
Cours
Introduction aux LLM en Python
3 h
33.6K
De nombreux développeurs créent des chatbots et des assistants IA capables de répondre brillamment à des questions de manière isolée, mais qui ont du mal à maintenir des conversations cohérentes. La cause principale ? Manque de mémoire. Lorsqu'un utilisateur pose une question complémentaire en faisant référence au contexte précédent, les modèles linguistiques sans état la traitent comme si elle était entièrement nouvelle, ce qui entraîne des interactions répétitives et frustrantes.
Il est essentiel de comprendre et de mettre en œuvre la mémoire dans les grands modèles linguistiques pour créer des applications d'IA qui semblent naturelles et intelligentes. La mémoire permet aux LLM de conserver le contexte tout au long des conversations, d'apprendre des interactions passées et de fournir des réponses personnalisées. Dans ce tutoriel, je vous présenterai les principes fondamentaux de la mémoire LLM, depuis les fenêtres contextuelles de base jusqu'aux architectures avancées.
Si vous débutez dans le domaine des LLM, je vous recommande de suivre l'un de nos cours, tel que Développer des applications LLM avec LangChain, Développement de grands modèles linguistiquesou Concepts LLMOps.
Les grands modèles linguistiques traitent les informations différemment des logiciels traditionnels. Alors que les bases de données stockent et récupèrent les données de manière explicite, les LLM doivent gérer la mémoire dans le cadre de contraintes architecturales telles que les fenêtres contextuelles et les limites de jetons. Le défi consiste à faire en sorte que les modèles mémorisent les informations pertinentes tout en omettant les détails superflus, en maintenant la cohérence sans surcharger les ressources informatiques.
Avant d'entrer dans les détails de la mise en œuvre, définissons ce que signifie la mémoire dans le contexte des grands modèles linguistiques et pourquoi elle est importante pour créer des applications d'IA efficaces.
La mémoire dans les LLM fait référence à la capacité du système à conserver et à utiliser les informations issues d'interactions précédentes ou de données d'entraînement. Il ne s'agit pas ici de mémoire au sens informatique traditionnel du terme. Il s'agit de la capacité du modèle à conserver le contexte, à se référer aux échanges passés et à appliquer les modèles appris à de nouvelles situations.
La mémoire est essentielle car elle transforme des paires question-réponse isolées en conversations cohérentes. Sans mémoire, un LLM ne peut pas comprendre lorsque vous dites « veuillez m'en dire plus à ce sujet ». Le modèle nécessite un contexte pour interpréter les références et s'appuyer sur les échanges antérieurs.
Je compare souvent la mémoire LLM à la mémoire humaine. Les êtres humains possèdent une mémoire sensorielle (perception immédiate), une mémoire à court terme (informations actives) et une mémoire à long terme (connaissances stockées). Les LLM mettent en œuvre des systèmes analogues : les fenêtres contextuelles agissent comme la mémoire à court terme, les informations récupérées fonctionnent comme la mémoire à long terme, et les paramètres entraînés représentent les connaissances permanentes.
Maintenant que j'ai abordé le concept fondamental de la mémoire dans les LLM, examinons comment les systèmes de mémoire sont classés afin de vous aider à choisir l'approche la mieux adaptée à votre application spécifique.
Comprendre comment la mémoire est classifiée vous aidera à choisir l'approche la plus adaptée à votre application. La mémoire LLM peut être classée selon trois dimensions clés : l'objet, la forme et le temps.
L' e de dimension d'objet fait la distinction entre la mémoire personnelle et la mémoire système. La mémoire personnelle stocke des informations spécifiques à l'utilisateur, telles que ses préférences et l'historique de ses conversations.
La mémoire système contient les connaissances générales et les capacités accessibles à tous les utilisateurs. Un robot de service client peut utiliser la mémoire système pour stocker des informations sur les produits tout en conservant en mémoire l'historique des commandes de chaque client.
Passant à la deuxième dimension, la dimension de la forme distingue la mémoire paramétrique de la mémoire non paramétrique. La mémoire paramétrique est codée dans les poids du modèle pendant l'entraînement. La mémoire non paramétrique existe en dehors du modèle, stockée dans des bases de données ou des magasins de vecteurs. La mémoire paramétrique est figée après l'apprentissage, tandis que la mémoire non paramétrique peut être mise à jour de manière dynamique.
Enfin, la dimension temporelle classe la mémoire en fonction de sa durée : mémoire à court terme et mémoire à long terme. La mémoire à court terme couvre la conversation en cours, stockée dans la fenêtre contextuelle. La mémoire à long terme persiste d'une session à l'autre, est stockée en externe et récupérée lorsque nécessaire.
Une fois ce cadre de classification établi, examinons les types spécifiques de mémoire que les LLM mettent en œuvre dans la pratique.
Différents types de mémoire remplissent des fonctions distinctes dans les applications LLM. La compréhension de ces types vous aide à concevoir des architectures de mémoire efficaces pour votre cas d'utilisation spécifique.
s de mémoire sémantique stocke des faits et des connaissances générales auxquels le système peut accéder et se référer. Alors que les modèles disposent de connaissances fondamentales issues de leur formation, la mémoire sémantique fait souvent référence, dans la pratique, à des bases de connaissances externes, des bases de données ou des référentiels de documents contenant des informations factuelles.
Par exemple, un bot dédié au service client pourrait disposer d'une mémoire sémantique stockant les spécifications des produits, les informations sur les prix et les politiques de l'entreprise dans une base de données vectorielle. Cela permet au système de récupérer et de référencer des informations précises et actualisées sans dépendre uniquement de données d'entraînement potentiellement obsolètes. La mémoire sémantique est généralement stockée en externe et récupérée lorsque nécessaire, ce qui facilite sa mise à jour et sa maintenance.
