
Kurs
Einführung in LLMs mit Python
3 Std.
33.6K
Viele Entwickler machen Chatbots und KI-Assistenten, die Fragen super beantworten können, wenn man sie einzeln betrachtet, aber Probleme haben, zusammenhängende Gespräche zu führen. Die eigentliche Ursache? Gedächtnisverlust. Wenn jemand eine Folgefrage stellt, die sich auf vorheriges Geschehen bezieht, sehen stateless Sprachmodelle das als komplett neues Thema an, was zu nervigen, sich wiederholenden Unterhaltungen führt.
Das Verständnis und die Implementierung von Speicher in großen Sprachmodellen sind super wichtig, um KI-Anwendungen zu entwickeln, die sich natürlich und intelligent anfühlen. Dank Speicher können LLMs den Kontext über mehrere Unterhaltungen hinweg behalten, aus früheren Interaktionen lernen und personalisierte Antworten geben. In diesem Tutorial zeige ich dir die Grundlagen des LLM-Speichers, von einfachen Kontextfenstern bis hin zu fortgeschrittenen Architekturen.
Wenn du dich noch nicht mit LLMs auskennst, empfehle ich dir, einen unserer Kurse zu besuchen, zum Beispiel Entwicklung von LLM-Anwendungen mit LangChainoder Entwicklung großer Sprachmodelleoder LLMOps-Konzepte.
Große Sprachmodelle verarbeiten Infos anders als normale Software. Während Datenbanken Daten explizit speichern und abrufen, müssen LLMs den Speicher innerhalb architektonischer Einschränkungen wie Kontextfenstern und Token-Limits verwalten. Die Herausforderung besteht darin, Modelle dazu zu bringen, sich relevante Infos zu merken und unnötige Details zu vergessen, und dabei die Kohärenz zu wahren, ohne die Rechenressourcen zu überlasten.
Bevor wir uns mit den Details der Umsetzung beschäftigen, lass uns mal klären, was Speicher im Zusammenhang mit großen Sprachmodellen bedeutet und warum er für die Entwicklung effektiver KI-Anwendungen wichtig ist.
Speicher in LLMs ist die Fähigkeit des Systems, Infos aus früheren Interaktionen oder Trainingsdaten zu behalten und zu nutzen. Das ist kein Speicher im herkömmlichen Sinne der Informatik. Das Modell kann den Kontext behalten, auf frühere Gespräche zurückgreifen und gelernte Muster auf neue Situationen anwenden.
Das Gedächtnis ist wichtig, weil es einzelne Frage-Antwort-Paare in zusammenhängende Gespräche verwandelt. Ohne Speicher kann ein LLM nicht kapieren, wenn du sagst: „Erzähl mir mehr darüber.“ Das Modell braucht einen Kontext, um Referenzen zu verstehen und auf früheren Gesprächen aufzubauen.
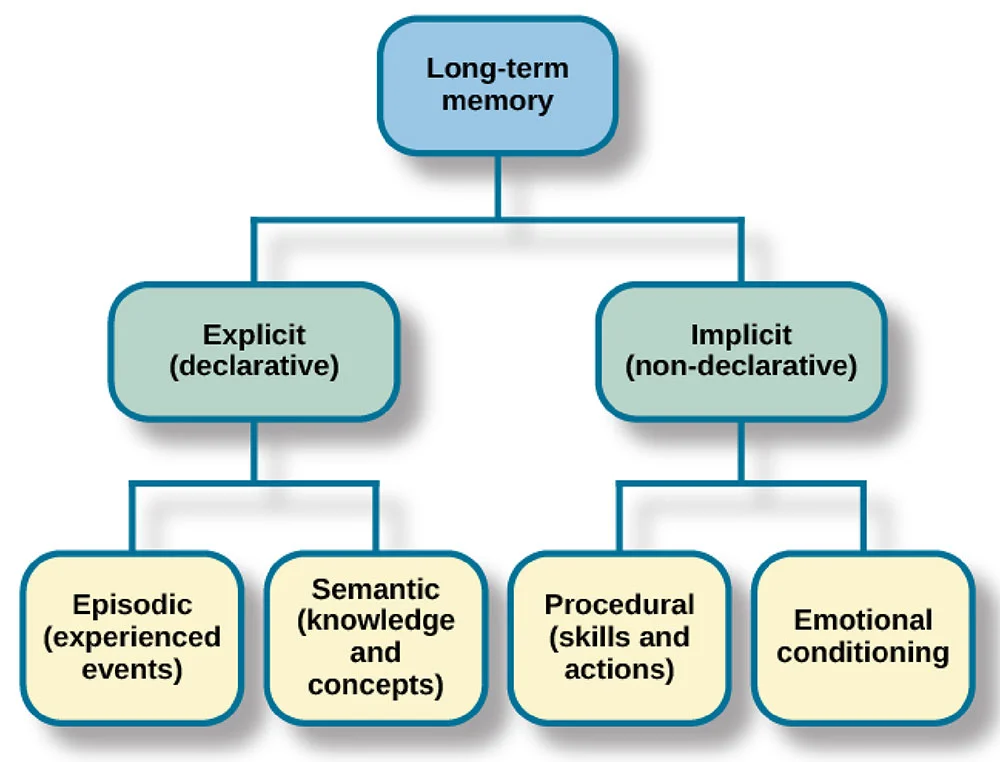
Ich vergleiche LLM-Speicher oft mit menschlichem Gedächtnis. Menschen haben ein sensorisches Gedächtnis (sofortige Wahrnehmung), ein Kurzzeitgedächtnis (aktive Infos) und ein Langzeitgedächtnis (gespeichertes Wissen). LLMs haben ähnliche Systeme: Kontextfenster sind wie ein Kurzzeitgedächtnis, abgerufene Infos sind wie Langzeitgedächtnis und trainierte Parameter sind wie dauerhaftes Wissen.
