Foundations of Probability in Python
BeginnerSkill Level
5 hr
12K learners
Run and edit the code from this tutorial online
Run codePerhaps one of the simplest and useful distribution is the uniform distribution. The probability distribution function of the continuous uniform distribution is:
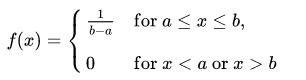
Since any interval of numbers of equal width has an equal probability of being observed, the curve describing the distribution is a rectangle, with constant height across the interval and 0 height elsewhere. Since the area under the curve must be equal to 1, the length of the interval determines the height of the curve. The following figure shows a uniform distribution in interval (a,b). Notice since the area needs to be $1$. The height is set to $1/(b-a)$.
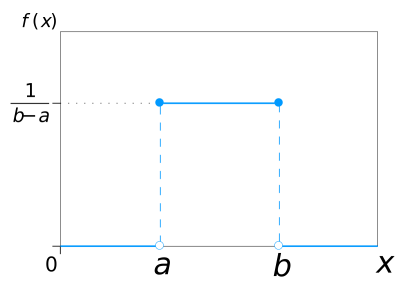
You can visualize uniform distribution in python with the help of a random number generator acting over an interval of numbers (a,b). You need to import the uniform function from scipy.stats module.
# import uniform distribution
from scipy.stats import uniform
The uniform function generates a uniform continuous variable between the specified interval via its loc and scale arguments. This distribution is constant between loc and loc + scale. The size arguments describe the number of random variates. If you want to maintain reproducibility, include a random_state argument assigned to a number.
# random numbers from uniform distribution
n = 10000
start = 10
width = 20
data_uniform = uniform.rvs(size=n, loc = start, scale=width)
You can use Seaborn’s distplot to plot the histogram of the distribution you just created. Seaborn’s distplot takes in multiple arguments to customize the plot. You first create a plot object ax. Here, you can specify the number of bins in the histogram, specify the color of the histogram and specify density plot option with kde and linewidth option with hist_kws. You can also set labels for x and y axis using the xlabel and ylabel arguments.
ax = sns.distplot(data_uniform,
bins=100,
kde=True,
color='skyblue',
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Uniform Distribution ', ylabel='Frequency')
[Text(0,0.5,u'Frequency'), Text(0.5,0,u'Uniform Distribution ')]
Normal Distribution, also known as Gaussian distribution, is ubiquitous in Data Science. You will encounter it at many places especially in topics of statistical inference. It is one of the assumptions of many data science algorithms too.
A normal distribution has a bell-shaped density curve described by its mean $μ$ and standard deviation $σ$. The density curve is symmetrical, centered about its mean, with its spread determined by its standard deviation showing that data near the mean are more frequent in occurrence than data far from the mean. The probability distribution function of a normal density curve with mean $μ$ and standard deviation $σ$ at a given point $x$ is given by:
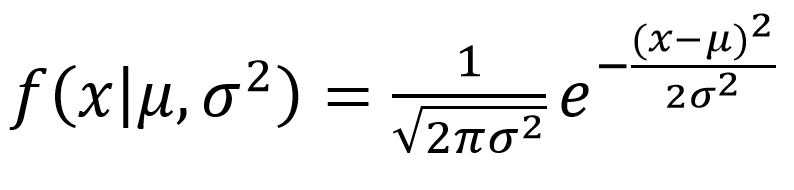
Below is the figure describing what the distribution looks like:
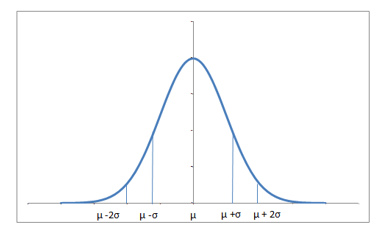
Almost 68% of the data falls within a distance of one standard deviation from the mean on either side and 95% within two standard deviations. Also it worth mentioning that a distribution with mean $0$ and standard deviation $1$ is called a standard normal distribution.
