
Curso
Introdução a LLMs em Python
3 h
33.6K
Muitos desenvolvedores criam chatbots e assistentes de IA que conseguem responder perguntas de forma brilhante isoladamente, mas têm dificuldade em manter conversas coerentes. A causa principal? Falta de memória. Quando alguém faz uma pergunta de acompanhamento que faz referência a algo que já foi dito, os modelos de linguagem sem estado tratam isso como algo totalmente novo, o que leva a interações repetitivas e frustrantes.
Entender e implementar a memória em grandes modelos de linguagem é essencial pra criar aplicativos de IA que pareçam naturais e inteligentes. A memória permite que os LLMs mantenham o contexto das conversas, aprendam com interações anteriores e deem respostas personalizadas. Neste tutorial, vou te mostrar os fundamentos da memória LLM, desde janelas de contexto básicas até arquiteturas avançadas.
Se você é novo no mundo dos LLMs, recomendo fazer um dos nossos cursos, como Desenvolvendo aplicativos LLM com LangChain, Desenvolvendo grandes modelos de linguagemou Conceitos de LLMOps.
Os grandes modelos de linguagem processam as informações de maneira diferente dos softwares tradicionais. Enquanto os bancos de dados armazenam e recuperam dados explicitamente, os LLMs precisam gerenciar a memória dentro de restrições arquitetônicas, como janelas de contexto e limites de tokens. O desafio é fazer com que os modelos lembrem as informações importantes e esqueçam os detalhes desnecessários, mantendo a coerência sem sobrecarregar os recursos computacionais.
Antes de mergulhar nos detalhes da implementação, vamos entender o que significa memória no contexto de grandes modelos de linguagem e por que ela é importante para criar aplicativos de IA eficazes.
A memória em LLMs é a capacidade do sistema de guardar e usar informações de interações anteriores ou dados de treinamento. Isso não é memória no sentido tradicional da computação. É a capacidade do modelo de manter o contexto, fazer referência a trocas anteriores e aplicar padrões aprendidos a novas situações.
A memória é super importante porque transforma pares isolados de perguntas e respostas em conversas que fazem sentido. Sem memória, um LLM não consegue entender quando você diz “me conte mais sobre isso”. O modelo precisa de contexto para entender as referências e aproveitar as conversas anteriores.
Costumo pensar na memória LLM em paralelo com a memória humana. Os humanos têm memória sensorial (percepção imediata), memória de curto prazo (informação ativa) e memória de longo prazo (conhecimento armazenado). Os LLMs usam sistemas parecidos: as janelas de contexto funcionam como a memória de curto prazo, as informações recuperadas são como a memória de longo prazo e os parâmetros treinados são o conhecimento permanente.
Agora que já falei sobre o conceito básico de memória em LLMs, vamos ver como os sistemas de memória são classificados para te ajudar a escolher a abordagem certa para a sua aplicação específica.
Entender como a memória é classificada ajuda a escolher a abordagem certa para sua aplicação. A memória LLM pode ser categorizada em três dimensões principais: objeto, forma e tempo.
A dimensão do objeto faz a diferença entre memória pessoal e memória do sistema. A memória pessoal guarda informações específicas do usuário, como preferências e histórico de conversas.
A memória do sistema tem conhecimentos e recursos gerais que todos os usuários podem usar. Um bot de atendimento ao cliente pode usar a memória do sistema para informações sobre produtos, enquanto mantém a memória pessoal do histórico de pedidos de cada cliente.
Passando para a segunda dimensão, a dimensão da forma separa a memória paramétrica da não paramétrica. A memória paramétrica é codificada nos pesos do modelo. pesos do modelo durante o treinamento. A memória não paramétrica existe fora do modelo, guardada em bancos de dados ou armazenamentos vetoriais. A memória paramétrica é fixada após o treinamento, enquanto a memória não paramétrica pode ser atualizada dinamicamente.
Por fim, a dimensão temporal classifica a memória por duração: curto prazo versus longo prazo. A memória de curto prazo abrange a conversa atual, guardada na janela de contexto. A memória de longo prazo fica guardada entre as sessões, armazenada fora do aparelho e recuperada quando precisar.
Com essa estrutura de classificação estabelecida, vamos examinar os tipos específicos de memória que os LLMs implementam na prática.
