
Course
Introduction to LLMs in Python
3 hr
33.6K
Many developers build chatbots and AI assistants that can answer questions brilliantly in isolation but struggle to maintain coherent conversations. The root cause? Lack of memory. When a user asks a follow-up question referencing earlier context, stateless language models treat it as completely new, leading to frustrating, repetitive interactions.
Understanding and implementing memory in large language models is crucial for creating AI applications that feel natural and intelligent. Memory enables LLMs to maintain context across conversations, learn from past interactions, and provide personalized responses. In this tutorial, I'll walk you through LLM memory fundamentals, from basic context windows to advanced architectures.
If you are new to LLMs, I recommend taking one of our courses, such as Developing LLM Applications with LangChain, Developing Large Language Models, or LLMOps Concepts.
Large language models process information differently from traditional software. While databases store and retrieve data explicitly, LLMs must manage memory within architectural constraints like context windows and token limits. The challenge lies in making models remember relevant information while forgetting unnecessary details, maintaining coherence without overwhelming computational resources.
Before diving into implementation details, let's establish what memory means in the context of large language models and why it matters for building effective AI applications.
Memory in LLMs refers to the system's ability to retain and utilize information from previous interactions or training data. This isn't memory in the traditional computing sense. It's the model's capacity to maintain context, reference past exchanges, and apply learned patterns to new situations.
Memory is critical because it transforms isolated question-answer pairs into coherent conversations. Without memory, an LLM can't understand when you say "tell me more about that." The model needs context to interpret references and build upon prior exchanges.
I often think of LLM memory in parallel with human memory. Humans have sensory memory (immediate perception), short-term memory (active information), and long-term memory (stored knowledge). LLMs implement analogous systems: context windows act like short-term memory, retrieved information functions as recalled long-term memory, and trained parameters represent permanent knowledge.
Now that I’ve covered the fundamental concept of memory in LLMs, let's examine how memory systems are classified to help you choose the right approach for your specific application.
Understanding how memory is classified helps in choosing the right approach for your application. LLM memory can be categorized along three key dimensions: object, form, and time.
The object dimension distinguishes between personal memory and system memory. Personal memory stores user-specific information like preferences and conversation history.
System memory contains general knowledge and capabilities available to all users. A customer service bot might use system memory for product information while maintaining personal memory of each customer's order history.
Moving to the second dimension, the form dimension separates parametric from non-parametric memory. Parametric memory is encoded in the model's weights during training. Non-parametric memory exists outside the model, stored in databases or vector stores. Parametric memory is fixed after training, while non-parametric memory can be updated dynamically.
Finally, the time dimension categorizes memory by duration: short-term versus long-term. Short-term memory spans the current conversation, stored in the context window. Long-term memory persists across sessions, stored externally and retrieved when needed.
With this classification framework established, let's examine the specific types of memory that LLMs implement in practice.
Different memory types serve distinct purposes in LLM applications. Understanding these types helps you design effective memory architectures for your specific use case.
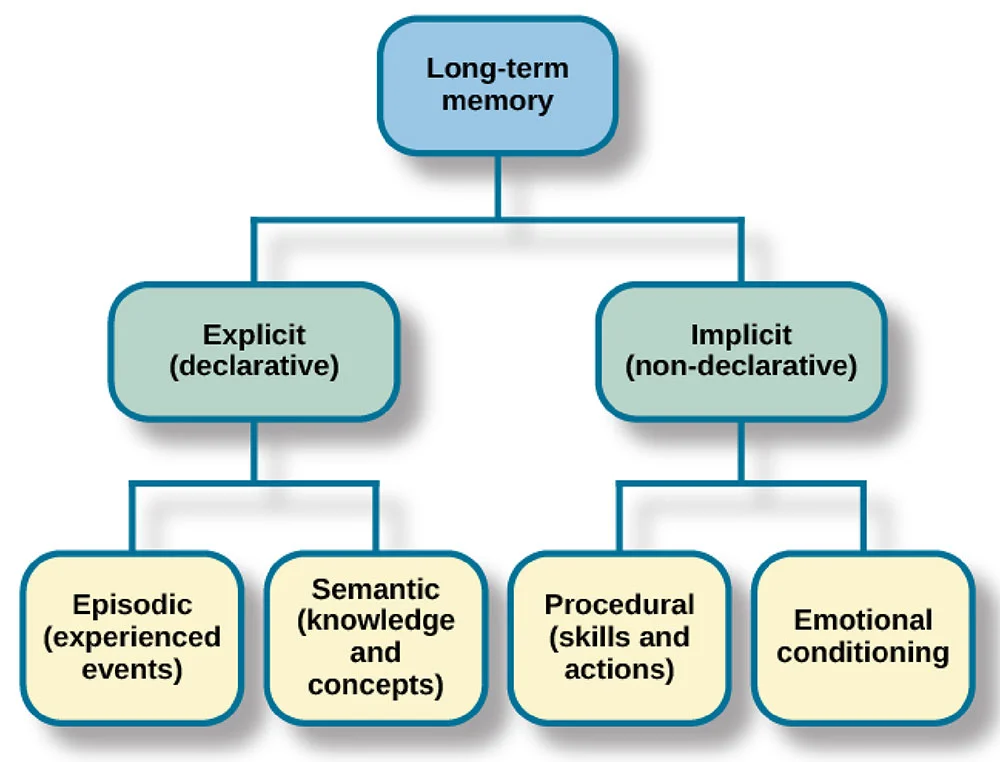
Semantic memory stores facts and general knowledge that the system can access and reference. While models have foundational knowledge from training, semantic memory in practice often refers to external knowledge bases, databases, or document stores containing factual information.
