I often get asked “what are you most excited about in the future of data science?”
When experts talk about the most exciting advancements, they often talk about work at the frontier of the field. They may discuss deep learning and how it lets computers beat humans at Go, how advancements in AI have enabled self-driving cars, or how technologies like Spark and Hadoop allow computation on enormous data sets.
I have a different answer to the question. I discuss this in detail in our recent DataCamp webinar, Democratizing Data Science within your Company, and I’ll share some of my thoughts here as well.
Making the impossible possible; making the possible easy
Suppose you lived in 1903, and someone asked you what was the most exciting advancement happening in transportation. There’s an easy answer: December 3rd 1903 marked the first heavier-than-air flight, performed by the Wright brothers in Kitty Hawk. If you were asked the same question in 1969, you might have replied “Apollo 11 landing on the moon.” Both of these are entirely fair responses, focusing on firsts in transportation history: making the impossible possible.
But let me offer another perspective. 1903 wasn’t just the year of the first heavier-than-air flight, it was also the year the Ford Motor Company was incorporated. Within a few years Ford would introduce the Model T, widely credited with turning cars from a luxury item into an affordable mode of transportation. And while 1969 saw the first time a human walked on the moon, it also marked the original flight of the Boeing 747, the first “jumbo jet.” The increase in passenger capacity made air travel more possible for everyone. I’d describe these as making the possible easy.
I think the question “what’s exciting in data science” has a similar answer. Hyped advancements like deep learning, self-driving cars, or big data are making the impossible possible: just like the Wright brothers’ first flight or the moon landing, they get a reaction of “I can’t believe we can do that!”
But there’s a second revolution : the spread of data science skills, both in programming and in statistical analysis, to a larger community.
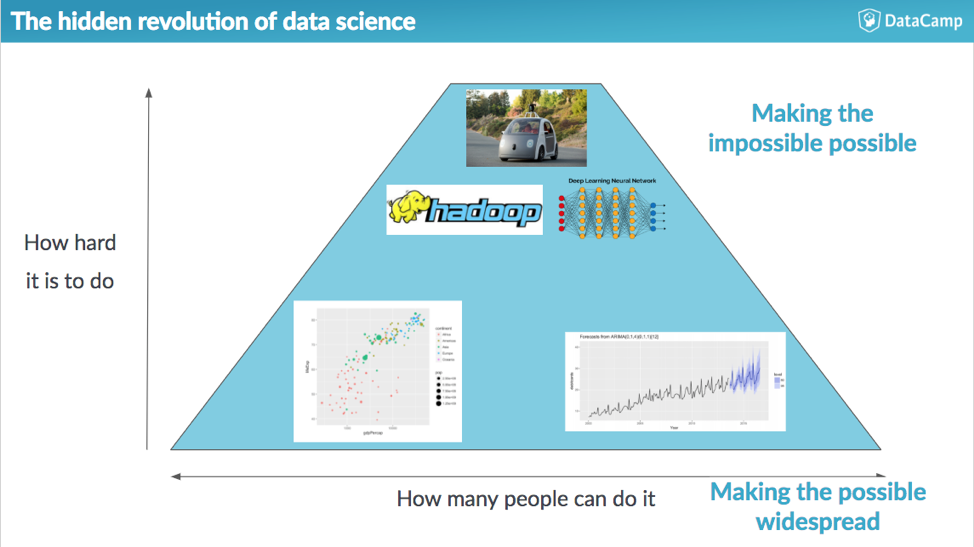
More and more people, from different backgrounds and across different departments and industries, are taking advantage of data science tools and skills to get their jobs done. Some of these changes include
- Growth of the number of people using Python and R to analyze data
- Interfaces to statistical tools becoming increasingly intuitive
- Advances in statistics and programming education
Most of these don’t involve novel statistical methods or AI approaches, just like the Model T wasn’t the first automobile and the Boeing 747 wasn’t the first plane. What makes them exciting is the breadth of the people that are able to take advantage of them.
What’s changed in data science?