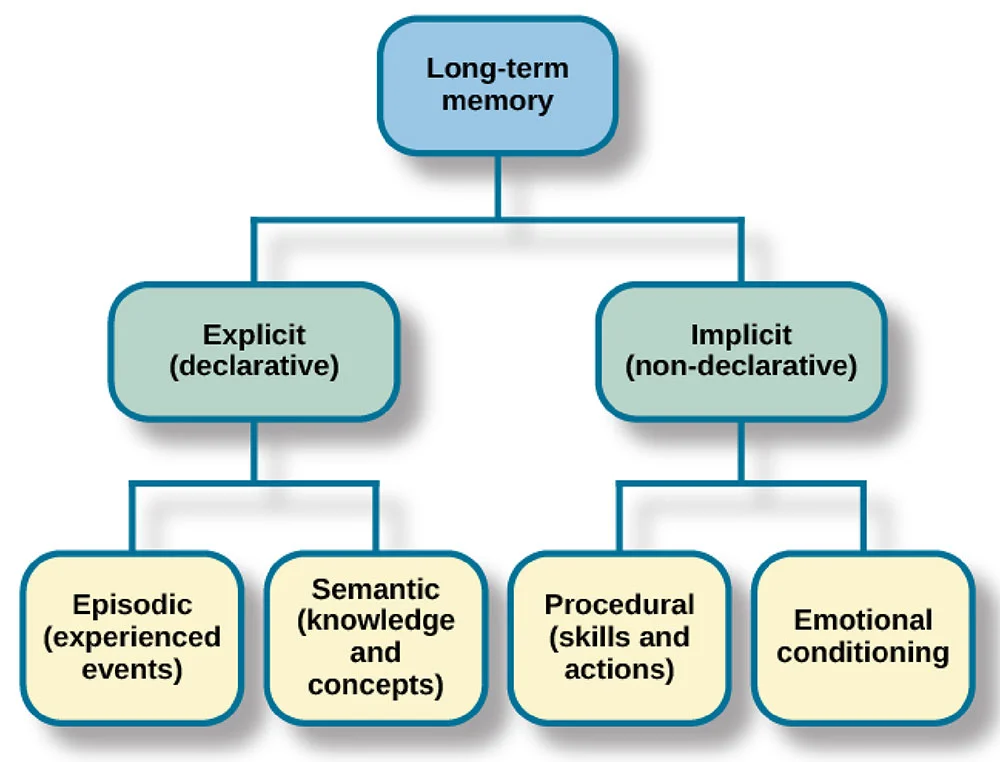
Diferentes tipos de memória têm funções distintas nas aplicações LLM. Entender esses tipos ajuda você a projetar arquiteturas de memória eficazes para o seu caso específico.
A memória semântica guarda fatos e conhecimentos gerais que o sistema pode acessar e consultar. Embora os modelos tenham conhecimento básico proveniente do treinamento, a memória semântica, na prática, geralmente se refere a bases de conhecimento externas, bancos de dados ou armazenamentos de documentos que contêm informações factuais.
Por exemplo, um bot de atendimento ao cliente pode ter uma memória semântica que guarda especificações de produtos, informações de preços e políticas da empresa em um banco de dados vetorial. Isso permite que o sistema recupere e consulte fatos precisos e atualizados sem depender só de dados de treinamento que podem estar desatualizados. A memória semântica geralmente fica guardada fora da cabeça e é usada quando a gente precisa, o que facilita atualizar e manter.
Enquanto a memória semântica lida com fatos e conhecimento, a memória episódica foca em experiências específicas. A memória episódica guarda as interações passadas, quais perguntas foram feitas, como o modelo respondeu e o contexto em torno dessas trocas.
A memória episódica permite que o modelo faça referência a partes anteriores da conversa de forma natural, dizendo coisas como “como discutimos anteriormente” ou “com base no que você me contou sobre o seu projeto”. Esse tipo de memória geralmente não é paramétrica, sendo armazenada em buffers de conversação ou bancos de dados.
A memória procedural inclui instruções do sistema e procedimentos aprendidos. Isso inclui o prompt do sistema que define o comportamento da IA, diretrizes sobre como responder e instruções específicas para cada tarefa.
Quando você configura um modelo para “sempre responder em tópicos” ou “priorizar a precisão em vez da criatividade”, você está definindo a memória procedural. Isso molda como o modelo processa e responde às informações, em vez de quais informações ele conhece.
Além desses tipos básicos de memória, implementações práticas, especialmente em estruturas como LangChain, oferecem várias formas de memória conversacional.
ConversationBufferMemory Armazena todas as mensagens na íntegra, mantendo o histórico completo da conversa, ideal para conversas curtas em que você precisa do contexto completo. ConversationSummaryMemory compacta interações anteriores em resumos, reduzindo o uso de tokens e preservando as informações importantes para conversas mais longas. ConversationBufferWindowMemory mantém só as N mensagens mais recentes, criando uma janela deslizante de contexto que funciona bem quando só as trocas recentes importam. ConversationSummaryBufferMemory combina abordagens, mantendo as mensagens recentes na íntegra e resumindo as conversas mais antigas, oferecendo um equilíbrio entre detalhes e eficiência. Cada formulário tem suas vantagens e desvantagens entre completude e eficiência, permitindo que você escolha com base nas necessidades específicas da sua aplicação.Entender esses tipos de memória é essencial, mas todos eles funcionam dentro de uma limitação fundamental: a janela de contexto. Vamos ver como essa limitação arquitetônica influencia a implementação da memória.
Acho que talvez um dos pontos principais da memória LLM que a gente precisa entender é o conceito de janelas de contexto. Vamos dar uma olhada rápida em como elas funcionam.
Uma janela de contexto é a quantidade máxima de texto, medida em tokens, que um LLM pode processar em uma única solicitação. Tokens são pedaços de texto, que mais ou menos correspondem a palavras ou subpalavras.
A janela de contexto funciona como a memória de trabalho imediata do modelo. Tudo o que o modelo considera deve caber nessa janela: prompt do sistema, histórico de conversas, documentos recuperados e espaço de resposta. À medida que as conversas aumentam, as mensagens mais antigas precisam ser removidas para dar lugar às novas.
