
Track
AI Business Fundamentals
12 hr
To access Runway Gen-4, we need a subscription. Be aware that it’s still rolling out, so depending on where you’re located, it might not be available yet or might only be available on higher-tier subscriptions. In the US, a $12 subscription gives us 625 credits to use Gen-4.
Moreover, even after subscribing, I had to wait one day for it to become available on my account.
Videos in Runway ML are generated inside sessions. To create a video, we first need to create a new session by selecting the “Sessions” item in the menu on the left:
Then we click the “New Session” button on the right to create a session:
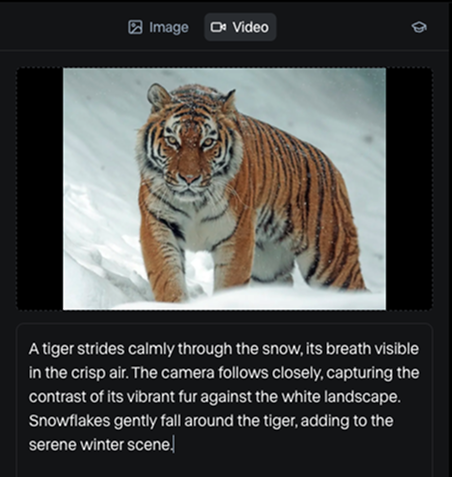
When we open the session, we’re presented with a simple interface where we can combine an image and a text prompt to generate a video:
Image source: Pexels
Make sure to select the Gen-4 model at the bottom:
Here’s the result:
The video is pretty good in my opinion.
If you need guidance creating a prompt, they provide this guideline page. The way I used the guidelines to generate prompts is that I created an AI bot with the guidelines, designed to transform my high-level ideas into usable Runway prompts.
Note that, unlike other video generation models out there, we can’t generate a video from text only—the model always requires an image.
In this first example, I used a free-to-use image that I found online. These can be a great resource for creating videos.
Runway also provides an image generation model. However, for some reason, it wasn’t available on the basic plan, and I had to subscribe to their most expensive plan to access it.
To generate an image:
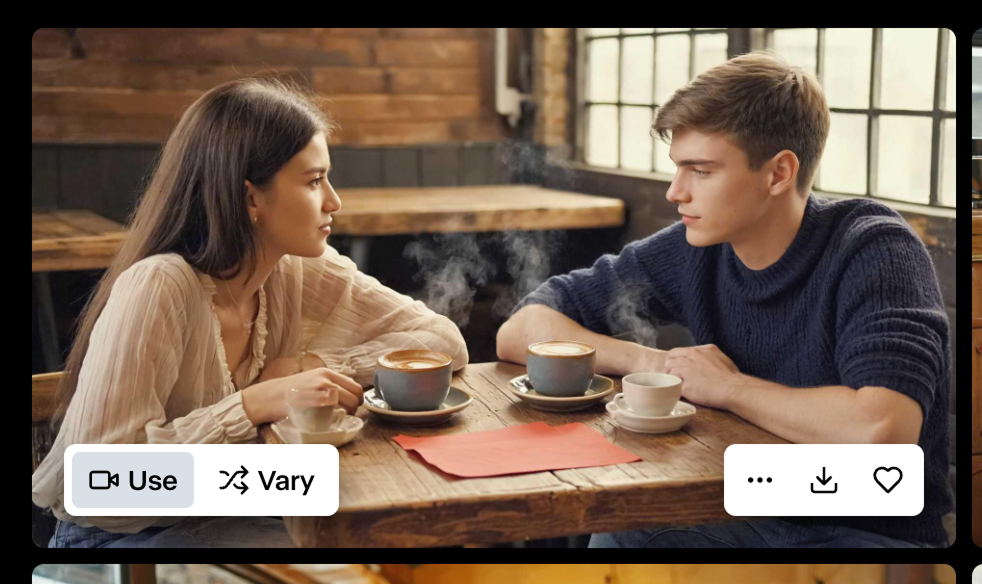
The model generated these four images:

Only the bottom two comply with the prompt. We can see both images on the top have more than two coffee cups, and the first even has some strange artefacts.
The reason I asked for a red paper on the table is that I wanted to generate a video from this image of the man creating an origami paper flower to give to the girl.
To do so, we can hover the image we want to use and click the “Use” button:
I created a prompt asking to create a video with a fixed camera of the man making an origami flower and giving it to the girl. I tried it twice, once generating a 5-second video and then a 10-second one. The results were quite disappointing this time (I used Gen-4 here):
I expected to be able to provide an image of my character, generate the scene images with that character in them, and finally generate each scene using Gen-4. However, that’s not supported, at least for now.
In the image generation tab, we see a “References” feature that isn’t available yet.
I find this misleading because, without that feature, the videos in their announcement simply aren't possible to make.
Fortunately, both Google and OpenAI recently released this feature in their image generation models. Google’s Gemini 2.0 has a storytelling mode that will generate a series of images for a given story, while OpenAI’s GPT-4o image generator can take a reference image and make it into whatever we want. If you want to learn more about these two tools, I covered them here:
Here’s a video I created asking Gemini to tell a visual story about a flame and a water drop that fall in love but learn that they can’t touch each other.
In the storytelling mode, Gemini generates a sequence of images to tell a visual story. Then, I used an AI tool to generate prompts based on Runway’s guidelines to animate each of the frames. Here’s the result:
Learn AI with these courses!
Track
Track
Course
blog
Iva Vrtaric
11 min
blog
François Aubry
8 min
Tutorial
François Aubry
Tutorial
François Aubry
Tutorial
Arunn Thevapalan
Tutorial
Dimitri Didmanidze
