Become a Data Engineer
The ecosystem of Apache Hadoop
Hadoop became the de facto standard for data processing, much like Excel has gradually become the default software for data analysis. Unlike Excel, Hadoop was designed by developers rather than "Business Analysts", yet large-scale adoption and success depend on business analysts rather than developers. For this reason the problems of Big Data have been segmented from a functional point of view, and for each segment, technologies based on Hadoop have been developed to meet its challenges. All of these tools form what is called the Hadoop ecosystem.
The Hadoop ecosystem enriches Hadoop and makes it capable of solving a wide variety of business problems. To date, the Hadoop ecosystem is composed of hundreds of technologies that we have chosen to group into 14 categories according to their problematic segments: abstraction languages, SQL on Hadoop (Hive and Pig), computational models (MapReduce and Tez), real-time processing tools (Storm and Spark Streaming), databases (HBase and Cassandra), streaming ingestion tools (Kafka and Flume), data integration tools (Sqoop and Talend), workflow coordination tools (Oozie and Control M for Hadoop), distributed service coordination tools (Zookeeper), cluster administration tools (Ranger and Sentry), user interface tools (Hue and Jupyter), content indexing tools (ElasticSearch and Splunk), distributed file systems (HDFS), and resource managers (YARN and MESOS). This section will review the function of each of the tools that make up this ecosystem of Big Data technologies. After that, if you want to go further, we recommend you read our guides on the differemt Hadoop Ecosystem elements that wil follow this article. The following mind map globally presents the Hadoop ecosystem.
Hadoop ecosystem heuristic map
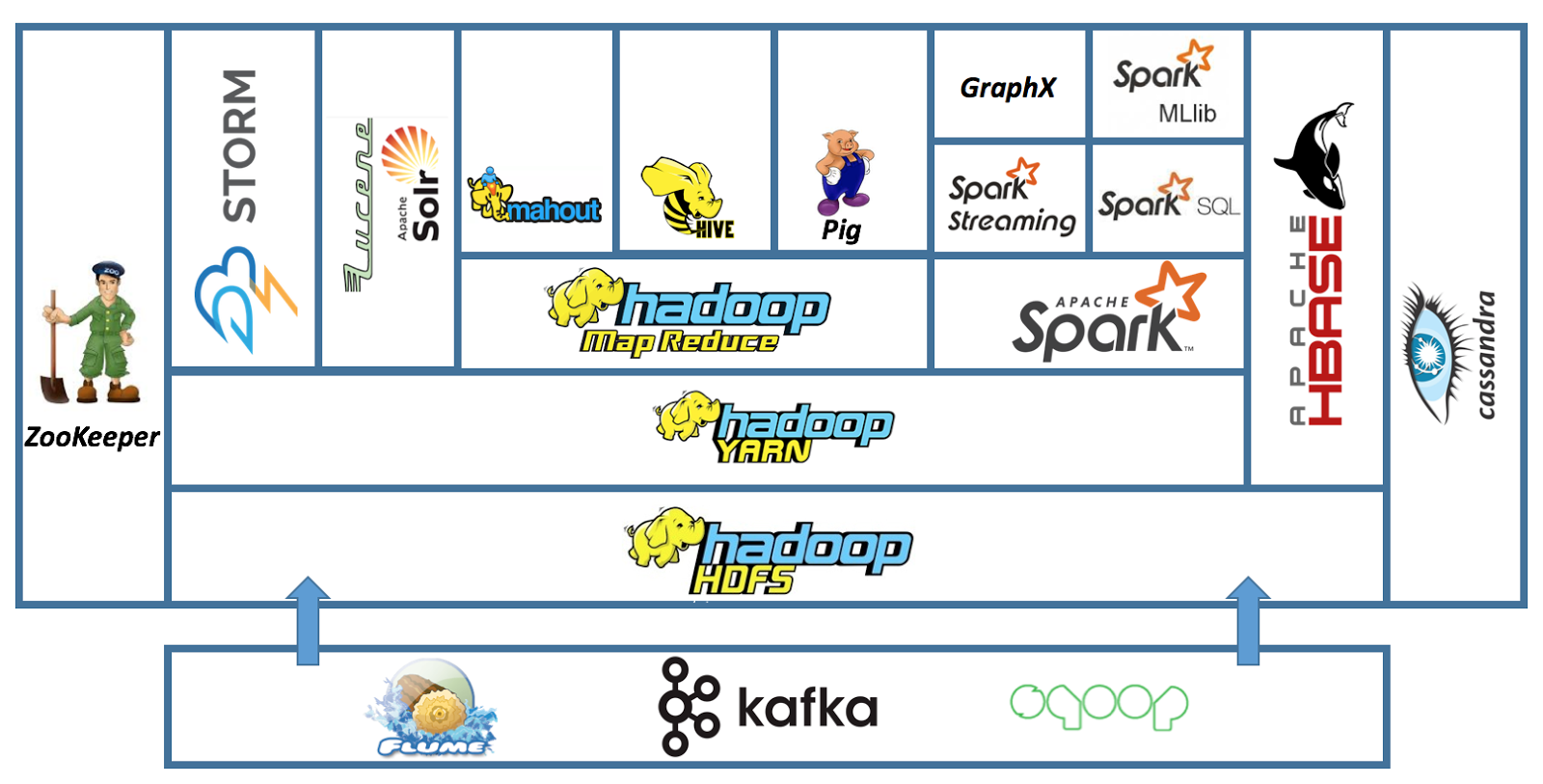
The basic configuration of the Hadoop ecosystem contains the following technologies: Spark, Hive, Pig, HBase, Sqoop, Storm, ZooKeeper, Oozie, and Kafka.