Alors que la mémoire sémantique traite des faits et des connaissances, la mémoire épisodique se concentre sur des expériences spécifiques. L' de la mémoire épisodique permet de capturer les interactions passées, les questions posées, les réponses fournies par le modèle et le contexte entourant ces échanges.
La mémoire épisodique permet au modèle de faire naturellement référence aux parties précédentes de la conversation, en utilisant des expressions telles que « comme nous en avons discuté précédemment » ou « d'après ce que vous m'avez dit au sujet de votre projet ». Ce type de mémoire est généralement non paramétrique, stocké dans des tampons de conversation ou des bases de données.
La mémoire procédurale englobe les instructions du système et les procédures apprises. Cela comprend l'invite système qui définit le comportement de l'IA, les directives sur la manière de répondre et les instructions spécifiques à la tâche.
Lorsque vous configurez un modèle pour qu'il « réponde toujours sous forme de liste à puces » ou « privilégie la précision à la créativité », vous définissez une mémoire procédurale. Il détermine la manière dont le modèle traite et réagit aux informations plutôt que les informations dont il dispose.
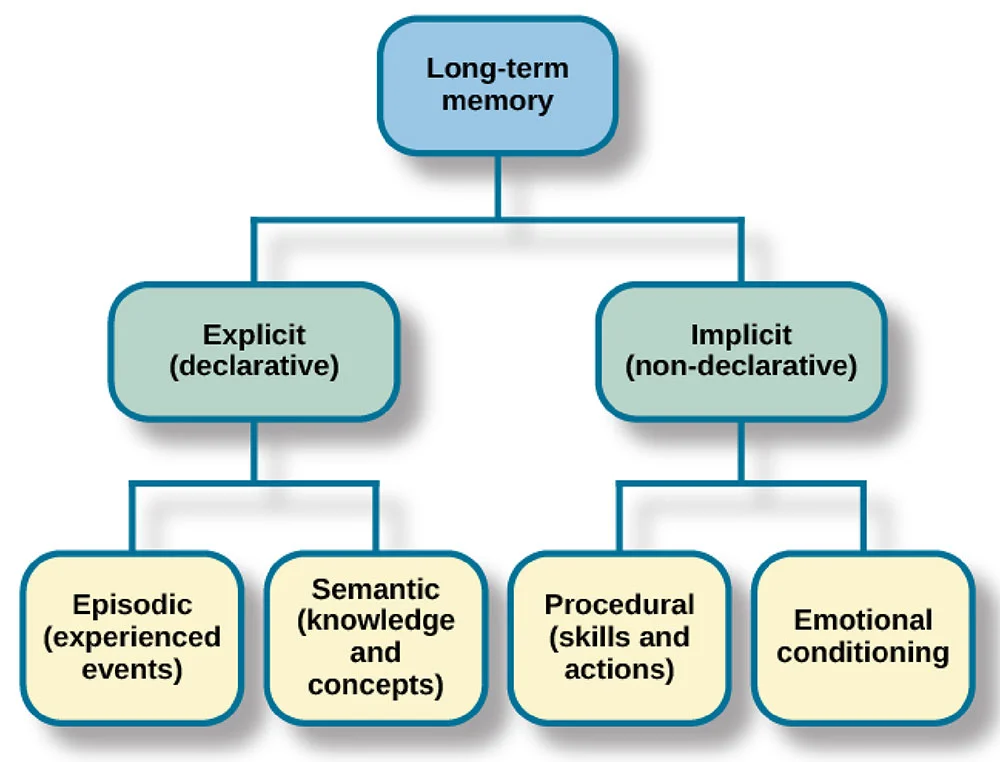
Au-delà de ces types de mémoire fondamentaux, les implémentations pratiques, en particulier dans des cadres tels que LangChain, offrent diverses formes de mémoire conversationnelle.
ConversationBufferMemory stocke tous les messages dans leur intégralité, conservant ainsi l'historique complet des conversations, ce qui est idéal pour les conversations courtes où vous avez besoin de disposer de tout le contexte. ConversationSummaryMemory compresse les interactions passées en résumés, réduisant ainsi l'utilisation de jetons tout en conservant les informations clés pour les conversations plus longues. ConversationBufferWindowMemory conserve uniquement les N messages les plus récents, créant ainsi une fenêtre contextuelle mobile qui fonctionne efficacement lorsque seuls les échanges récents sont pertinents. ConversationSummaryBufferMemory combine différentes approches, en conservant les messages récents dans leur intégralité tout en résumant les échanges plus anciens, offrant ainsi un équilibre entre précision et efficacité. Chaque formulaire présente un compromis entre exhaustivité et efficacité, vous permettant ainsi de faire votre choix en fonction des besoins spécifiques de votre application.Il est essentiel de comprendre ces types de mémoire, mais ils fonctionnent tous dans le cadre d'une contrainte fondamentale : la fenêtre contextuelle. Examinons comment cette contrainte architecturale influence la mise en œuvre de la mémoire.
Je pense que l'un des aspects essentiels à comprendre concernant la mémoire LLM est le concept des fenêtres contextuelles. Examinons brièvement leur fonctionnement.
Une fenêtre contextuelle correspond à la quantité maximale de texte, mesurée en tokens, qu'un LLM peut traiter en une seule requête. Les tokens sont des fragments de texte correspondant approximativement à des mots ou à des sous-mots.
La fenêtre contextuelle agit comme la mémoire de travail immédiate du modèle. Tout ce que le modèle prend en compte doit s'inscrire dans cette fenêtre : invite du système, historique des conversations, documents récupérés et espace de réponse. Au fur et à mesure que les conversations s'allongent, les messages plus anciens doivent être supprimés pour faire place aux nouveaux.