O tamanho da janela de contexto muda bastante. Por exemplo, o GPT-5 suporta 400.000 tokens, o Claude 4.5 Sonnet suporta 200.000 tokens e o Gemini 3 Pro chega a 1,5 milhão de tokens. Janelas maiores permitem um contexto mais rico, mas aumentam os custos computacionais de forma quadrática.
Embora janelas de contexto grandes pareçam ideais, elas trazem desafios práticos significativos que afetam a implementação no mundo real.
Pela minha experiência, o maior problema com janelas de contexto é o problema de “perder-se no meio”. Pesquisas mostram que os LLMs prestam mais atenção às informações no começo e no final da janela de contexto, com o conteúdo do meio recebendo menos atenção. Encher o contexto com informações não garante um uso eficaz.
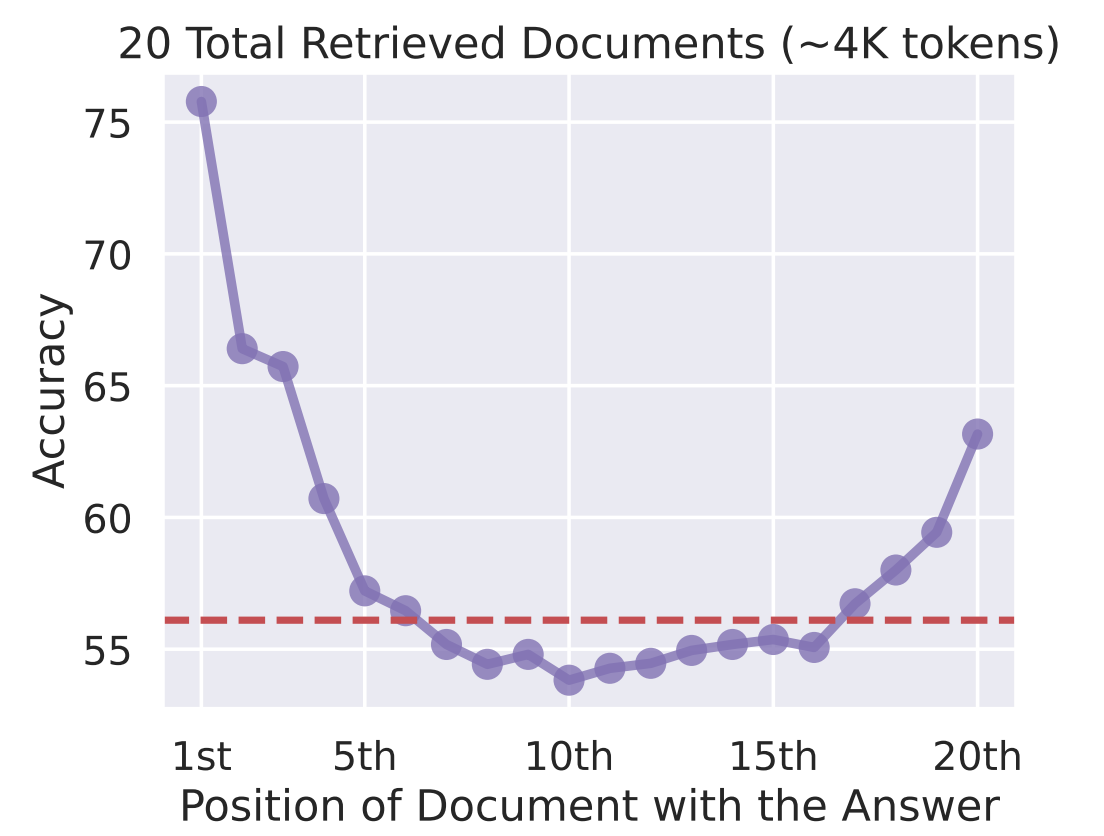
Precisão vs. Posição do documento com a resposta
As limitações computacionais tornam a expansão das janelas de contexto cara. Processar um contexto de 100.000 tokens precisa de muito mais memória da GPU e tempo do que um contexto de 10.000 tokens.
Para aplicações de produção, esses custos aumentam rapidamente, exigindo sistemas de memória inteligentes que incluam seletivamente apenas as informações relevantes.
Com essas limitações, a solução não é só aumentar as janelas de contexto, mas criar sistemas mais inteligentes que as usem de forma eficiente.
As aplicações eficazes de LLM juntam janelas de contexto com sistemas de memória que vão além do contexto imediato. O padrão envolve usar a janela de contexto para informações de curto prazo e alta prioridade, enquanto armazena a memória de longo prazo externamente e a recupera seletivamente.
Uma arquitetura típica mantém as conversas recentes na janela de contexto, guarda as conversas mais antigas em um banco de dados e usa mecanismos de recuperação para trazer informações relevantes do passado quando necessário. Isso equilibra a integridade com a eficiência e o desempenho.
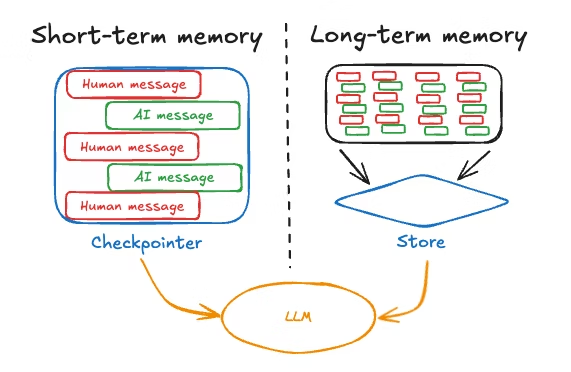
Com essa compreensão arquitetônica em mente, vamos ver como implementar sistemas de memória de curto prazo eficazes que funcionem dentro dessas limitações.