Spark
Before explaining what Spark is, let's remember that it must be parallelizable for an algorithm to run on a multi-node cluster in Hadoop. Thus, an algorithm is said to be "scalable" if it is parallelizable (and can therefore take advantage of the scalability of a cluster). Hadoop is an implementation of the MapReduce computing model. The problem with MapReduce is that it is built on a Direct Acyclic Graph model. In other words, the MapReduce operation sequence runs in three direct sequential phases without detours (Map -> Shuffle -> Reduce); no phase is iterative (or cyclic).
The direct acyclic model is not suitable for some applications, especially those that reuse data across multiple operations, such as most statistical learning algorithms, which are iterative and interactive data analysis queries. Spark answers these limitations; it is a computational engine that performs distributed processing in memory on a cluster. In other words, it's a distributed in-memory computing engine. Compared to MapReduce, which works in batch mode, Spark's computation model works in interactive mode, i.e., assembles the data in memory before processing it and is therefore very suitable for Machine Learning processing.
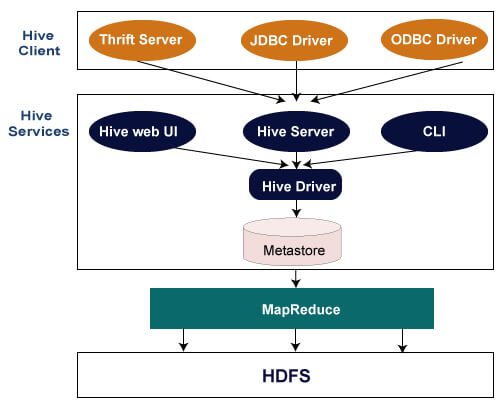
Hive
Hive is a computing infrastructure similar to the Data Warehouse that provides query and aggregation services for very large volumes of data stored on a distributed file system such as HDFS. Hive offers a SQL-based (ANSI-92 standard) query language called HiveQL (Hive Query Language), which addresses queries to data stored on the HDFS. HiveQL also allows advanced users/developers to integrate Map and Reduce functions directly into their queries to cover a wider range of data management problems. When you write a query in HiveQL, that query is transformed into a MapReduce job and submitted to the JobTracker for execution by Hive.
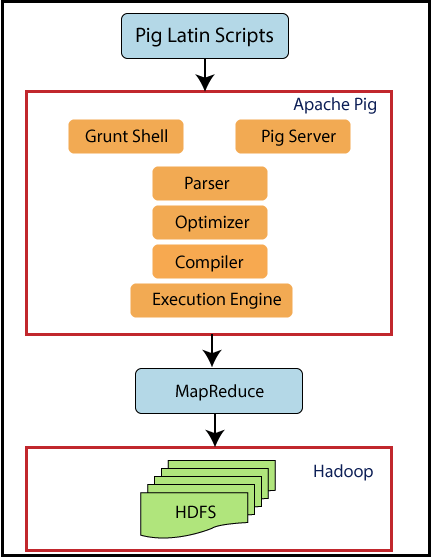
Pig
Pig is an interactive dataflow execution environment under Hadoop. It is composed of 2 elements: a dataflow expression language called Pig Latin, and an interactive dataflow execution environment.
The language offered by Pig, the Pig Latin, is roughly similar to scripting languages such as Perl, Python, or Ruby. However, it is more specific than the latter and is best described as a "data flow language". It allows you to write queries in sequential streams of source data to obtain "target" data under Hadoop in the manner of an ETL. These flows are then transformed into MapReduce functions that are finally submitted to the job tracker for execution. Simply put, Pig is the ETL of Hadoop. Programming in Pig Latin means describing in independent but nested streams how data is loaded, transformed, and aggregated using specific Pig statements called operators. Mastering these operators is the key to mastering Pig Latin programming, especially since there are few of them compared to Hive.
HBase
Before talking about HBase, we will remind you that RDBMS, which has been used until now for data management, have very quickly shown their limits in front of the high volume of data and the diversity of data. Indeed, RDBMS are designed to manage only structured data (table of data inline/columns); moreover, the volume of data increases the latency of the requests. This latency is detrimental to many businesses that require near-real-time responses. New DBMSs called "NoSQL" have been developed to address these limitations. These do not impose any particular structure on the data, can distribute the storage and management of data over several nodes, and are scalable. As a reminder, scalability means that the system's performance remains stable as the processing load increases. HBase belongs to this category of DBMS.
HBase is a distributed, column-oriented DBMS that provides real-time read and write access to data stored on the HDFS. HDFS provides sequential access to data in batch, not suitable for fast data access issues such as streaming; HBase covers these gaps and provides fast access to data stored on HDFS.
HBase is based on Google's "Big Table" DBMS and can store very large volumes of data (billion rows/columns). It depends on ZooKeeper, a distributed coordination service for application development.