La taille de la fenêtre contextuelle varie considérablement. Par exemple, GPT-5 prend en charge 400 000 jetons, Claude 4.5 Sonnet gère 200 000 jetons et Gemini 3 Pro s'étend à 1,5 million de jetons. Des fenêtres plus grandes permettent un contexte plus riche, mais augmentent les coûts de calcul de manière quadratique.
Bien que les fenêtres contextuelles de grande taille semblent idéales, elles présentent des défis pratiques importants qui affectent leur déploiement dans le monde réel.
D'après mon expérience, le principal problème lié aux fenêtres contextuelles est celui de la « perte au milieu ». Les recherches indiquent que les LLM accordent davantage d'attention aux informations situées au début et à la fin de la fenêtre contextuelle, le contenu intermédiaire recevant moins d'attention. Le simple fait de remplir le contexte d'informations ne garantit pas une utilisation efficace.
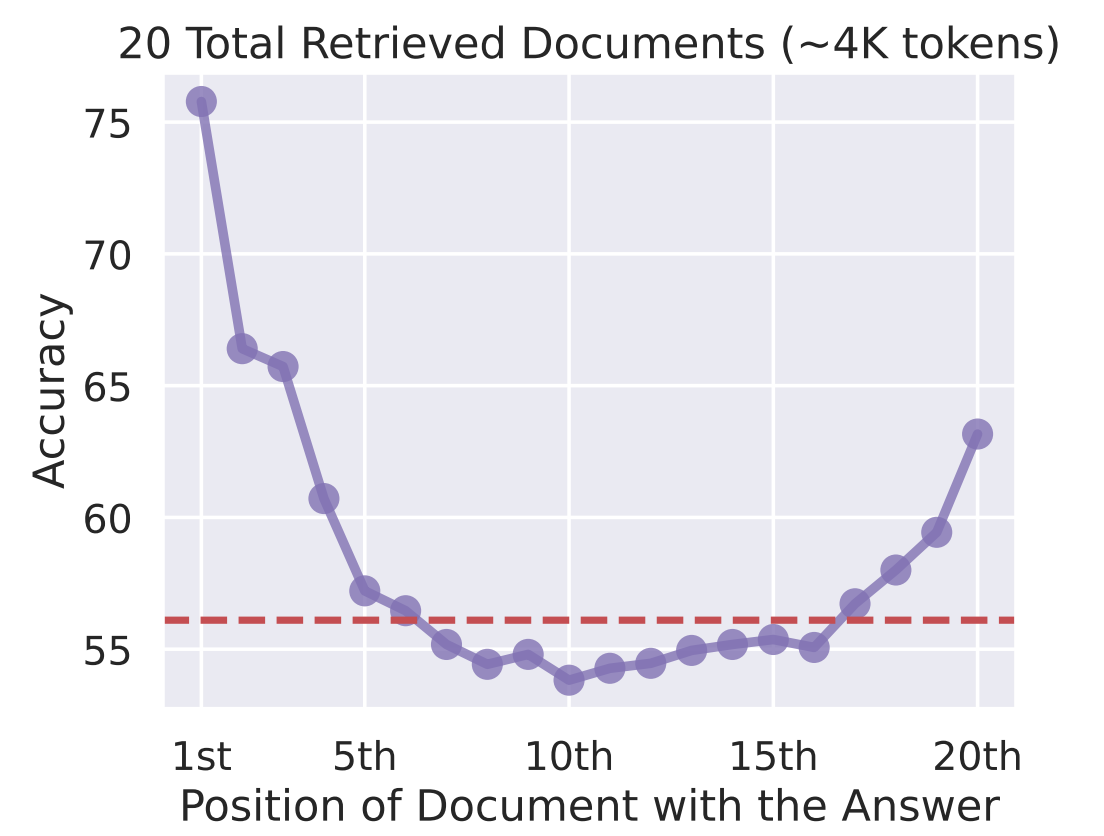
Précision par rapport à Emplacement du document contenant la réponse
Les contraintes informatiques rendent l'extension des fenêtres contextuelles coûteuse. Le traitement d'un contexte de 100 000 jetons nécessite beaucoup plus de mémoire GPU et de temps qu'un contexte de 10 000 jetons.
Dans les applications de production, ces coûts s'accumulent rapidement, ce qui rend nécessaire le recours à des systèmes de mémoire intelligents qui ne conservent que les informations pertinentes.
Compte tenu de ces contraintes, la solution ne consiste pas simplement à élargir les fenêtres contextuelles, mais à créer des systèmes plus intelligents qui les utilisent efficacement.
Les applications LLM efficaces combinent des fenêtres contextuelles avec des systèmes de mémoire qui s'étendent au-delà du contexte immédiat. Le modèle consiste à utiliser la fenêtre contextuelle pour les informations à court terme et à haute priorité, tout en stockant la mémoire à long terme en externe et en la récupérant de manière sélective.
Une architecture typique conserve les derniers échanges dans la fenêtre contextuelle, stocke les conversations plus anciennes dans une base de données et utilise des mécanismes de récupération pour extraire les informations passées pertinentes lorsque cela est nécessaire. Cela permet d'équilibrer l'exhaustivité, l'efficacité et la performance.
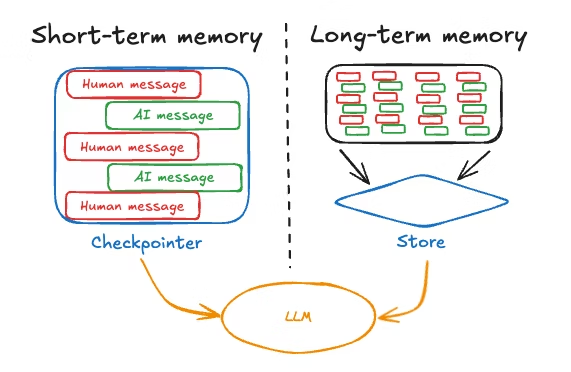
Une fois ces concepts architecturaux acquis, nous allons examiner comment mettre en œuvre des systèmes de mémoire à court terme efficaces qui fonctionnent dans le cadre de ces contraintes.