For example, a customer service bot might have semantic memory storing product specifications, pricing information, and company policies in a vector database. This allows the system to retrieve and reference accurate, up-to-date facts without relying solely on potentially outdated training data. Semantic memory is typically stored externally and retrieved when needed, making it easy to update and maintain.
While semantic memory deals with facts and knowledge, episodic memory focuses on specific experiences. Episodic memory captures past interactions, what questions were asked, how the model responded, and the context surrounding those exchanges.
Episodic memory enables the model to reference earlier parts of the conversation naturally, saying things like "as we discussed earlier" or "based on what you told me about your project." This type of memory is typically non-parametric, stored in conversation buffers or databases.
Procedural memory encompasses system instructions and learned procedures. This includes the system prompt that defines the AI's behavior, guidelines for how to respond, and task-specific instructions.
When you configure a model to "always respond in bullet points" or "prioritize accuracy over creativity," you're setting procedural memory. It shapes how the model processes and responds to information rather than what information it knows.
Beyond these fundamental memory types, practical implementations, particularly in frameworks like LangChain, offer various forms of conversational memory.
ConversationBufferMemory stores all messages in their entirety, maintaining complete conversation history, ideal for short conversations where you need full context. ConversationSummaryMemory compresses past interactions into summaries, reducing token usage while preserving key information for longer conversations. ConversationBufferWindowMemory keeps only the most recent N messages, creating a sliding window of context that works well when only recent exchanges matter. ConversationSummaryBufferMemory combines approaches, maintaining recent messages verbatim while summarizing older exchanges, offering a balance between detail and efficiency. Each form trades off between completeness and efficiency, allowing you to choose based on your application's specific needs.Understanding these memory types is essential, but they all operate within a fundamental constraint: the context window. Let's explore how this architectural limitation shapes memory implementation.
I think perhaps one of the key aspects of LLM memeory to understand is the concept of context windows, Let’s take a brief look at thow they work.
A context window is the maximum amount of text, measured in tokens, that an LLM can process in a single request. Tokens are chunks of text, roughly corresponding to words or subwords.
The context window functions as the model's immediate working memory. Everything the model considers must fit within this window: system prompt, conversation history, retrieved documents, and response space. As conversations grow, older messages must be removed for new ones.
Context window size varies dramatically. For example, GPT-5 supports 400,000 tokens, Claude 4.5 Sonnet handles 200,000 tokens, and Gemini 3 Pro extends to 1.5 million tokens. Larger windows enable richer context but increase computational costs quadratically.
While having large context windows sounds ideal, they introduce significant practical challenges that affect real-world deployment.
In my experience, the biggest issue with context windows is the "lost in the middle" problem. Research shows LLMs attend better to information at the beginning and end of the context window, with middle content receiving less attention. Simply stuffing the context with information doesn't guarantee effective use.
