for remote script execution:
EXEC sp_configure ‘external scripts enabled’, 1
RECONFIGURE WITH OVERRIDERestart the SQL server before proceeding any further.
Now, let’s set the language and check the path of the installation. With Microsoft SQL Machine Learning Service, you have two options: R or Python. In this example, we will use Python, or more specifically PyCaret (A python library for machine learning), to train an unsupervised clustering model on the “jewelry” dataset.
EXECUTE sp_execute_external_script
@language =N’Python’,
@script=N’import sys; print(“\n”.join(sys.path))’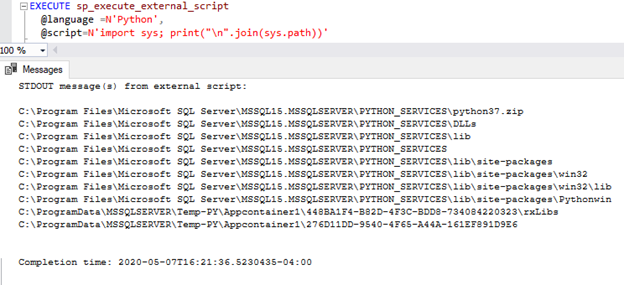
The final step before we start training the model is to install the PyCaret library. To install the PyCaret package, open a command prompt and browse to the location of Python packages where SQL Server is installed (see the path above). Run the following code on command prompt.
pip.exe install pycaret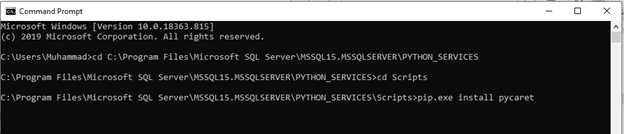
Installation may take 10-15 minutes. Once it is done, it will look like this:

Now, head over to the Microsoft SSMS.
Train an unsupervised clustering model
Clustering is a machine learning technique that groups data points with similar characteristics. These groupings are useful for exploring data, identifying patterns, and analyzing a subset of data. Some common business use cases for clustering are:
- Customer segmentation for the purpose of marketing.
- Customer purchasing behavior analysis for promotions and discounts.
- Identifying geo-clusters in an epidemic outbreak such as COVID-19.
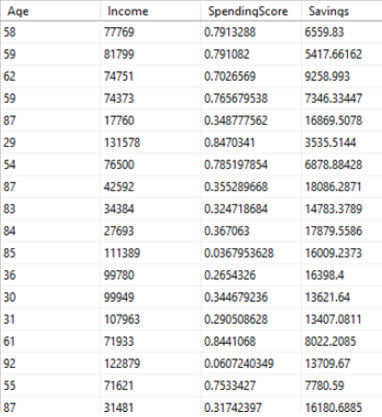
We have four data points per customer which looks like this:
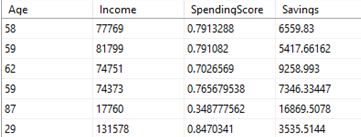
Our goal is to train KMeans clustering model on this dataset and create a new column “Cluster” which represents the group of customers which belong together.
EXECUTE sp_execute_external_script
@language = N’Python’,
@script = N’dataset = InputDataSet
import pycaret.clustering as pc
dataset = pc.get_clusters(data = dataset, num_clusters=4)
OutputDataSet = dataset’,
@input_data_1 = N’SELECT [Age], [Income], [SpendingScore], [Savings] FROM [jewellery]’
WITH RESULT SETS(([Age] INT, [Income] INT, [SpendingScore] FLOAT, [Savings] FLOAT, [Cluster] varchar(15)));Output:
Notice how easy that was. With just one line `pc.get_clusters(...)`, we have preprocessed the data, trained an unsupervised KMeans model, and used the trained model to generate the cluster labels – all without having to leave the SQL server environment. Similar to clustering, PyCaret also supports unsupervised anomaly detection with `pc.get_anomaly` magic command. You can also train supervised machine learning models (Classification or Regression), store the model in SQL procedure, and use it later to generate inference. This can all be done right from your database.
Conclusion
What does machine learning in the database mean for your business? It means that you can minimize the number of steps you need to take for more efficient, faster, and easier to operationalize machine learning. Training machine learning models in the database minimizes data movement, which saves time and costs. However, this is not a silver bullet. Whether you employ it or not will always depend on the use case. Hopefully, this tutorial has given you a new perspective on the possibilities of machine learning in enterprise environments.
If you would like to learn more about how Python and SQL can be used together to improve your data analysis and efficiency then I recommend you take Introduction to Databases in Python course. In this course, you'll learn the basics of using SQL with Python. This will be useful because databases are ubiquitous and data scientists, analysts, and engineers must interact with them constantly. The Python SQL toolkit SQLAlchemy provides an accessible and intuitive way to query, build, and write to essential databases, including SQLite, MySQL, and PostgreSQL.