Nachdem ich jetzt das grundlegende Konzept des Speichers in LLMs erklärt habe, schauen wir uns an, wie Speichersysteme klassifiziert werden, damit du den richtigen Ansatz für deine spezielle Anwendung auswählen kannst.
Wenn du weißt, wie Speicher klassifiziert wird, kannst du den richtigen Ansatz für deine Anwendung auswählen. Das LLM-Gedächtnis kann in drei Hauptbereiche eingeteilt werden: Objekt, Form und Zeit.
Die Objektdimension „ “ unterscheidet zwischen persönlichem Speicher und Systemspeicher. Der persönliche Speicher speichert benutzerspezifische Infos wie Einstellungen und den Verlauf von Unterhaltungen.
Der Systemspeicher hat allgemeines Wissen und Funktionen, die jeder Nutzer nutzen kann. Ein Kundenservice-Bot kann den Systemspeicher für Produktinfos nutzen und gleichzeitig die Bestellhistorie jedes Kunden im Speicher behalten.
In der zweiten Dimension trennt die Formdimension zwischen parametrischem und nicht-parametrischem Speicher. Der parametrische Speicher ist im Gewichtungen des Modells während des Trainings. Nichtparametrischer Speicher ist außerhalb des Modells und wird in Datenbanken oder Vektorspeicherngespeichert. Der parametrische Speicher bleibt nach dem Training unverändert, während der nicht-parametrische Speicher dynamisch aktualisiert werden kann.
Schließlich gibt es noch die Zeitdimension , die Erinnerungen nach Dauer sortiert: Kurzzeitgedächtnis versus Langzeitgedächtnis. Das Kurzzeitgedächtnis umfasst das aktuelle Gespräch, das im Kontextfenster gespeichert ist. Das Langzeitgedächtnis bleibt über mehrere Sitzungen hinweg bestehen, wird extern gespeichert und bei Bedarf abgerufen.
Nachdem wir diesen Klassifizierungsrahmen festgelegt haben, schauen wir uns mal die spezifischen Arten von Speicher an, die LLMs in der Praxis nutzen.
Verschiedene Speichertypen haben in LLM-Anwendungen unterschiedliche Aufgaben. Wenn du diese Typen verstehst, kannst du effektive Speicherarchitekturen für deinen speziellen Anwendungsfall entwerfen.
Das semantische Gedächtnis speichert Fakten und Allgemeinwissen, auf die das System zugreifen und zurückgreifen kann. Während Modelle grundlegendes Wissen aus dem Training haben, geht es beim semantischen Gedächtnis in der Praxis oft um externe Wissensdatenbanken, Datenbanken oder Dokumentenspeicher, die Fakten enthalten.
Ein Kundenservice-Bot könnte zum Beispiel ein semantisches Gedächtnis haben, das Produktspezifikationen, Preisinformationen und Unternehmensrichtlinien in einer Vektordatenbank speichert. Dadurch kann das System genaue und aktuelle Fakten abrufen und referenzieren, ohne sich nur auf möglicherweise veraltete Trainingsdaten zu verlassen. Das semantische Gedächtnis wird normalerweise extern gespeichert und bei Bedarf abgerufen, was die Aktualisierung und Pflege vereinfacht.
Während das semantische Gedächtnis sich mit Fakten und Wissen beschäftigt, dreht sich das episodische Gedächtnis um bestimmte Erlebnisse. Das episodische Speicher m speichert vergangene Interaktionen, welche Fragen gestellt wurden, wie das Modell geantwortet hat und den Kontext dieser Gespräche.
Das episodische Gedächtnis lässt das Modell ganz natürlich auf frühere Teile des Gesprächs eingehen, indem es Sachen sagt wie „wie wir schon besprochen haben“ oder „basierend auf dem, was du mir über dein Projekt erzählt hast“. Diese Art von Speicher ist normalerweise nicht parametrisch und wird in Konversationspuffern oder Datenbanken gespeichert.
Das prozedurale Gedächtnis umfasst Systemanweisungen und gelernte Abläufe. Dazu gehören die Systemaufforderung, die das Verhalten der KI festlegt, Richtlinien für die Reaktion und aufgabenspezifische Anweisungen.
Wenn du ein Modell so einstellst, dass es „immer in Stichpunkten antwortet“ oder „Genauigkeit vor Kreativität priorisiert“, legst du damit das prozedurale Gedächtnis fest. Es bestimmt, wie das Modell Infos verarbeitet und darauf reagiert, und nicht, welche Infos es kennt.
Abgesehen von diesen grundlegenden Speichertypen gibt es praktische Implementierungen, vor allem in Frameworks wie LangChain, gibt's verschiedene Arten von Konversationsspeichern.
ConversationBufferMemory Speichert alle Nachrichten komplett und behält den ganzen Gesprächsverlauf bei. Das ist super für kurze Unterhaltungen, bei denen du den ganzen Kontext brauchst. ConversationSummaryMemory fasst frühere Interaktionen in Zusammenfassungen zusammen, spart so Token und behält trotzdem die wichtigsten Infos für längere Unterhaltungen bei. ConversationBufferWindowMemory behält nur die letzten N Nachrichten und macht so ein gleitendes Kontextfenster, das super funktioniert, wenn nur die letzten Unterhaltungen wichtig sind. ConversationSummaryBufferMemory kombiniert verschiedene Ansätze, indem es die neuesten Nachrichten wortwörtlich beibehält und ältere Unterhaltungen zusammenfasst, und schafft so ein Gleichgewicht zwischen Detailtreue und Effizienz. Jedes Formular ist ein Kompromiss zwischen Vollständigkeit und Effizienz, sodass du je nach den spezifischen Anforderungen deiner Anwendung die passende Lösung auswählen kannst.Es ist wichtig, diese Speichertypen zu verstehen, aber sie alle haben eine grundlegende Einschränkung: das Kontextfenster. Schauen wir mal, wie diese architektonische Einschränkung die Speicherimplementierung beeinflusst.