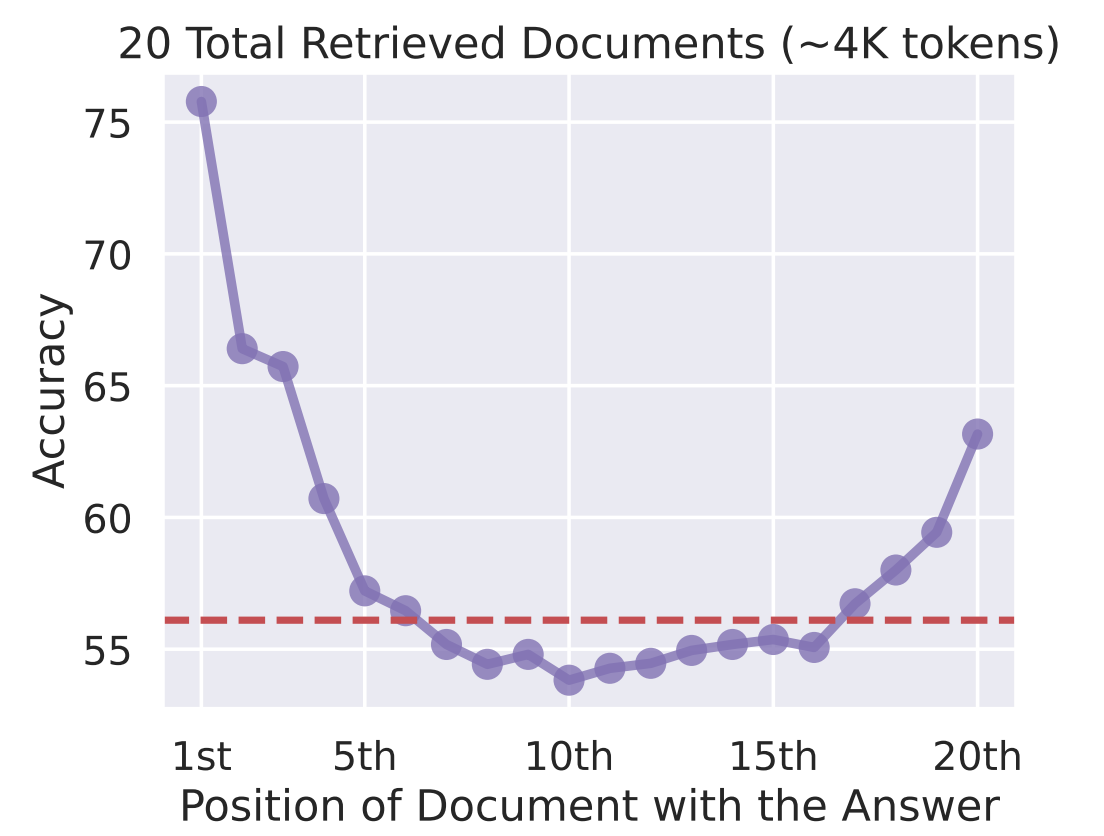
Accuracy vs. Position of Document with the Answer
Computational constraints make expanding context windows expensive. Processing a 100,000-token context requires significantly more GPU memory and time than a 10,000-token context.
For production applications, these costs compound quickly, driving the need for intelligent memory systems that selectively include only relevant information.
Given these constraints, the solution isn't simply expanding context windows, it's building smarter systems that use them efficiently.
Effective LLM applications combine context windows with memory systems that extend beyond immediate context. The pattern involves using the context window for short-term, high-priority information while storing long-term memory externally and retrieving it selectively.
A typical architecture maintains recent conversation turns in the context window, stores older conversations in a database, and uses retrieval mechanisms to bring relevant past information back when needed. This balances completeness with efficiency and performance.
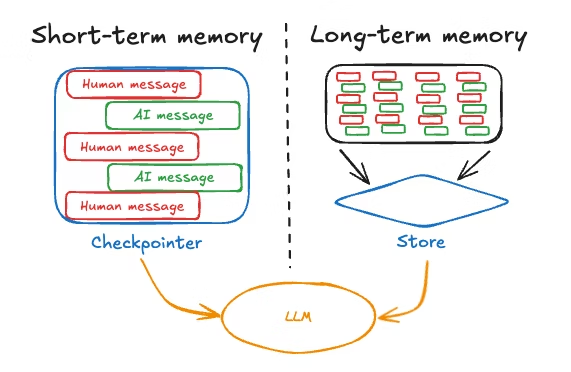
With this architectural understanding in place, let's explore how to implement effective short-term memory systems that work within these constraints
Short-term memory systems manage information within the current session, primarily leveraging the context window. I like to think of this as the model's working memory; the information it actively holds while processing the current conversation.
Let's see how to maximize this limited but crucial memory space.
In-context learning refers to the model's ability to adapt behavior based on examples or instructions in the prompt. You teach the model by showing it what to do within the context window rather than fine-tuning.