Les systèmes de mémoire à court terme gèrent les informations au sein de la session en cours, en s'appuyant principalement sur la fenêtre contextuelle. Je considère cela comme la mémoire de travail du modèle, c'est-à-dire les informations qu'il conserve activement pendant le traitement de la conversation en cours.
Voyons comment optimiser cet espace mémoire limité mais essentiel.
L'apprentissage contextuel fait référence à la capacité du modèle à adapter son comportement en fonction des exemples ou des instructions fournis dans l'invite. Vous enseignez au modèle en lui montrant quoi faire dans la fenêtre contextuelle plutôt qu'en effectuant des réglages précis.
Le mécanisme est simple :
Les avantages de cette approche comprennent :
Les limites comprennent une efficacité réduite dans de nombreux cas en raison de la « perte au milieu », l'augmentation des coûts des jetons et des performances qui correspondent rarement à celles des modèles optimisés.
L'apprentissage en contexte démontre ce qu'il est possible de réaliser avec la mémoire à court terme, mais comment les informations sont-elles réellement stockées pour que le modèle puisse les utiliser ? Explorons les mécanismes qui sous-tendent la formation de la mémoire.
La formation de la mémoire dans les systèmes LLM peut être consciente (explicite) ou subconsciente (implicite).
De nombreux frameworks gèrent automatiquement les tampons de conversation, créant ainsi une mémoire implicite sans opérations explicites. Le défi consiste à gérer cette accumulation, en veillant à ce que les informations pertinentes soient conservées tandis que les détails moins importants sont supprimés.
La mémoire à court terme gère les besoins conversationnels immédiats, mais que se passe-t-il lorsque vous avez besoin que les informations persistent au-delà de la session en cours ? C'est là que les solutions de mémoire à long terme deviennent indispensables.
La mémoire à long terme permet aux LLM de conserver les informations d'une session à l'autre.
Alors que la mémoire à court terme est éphémère et disparaît à la fin de la conversation, la mémoire à long terme persiste, permettant à votre IA de se souvenir des préférences des utilisateurs, des interactions passées et des connaissances accumulées au fil du temps.
Je vais mettre en avant deux approches clés : les systèmes de mémoire textuelle qui stockent les informations en externe et la mise en cache clé-valeur qui optimise la manière dont le modèle accède aux informations précédemment calculées.
La mémoire textuelle stocke l'historique des conversations et les informations utilisateur dans des bases de données ou des magasins vectoriels. L'acquisition consiste à recueillir des informations pertinentes, des préférences, des décisions, des faits ou des détails contextuels.
La gestion de la mémoire nécessite une compression et une organisation. Les techniques de synthèse permettent de condenser les conversations en points clés. Les structures organisationnelles hiérarchiques classent les souvenirs par thèmes, périodes ou pertinence.
L'utilisation est axée sur la récupération. La recherche par similarité vectorielle identifie les souvenirs pertinents en fonction de leur signification sémantique. La recherche basée sur le temps donne la priorité aux informations récentes. Le score de pertinence classe les souvenirs par ordre d'importance.
Les systèmes textuels gèrent ce qu'il convient de stocker, mais il convient également de se demander comment rendre la recherche plus efficace. C'est là que la mise en cache clé-valeur entre en jeu.
La mise en cache clé-valeur (KV) améliore l'efficacité de la génération de jetons. Lors de la génération de texte, le modèle calcule l'attention sur tous les tokens précédents. La mise en cache KV stocke ces calculs intermédiaires, ce qui permet de les réutiliser lors de la génération des jetons suivants sans avoir à les recalculer.
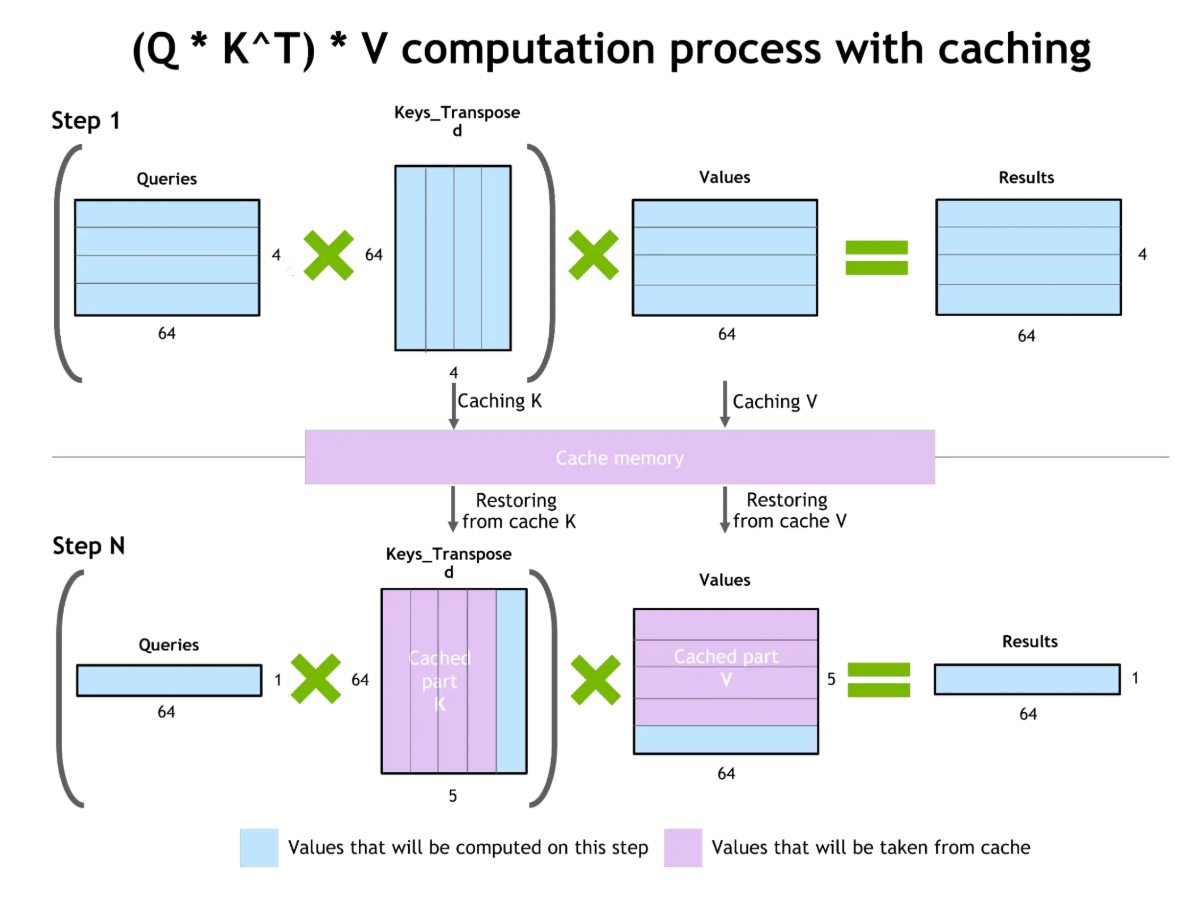
Mise en cache des valeurs clés et optimisation de l'attention