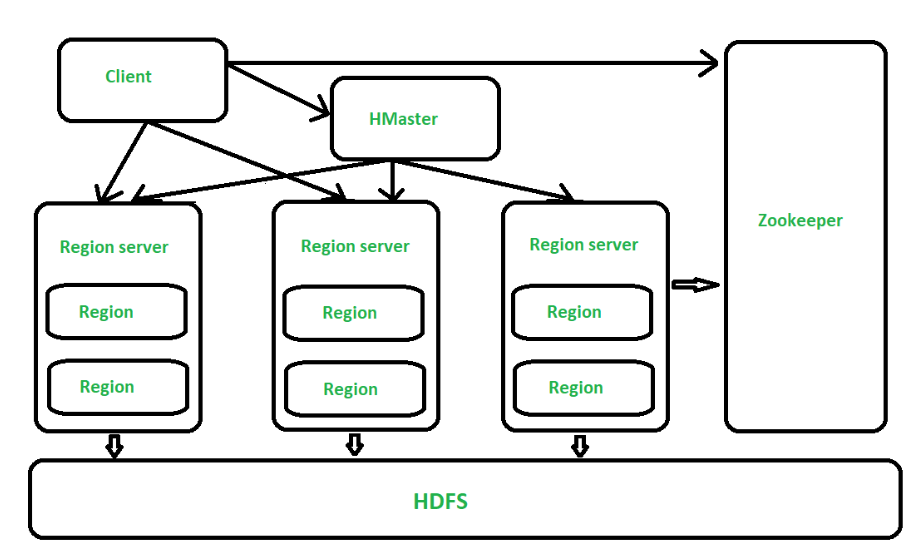
Sqoop
Sqoop or SQL-to-Hadoop is a tool that transfers data from a relational database to Hadoop's HDFS and vice versa. It is integrated with the Hadoop ecosystem and is the data ingestion scheduler in Hadoop. You can use Sqoop to import data from RDBMSs such as MySQL, Oracle, or SQL Server to HDFS, transform the data in Hadoop via MapReduce or another computational model, and export it back to the RDBMS. We call it a data ingestion scheduler because, like Oozie, it automates this import/export process and schedules its execution time. All you have to do as a user is to write the SQL queries that will be used to perform the import/export movement. Moreover, Sqoop uses MapReduce to import and export data, which is efficient and fault-tolerant.
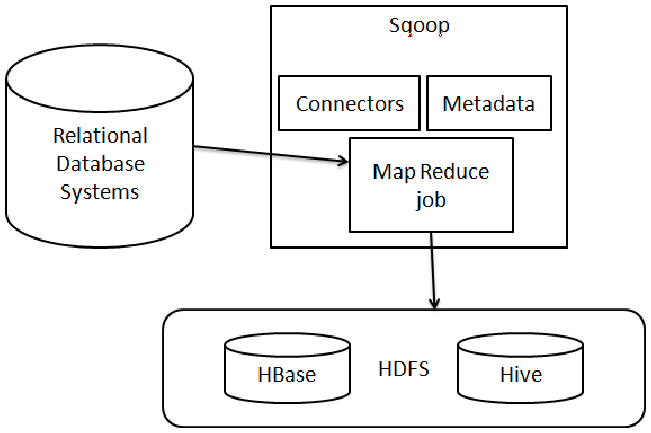
Storm
To understand Storm, you need to understand the concept of lambda architectures (λ) and the interest in lambda architectures. You need to understand the concept of connected objects. The connected objects or Internet of Things (IoT) represent the Internet's extension to our daily lives. It generates streaming data and requires that the data be processed in real-time in most of its issues. The models you are familiar with, such as batch models, are not adapted to the real-time issues raised by the IoT. Even interactive computing models are not adapted to do continuous processing in real-time. Unlike operational data produced by a company's operational systems such as finance marketing, which even when produced in streaming can be historized for later processing, data produced in streaming as part of phenomena such as IoT or the Internet expire (or are no longer valid) in the moments following their creation, and therefore require immediate processing. Apart from connected objects, business problems such as the fight against fraud, and the analysis of social network data, geolocation requires very low response times, taking almost less than a second. To solve this problem in a Big Data context, so-called λ architectures have been developed. These architectures add two additional processing layers to MapReduce for latency reduction. Storm is a software implementation of the λ architecture. It allows applications under Hadoop that process data in real (or near-real) time.
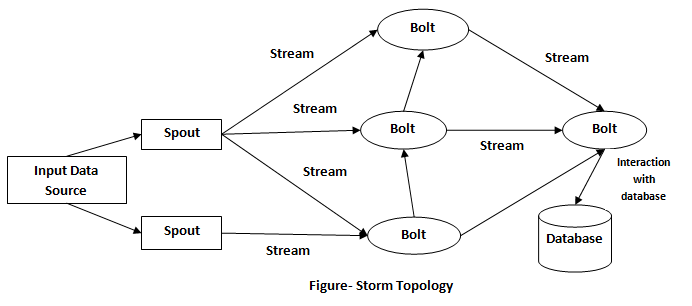
ZooKeeper
Synchronizing or coordinating communication between nodes when executing parallel tasks is one of the most difficult problems in distributed application development. To solve this problem Hadoop has introduced service coordination tools into its ecosystem, in this case, ZooKeeper. ZooKeeper takes care of the inherent complexity of synchronizing the execution of distributed jobs in the cluster and means other tools in the Hadoop ecosystem don't have to deal with this problem themselves. It also allows users to develop distributed applications without being experts in distributed programming. Without getting into the complex details of coordinating data between nodes in a Hadoop cluster, ZooKeeper provides a distributed configuration service, a distribution service, and a naming registry for distributed applications. ZooKeeper is the way Hadoop coordinates distributed jobs.
Oozie
By default, Hadoop executes jobs as the user submits them without considering the relationship they may have with each other. However, the problems for which Hadoop is used generally require the writing of one or more complex jobs. When the two jobs are submitted to the JobTracker (or to YARN), the latter will execute them without paying attention to the link between them, which may cause an error (exception) and lead to the code being stopped. How can we manage the execution of several jobs that are related to the same problem? To manage this type of problem, the simplest solution currently is to use a job scheduler, in this case, Oozie.
Oozie is a job scheduler that runs as a service on a Hadoop cluster. It is used for scheduling Hadoop jobs and more generally for scheduling the execution of all jobs that can run on a cluster, such as a Hive script, MapReduce job, Hama job, Storm job, etc. It has been designed to automatically manage the immediate or delayed execution of thousands of interdependent jobs on a Hadoop cluster. To use Oozie, you just need to configure 2 XML files: an Oozie engine configuration file and a job workflow configuration file.