Ich denke, einer der wichtigsten Aspekte des LLM-Speichers, den man verstehen sollte, ist das Konzept der Kontextfenster. Schauen wir uns kurz an, wie sie funktionieren.
Ein Kontextfenster ist die maximale Textmenge, gemessen in Tokens, die ein LLM in einer einzigen Anfrage verarbeiten kann. Tokens sind Textabschnitte, die ungefähr Wörtern oder Wortteilen entsprechen.
Das Kontextfenster ist quasi das Arbeitsgedächtnis des Modells. Alles, was das Modell berücksichtigt, muss in dieses Fenster passen: Systemaufforderung, Gesprächsverlauf, abgerufene Dokumente und Antwortbereich. Wenn die Unterhaltungen länger werden, müssen alte Nachrichten gelöscht werden, damit Platz für neue ist.
Die Größe des Kontextfensters kann ganz unterschiedlich sein. Zum Beispiel kann GPT-5 400.000 Token verarbeiten, Claude 4.5 Sonnet schafft 200.000 Token und Gemini 3 Pro geht bis zu 1,5 Millionen Token. Größere Fenster bieten mehr Kontext, erhöhen aber die Rechenkosten quadratisch.
Große Kontextfenster klingen zwar super, bringen aber ein paar echte Herausforderungen mit sich, die den Einsatz in der Praxis beeinträchtigen.
Meiner Erfahrung nach ist das größte Problem bei Kontextfenstern, dass man sich in der Mitte verliert. Untersuchungen zeigen, dass LLMs den Infos am Anfang und am Ende des Kontextfensters mehr Aufmerksamkeit schenken, während der mittlere Inhalt weniger beachtet wird. Einfach nur den Kontext mit Infos vollstopfen, garantiert noch keine effektive Nutzung.
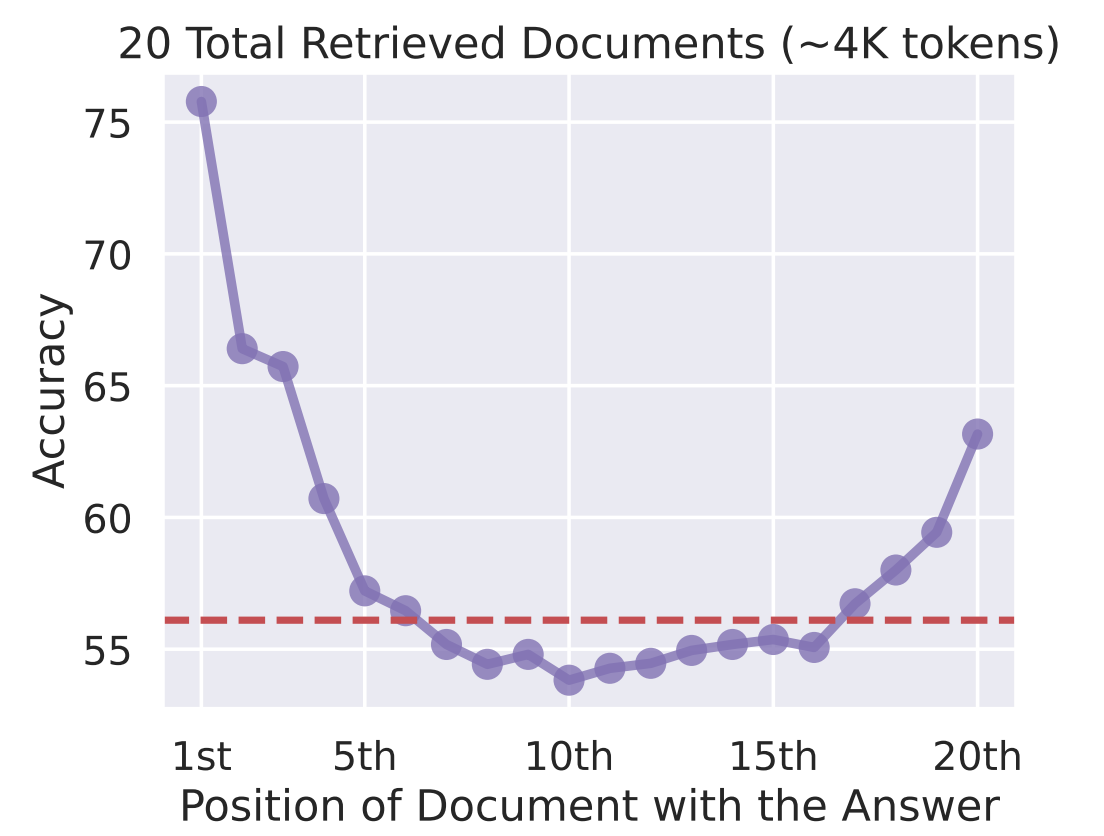
Genauigkeit vs. Wo ist das Dokument mit der Antwort?
Wegen der Rechenbeschränkungen ist es ziemlich aufwendig, die Kontextfenster zu vergrößern. Die Verarbeitung eines Kontexts mit 100.000 Token braucht deutlich mehr GPU-Speicher und Zeit als ein Kontext mit 10.000 Token.