The mechanism is straightforward:
Benefits of this approach include:
Limitations include degraded effectiveness with many examples due to "lost in the middle," increased token costs, and performance rarely matching fine-tuned models.
In-context learning shows what's possible with short-term memory, but how does information actually get stored for the model to use? Let's explore the mechanisms behind memory formation.
Memory formation in LLM systems can be conscious (explicit) or subconscious (implicit).
Many frameworks automatically maintain conversation buffers, creating implicit memory without explicit operations. The challenge is managing this accumulation, ensuring relevant information persists while less important details are pruned.
Short-term memory handles immediate conversational needs, but what happens when you need information to persist beyond the current session? That's where long-term memory solutions become essential.
Long-term memory enables LLMs to maintain information across sessions.
While short-term memory is ephemeral and disappears when the conversation ends, long-term memory persists, allowing your AI to remember user preferences, past interactions, and accumulated knowledge over time.
I’ll highlight two key approaches: text-based memory systems that store information externally and key-value caching that optimizes how the model accesses previously computed information.
Text-based memory stores conversation history and user information in databases or vector stores. Acquisition involves capturing relevant information, preferences, decisions, facts, or contextual details.
Memory management requires compression and organization. Summarization techniques compress conversations into key points. Hierarchical organization structures memories by topics, time periods, or relevance.
Utilization focuses on retrieval. Vector similarity search finds relevant memories by semantic meaning. Time-based retrieval prioritizes recent information. Relevance scoring ranks memories by importance.
Text-based systems handle what to store, but there's also the question of how to make retrieval more efficient. This is where key-value caching comes in.
Key-value (KV) caching improves token generation efficiency. During text generation, the model computes attention over all previous tokens. KV caching stores these intermediate computations, allowing reuse when generating subsequent tokens without recalculation.
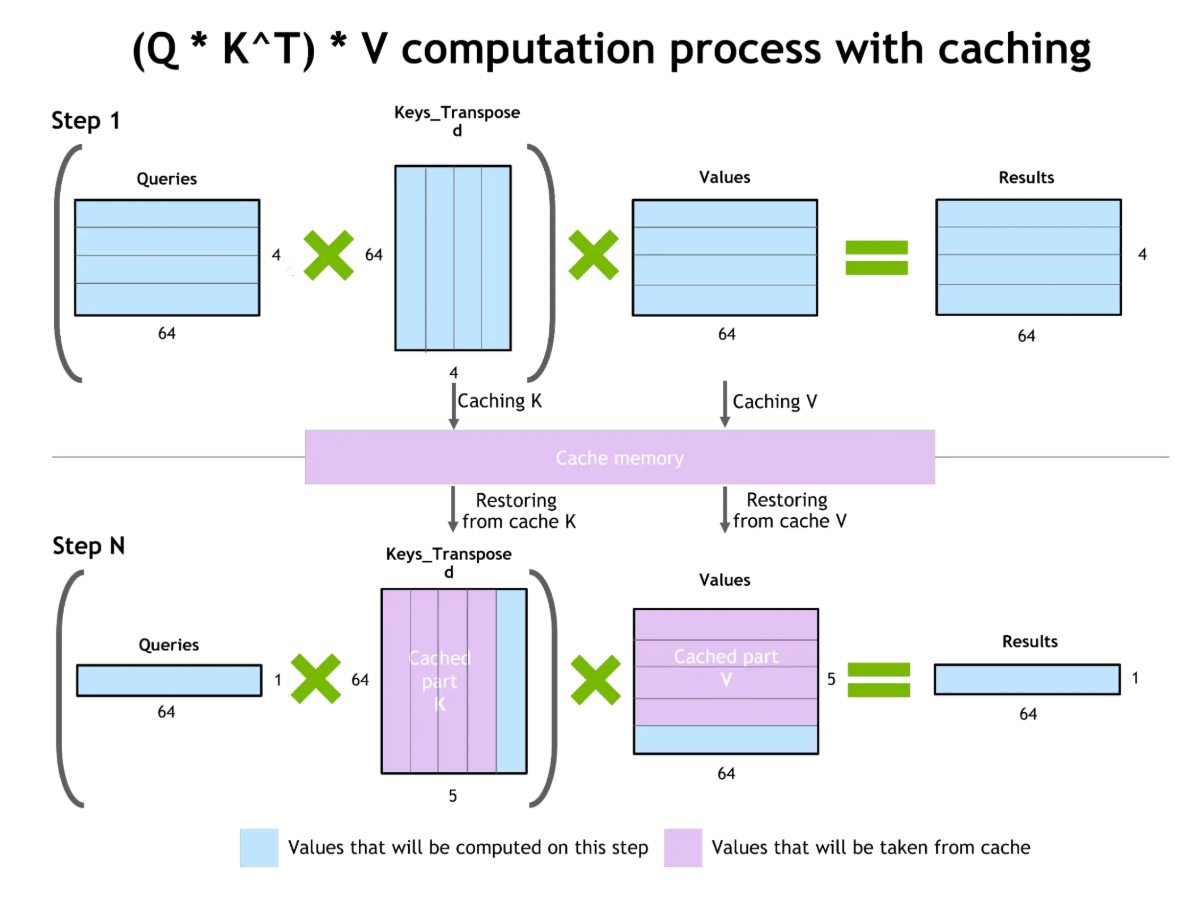
Key-value Caching and Attention Optimization
The benefit is substantial: reduced computational cost, enabling faster responses and lower resource usage. However, cached key-value pairs consume GPU VRAM. For very long contexts, KV cache size becomes a constraint.