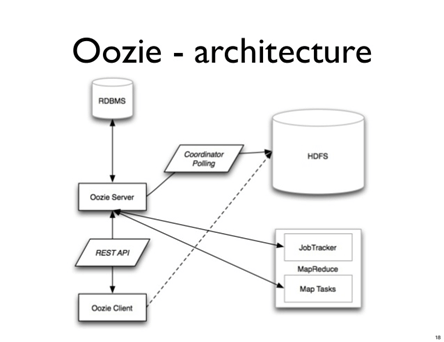
Introducing Cloudera
Cloudera is an American company based in California, dedicated to developing a Big Data solution based historically on the Hadoop distributed framework; it is currently reorienting itself towards the cloud. For over a year, Cloudera has been expanding its solution in the public clouds AWS, Azure, and GCP.
Introducing CDP
The Cloudera Data Platform CDP is a platform that allows companies to analyze data with self-service analytics in hybrid and multi-cloud environments. It allows organizations to get more value out of all their data by creating data lakes in the cloud in a matter of hours.
CDP provides integrated, multi-functional, self-service tools to analyze and centralize data. In addition, it offers enterprise-wide security and governance and can be deployed in public, private, and multi-cloud environments. CDP is the subsequent distribution to Cloudera's two previous Hadoop distributions: Cloudera Distribution of Hadoop (CDH) and Hortonworks Data Platform (HDP).
Self-service access to enterprise data is at the core of this service. The newly added cloud services integrated into the platform also provide self-service access to data and analytics for analysts, data scientists, IT professionals, and developers. The keywords that set the platform apart from its competition are the three Cloud-Native CDP services presented by Cloudera: self-service, multi-cloud, and security.
CDP offers a unique public-private approach, real-time data analytics, scalable on-premise, cloud and hybrid deployment options, and a privacy-first architecture.
CDP Public Cloud
CDP Public Cloud is a Platform-as-a-Service (PaaS) compatible with cloud infrastructure and easily portable between various cloud providers, including private solutions such as OpenShift. CDP was designed to be fully hybrid and multi-cloud, meaning that a single platform can manage all data lifecycle use cases. The CDP platform can work with data with many settings, including public clouds such as AWS, Azure, and GCP. In addition, it can automatically scale workloads and resources up or down to improve performance and reduce costs.
CDP Public Cloud Services
Here are the main components that make up CDP Public Cloud:
-
CDP Data Engineering is an all-in-one setup. It is built on Apache Spark. It streamlines ETL processes across enterprise data analysis teams by enabling orchestration and automation with Apache Airflow and provides highly developed pipeline monitoring, visual debugging, and management tools. In addition, it has isolated working environments and is containerized, scalable, and easy to transport.
-
CDP Data Hub is a service that allows high-value analytics from Edge to AI. The Cloudera Data Hub is a cloud-native data management and analytics service. It enables IT and business developers to faster build business applications for any scenario, from streaming to ETL. Data marts, databases, and Machine Learning are just a few of the services covered among the wide span of analytical workloads.
-
CDP Data Warehouse is a service that enables IT to provide a cloud-native self-service analytics experience for BI analysts. Streaming, data engineering, and analytics are fully integrated into CDP Data Warehouse. In addition, it has a unified framework to secure and govern all your data and metadata across private, multiple public, or hybrid clouds. The Cloudera Data Warehouse service makes it easy to deploy self-service data warehouses for data analysts. It's based on robust, enterprise-tested SQL engines. Hundreds of users will be able to access data with a single click, both on-premises and in the cloud. Resources can be scaled on-demand as needed, and workload management is also self-service with intuitive tools.
-
CDP Machine Learning makes it easy to deploy collaborative Machine Learning workspaces to enable data scientists to leverage enterprise data. It optimizes ML workflows using native and comprehensive tools to deploy, distribute, and monitor models. With this tool, organizations can quickly deploy new Machine Learning workspaces with a few clicks to enable self-service access to the tools and data needed for machine learning workflows. Additionally, data replication on-premises or in the cloud can be done quickly without compromising security and governance. Data scientists can also choose their tools while taking advantage of elastic resources that can be tailored to their needs. Model training, data engineering, deployment, and model management are quickly done through an all-in-one interface, eliminating the need to switch between platforms.
-
Cloudera Data Visualization enables its users to model data in the virtual data warehouse without removing or updating underlying data structures or tables, and to query large amounts of data without constantly loading data, therefore saving time and money.
-
Cloudera Operational Database is a managed solution synthesizing the underlying cluster instance into a database. It will automatically scale based on cluster workload utilization, improve performance within the same infrastructure footprint, and automatically resolve operational issues.
CDP Private Cloud
CDP Private Cloud is better suited for hybrid cloud deployments, allowing on-premises to connect to public clouds while maintaining consistent, integrated security and governance. Processing and storage are decoupled in CDP Private Cloud, allowing both clusters to scale independently. Available on a CDP Private Cloud Base cluster, Cloudera Shared Data Experience (SDX) provides unified security, governance, and metadata management. In addition, CDP Private Cloud users can rapidly provision and deploy Cloudera Data Warehousing and Cloudera Machine Learning services and scale them as needed, using Management Console.
CDP Private Cloud Services
Some CDP Public Cloud components, such as Machine Learning and Data Warehouse, are available on CDP Private Cloud. It uses a collection of analytical engines covering streaming, data engineering, data marts, operational databases, and data science to support traditional workloads.
Essentials of HDFS and MapReduce
HDFS is Hadoop's Distributed File System and the central element of Hadoop, allowing storing and replicating data on several servers. In combination with YARN, it increases the data management capabilities of the HDFS Hadoop cluster and thus enables efficient Big Data processing.