You can generate a normally distributed random variable using scipy.stats module's norm.rvs() method. The loc argument corresponds to the mean of the distribution. scale corresponds to standard deviation and size to the number of random variates. If you want to maintain reproducibility, include a random_state argument assigned to a number.
from scipy.stats import norm
# generate random numbers from N(0,1)
data_normal = norm.rvs(size=10000,loc=0,scale=1)
You can visualize the distribution just like you did with the uniform distribution, using seaborn's distplot functions. The meaning of the arguments remains the same as in the last case.
ax = sns.distplot(data_normal,
bins=100,
kde=True,
color='skyblue',
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Normal Distribution', ylabel='Frequency')
[Text(0,0.5,u'Frequency'), Text(0.5,0,u'Normal Distribution')]
The gamma distribution is a two-parameter family of continuous probability distributions. While it is used rarely in its raw form but other popularly used distributions like exponential, chi-squared, erlang distributions are special cases of the gamma distribution. The gamma distribution can be parameterized in terms of a shape parameter $α = k$ and an inverse scale parameter $β = 1/θ$, called a rate parameter., the symbol $Γ(n)$ is the gamma function and is defined as $(n-1)!$ :
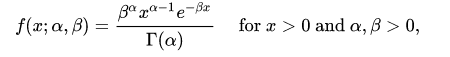
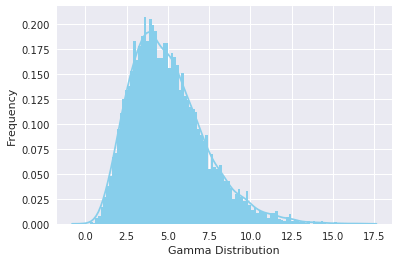
A typical gamma distribution looks like:
You can generate a gamma distributed random variable using scipy.stats module's gamma.rvs() method which takes shape parameter $a$ as its argument. When $a$ is an integer, gamma reduces to the Erlang distribution, and when $a=1$ to the exponential distribution. To shift distribution use the loc argument, to scale use scale argument, size decides the number of random variates in the distribution. If you want to maintain reproducibility, include a random_state argument assigned to a number.
from scipy.stats import gamma
data_gamma = gamma.rvs(a=5, size=10000)
You can visualize the distribution just like you did with the uniform distribution, using seaborn's distplot functions. The meaning of the arguments remains the same as explained in the uniform distribution section.
ax = sns.distplot(data_gamma,
kde=True,
bins=100,
color='skyblue',
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Gamma Distribution', ylabel='Frequency')
[Text(0,0.5,u'Frequency'), Text(0.5,0,u'Gamma Distribution')]
The exponential distribution describes the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. It has a parameter $λ$ called rate parameter, and its equation is described as :
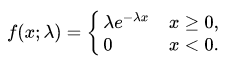
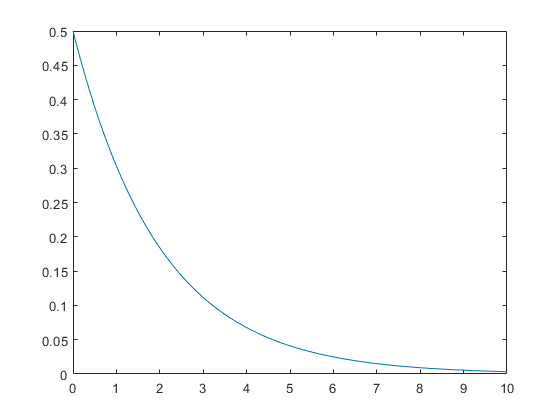
A decreasing exponential distribution looks like :
You can generate an exponentially distributed random variable using scipy.stats module's expon.rvs() method which takes shape parameter scale as its argument which is nothing but 1/lambda in the equation. To shift distribution use the loc argument, size decides the number of random variates in the distribution. If you want to maintain reproducibility, include a random_state argument assigned to a number.