While KV caching optimizes how models use their context windows, it doesn't solve the fundamental problem of limited memory capacity. This is where retrieval-augmented generation offers a complementary approach.
One of the recent advancements I find most interesting is Retrieval-Augmented Generation or RAG. RAG bridges internal and external memory, extending an LLM’s memory beyond the context window constraints.
Instead of relying solely on what the model learned during training or what fits in the current context, RAG dynamically pulls in relevant information from external sources exactly when needed. Let’s explore RAG in more detail.
RAG architecture consists of two main components: a retriever that searches external knowledge bases for relevant information and a generator (the LLM) that produces responses based on both the query and retrieved context.
When a query arrives, the retriever finds relevant documents from vector databases or knowledge bases. Retrieved documents are injected into the context window, providing specific information to ground the response.
Benefits of RAG include reduced hallucinations by referencing actual documents, improved accuracy by accessing up-to-date information beyond training data, and incorporating proprietary knowledge without retraining.
However, challenges include potential hallucinations when retrieved documents contain errors, relevance issues if retrieval returns unhelpful information, and the complexity of managing vector databases.
The real power of RAG becomes apparent when we consider how it addresses one of the most fundamental limitations we discussed earlier: context window constraints.
RAG extends context beyond the window size by selectively retrieving only relevant information. Rather than maintaining a complete conversation history, you store it externally and retrieve pertinent parts as needed, supporting effectively unlimited conversation length within context window constraints.
Strategies to improve context windows with RAG include hybrid retrieval combining semantic search with metadata filtering, reranking retrieved results to prioritize relevant documents, and recursive retrieval where the model's initial response guides additional retrieval.
RAG represents a practical, production-ready approach to memory extension, but the research community continues pushing boundaries with novel architectures that reimagine how models handle memory at a fundamental level.
Novel architectures and neuroscience-inspired systems are advancing LLM memory capabilities. These cutting-edge approaches reimagine how models handle long-context information, moving beyond traditional transformer limitations to create more efficient and human-like memory systems.
Architectures like Mamba and recurrent memory transformers optimize memory efficiency. Mamba uses state space models instead of attention mechanisms, achieving linear rather than quadratic scaling with sequence length, enabling processing of vastly longer sequences with comparable resources.