You can run HDFS on commodity hardware, which makes it very error-tolerant. Each piece of data is stored in several places and can be recovered under any circumstances. Also, this replication allows fighting against potential data corruption.
HDFS uses a NameNode and a DataNode. The DataNode is a standard server on which data is stored. The NameNode contains metadata (data stored in the different nodes). The application interacts only with the NameNode, and the NameNode communicates with the data nodes as needed.
HDFS also avoids network congestion by focusing on moving operations rather than moving data. This means that applications can access the data where it is stored. The final strength is its portability. It can run on different types of hardware without any compatibility problem.
What is Mapreduce, and how does it work?
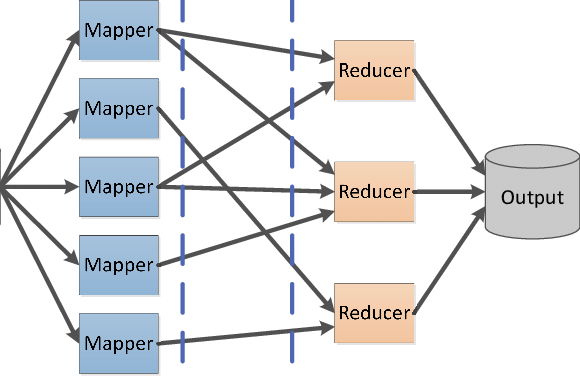
MapReduce is the processing engine of Apache Hadoop, directly derived from Google's MapReduce. The MapReduce application is essentially written in Java. It allows one to easily compute huge amounts of data by applying mapping and reduction steps to find a solution to the problem at hand. The mapping step takes a dataset to convert it into another dataset by decomposing the individual elements into key/value pairs called tuples. The second reduction step takes the output derived from the mapping process and combines the data tuples into a smaller set of tuples.
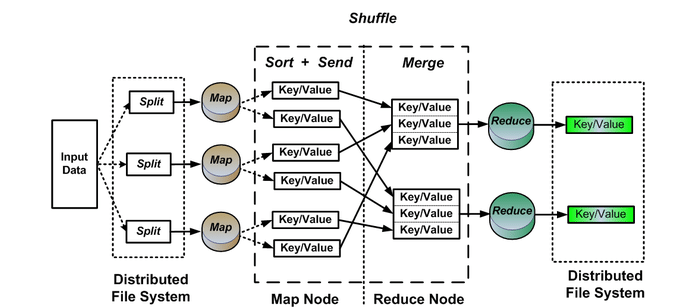
MapReduce is a highly parallel processing framework that can easily be scaled on massive amounts of commodity hardware to meet the growing need for processing large amounts of data. Once the mapping and reduction tasks are running smoothly, all that is required is a configuration change to run on a larger data set. This type of extreme scalability, from a single node to hundreds or even thousands of nodes, is what makes MapReduce a favorite of Big Data professionals around the world.
MapReduce allows a wide range of features, including:
- It enables the parallel processing required to perform Big Data tasks.
- It is applicable to a wide variety of commercial data processing applications
- It is a cost-effective solution for centralized processing frameworks
- It can be integrated with SQL to facilitate parallel processing capabilities.
Cloudera's Distribution Including Apache Hadoop
Cloudera is one of the historical pure-players of Hadoop, alongside Hortonworks and MapR. The Intel-backed group develops CDH, a distribution of Hadoop that includes several other open-source projects, such as Impala and Search. It also offers security and integration features.
The Impala framework is an interactive SQL query engine that allows direct queries of data stored in HDFS, Apache HBase, or AWS S3. This engine relies on other technologies and components from Hive, such as its SQL syntax (HiveSQL), the Open DataBase Connectivity driver, and Query UI.
The Search component is based on the Apache Solr project, a data indexing and search engine built on Lucene. The integration of this technology in CDH gives access, for example, to indexing capabilities in (almost) real-time and access to data stored in a Hadoop or HBase cluster. Solr technology allows complex full-text searches without extensive SQL skills. Solr enables you to query Hadoop data, but without having to move it first.
Cloudera offers several editions of CDH, each with different service and cluster management features, with varying levels of support:
- Cloudera Express is the free version of CDH, which includes the elements of CDH and the core functions of Cloudera Manager. In addition, it provides access to a 30-day evaluation version of the Enterprise version.
- Cloudera Manager is the control tower of CDH. The tool provides a web-based administration console to deploy, manage, monitor, and control the health of CDH deployments. It also includes an API to configure the system and retrieve metrics and information about the operation of a CDH cluster.
- Cloudera Enterprise is a paid license version, and therefore with extended features. It includes, for example, advanced tools extracted from Cloudera Manager and Navigator.
- Cloudera Manager Advanced Features adds key features to Cloudera Express: operational reporting, quota management, configuration logs, continuous updates, service restarts, Kerberos integration, LDAP integration, SNMP support, and automatic disaster recovery.
- Cloudera Navigator, which comes only with the Flex and Data Hub editions, enables data security and governance management within a CDH platform. The tool supports the compliance constraints of companies. With it, data managers, analysts, and administrators can explore large volumes of data stored in Hadoop and more easily manage the encryption keys used to secure the data in a CDH cluster.
To set up a proof-of-concept environment, you must first download and run the Cloudera Manager Server installer.