Bei Produktionsanwendungen summieren sich diese Kosten schnell, was den Bedarf an intelligenten Speichersystemen erhöht, die nur die relevanten Infos speichern.
Angesichts dieser Einschränkungen besteht die Lösung nicht einfach darin, Kontextfenster zu vergrößern, sondern intelligentere Systeme zu entwickeln, die diese effizient nutzen.
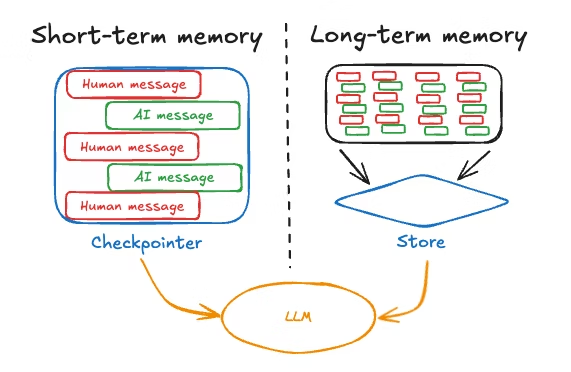
Effektive LLM-Anwendungen verbinden Kontextfenster mit Speichersystemen, die über den unmittelbaren Kontext hinausgehen. Das Muster besteht darin, das Kontextfenster für kurzfristige, wichtige Infos zu nutzen, während man das Langzeitgedächtnis extern speichert und selektiv abruft.
Eine typische Architektur speichert die letzten Gesprächsrunden im Kontextfenster, legt ältere Gespräche in einer Datenbank ab und nutzt Abrufmechanismen, um relevante Informationen aus der Vergangenheit bei Bedarf wieder abzurufen. Das schafft ein Gleichgewicht zwischen Vollständigkeit und Effizienz sowie Leistung.
Nachdem wir uns jetzt mit der Architektur auskennen, schauen wir mal, wie wir gute Kurzzeitspeichersysteme einbauen können, die mit diesen Einschränkungen klarkommen.
Kurzzeitgedächtnissysteme verwalten Infos innerhalb der aktuellen Sitzung und nutzen dabei hauptsächlich das Kontextfenster. Ich sehe das als das Arbeitsgedächtnis des Modells: die Infos, die es aktiv speichert, während es die aktuelle Unterhaltung verarbeitet.
Schauen wir mal, wie wir diesen begrenzten, aber wichtigen Speicherplatz optimal nutzen können.
Kontextbezogenes Lernen ist die Fähigkeit des Modells, sein Verhalten anhand von Beispielen oder Anweisungen in der Eingabe anzupassen. Du bringst dem Modell bei, was es machen soll, indem du es im Kontextfenster zeigst, anstatt es fein abzustimmen.
Der Mechanismus ist ganz einfach:
Die Vorteile dieses Ansatzes sind:
Zu den Einschränkungen gehören eine geringere Effektivität bei vielen Beispielen, weil sie „in der Mitte verloren gehen“, höhere Token-Kosten und eine Leistung, die selten mit fein abgestimmten Modellen mithalten kann.
Kontextbezogenes Lernen zeigt, was mit dem Kurzzeitgedächtnis möglich ist, aber wie werden Infos eigentlich gespeichert, damit das Modell sie nutzen kann? Schauen wir uns mal an, wie Erinnerungen eigentlich entstehen.
Die Gedächtnisbildung in LLM-Systemen kann bewusst (explizit) oder unbewusst (implizit) sein.
Viele Frameworks verwalten automatisch Konversationspuffer und schaffen so impliziten Speicher ohne explizite Operationen. Die Herausforderung besteht darin, diese Ansammlung zu verwalten und sicherzustellen, dass relevante Infos erhalten bleiben, während weniger wichtige Details aussortiert werden.
Das Kurzzeitgedächtnis kümmert sich um die unmittelbaren Bedürfnisse in Gesprächen, aber was passiert, wenn du Infos brauchst, die über die aktuelle Sitzung hinaus bestehen bleiben sollen? Da sind langfristige Speicherlösungen echt wichtig.
Das Langzeitgedächtnis lässt LLMs Infos über mehrere Sitzungen hinweg behalten.
Während das Kurzzeitgedächtnis nur kurz hält und nach dem Gespräch weg ist, bleibt das Langzeitgedächtnis bestehen, sodass deine KI sich an die Vorlieben der Nutzer, frühere Interaktionen und das gesammelte Wissen im Laufe der Zeit erinnern kann.
Ich werde zwei wichtige Ansätze vorstellen: textbasierte Speichersysteme, die Infos extern speichern, und Key-Value-Caching, das den Zugriff des Modells auf zuvor berechnete Infos optimiert.
Textbasierte Speicher speichern den Gesprächsverlauf und die Nutzerinfos in Datenbanken oder Vektorspeichern. Beim Erwerb geht's darum, wichtige Infos, Vorlieben, Entscheidungen, Fakten oder Details zum Kontext zu sammeln.
Speicherverwaltung braucht Komprimierung und Organisation. Zusammenfassungstechniken packen Gespräche in wichtige Punkte rein. Hierarchische Strukturen ordnen Erinnerungen nach Themen, Zeiträumen oder Relevanz.
Die Nutzung dreht sich um das Abrufen. Die Vektorsimilaritätssuche findet relevante Erinnerungen anhand der semantischen Bedeutung. Bei der zeitbasierten Suche werden aktuelle Infos zuerst angezeigt. Die Relevanzbewertung sortiert Erinnerungen nach ihrer Wichtigkeit.
Textbasierte Systeme kümmern sich darum, was gespeichert wird, aber es stellt sich auch die Frage, wie man das Abrufen effizienter gestalten kann. Hier kommt das Key-Value-Caching ins Spiel.