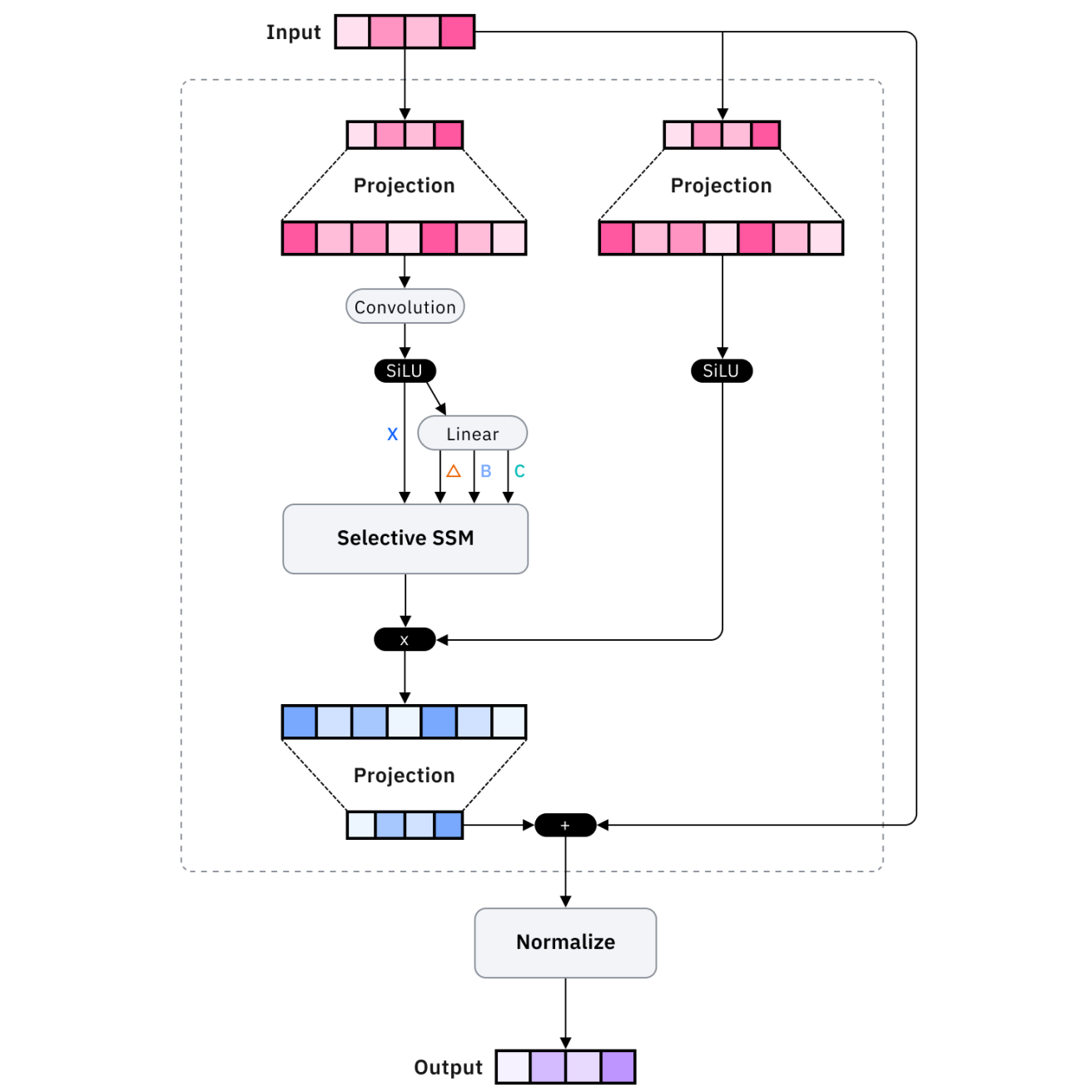
Recurrent memory transformers augment standard transformers with recurrent connections that maintain long-term state, allowing information to persist beyond the immediate context window through learned memory mechanisms.
These architectural innovations are fascinating from a research perspective, but what about production-ready solutions? That's where external memory platforms come in.
Platforms like Mem0 and Zep provide production-ready external memory solutions. Mem0 offers a managed memory layer that automatically extracts, stores, and retrieves relevant information. Zep focuses on conversational memory with built-in summarization, fact extraction, and vector search.
While these platforms offer practical solutions, some researchers are taking inspiration from an unexpected source: how human brains actually form and manage memories.
CAMELoT (Consolidated Associative Memory Enhanced Long Transformer) applies neuroscience principles to LLM memory, implementing consolidation, novelty detection, and recency weighting. These principles mirror human memory systems, creating more natural memory behavior.