- First, you need to open Cloudera Manager Downloads in your browser. In the Cloudera Manager box, click Download Now. You can also download the installer for your Cloudera Manager version. For example, for Cloudera Manager 6.3.3:
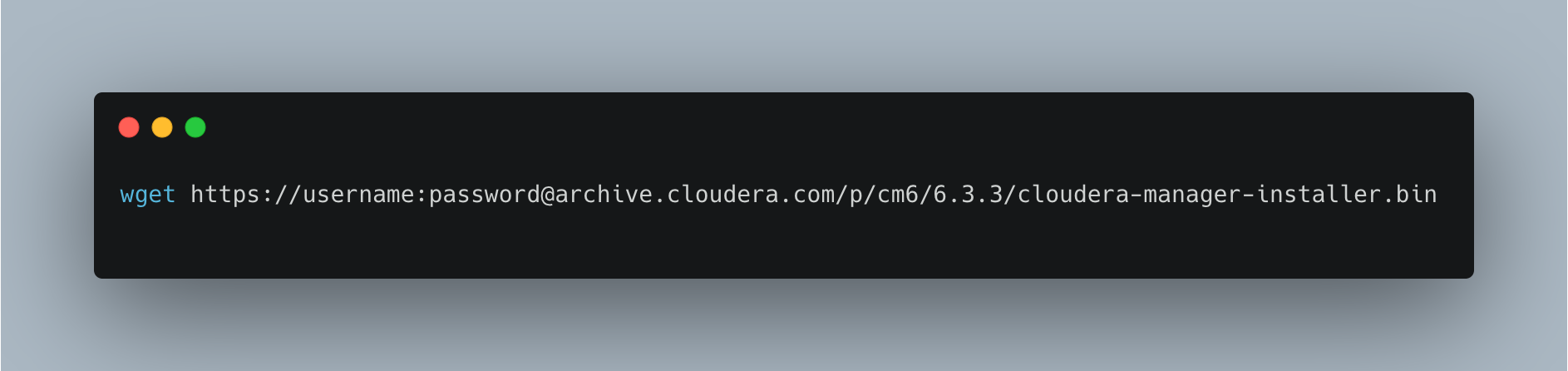
- Next, you need to run the Cloudera Manager Installer.
First, Change Cloudera-manager-installer.bin to be able to execute permissions: chmod u+x Cloudera-manager-installer.bin
To run the installer, use the following command: sudo ./cloudera-manager-installer.bin --username=username --password=password
- Read and Accept the Associated License Agreements
The installer then:
- Installs the Cloudera Manager repository files.
- Installs the Oracle JDK.
- Installs the Cloudera Manager Server and embedded PostgreSQL packages.
The complete URL for the Cloudera Manager Admin Console displays when the installation completes, including the port number (7180 by default). First, make a note of this URL. Then, press Enter to choose OK to exit the installer and acknowledge the successful installation.
The next step is to install CDH using the Wizard.
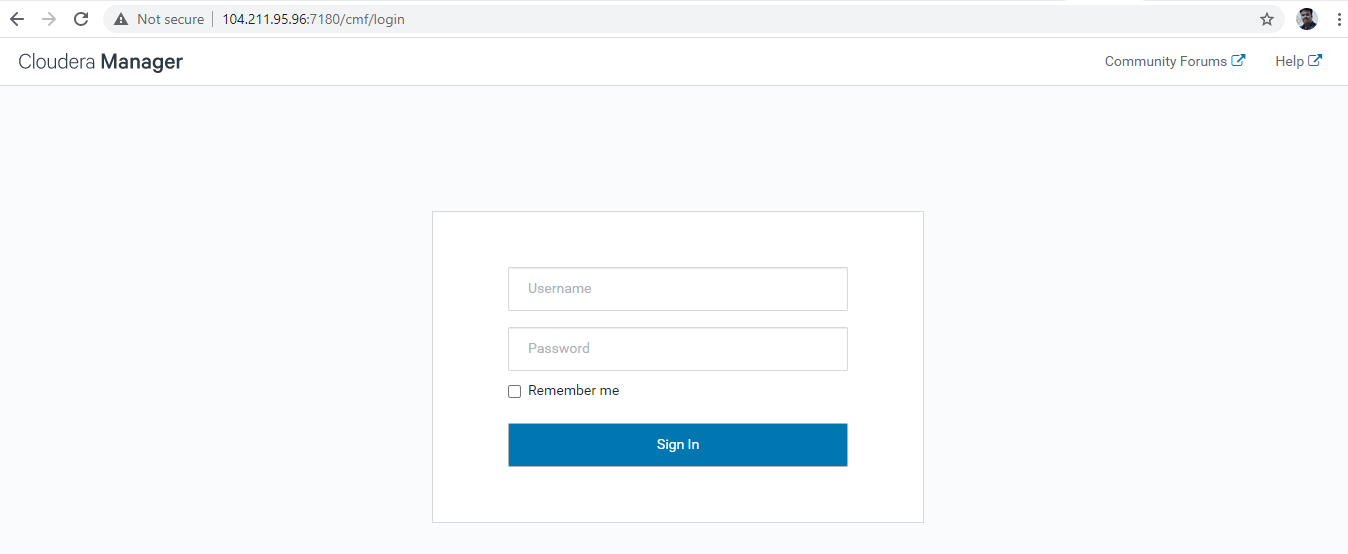
- Go to your Cloudera Manager Admin Console by logging in to: HTTP://:7180, where is the FQDN or IP address of the host Cloudera Manager Server is running.
- Log into Cloudera Manager Admin Console. The default credentials are:
**Username**: admin **Password**: admin
Read the terms and conditions and accept them: Click Continue, and the installation wizard will start.