L'avantage est considérable : réduction des coûts informatiques, accélération des réponses et diminution de l'utilisation des ressources. Cependant, les paires clé-valeur mises en cache utilisent la mémoire VRAM du GPU. Dans des contextes de très longue durée, la taille du cache KV peut constituer une contrainte.
Bien que la mise en cache KV optimise la manière dont les modèles utilisent leurs fenêtres contextuelles, elle ne résout pas le problème fondamental de la capacité mémoire limitée. C'est là que la génération augmentée par la récupération offre une approche complémentaire.
L'une des avancées récentes que je trouve particulièrement intéressante est la la génération augmentée par la recherche (RAG). RAG relie la mémoire interne et externe, étendant ainsi la mémoire d'un LLM au-delà des contraintes de la fenêtre contextuelle.
Au lieu de se fier uniquement à ce que le modèle a appris pendant la formation ou à ce qui correspond au contexte actuel, RAG extrait de manière dynamique les informations pertinentes provenant de sources externes exactement au moment où elles sont nécessaires. Explorons plus en détail le RAG.
L'architecture RAG se compose de deux éléments principaux : un récupérateur qui recherche des informations pertinentes dans des bases de connaissances externes et un générateur (le LLM) qui produit des réponses en fonction de la requête et du contexte récupéré.
Lorsqu'une requête est reçue, le moteur de recherche identifie les documents pertinents à partir de bases de données vectorielles ou de bases de connaissances. Les documents récupérés sont intégrés dans la fenêtre contextuelle, fournissant des informations spécifiques pour étayer la réponse.
Les avantages du RAG comprennent une réduction des hallucinations grâce à la consultation de documents réels, une amélioration de la précision grâce à l'accès à des informations actualisées au-delà des données d'entraînement, et l'intégration de connaissances propriétaires sans nécessiter de nouvel entraînement.
Cependant, les défis à relever comprennent les hallucinations potentielles lorsque les documents récupérés contiennent des erreurs, les problèmes de pertinence si la recherche renvoie des informations inutiles et la complexité de la gestion des bases de données vectorielles.
La véritable puissance du RAG apparaît clairement lorsque l'on considère la manière dont il résout l'une des limitations fondamentales évoquées précédemment : les contraintes liées à la fenêtre contextuelle.
RAG étend le contexte au-delà de la taille de la fenêtre en récupérant de manière sélective uniquement les informations pertinentes. Plutôt que de conserver l'historique complet des conversations, vous le stockez en externe et récupérez les parties pertinentes selon les besoins, ce qui permet de prendre en charge une durée de conversation pratiquement illimitée dans les limites de la fenêtre contextuelle.
Les stratégies visant à améliorer les fenêtres contextuelles avec RAG comprennent la recherche hybride combinant la recherche sémantique et le filtrage des métadonnées, le reclassement des résultats récupérés afin de hiérarchiser les documents pertinents, et la recherche récursive où la réponse initiale du modèle guide la recherche supplémentaire.
RAG représente une approche pratique et prête à la production pour l'extension de la mémoire, mais la communauté scientifique continue de repousser les limites avec des architectures novatrices qui réinventent la manière dont les modèles gèrent la mémoire à un niveau fondamental.
De nouvelles architectures et des systèmes inspirés des neurosciences améliorent les capacités de mémoire des LLM. Ces approches innovantes réinventent la manière dont les modèles traitent les informations contextuelles à long terme, dépassant les limites traditionnelles des transformateurs pour créer des systèmes de mémoire plus efficaces et plus proches de ceux de l'être humain.
Les architectures telles que Mamba et les transformateurs à mémoire récurrente optimisent l'efficacité de la mémoire. Mamba utilise des modèles d'espace d'état plutôt que des mécanismes d'attention, ce qui permet d'obtenir une mise à l'échelle linéaire plutôt que quadratique avec la longueur de la séquence, et donc de traiter des séquences beaucoup plus longues avec des ressources comparables.