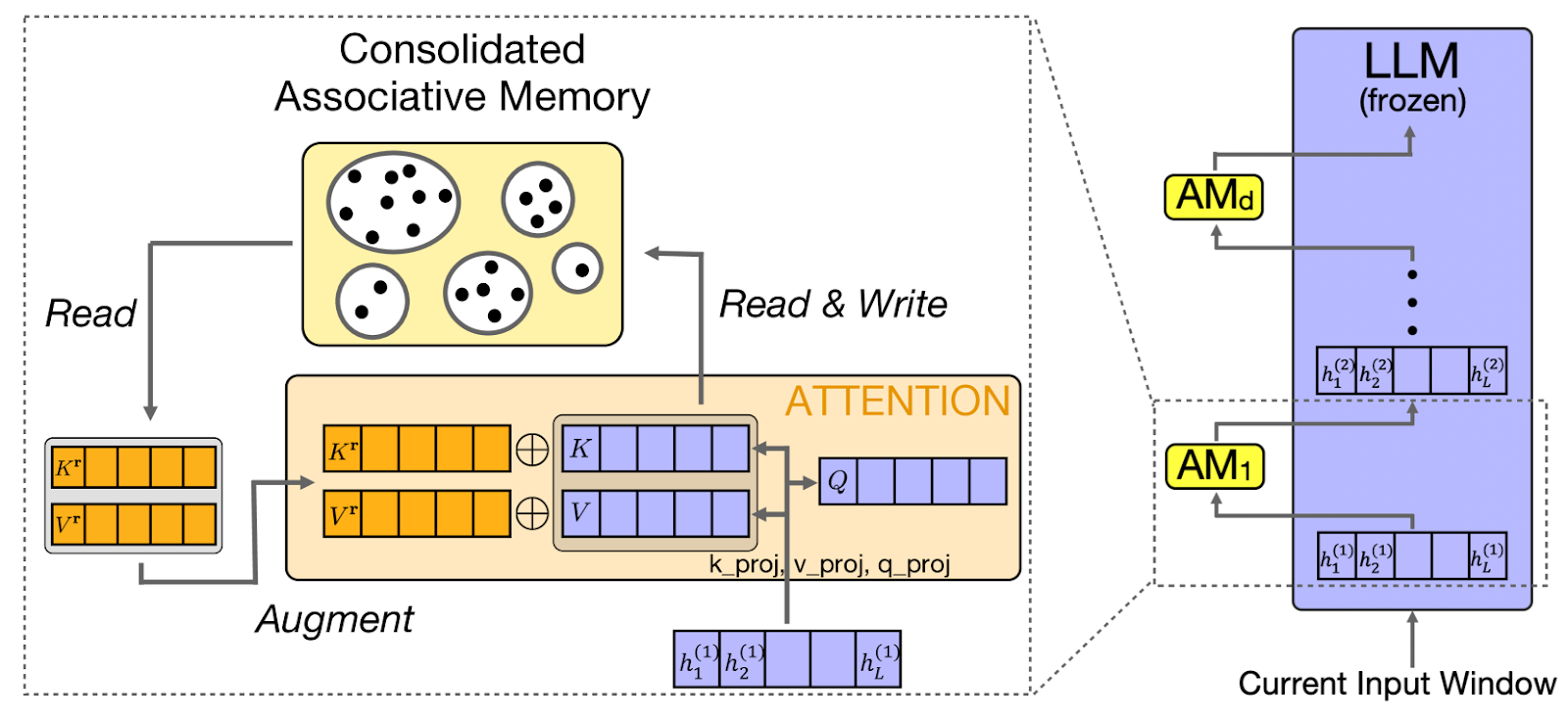
Building on these neuroscience principles, another approach, like Laminar, focuses specifically on how humans remember distinct experiences and events.
Larimar enables LLMs to maintain distinct memory episodes. Rather than treating all past information uniformly, episodic memory structures information into discrete events. This enables context length generalization. The model references specific past episodes without loading the complete history.
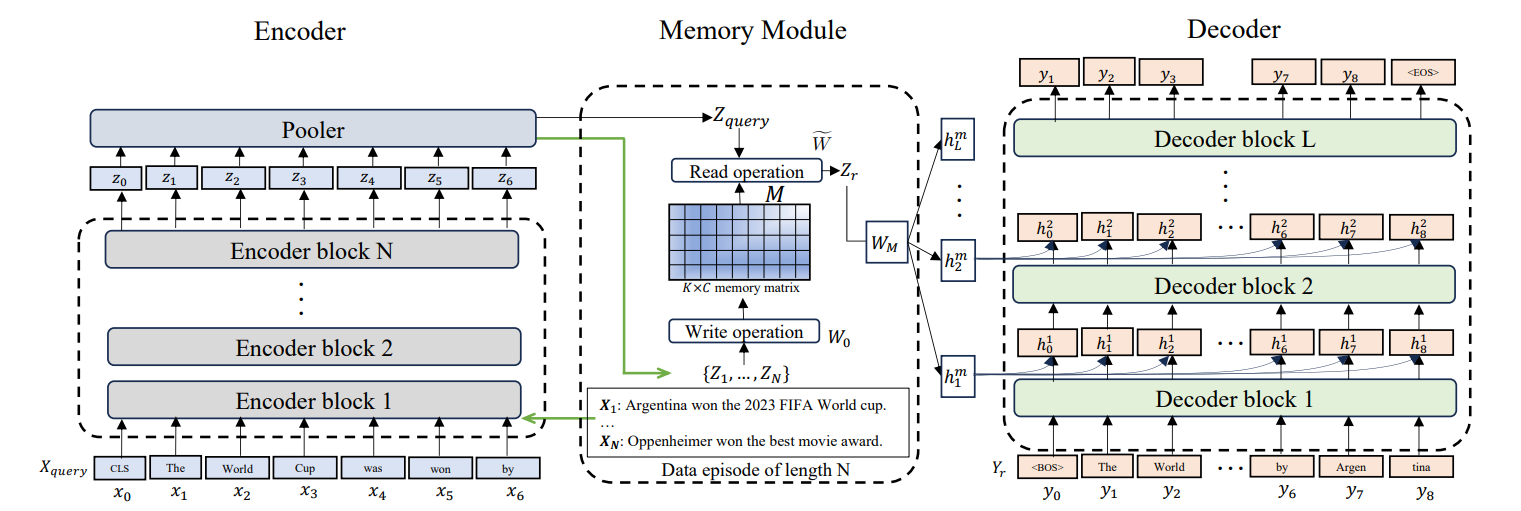
These advanced architectures show tremendous promise, but they also introduce new complexities. Let's examine the practical challenges that arise when implementing memory systems and strategies for overcoming them.