Growth of data science programming languages. The last few years have seen an explosion in the use of programming languages for data science. As seen in analyses from the Stack Overflow blog, Python has a solid claim to being the fastest-growing programming language in the world, and it’s mostly thanks to its tools for data science. The R language shows similarly impressive growth, especially within industries like academia, healthcare, government, and consulting.
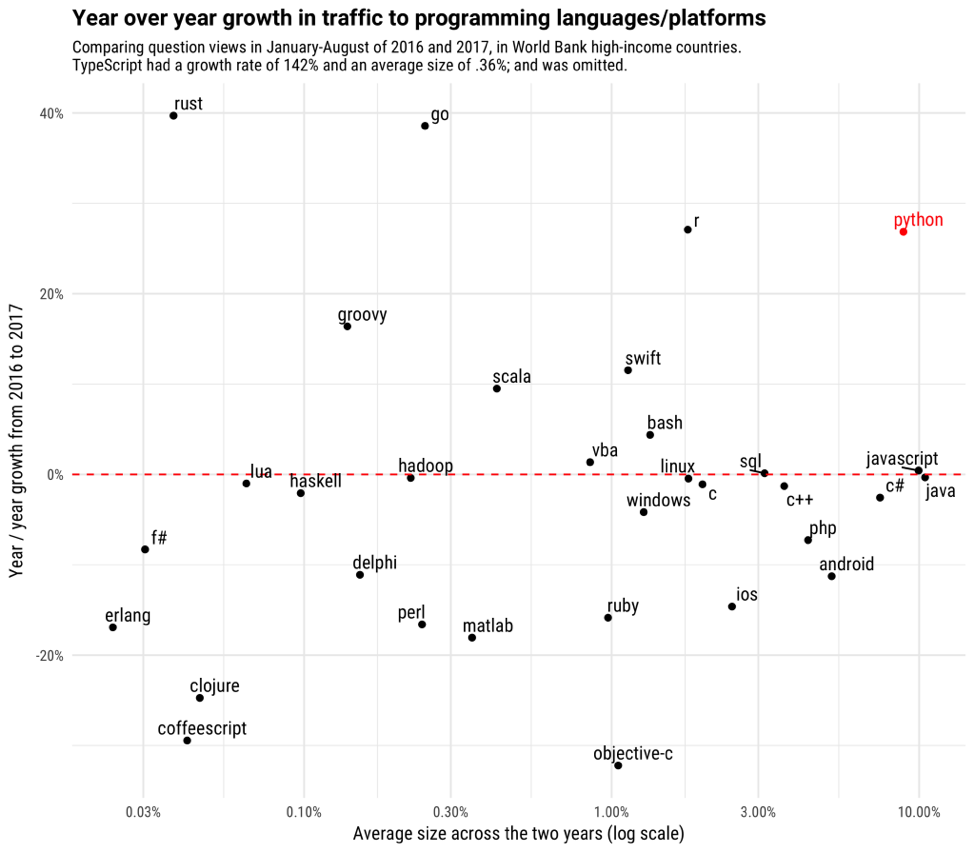 Source: Stack Overflow
Source: Stack OverflowImproved usability in programming languages and tools. A lot of this growth comes not from novel methods in statistics, machine learning, or AI, but rather from improvements in making existing methods more usable. One notable example is the pandas package in Python, which structures data into an object called a DataFrame that allows for powerful and intuitive analyses.