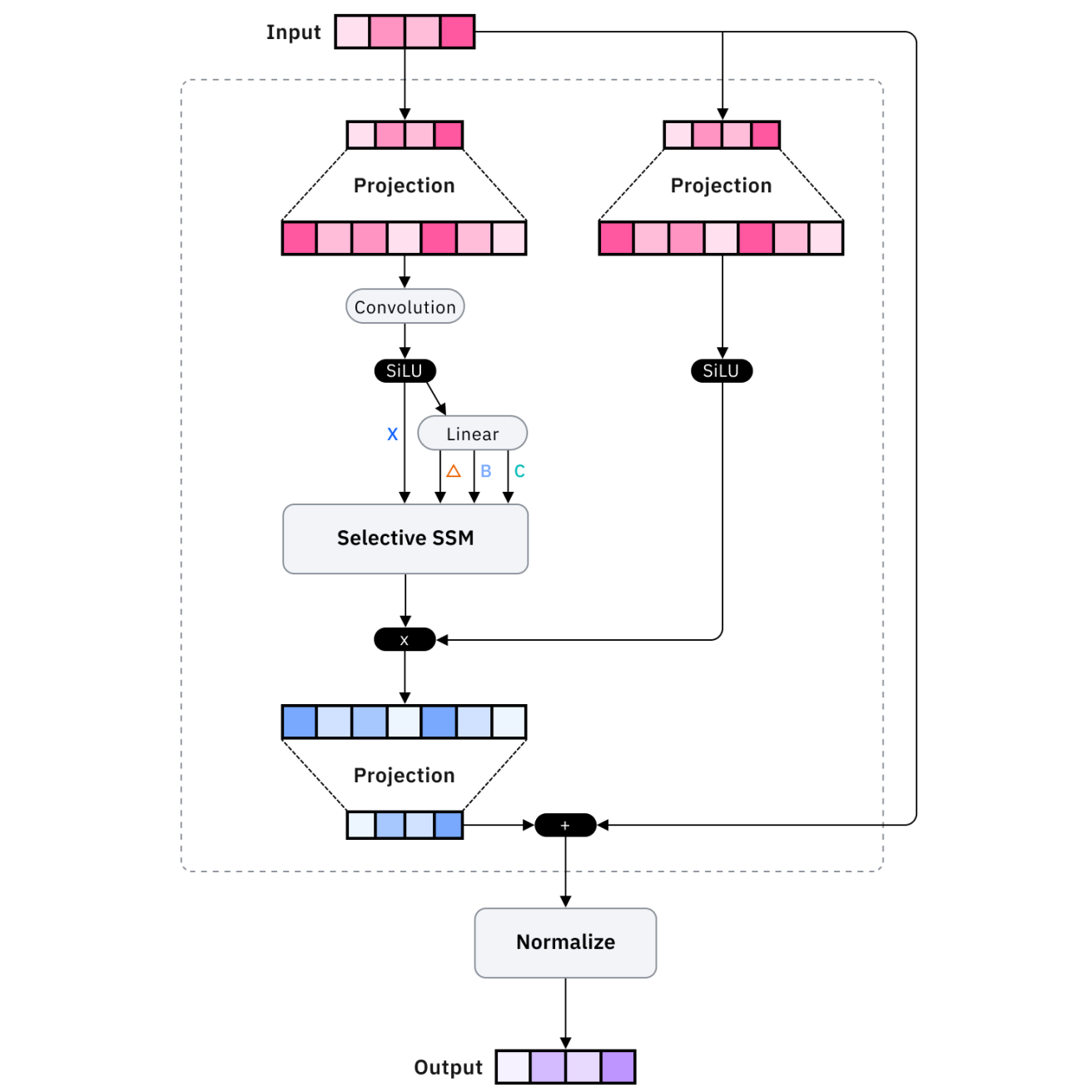
Les transformateurs à mémoire récurrente améliorent les transformateurs standard grâce à des connexions récurrentes qui maintiennent un état à long terme, permettant ainsi aux informations de persister au-delà de la fenêtre contextuelle immédiate grâce à des mécanismes de mémoire appris.
Ces innovations architecturales sont particulièrement intéressantes d'un point de vue recherche, mais qu'en est-il des solutions prêtes à être mises en production ? C'est là que les plateformes de mémoire externe entrent en jeu.
Des plateformes telles que Mem0 et Zep fournissent des solutions de mémoire externe prêtes à l'emploi. Mem0 propose une couche mémoire gérée qui extrait, stocke et récupère automatiquement les informations pertinentes. Zep se concentre sur la mémoire conversationnelle avec des fonctionnalités intégrées de synthèse, d'extraction de faits et de recherche vectorielle.
Bien que ces plateformes offrent des solutions pratiques, certains chercheurs s'inspirent d'une source inattendue : la manière dont le cerveau humain forme et gère les souvenirs.
CAMELoT (Consolidated Associative Memory Enhanced Long Transformer) applique les principes des neurosciences à la mémoire LLM, en mettant en œuvre la consolidation, la détection de nouveauté et la pondération de la récence. Ces principes reflètent les systèmes de mémoire humaine, créant ainsi un comportement mémoriel plus naturel.