Even with sophisticated architectures, I’ve found that memory systems face challenges that often require careful mitigation. Understanding these obstacles and their solutions is crucial for building robust production systems that users can trust.
Catastrophic forgetting occurs when models lose previously learned information. Solutions include memory consolidation, strengthening important memories, memory hierarchies, preserving critical information, and periodic memory refresh.
Beyond forgetting, another critical challenge is when memory systems actively mislead the model. Hallucination (generating plausible but incorrect information) is exacerbated by faulty memory. Mitigation involves source attribution, confidence scoring for retrieved memories, and verification steps.
Finally, storing user conversations and preferences raises important privacy questions. Privacy and security considerations are critical when storing user data. Implement data encryption, retention policies automatically purging old data, and access controls ensuring users only access their own memories.
Integrating memory requires thoughtful API design. Core patterns include stateful integration, where the memory system maintains state across requests, and stateless integration, where each request includes necessary identifiers.
Efficient memory management employs trimming (removing the oldest or least relevant messages), deletion (removing specific items), and summarization (compressing messages). These patterns maintain memory within budget while preserving essential context.
Understanding these theoretical patterns and challenges is valuable, but the real test comes in implementation. Let's translate these concepts into practical guidelines you can apply to your own projects.
Here are some of the ways I've seen developers get the most out of LLM memory systems.
Effective context management starts with understanding your token budget. Calculate how many tokens your system prompt, memory, and response require, ensuring the sum stays within limits. Structure data hierarchically, placing important information where the model attends best—at the beginning or end.
Equally important is how you prepare the data before it enters your memory system. Data preparation matters significantly. Break large documents into semantic chunks rather than arbitrary token limits. Overlap chunks slightly for context continuity. Include metadata with each chunk to enable filtered retrieval.
Once your system is running, you need ways to measure whether it's actually working. Memory evaluation requires tracking metrics like recall accuracy, hallucination rate, and user satisfaction. Monitor memory system latency, token usage, and retrieval relevance.
Finally, your retrieval strategy should adapt to the complexity of what users ask. Flexible retrieval strategies adapt to query complexity. Simple queries use keyword search, while complex questions benefit from semantic similarity search. Implement memory namespaces to organize information by user, topic, or time period.
Large language model memory transforms these models from stateless text generators into context-aware AI assistants capable of coherent, personalized interactions. Throughout this tutorial, I’ve explored LLM memory fundamentals, from context windows to advanced architectures.
I think the key takeaways are to start with well-managed context windows and conversation buffers for immediate needs, implement RAG for scalable knowledge access beyond parametric memory, leverage external memory platforms for production applications, and continuously evaluate memory effectiveness through metrics and user feedback.
As LLM capabilities advance, memory systems will become increasingly sophisticated. For practitioners, focus on building memory systems that serve user needs: maintaining relevant context, forgetting appropriately, and enabling natural interactions that make AI applications genuinely useful.
To keep learning, I recommend checking out the following resources:
Top DataCamp Courses
Course
Course
Course
blog
Javier Canales Luna
12 min
blog
Tim Lu
15 min
blog
Amberle McKee
8 min
blog
Arun Nanda
14 min
blog
Bhavishya Pandit
8 min
blog
Dr Ana Rojo-Echeburúa
8 min