Das Caching von Schlüssel-Wert-Paaren (KV) macht die Token-Erzeugung effizienter. Beim Erstellen von Text berechnet das Modell die Aufmerksamkeit für alle vorherigen Token. KV-Caching speichert diese Zwischenberechnungen, sodass sie bei der Generierung nachfolgender Token wiederverwendet werden können, ohne dass eine Neuberechnung nötig ist.
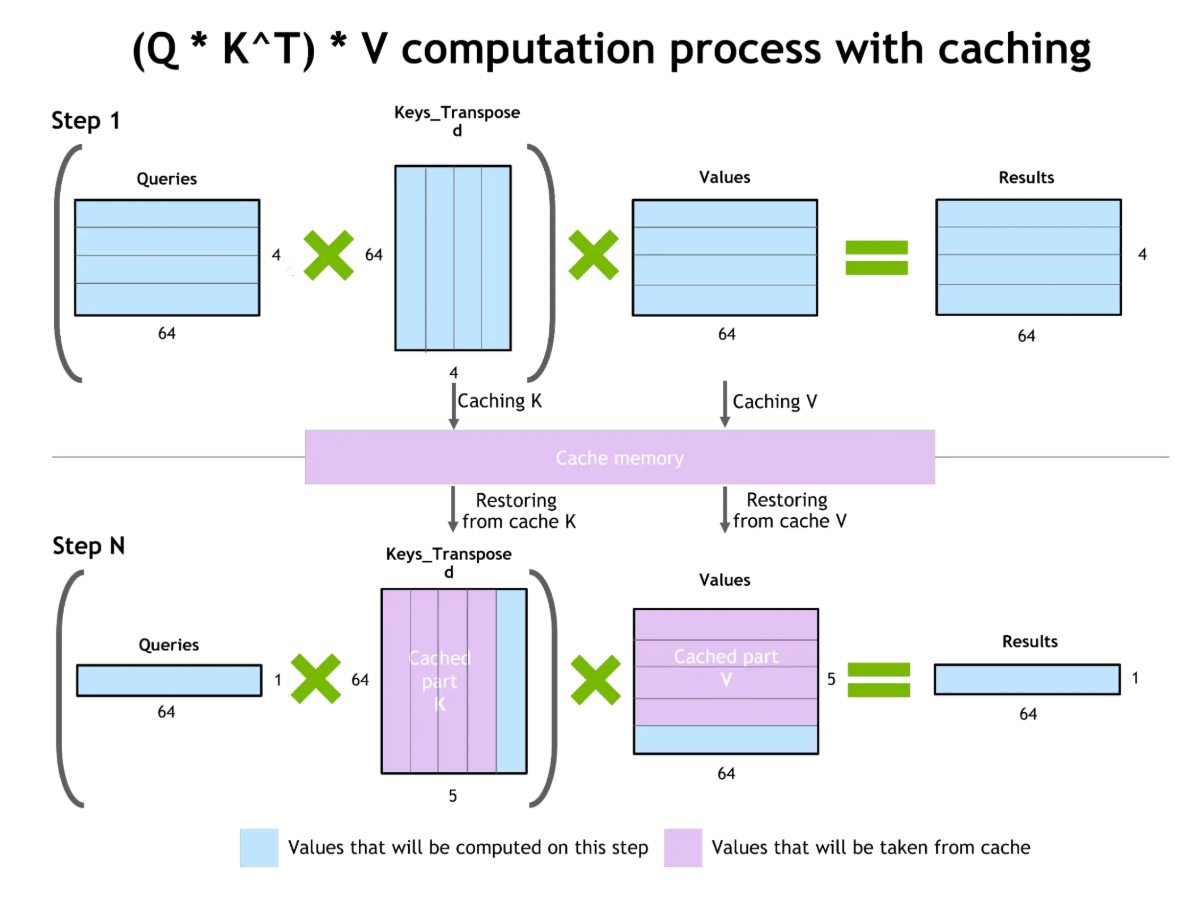
Schlüsselwert-Caching und Aufmerksamkeitsoptimierung
Der Vorteil ist echt groß: weniger Rechenaufwand, was schnellere Antworten und weniger Ressourcenverbrauch bedeutet. Allerdings brauchen zwischengespeicherte Schlüssel-Wert-Paare GPU-VRAM. Bei echt langen Kontexten wird die Größe des KV-Caches zum Problem.
KV-Caching macht zwar die Nutzung der Kontextfenster durch Modelle besser, löst aber nicht das eigentliche Problem der begrenzten Speicherkapazität. Hier kommt die abrufgestützte Generierung ins Spiel, die einen ergänzenden Ansatz bietet.
Eine der neuesten Entwicklungen, die ich am interessantesten finde, ist Retrieval-Augmented Generation oder RAG. RAG verbindet internen und externen Speicher und erweitert so den Speicher eines LLM über die Grenzen des Kontextfensters hinaus.
Anstatt sich nur auf das zu verlassen, was das Modell beim Training gelernt hat oder was gerade passt, holt sich RAG genau dann relevante Infos aus externen Quellen, wenn sie gebraucht werden. Schauen wir uns RAG mal genauer an.
Die RAG-Architektur besteht aus zwei Hauptkomponenten: einem Retriever, der externe Wissensdatenbanken nach relevanten Infos durchsucht, und einem Generator (dem LLM), der Antworten basierend auf der Anfrage und dem abgerufenen Kontext erstellt.
Wenn eine Anfrage reinkommt, sucht der Retriever relevante Dokumente aus Vektordatenbanken oder Wissensdatenbanken raus. Die gefundenen Dokumente werden ins Kontextfenster eingefügt und liefern genaue Infos, um die Antwort zu begründen.