Os sistemas de memória de curto prazo gerenciam as informações dentro da sessão atual, principalmente usando a janela de contexto. Gosto de pensar nisso como a memória de trabalho do modelo; as informações que ele mantém ativamente enquanto processa a conversa atual.
Vamos ver como maximizar esse espaço de memória limitado, mas super importante.
A aprendizagem contextual refere-se à capacidade do modelo de adaptar o comportamento com base em exemplos ou instruções na solicitação. Você ensina o modelo mostrando o que fazer dentro da janela de contexto, em vez de fazer ajustes finos.
O mecanismo é simples:
Os benefícios dessa abordagem incluem:
As limitações incluem eficácia reduzida em muitos casos por causa da “perda no meio”, aumento dos custos simbólicos e desempenho que raramente chega perto dos modelos ajustados.
A aprendizagem contextual mostra o que é possível fazer com a memória de curto prazo, mas como é que a informação é realmente armazenada para o modelo usar? Vamos ver como funciona a formação da memória.
A formação da memória nos sistemas LLM pode ser consciente (explícita) ou subconsciente (implícita).
Muitas estruturas mantêm automaticamente buffers de conversação, criando memória implícita sem operações explícitas. O desafio é gerenciar esse acúmulo, garantindo que as informações relevantes continuem lá, enquanto os detalhes menos importantes são eliminados.
A memória de curto prazo lida com as necessidades imediatas da conversa, mas o que acontece quando você precisa que as informações continuem além da sessão atual? É aí que as soluções de memória de longo prazo se tornam essenciais.
A memória de longo prazo permite que os LLMs guardem informações entre sessões.
Enquanto a memória de curto prazo é efêmera e desaparece quando a conversa termina, a memória de longo prazo persiste, permitindo que sua IA se lembre das preferências do usuário, interações passadas e conhecimento acumulado ao longo do tempo.
Vou destacar duas abordagens principais: sistemas de memória baseados em texto que armazenam informações externamente e cache de chave-valor que otimiza a forma como o modelo acessa informações calculadas anteriormente.
A memória baseada em texto guarda o histórico das conversas e as informações do usuário em bancos de dados ou armazenamentos vetoriais. A aquisição envolve capturar informações relevantes, preferências, decisões, fatos ou detalhes contextuais.
A gestão da memória precisa de compressão e organização. As técnicas de resumo condensam as conversas em pontos-chave. A organização hierárquica organiza as memórias por tópicos, períodos de tempo ou relevância.
A utilização concentra-se na recuperação. A pesquisa por similaridade vetorial encontra memórias relevantes por significado semântico. A recuperação baseada no tempo prioriza as informações mais recentes. A pontuação de relevância classifica as memórias por importância.
Os sistemas baseados em texto lidam com o que armazenar, mas também há a questão de como tornar a recuperação mais eficiente. É aí que entra o cache de chave-valor.
O cache de chave-valor (KV) melhora a eficiência da geração de tokens. Durante a geração do texto, o modelo calcula a atenção sobre todos os tokens anteriores. O cache KV guarda esses cálculos intermediários, permitindo reutilizá-los na geração de tokens seguintes sem precisar recalcular tudo de novo.
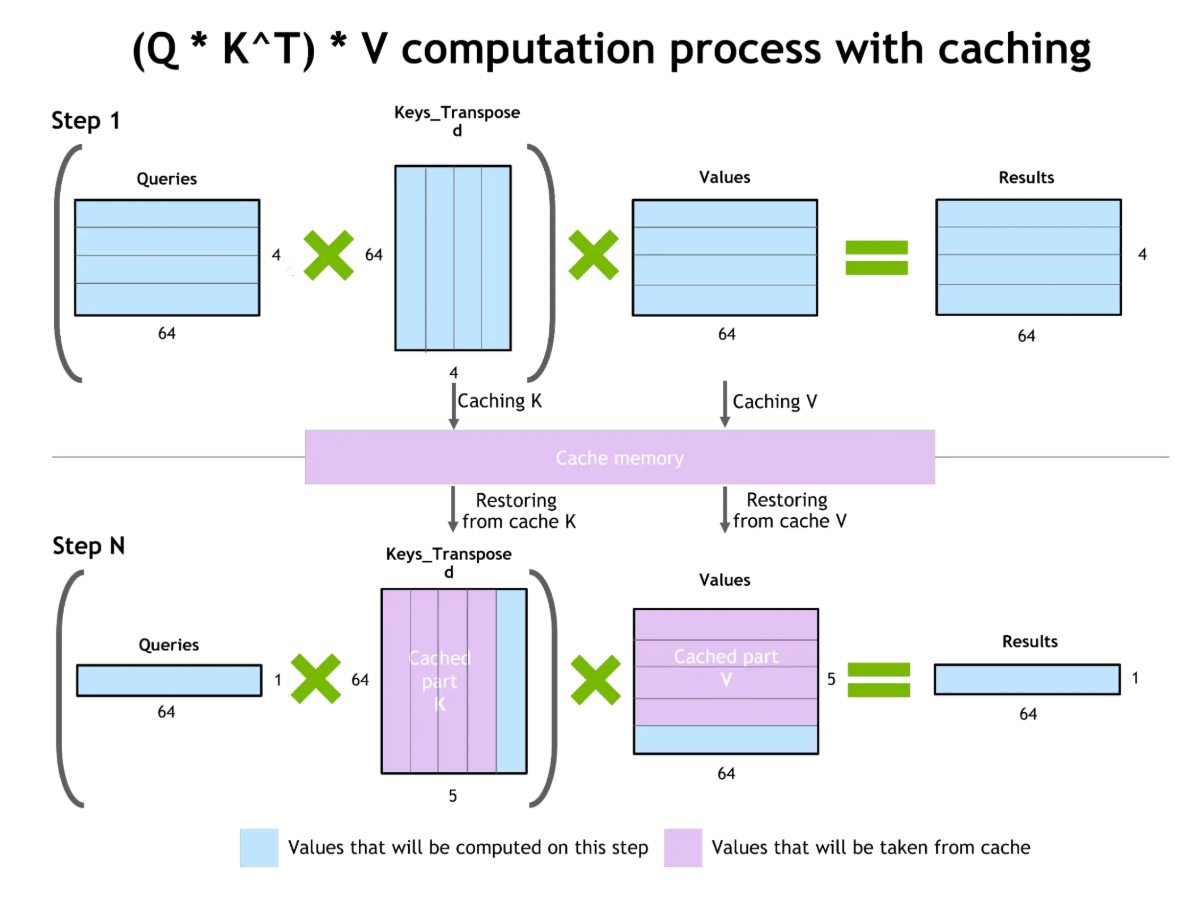
Cache de chave-valor e otimização de atenção