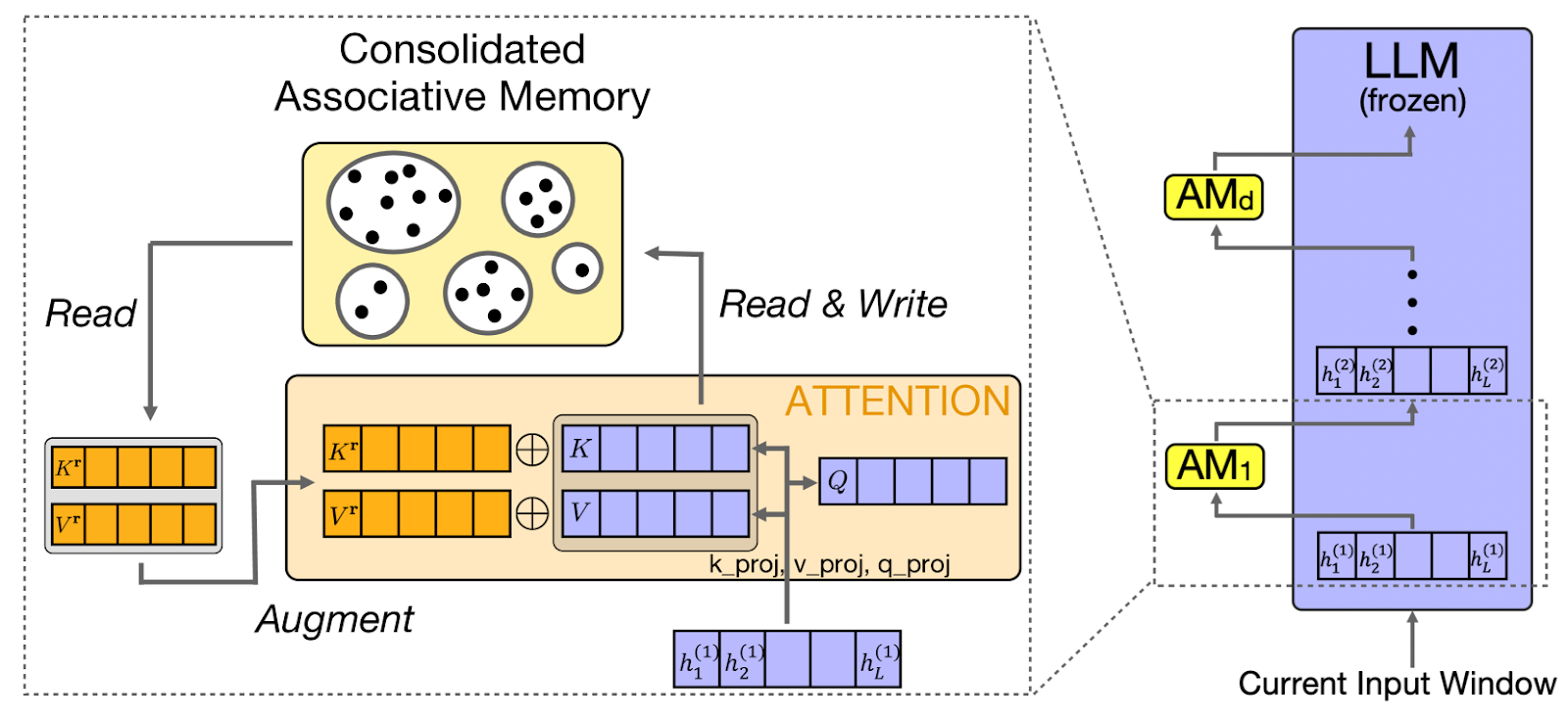
S'appuyant sur ces principes neuroscientifiques, une autre approche, telle que Laminar, se concentre spécifiquement sur la manière dont les êtres humains se souviennent d'expériences et d'événements distincts.
Larimar permet aux LLM de conserver des épisodes mémoriels distincts. Plutôt que de traiter toutes les informations passées de manière uniforme, la mémoire épisodique organise les informations en événements distincts. Cela permet une généralisation de la longueur du contexte. Le modèle fait référence à des épisodes passés spécifiques sans charger l'historique complet.
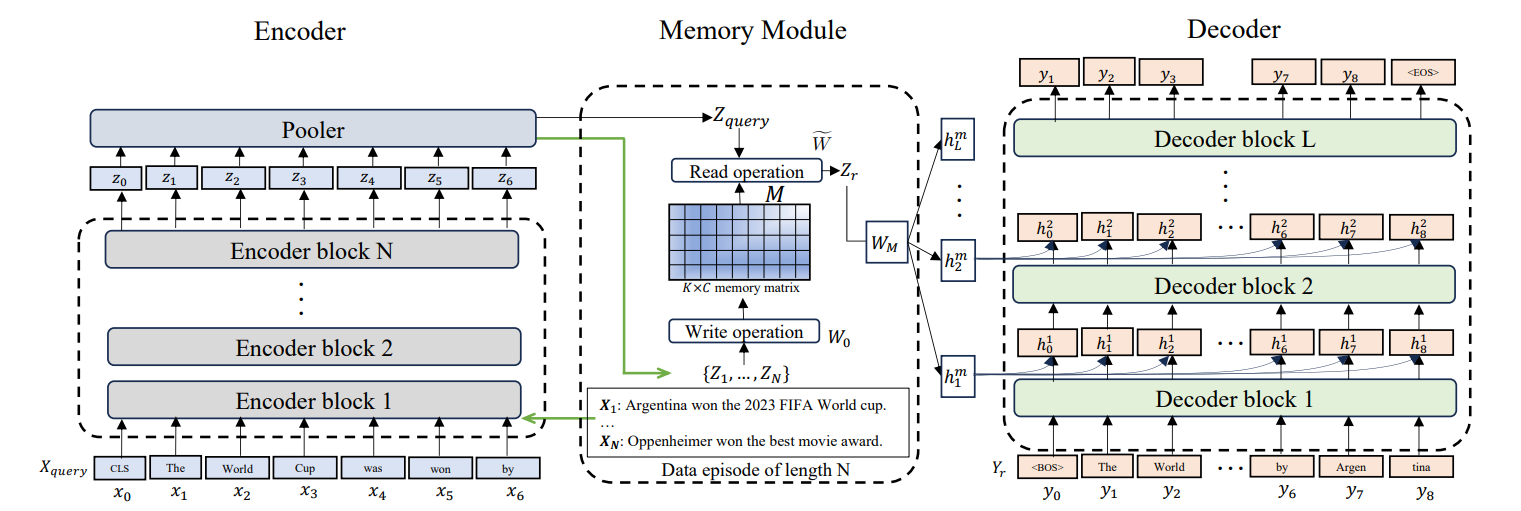
Ces architectures avancées sont extrêmement prometteuses, mais elles introduisent également de nouvelles complexités. Examinons les défis pratiques qui se posent lors de la mise en œuvre de systèmes de mémoire et les stratégies pour les surmonter.