Zu den Vorteilen von RAG gehört die Reduzierung von Halluzinationen durch den Zugriff auf aktuelle Dokumente, eine höhere Genauigkeit durch den Zugriff auf aktuelle Informationen, die über die Trainingsdaten hinausgehen, und die Einbeziehung von firmeneigenem Wissen ohne erneutes Training.
Zu den Herausforderungen gehören aber mögliche Halluzinationen, wenn die gefundenen Dokumente Fehler haben, Relevanzprobleme, wenn die Suche nutzlose Infos liefert, und die Komplexität beim Verwalten von Vektordatenbanken.
Die wahre Stärke von RAG wird deutlich, wenn wir uns anschauen, wie es eine der grundlegendsten Einschränkungen angeht, über die wir vorhin gesprochen haben: die Beschränkungen des Kontextfensters.
RAG erweitert den Kontext über die Fenstergröße hinaus, indem es nur die relevanten Infos herauspickt. Anstatt den kompletten Gesprächsverlauf zu speichern, legst du ihn extern ab und holst dir bei Bedarf die relevanten Teile raus. So kannst du praktisch unbegrenzte Gesprächslängen innerhalb der Einschränkungen des Kontextfensters unterstützen.
Strategien zur Verbesserung von Kontextfenstern mit RAG umfassen die hybride Suche, bei der semantische Suche mit Metadatenfilterung kombiniert wird, die Neuanordnung der Suchergebnisse, um relevante Dokumente zu priorisieren, und die rekursive Suche, bei der die erste Antwort des Modells die weitere Suche steuert.
RAG ist ein praktischer, produktionsreifer Ansatz zur Speichererweiterung, aber die Forschungswelt geht immer weiter und entwickelt neue Architekturen, die die Art und Weise, wie Modelle mit Speicher umgehen, grundlegend verändern.
Neue Architekturen und von der Neurowissenschaft inspirierte Systeme bringen die Speicherfähigkeiten von LLM weiter voran. Diese innovativen Ansätze verändern die Art und Weise, wie Modelle mit Informationen aus einem langen Kontext umgehen, und gehen über die traditionellen Grenzen von Transformatoren hinaus, um effizientere und menschenähnlichere Speichersysteme zu schaffen.
Architekturen wie Mamba und Recurrent Memory Transformers machen den Speicher effizienter. Mamba nutzt Zustandsraummodelle anstelle von Aufmerksamkeitsmechanismen und erreicht so eine lineare statt einer quadratischen Skalierung mit der Sequenzlänge, was die Verarbeitung von viel längeren Sequenzen mit vergleichbaren Ressourcen ermöglicht.