A vantagem é grande: menos custo de computação, respostas mais rápidas e menos uso de recursos. Mas, os pares de chave-valor armazenados em cache usam a VRAM da GPU. Em contextos muito longos, o tamanho do cache KV vira uma limitação.
Embora o cache KV otimize a forma como os modelos usam suas janelas de contexto, ele não resolve o problema básico da capacidade limitada de memória. É aí que a geração aumentada por recuperação oferece uma abordagem complementar.
Um dos avanços recentes que considero mais interessante é a Geração Aumentada por Recuperação ou RAG. O RAG conecta a memória interna e externa, ampliando a memória de um LLM além das limitações da janela de contexto.
Em vez de depender só do que o modelo aprendeu durante o treinamento ou do que se encaixa no contexto atual, o RAG pega informações relevantes de fontes externas exatamente quando precisa. Vamos explorar o RAG com mais detalhes.
A arquitetura RAG tem dois componentes principais: um recuperador que procura informações relevantes em bases de conhecimento externas e um gerador (o LLM) que cria respostas com base na consulta e no contexto recuperado.
Quando uma consulta chega, o recuperador encontra documentos relevantes em bancos de dados vetoriais ou bases de conhecimento. Os documentos recuperados são colocados na janela de contexto, dando informações específicas para fundamentar a resposta.
Os benefícios do RAG incluem a redução das alucinações por meio da referência a documentos reais, maior precisão pelo acesso a informações atualizadas além dos dados de treinamento e incorporação de conhecimento proprietário sem a necessidade de novo treinamento.
Mas, os desafios incluem possíveis alucinações quando os documentos recuperados têm erros, problemas de relevância se a recuperação trouxer informações inúteis e a complexidade de gerenciar bancos de dados vetoriais.
O verdadeiro poder do RAG fica claro quando a gente pensa em como ele lida com uma das limitações mais importantes que falamos antes: as restrições da janela de contexto.
O RAG amplia o contexto além do tamanho da janela, recuperando seletivamente apenas as informações relevantes. Em vez de manter um histórico completo das conversas, você guarda tudo fora do sistema e pega as partes que precisa, o que permite conversas praticamente ilimitadas dentro das restrições da janela de contexto.
As estratégias para melhorar as janelas de contexto com RAG incluem a recuperação híbrida, que combina a pesquisa semântica com a filtragem de metadados, a reclassificação dos resultados recuperados para priorizar documentos relevantes e a recuperação recursiva, em que a resposta inicial do modelo orienta a recuperação adicional.
O RAG é uma abordagem prática e pronta para produção para a extensão da memória, mas a galera da pesquisa continua inovando com novas arquiteturas que repensam como os modelos lidam com a memória em um nível básico.
Novas arquiteturas e sistemas inspirados na neurociência estão melhorando as capacidades de memória do LLM. Essas abordagens inovadoras repensam como os modelos lidam com informações de contexto longo, indo além das limitações tradicionais dos transformadores para criar sistemas de memória mais eficientes e parecidos com os humanos.
Arquiteturas como Mamba e transformadores de memória recorrente otimizam a eficiência da memória. O Mamba usa modelos de espaço de estado em vez de mecanismos de atenção, conseguindo uma escala linear em vez de quadrática com o comprimento da sequência, o que permite processar sequências bem mais longas com recursos comparáveis.