from scipy.stats import expon
data_expon = expon.rvs(scale=1,loc=0,size=1000)
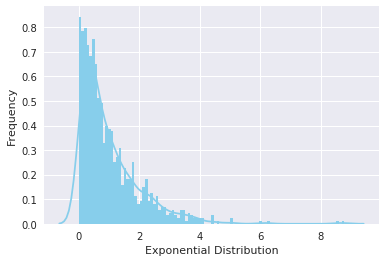
Again visualizing the distribution with seaborn yields the curve shown below:
ax = sns.distplot(data_expon,
kde=True,
bins=100,
color='skyblue',
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Exponential Distribution', ylabel='Frequency')
[Text(0,0.5,u'Frequency'), Text(0.5,0,u'Exponential Distribution')]
Poisson random variable is typically used to model the number of times an event happened in a time interval. For example, the number of users visited on a website in an interval can be thought of a Poisson process. Poisson distribution is described in terms of the rate ($μ$) at which the events happen. An event can occur 0, 1, 2, … times in an interval. The average number of events in an interval is designated $λ$ (lambda). Lambda is the event rate, also called the rate parameter. The probability of observing $k$ events in an interval is given by the equation:
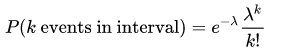
Note that the normal distribution is a limiting case of Poisson distribution with the parameter $λ →∞$. Also, if the times between random events follow an exponential distribution with rate $λ$, then the total number of events in a time period of length $t$ follows the Poisson distribution with parameter $λt$.
The following figure shows a typical poisson distribution:
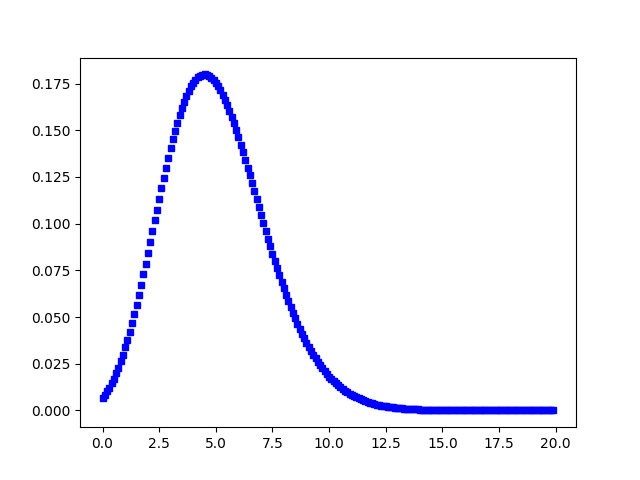
You can generate a poisson distributed discrete random variable using scipy.stats module's poisson.rvs() method which takes $μ$ as a shape parameter and is nothing but the $λ$ in the equation. To shift distribution use the loc parameter. size decides the number of random variates in the distribution. If you want to maintain reproducibility, include a random_state argument assigned to a number.
from scipy.stats import poisson
data_poisson = poisson.rvs(mu=3, size=10000)
You can visualize the distribution just like you did with the uniform distribution, using seaborn's distplot functions. The meaning of the arguments remains the same.
ax = sns.distplot(data_poisson,
bins=30,
kde=False,
color='skyblue',
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Poisson Distribution', ylabel='Frequency')
[Text(0,0.5,u'Frequency'), Text(0.5,0,u'Poisson Distribution')]
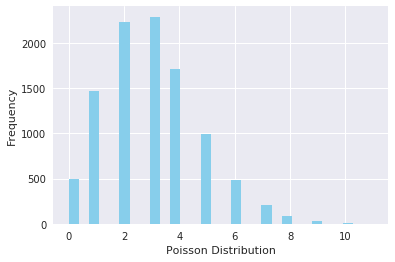
A distribution where only two outcomes are possible, such as success or failure, gain or loss, win or lose and where the probability of success and failure is same for all the trials is called a Binomial Distribution. However, The outcomes need not be equally likely, and each trial is independent of each other. The parameters of a binomial distribution are $n$ and $p$ where $n$ is the total number of trials, and $p$ is the probability of success in each trial. Its probability distribution function is given by :
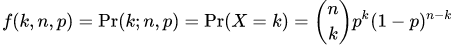
where :
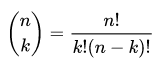
You can generate a binomial distributed discrete random variable using scipy.stats module's binom.rvs() method which takes $n$ (number of trials) and $p$ (probability of success) as shape parameters. To shift distribution use the loc parameter. size decides the number of times to repeat the trials. If you want to maintain reproducibility, include a random_state argument assigned to a number.