Rekursive Speichertransformatoren machen Standardtransformatoren mit rekursiven Verbindungen, die den langfristigen Zustand beibehalten, und ermöglichen es, dass Infos über das unmittelbare Kontextfenster hinaus durch gelernte Speichermodelle erhalten bleiben.
Diese architektonischen Neuerungen sind aus Forschungssicht echt spannend, aber wie sieht's mit serienreifen Lösungen aus? Hier kommen externe Speicherplattformen ins Spiel.
Plattformen wie Mem0 und Zep bieten einsatzbereite externe Speicherlösungen. Mem0 hat so 'ne verwaltete Speicherschicht, die automatisch wichtige Infos rausholt, speichert und wieder findet. Zep konzentriert sich auf das Gesprächsgedächtnis mit integrierter Zusammenfassung, Faktenextraktion und Vektorsuche.
Obwohl diese Plattformen praktische Lösungen bieten, lassen sich einige Forscher von einer unerwarteten Quelle inspirieren: der Art und Weise, wie das menschliche Gehirn Erinnerungen tatsächlich bildet und verwaltet.
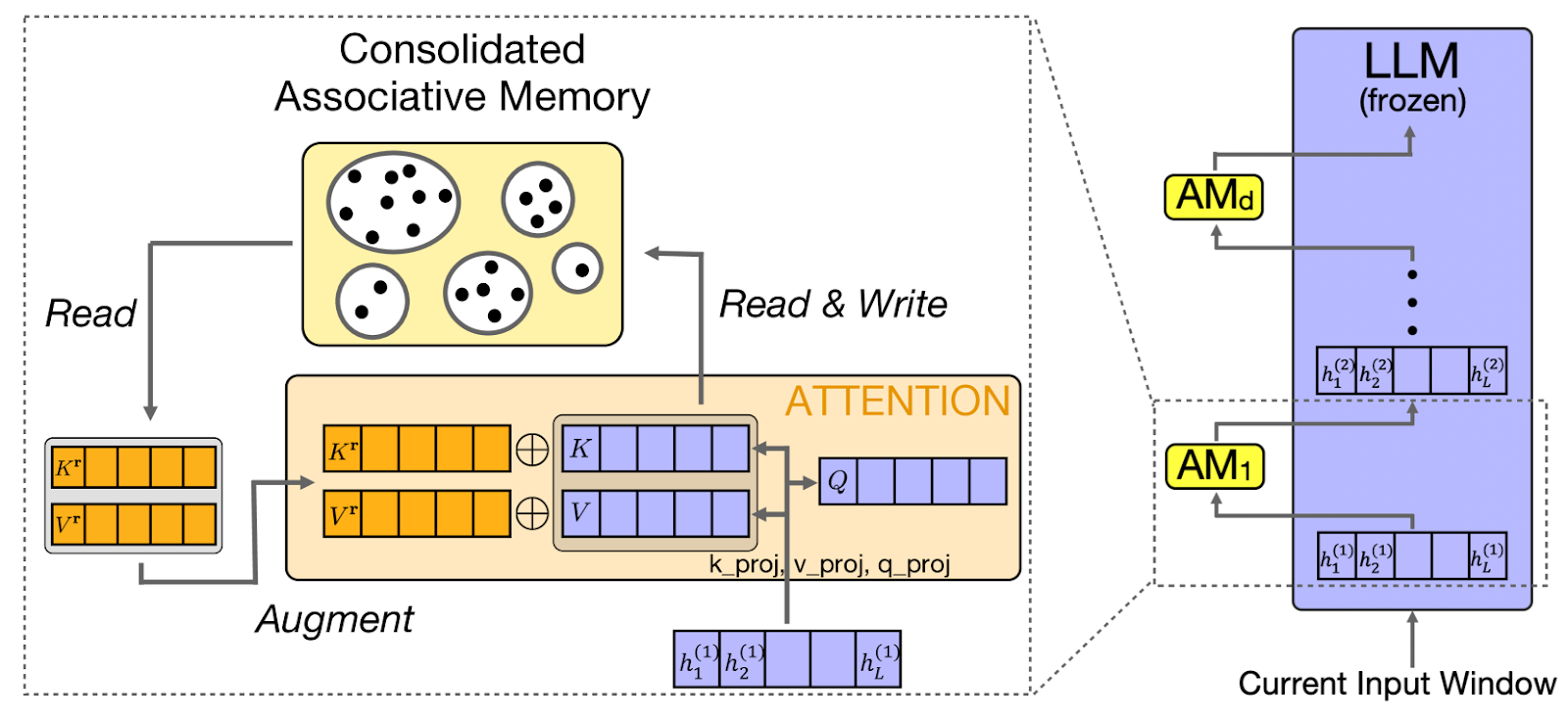
CAMELoT (Consolidated Associative Memory Enhanced Long Transformer) nutzt Prinzipien aus der Neurowissenschaft für das LLM-Gedächtnis und setzt dabei Konsolidierung, Neuheitserkennung und Gewichtung nach Aktualität um. Diese Prinzipien sind wie menschliche Gedächtnissysteme und sorgen für ein natürlicheres Gedächtnisverhalten.
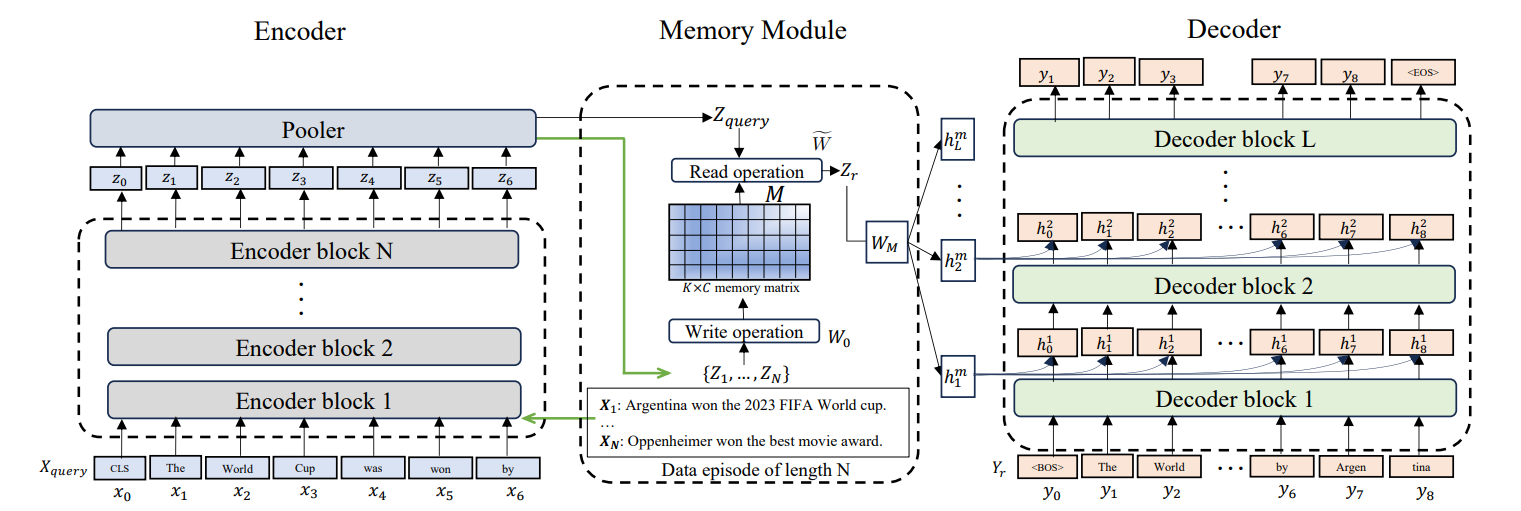
Auf diesen Prinzipien der Neurowissenschaften aufbauend, konzentriert sich ein anderer Ansatz wie Laminar speziell darauf, wie Menschen bestimmte Erfahrungen und Ereignisse erinnern.
Larimar ermöglicht es LLMs, bestimmte Gedächtnisepisoden zu behalten. Anstatt alle vergangenen Infos gleich zu behandeln, ordnet das episodische Gedächtnis die Infos in einzelne Ereignisse. Das macht es möglich, die Kontextlänge zu verallgemeinern. Das Modell bezieht sich auf bestimmte vergangene Ereignisse, ohne die ganze Geschichte zu laden.
Diese fortschrittlichen Architekturen sind echt vielversprechend, bringen aber auch neue Herausforderungen mit sich. Schauen wir uns mal die praktischen Probleme an, die bei der Umsetzung von Speichersystemen auftauchen, und wie man sie lösen kann.