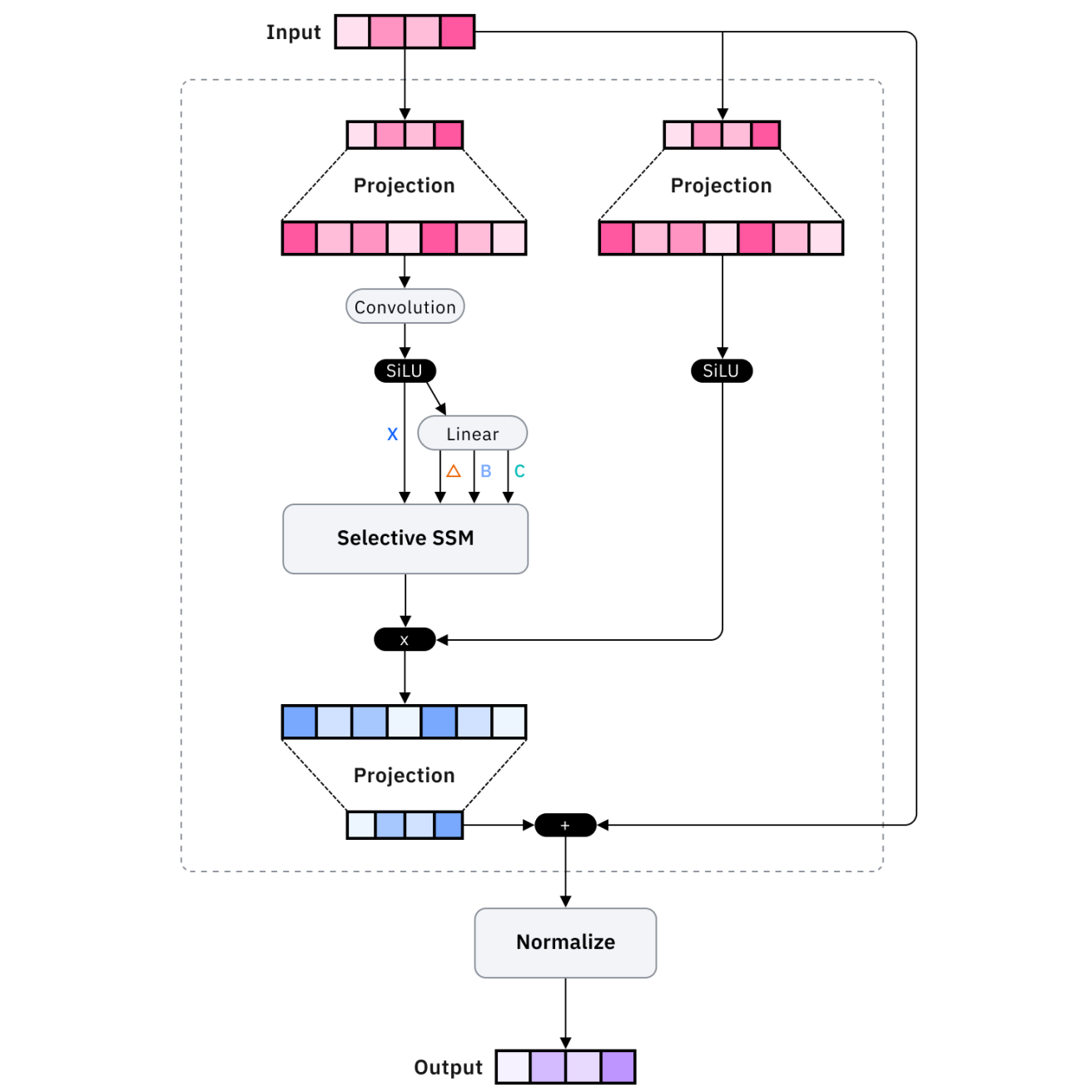
Os transformadores de memória recorrente aumentam os transformadores padrão com conexões recorrentes que mantêm o estado de longo prazo, permitindo que as informações persistam além da janela de contexto imediato por meio de mecanismos de memória aprendidos.
Essas inovações arquitetônicas são super interessantes do ponto de vista da pesquisa, mas e quanto às soluções prontas para produção? É aí que entram as plataformas de memória externa.
Plataformas como Mem0 e Zep oferecem soluções de memória externa prontas para produção. O Mem0 oferece uma camada de memória gerenciada que extrai, armazena e recupera automaticamente informações relevantes. O Zep foca na memória conversacional com resumo integrado, extração de fatos e pesquisa vetorial.
Embora essas plataformas ofereçam soluções práticas, alguns pesquisadores estão se inspirando em uma fonte inesperada: como o cérebro humano realmente forma e gerencia as memórias.
CAMELoT (Consolidated Associative Memory Enhanced Long Transformer) usa princípios da neurociência na memória do LLM, implementando consolidação, detecção de novidades e ponderação de recência. Esses princípios refletem os sistemas de memória humanos, criando um comportamento de memória mais natural.