Même avec des architectures sophistiquées, j'ai constaté que les systèmes de mémoire rencontrent des défis qui nécessitent souvent une atténuation minutieuse. Il est essentiel de comprendre ces obstacles et leurs solutions pour mettre en place des systèmes de production robustes auxquels les utilisateurs peuvent faire confiance.
L'oubli catastrophique se produit lorsque les modèles perdent des informations précédemment apprises. Les solutions comprennent la consolidation de la mémoire, le renforcement des souvenirs importants, les hiérarchies mémorielles, la préservation des informations essentielles et le rafraîchissement périodique de la mémoire.
Au-delà de l'oubli, un autre défi majeur se présente lorsque les systèmes de mémoire induisent activement le modèle en erreur. Les hallucinations (génération d'informations plausibles mais incorrectes) sont exacerbées par une mémoire défaillante. L'atténuation implique l'attribution de la source, l'évaluation du degré de confiance des souvenirs récupérés et des étapes de vérification.
Enfin, le stockage des conversations et des préférences des utilisateurs soulève d'importantes questions relatives à la confidentialité. Les considérations relatives à la confidentialité et à la sécurité sont essentielles lors du stockage des données utilisateur. Mettez en place un cryptage des données, des politiques de conservation supprimant automatiquement les anciennes données et des contrôles d'accès garantissant que les utilisateurs n'accèdent qu'à leurs propres souvenirs.
L'intégration de la mémoire nécessite une conception minutieuse de l'API. Les modèles principaux comprennent l'intégration avec état, où le système de mémoire conserve l'état entre les requêtes, et l'intégration sans état, où chaque requête comprend les identifiants nécessaires.
Une gestion efficace de la mémoire implique la suppression des messages les plus anciens ou les moins pertinents, la suppression d'éléments spécifiques et la compression des messages. Ces modèles permettent de conserver la mémoire tout en respectant le budget et en préservant le contexte essentiel.
Il est important de comprendre ces modèles théoriques et ces défis, mais le véritable défi réside dans la mise en œuvre. Traduisons ces concepts en directives pratiques que vous pouvez appliquer à vos propres projets.
Voici quelques-unes des méthodes que j'ai observées chez les développeurs pour tirer le meilleur parti des systèmes de mémoire LLM.
Une gestion efficace du contexte commence par la compréhension de votre budget en jetons. Veuillez calculer le nombre de jetons requis par votre système pour l'invite, la mémoire et la réponse, en vous assurant que le total reste dans les limites. Structurez les données de manière hiérarchique, en plaçant les informations importantes là où le modèle les prendra le mieux en compte, c'est-à-dire au début ou à la fin.
La manière dont vous préparez les données avant leur intégration dans votre système de mémoire est tout aussi importante. La préparation des données revêt une importance considérable. Divisez les documents volumineux en segments sémantiques plutôt qu'en segments arbitraires. Veuillez superposer légèrement les segments afin d'assurer la continuité du contexte. Veuillez inclure des métadonnées avec chaque segment afin de permettre une recherche filtrée.
Une fois votre système opérationnel, il est nécessaire de disposer de moyens pour évaluer son efficacité. L'évaluation de la mémoire nécessite le suivi de paramètres tels que la précision du rappel, le taux d'hallucination et la satisfaction des utilisateurs. Surveillez la latence du système de mémoire, l'utilisation des jetons et la pertinence des récupérations.
Enfin, votre stratégie de recherche doit s'adapter à la complexité des requêtes des utilisateurs. Les stratégies de recherche flexibles s'adaptent à la complexité des requêtes. Les requêtes simples utilisent la recherche par mot-clé, tandis que les questions complexes bénéficient de la recherche par similarité sémantique. Mettre en œuvre des espaces de noms mémoire pour organiser les informations par utilisateur, sujet ou période.
La mémoire des grands modèles linguistiques transforme ces modèles de générateurs de texte sans état en assistants IA sensibles au contexte, capables d'interactions cohérentes et personnalisées. Tout au long de ce tutoriel, j'ai examiné les principes fondamentaux de la mémoire LLM, des fenêtres contextuelles aux architectures avancées.
Je pense que les points clés à retenir sont les suivants : commencer par des fenêtres contextuelles et des tampons de conversation bien gérés pour les besoins immédiats, mettre en œuvre le RAG pour un accès évolutif aux connaissances au-delà de la mémoire paramétrique, exploiter les plateformes de mémoire externes pour les applications de production et évaluer en permanence l'efficacité de la mémoire à l'aide de mesures et des commentaires des utilisateurs.
À mesure que les capacités des LLM progressent, les systèmes de mémoire deviendront de plus en plus sophistiqués. Pour les praticiens, il est important de se concentrer sur la création de systèmes de mémoire qui répondent aux besoins des utilisateurs : conserver le contexte pertinent, oublier de manière appropriée et permettre des interactions naturelles qui rendent les applications d'IA véritablement utiles.
Pour continuer à approfondir vos connaissances, je vous recommande de consulter les ressources suivantes :
Meilleurs cours DataCamp
Cours
Cours
Cours