from scipy.stats import binom
data_binom = binom.rvs(n=10,p=0.8,size=10000)
Visualizing the distribution you just created using seaborn's distplot renders the following histogram:
ax = sns.distplot(data_binom,
kde=False,
color='skyblue',
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Binomial Distribution', ylabel='Frequency')
[Text(0,0.5,u'Frequency'), Text(0.5,0,u'Binomial Distribution')]
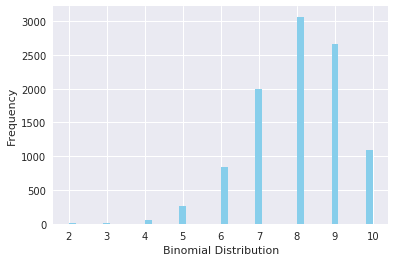
Note that since the probability of success was greater than $0.5$ the distribution is skewed towards the right side. Also, poisson distribution is a limiting case of a binomial distribution under the following conditions:
Normal distribution is another limiting form of binomial distribution under the following conditions:
A Bernoulli distribution has only two possible outcomes, namely $1$ (success) and $0$ (failure), and a single trial, for example, a coin toss. So the random variable $X$ which has a Bernoulli distribution can take value $1$ with the probability of success, $p$, and the value $0$ with the probability of failure, $q$ or $1-p$. The probabilities of success and failure need not be equally likely. The Bernoulli distribution is a special case of the binomial distribution where a single trial is conducted ($n=1$). Its probability mass function is given by:
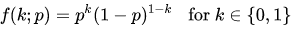
You can generate a bernoulli distributed discrete random variable using scipy.stats module's bernoulli.rvs() method which takes $p$ (probability of success) as a shape parameter. To shift distribution use the loc parameter. size decides the number of times to repeat the trials. If you want to maintain reproducibility, include a random_state argument assigned to a number.
from scipy.stats import bernoulli
data_bern = bernoulli.rvs(size=10000,p=0.6)
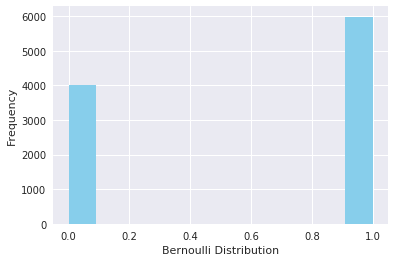
Again visulaizing the distribution, you can observe that you have only two possible outcomes:
ax= sns.distplot(data_bern,
kde=False,
color="skyblue",
hist_kws={"linewidth": 15,'alpha':1})
ax.set(xlabel='Bernoulli Distribution', ylabel='Frequency')
[Text(0,0.5,u'Frequency'), Text(0.5,0,u'Bernoulli Distribution')]
Congrats, you have made it to the end of this tutorial! In this tutorial, you explored some commonly used probability distributions and learned to create and plot them in python. Although there are many other distributions to be explored, this will be sufficient for you to get started. Don't forget to check out python's scipy library which has other cool statistical functionalities. Happy exploring!
If you would like to learn more about probability in Python, take DataCamp's Statistical Simulation in Python course.
Check out our Poker Probability and Statistics with Python tutorial.
Python Courses
Course
Course
Course
Tutorial
Daniel Poston
Tutorial
Sayak Paul
Tutorial
Matthew Przybyla
Tutorial
Avinash Navlani
Tutorial
Aditya Sharma
code-along
Justin Saddlemyer