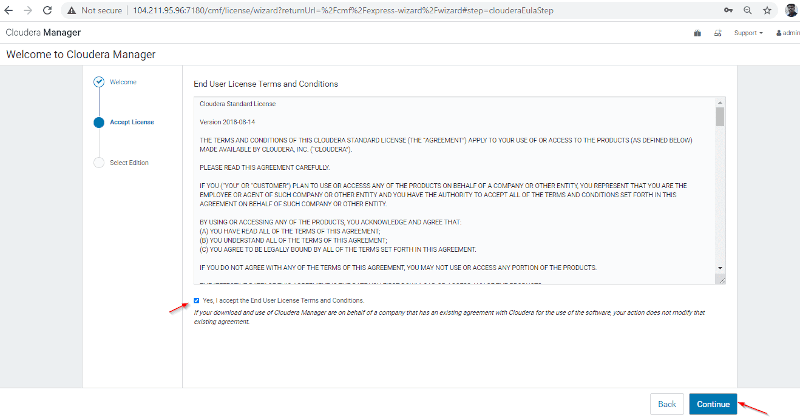
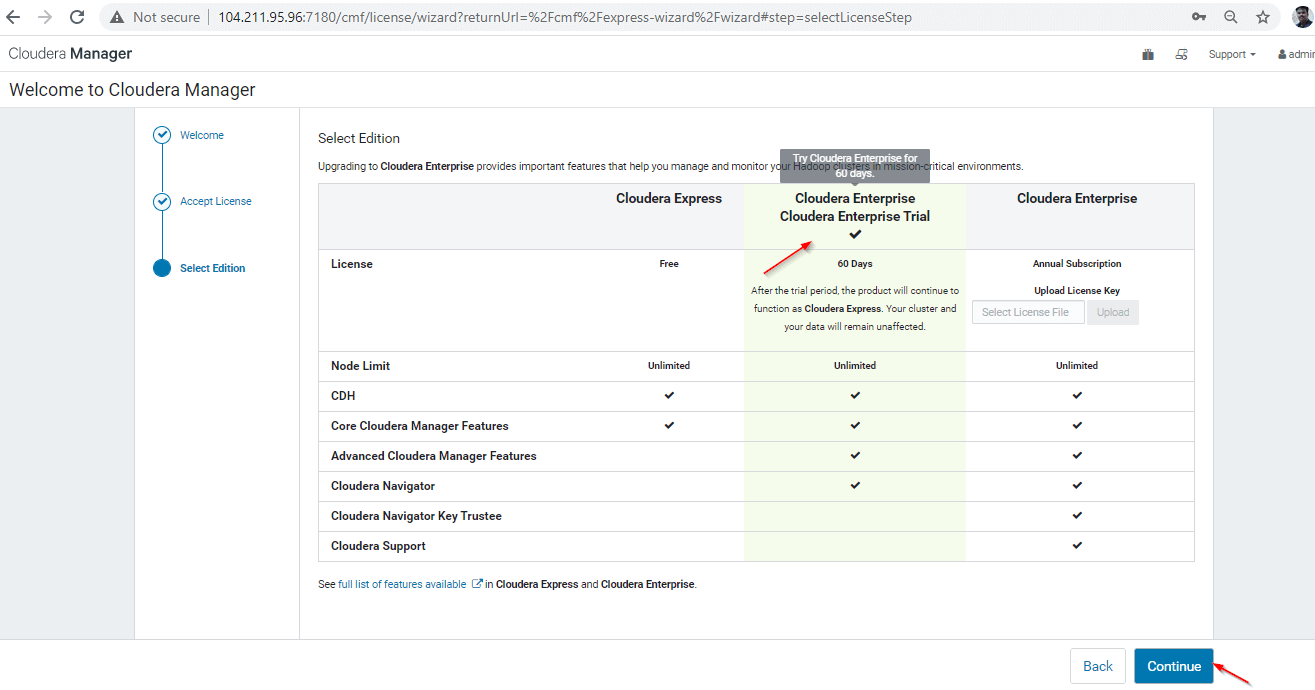
The installation wizard for Cloudera Manager will walk you through a set of steps as follows: Select Edition You can select the edition to install, and optionally you can also install a license.
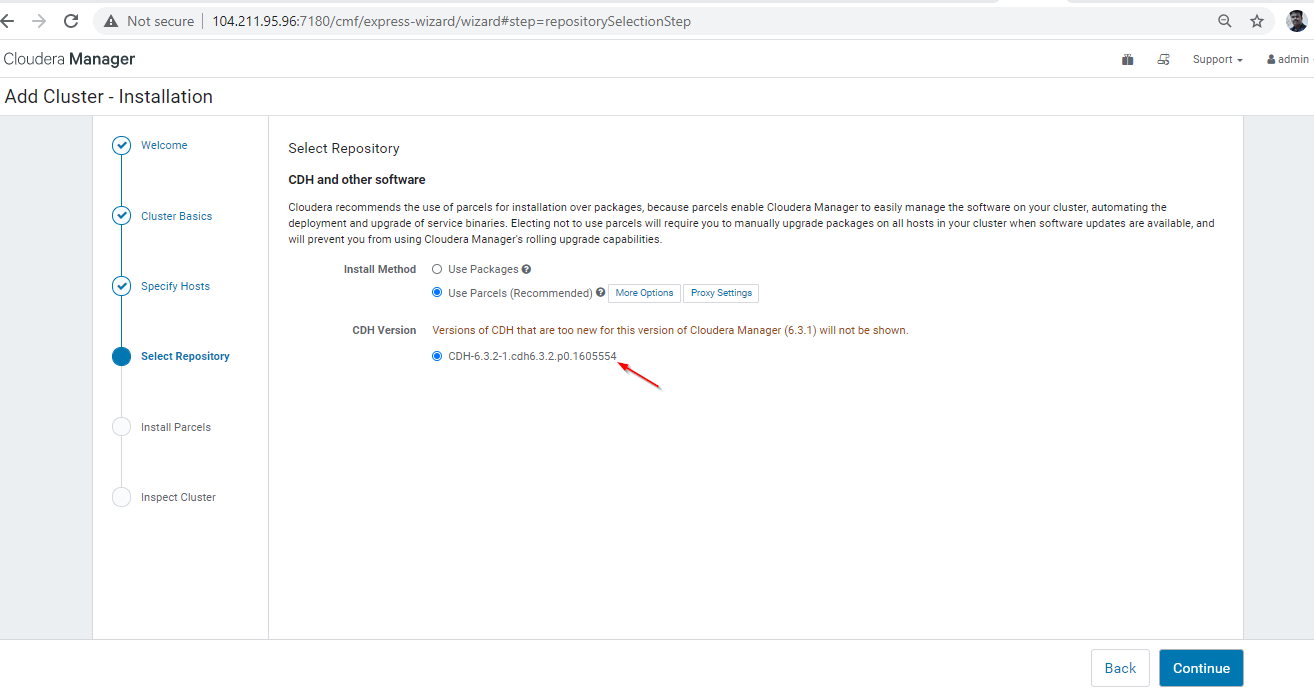
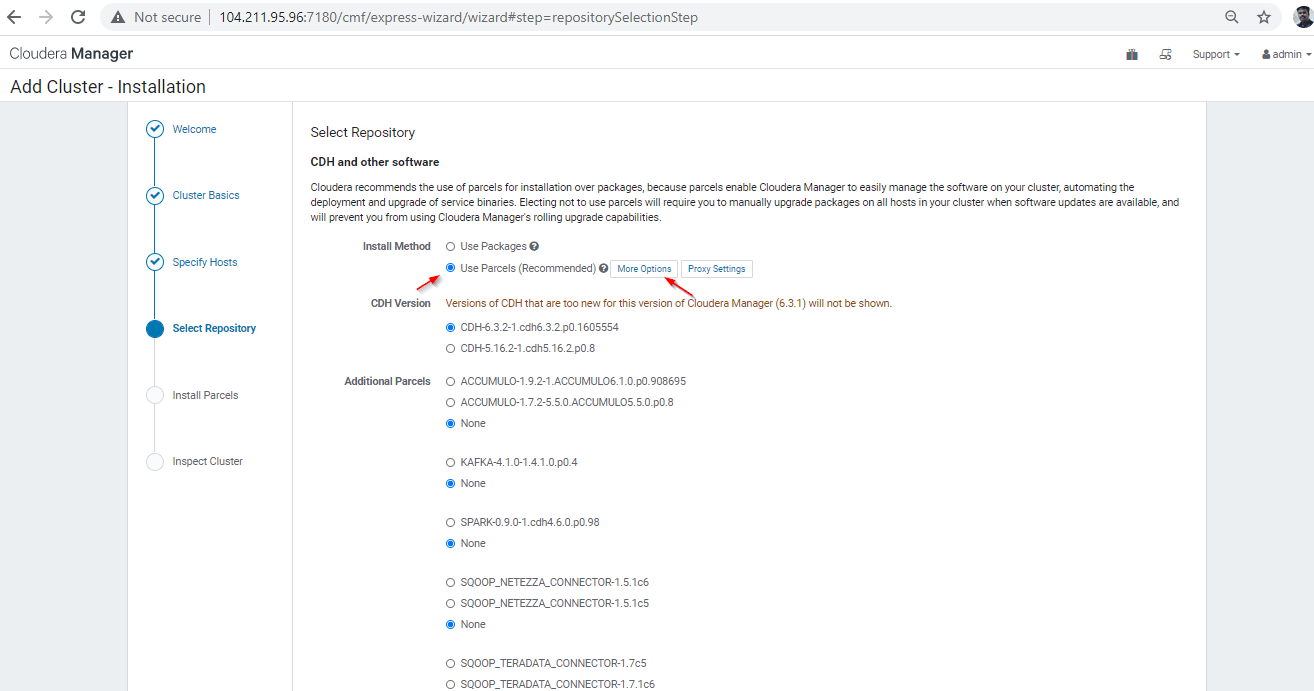
Specify Hosts Choose which hosts will be used to run CDH and other managed services. Select Repository Here you need to:
- First, select the repository type to use for the installation. It is recommended to choose Use Parcels for this proof-of-concept cluster.
- Then, you need to select the version of CDH to install and any additional Parcels you want to install.
- You will be able to select the release of the Cloudera Manager Agent you want to install.
- Click Continue.
Accept JDK License By installing the JDK software, you agree to be bound by the Oracle Binary Code License Agreement. After reading the license terms and checking the applicable boxes, click Continue.
Enter Login Credentials By defining a root account, username, authentication method, ssh port, and the number of hosts.
Install Agents The Install Agents page shows the progress of the installation. You can expand the details for any host to view the installation log.
Install Parcels The Install Parcels page displays the installation progress of the parcels you selected earlier. You can click on any specific progress bar for details about that host.
Inspect Hosts The Inspect Hosts page runs the Host Inspector to search for common configuration problems. View the results and address any issues identified. Then, click the Run Again button to update the results after making any changes.
After completing all of the steps above, the Cluster Setup wizard will automatically start.
Summary
The benefits brought to businesses by Hadoop are considerable. Thanks to this framework, it is feasible to store and process large amounts of data quickly thanks to its distributed computing. The data and applications being processed are protected from hardware failure. If a node fails, jobs are redirected directly to other nodes to ensure that the distributed computing does not fail. Several copies of all data are stored automatically. You can read more about the success stories here, and follow our blog for more data science-related updates.
Get certified in your dream Data Engineer role
Our certification programs help you stand out and prove your skills are job-ready to potential employers.