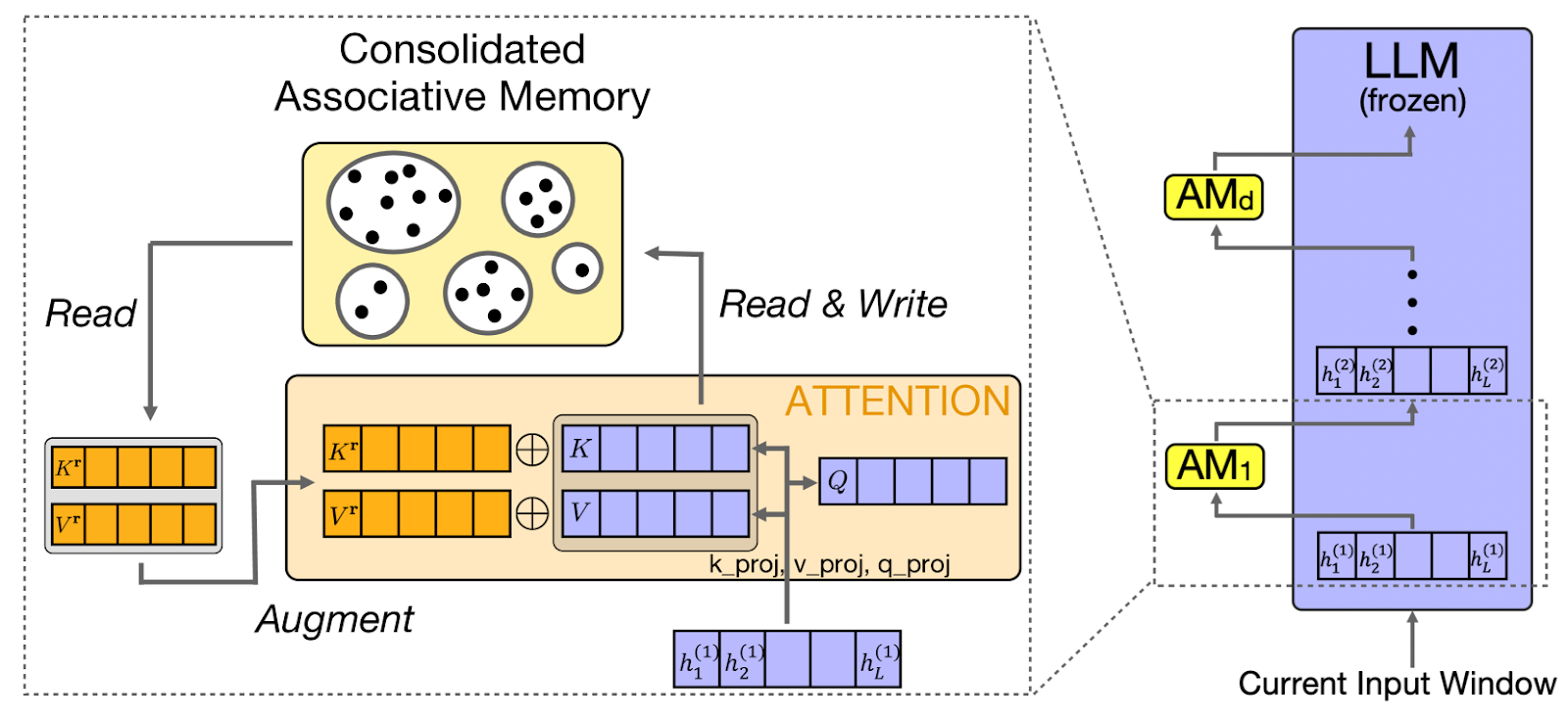
Com base nesses princípios da neurociência, outra abordagem, como a Laminar, foca especificamente em como os humanos se lembram de experiências e eventos distintos.
Larimar permite que os LLMs mantenham episódios de memória distintos. Em vez de tratar todas as informações passadas da mesma forma, a memória episódica organiza as informações em eventos separados. Isso permite generalizar o comprimento do contexto. O modelo faz referência a episódios específicos do passado sem carregar o histórico completo.
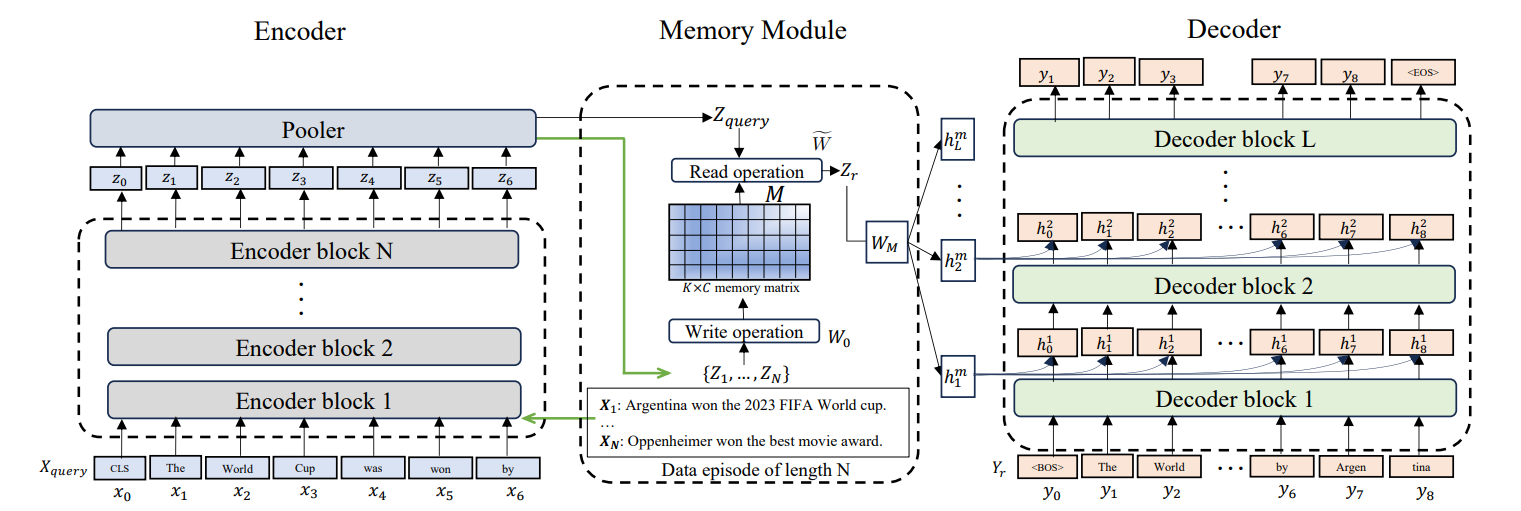
Essas arquiteturas avançadas são super promissoras, mas também trazem novas complexidades. Vamos ver os desafios práticos que aparecem na hora de implementar sistemas de memória e as estratégias para dar um jeito neles.