Selbst bei ausgeklügelten Architekturen habe ich festgestellt, dass Speichersysteme mit Herausforderungen konfrontiert sind, die oft sorgfältige Abhilfemaßnahmen erfordern. Diese Hindernisse und ihre Lösungen zu verstehen, ist echt wichtig, um stabile Produktionssysteme zu entwickeln, auf die sich die Nutzer verlassen können.
Katastrophales Vergessen passiert, wenn Modelle schon mal gelernte Infos verlieren. Lösungen umfassen Gedächtniskonsolidierung, Stärkung wichtiger Erinnerungen, Gedächtnishierarchien, Bewahrung wichtiger Infos und regelmäßige Gedächtnisauffrischung.
Neben dem Vergessen ist es auch ein echtes Problem, wenn Gedächtnissysteme das Modell absichtlich in die Irre führen. Halluzinationen (die Erzeugung plausibler, aber falscher Informationen) werden durch ein schlechtes Gedächtnis noch verstärkt. Die Schadensbegrenzung umfasst die Zuordnung der Quelle, die Bewertung der Zuverlässigkeit der abgerufenen Erinnerungen und Überprüfungsschritte.
Schließlich wirft das Speichern von Nutzergesprächen und -einstellungen wichtige Datenschutzfragen auf. Datenschutz und Sicherheit sind super wichtig, wenn man Nutzerdaten speichert. Mach Datenverschlüsselung, Richtlinien zum Löschen alter Daten und Zugriffskontrollen, damit Leute nur auf ihre eigenen Daten zugreifen können.
Die Integration von Speicher braucht ein durchdachtes API-Design. Zu den Kernmustern gehören die zustandsbehaftete Integration, bei der das Speichersystem den Zustand über mehrere Anfragen hinweg beibehält, und die zustandslose Integration, bei der jede Anfrage die erforderlichen Identifikatoren enthält.
Effiziente Speicherverwaltung nutzt Trimming (Entfernen der ältesten oder am wenigsten relevanten Nachrichten), Löschen (Entfernen bestimmter Elemente) und Zusammenfassung (Komprimieren von Nachrichten). Diese Muster halten den Speicherbedarf im Rahmen des Budgets und behalten gleichzeitig den wichtigen Kontext bei.
Es ist echt wichtig, diese theoretischen Muster und Herausforderungen zu verstehen, aber die eigentliche Herausforderung liegt in der Umsetzung. Lass uns diese Ideen in praktische Tipps umsetzen, die du für deine eigenen Projekte nutzen kannst.
Hier sind ein paar Beispiele, wie Entwickler meiner Erfahrung nach das Beste aus LLM-Speichersystemen rausholen.
Effektives Kontextmanagement fängt damit an, dass du dein Token-Budget verstehst. Berechne, wie viele Token dein System für Eingabeaufforderungen, Speicher und Antworten braucht, und pass auf, dass die Summe im Rahmen bleibt. Strukturier die Daten hierarchisch und pack die wichtigen Infos dahin, wo sie am besten rüberkommen – am Anfang oder am Ende.
Genauso wichtig ist, wie du die Daten aufbereitest, bevor sie in dein Speichersystem kommen. Die Datenvorbereitung ist echt wichtig. Teile große Dokumente in sinnvolle Abschnitte auf, statt dich an willkürliche Zeichenbegrenzungen zu halten. Lass die Textabschnitte ein bisschen überlappen, damit der Kontext klar bleibt. Füge Metadaten zu jedem Chunk hinzu, damit man die Daten filtern kann.
Sobald dein System läuft, brauchst du Möglichkeiten, um zu messen, ob es tatsächlich funktioniert. Die Bewertung des Gedächtnisses erfordert die Verfolgung von Kennzahlen wie Erinnerungsgenauigkeit, Halluzinationsrate und Benutzerzufriedenheit. Beobachte die Latenz des Speichersystems, die Token-Nutzung und die Relevanz der Abrufe.
Schlussendlich sollte deine Suchstrategie auf die Komplexität der Nutzeranfragen abgestimmt sein. Flexible Abrufstrategien passen sich der Komplexität der Abfrage an. Einfache Suchanfragen nutzen die Stichwortsuche, während komplexe Fragen von der semantischen Ähnlichkeitssuche profitieren. Speicher-Namespaces einrichten, um Infos nach Benutzer, Thema oder Zeitraum zu sortieren.
Große Sprachmodellspeicher machen aus diesen Modellen statt statischer Textgeneratoren kontextbewusste KI-Assistenten, die kohärente, personalisierte Interaktionen ermöglichen. In diesem Tutorial habe ich die Grundlagen des LLM-Speichers erkundet, von Kontextfenstern bis hin zu fortgeschrittenen Architekturen.
Ich denke, die wichtigsten Punkte sind, mit gut verwalteten Kontextfenstern und Konversationspuffern für den unmittelbaren Bedarf zu starten, RAG für skalierbaren Wissenszugriff über den parametrischen Speicher hinaus zu implementieren, externe Speicherplattformen für Produktionsanwendungen zu nutzen und die Speichereffizienz durch Metriken und Nutzer-Feedback ständig zu checken.
Mit der Weiterentwicklung der LLM-Fähigkeiten werden Speichersysteme immer ausgefeilter werden. Für Praktiker ist es wichtig, sich auf den Aufbau von Speichersystemen zu konzentrieren, die den Bedürfnissen der Nutzer entsprechen: relevante Zusammenhänge beibehalten, angemessen vergessen und natürliche Interaktionen ermöglichen, die KI-Anwendungen wirklich nützlich machen.
Um weiterzulernen, schau dir doch mal die folgenden Ressourcen an:
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Mark Pedigo
Tutorial
Allan Ouko