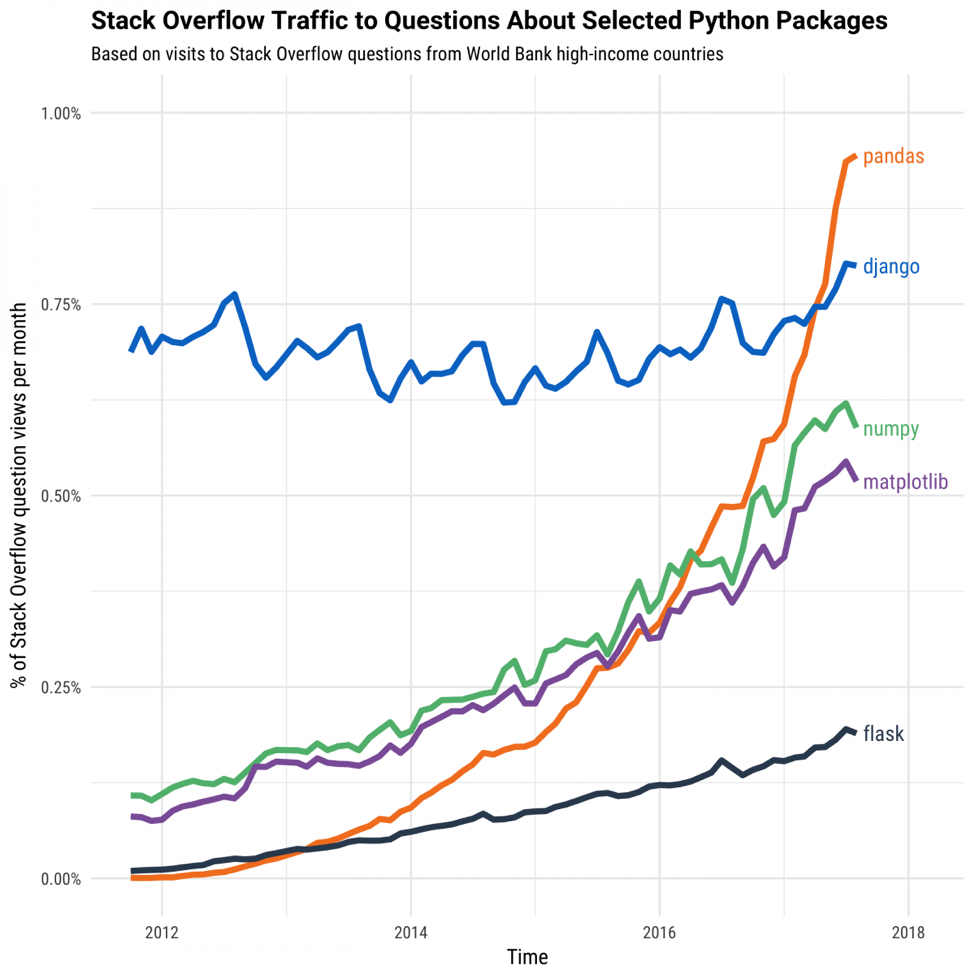 Source: Stack Overflow
Source: Stack OverflowPandas is focused on making existing methods of data transformation more intuitive. As pandas creator Wes McKinney shared in an interview in Quartz, “it enables people to analyze and work with data who are not expert computer scientists. You still have to write code, but it’s making the code intuitive and accessible. It helps people move beyond just using Excel for data analysis.” Pandas forms the backbone of DataCamp’s Data Scientist with Python track.
Within the R language, the tidyverse offers an similarly exciting revolution in usability. It’s a collection of packages that are designed to make data transformation, visualization, and modeling easier. As I’ve , I’ve found the tidyverse remarkably intuitive for introducing methods of data visualization to beginners, and analyses confirm it’s among the fastest growing parts of the R ecosystem.
Better education. The expansion of activity in data science programming languages comes from new people joining the community, either from other areas of software engineering or from entirely different careers. That means that part of the data science revolution is not just in how those tools are built, but how they’re taught.
Our interactive data science courses at DataCamp have taught hundreds of thousands of people how to analyze and visualize data, including many who have never programmed before. Making the learning curve easier is a critical part of making data science more democratic.
What does this mean for your company?
When someone asks you if you’re taking full advantage of data science, you shouldn’t assume that you need to add chatbots to your product, or to throw money at a consultant who says they’re using deep learning. Rather, you should look at how people within your company are taking advantage of data analysis and visualization.
It’s great that a lab at Google can use AI to build a self-driving car. But it’s also exciting when a marketing manager can use R to visualize how effective their ads are, or when a finance team can use Python to predict future revenue.
If you’d like to understand more about how this revolution in data science could affect your company, take our webinar on Democratizing Data Science Within Your Company.