Mesmo com arquiteturas sofisticadas, descobri que os sistemas de memória enfrentam desafios que muitas vezes exigem uma mitigação cuidadosa. Entender esses desafios e suas soluções é essencial para criar sistemas de produção robustos nos quais os usuários possam confiar.
O esquecimento catastrófico rola quando os modelos perdem informações que aprenderam antes. As soluções incluem consolidação da memória, reforço de memórias importantes, hierarquias de memória, preservação de informações críticas e atualização periódica da memória.
Além do esquecimento, outro desafio crítico é quando os sistemas de memória induzem ativamente o modelo em erro. A alucinação (gerar informações plausíveis, mas incorretas) é piorada por uma memória ruim. A mitigação envolve atribuição da fonte, pontuação de confiança para memórias recuperadas e etapas de verificação.
Por fim, guardar as conversas e preferências dos usuários levanta questões importantes sobre privacidade. As questões de privacidade e segurança são super importantes quando se trata de guardar os dados dos usuários. Implemente criptografia de dados, políticas de retenção que apagam automaticamente dados antigos e controles de acesso que garantem que os usuários só acessem suas próprias memórias.
Integrar a memória precisa de um design de API bem pensado. Os padrões principais incluem integração com estado, onde o sistema de memória mantém o estado entre as solicitações, e integração sem estado, onde cada solicitação inclui os identificadores necessários.
O gerenciamento eficiente da memória usa o corte (tirar as mensagens mais antigas ou menos relevantes), a exclusão (tirar itens específicos) e a síntese (comprimir mensagens). Esses padrões mantêm a memória dentro do orçamento, preservando o contexto essencial.
Entender esses padrões teóricos e desafios é importante, mas o verdadeiro teste é na hora de colocar em prática. Vamos transformar esses conceitos em orientações práticas que você pode usar nos seus próprios projetos.
Aqui estão algumas maneiras que vi os desenvolvedores aproveitarem ao máximo os sistemas de memória LLM.
Uma gestão eficaz do contexto começa com a compreensão do seu orçamento de tokens. Calcule quantos tokens seu sistema precisa para prompt, memória e resposta, garantindo que a soma fique dentro dos limites. Organize os dados de forma hierárquica, colocando as informações importantes onde o modelo funciona melhor — no começo ou no final.
Igualmente importante é como você prepara os dados antes de colocá-los no seu sistema de memória. A preparação dos dados é super importante. Divida documentos grandes em partes semânticas, em vez de limites arbitrários de tokens. Sobreponha ligeiramente os trechos para manter a continuidade do contexto. Inclua metadados em cada bloco para permitir a recuperação filtrada.
Depois que seu sistema estiver funcionando, você vai precisar de maneiras de medir se ele está realmente funcionando. A avaliação da memória precisa programar métricas como precisão de recuperação, taxa de alucinação e satisfação do usuário. Fique de olho na latência do sistema de memória, no uso de tokens e na relevância da recuperação.
Por fim, sua estratégia de recuperação deve se adaptar à complexidade do que os usuários pedem. Estratégias de recuperação flexíveis se adaptam à complexidade da consulta. As consultas simples usam a pesquisa por palavra-chave, enquanto as perguntas complexas se beneficiam da pesquisa por similaridade semântica. Use namespaces de memória pra organizar as informações por usuário, assunto ou período de tempo.
A memória de modelos de linguagem grandes transforma esses modelos de geradores de texto sem estado em assistentes de IA que entendem o contexto e são capazes de interações coerentes e personalizadas. Ao longo deste tutorial, explorei os fundamentos da memória LLM, desde janelas de contexto até arquiteturas avançadas.
Acho que o principal é começar com janelas de contexto e buffers de conversação bem gerenciados para as necessidades imediatas, implementar RAG para acesso escalável ao conhecimento além da memória paramétrica, aproveitar plataformas de memória externas para aplicações de produção e avaliar continuamente a eficácia da memória por meio de métricas e feedback dos usuários.
À medida que as capacidades do LLM avançam, os sistemas de memória vão ficar cada vez mais sofisticados. Para os profissionais, o foco é criar sistemas de memória que atendam às necessidades dos usuários: manter o contexto relevante, esquecer o que for preciso e permitir interações naturais que tornem as aplicações de IA realmente úteis.
Pra continuar aprendendo, recomendo dar uma olhada nesses recursos:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita

