
Curso
Introducción a los LLMs en Python
3 h
33.6K
Muchos programadores crean chatbots y asistentes de IA que pueden responder preguntas de forma brillante de manera aislada, pero que tienen dificultades para mantener conversaciones coherentes. ¿La causa principal? Falta de memoria. Cuando un usuario hace una pregunta de seguimiento que hace referencia al contexto anterior, los modelos de lenguaje sin estado la tratan como si fuera completamente nueva, lo que da lugar a interacciones frustrantes y repetitivas.
Comprender e implementar la memoria en modelos lingüísticos de gran tamaño es fundamental para crear aplicaciones de IA que resulten naturales e inteligentes. La memoria permite a los LLM mantener el contexto a lo largo de las conversaciones, aprender de interacciones pasadas y proporcionar respuestas personalizadas. En este tutorial, te guiaré a través de los fundamentos de la memoria LLM, desde las ventanas de contexto básicas hasta las arquitecturas avanzadas.
Si eres nuevo en el mundo de los LLM, te recomiendo que realices uno de nuestros cursos, como Desarrollo de aplicaciones LLM con LangChain, Desarrollo de modelos de lenguaje grandeso Conceptos de LLMOps.
Los modelos lingüísticos de gran tamaño procesan la información de forma diferente al software tradicional. Mientras que las bases de datos almacenan y recuperan datos de forma explícita, los LLM deben gestionar la memoria dentro de las limitaciones arquitectónicas, como las ventanas de contexto y los límites de tokens. El reto consiste en hacer que los modelos recuerden la información relevante y olviden los detalles innecesarios, manteniendo la coherencia sin sobrecargar los recursos computacionales.
Antes de entrar en detalles sobre la implementación, establezcamos qué significa la memoria en el contexto de los modelos de lenguaje grandes y por qué es importante para crear aplicaciones de IA eficaces.
La memoria en los LLM se refiere a la capacidad del sistema para retener y utilizar información de interacciones previas o datos de entrenamiento. No se trata de memoria en el sentido informático tradicional. Es la capacidad del modelo para mantener el contexto, hacer referencia a intercambios anteriores y aplicar patrones aprendidos a situaciones nuevas.
La memoria es fundamental porque transforma pares aislados de preguntas y respuestas en conversaciones coherentes. Sin memoria, un LLM no puede entender cuando dices «cuéntame más sobre eso». El modelo necesita contexto para interpretar referencias y basarse en intercambios previos.
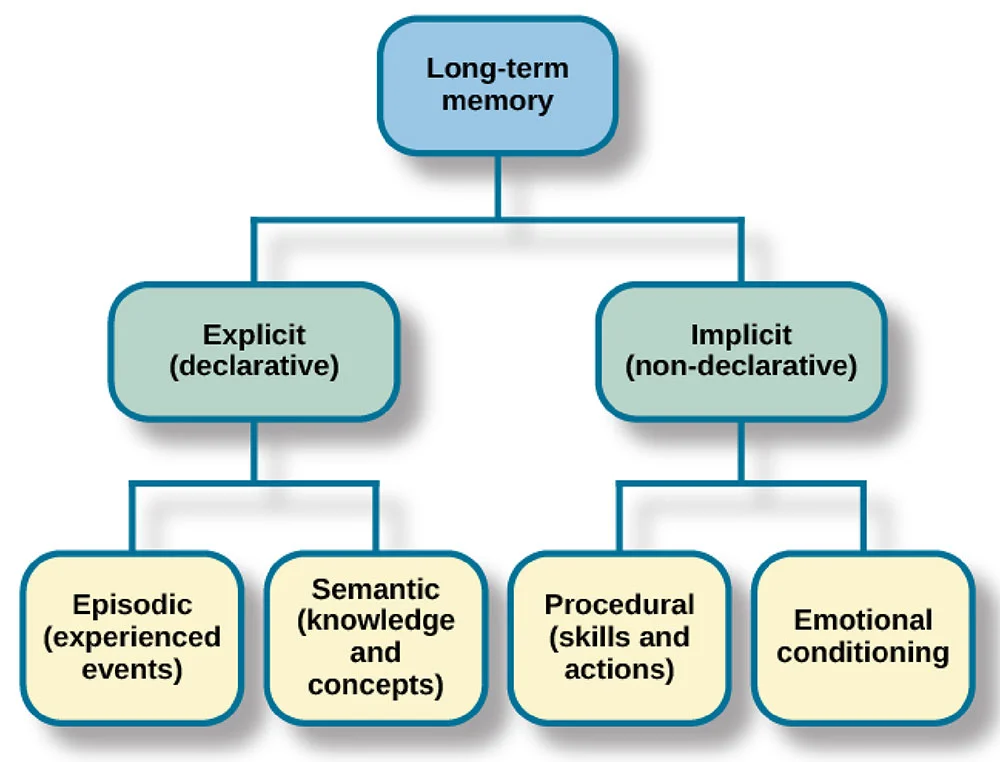
A menudo pienso en la memoria LLM en paralelo con la memoria humana. Los seres humanos tienen memoria sensorial (percepción inmediata), memoria a corto plazo (información activa) y memoria a largo plazo (conocimiento almacenado). Los LLM implementan sistemas análogos: las ventanas de contexto actúan como memoria a corto plazo, la información recuperada funciona como memoria a largo plazo y los parámetros entrenados representan el conocimiento permanente.
Ahora que ya he explicado el concepto fundamental de la memoria en los LLM, veamos cómo se clasifican los sistemas de memoria para ayudarte a elegir el enfoque adecuado para tu aplicación específica.
Comprender cómo se clasifica la memoria ayuda a elegir el enfoque adecuado para tu aplicación. La memoria LLM se puede clasificar en tres dimensiones clave: objeto, forma y tiempo.
La dimensión del objeto distingue entre memoria personal y memoria del sistema. La memoria personal almacena información específica del usuario, como tus preferencias y el historial de conversaciones.
La memoria del sistema contiene conocimientos generales y capacidades disponibles para todos los usuarios. Un bot de atención al cliente puede utilizar la memoria del sistema para almacenar información sobre los productos, al tiempo que mantiene una memoria personal con el historial de pedidos de cada cliente.
Pasando a la segunda dimensión, la dimensión de la forma separa la memoria paramétrica de la no paramétrica. La memoria paramétrica está codificada en los ponderaciones del modelo durante el entrenamiento. La memoria no paramétrica existe fuera del modelo, almacenada en bases de datos o almacenes de vectores. La memoria paramétrica se fija después del entrenamiento, mientras que la memoria no paramétrica se puede actualizar dinámicamente.
Por último, la dimensión temporal clasifica la memoria según su duración: a corto plazo frente a largo plazo. La memoria a corto plazo abarca la conversación actual, almacenada en la ventana de contexto. La memoria a largo plazo persiste entre sesiones, se almacena externamente y se recupera cuando es necesario.
Una vez establecido este marco de clasificación, examinemos los tipos específicos de memoria que los LLM implementan en la práctica.
Los diferentes tipos de memoria tienen fines distintos en las aplicaciones LLM. Comprender estos tipos te ayuda a diseñar arquitecturas de memoria eficaces para tu caso de uso específico.
La memoria semántica almacena datos y conocimientos generales a los que el sistema puede acceder y consultar. Si bien los modelos cuentan con conocimientos básicos adquiridos durante el entrenamiento, la memoria semántica en la práctica suele hacer referencia a bases de conocimiento externas, bases de datos o almacenes de documentos que contienen información factual.
Por ejemplo, un bot de atención al cliente puede tener una memoria semántica que almacene las especificaciones de los productos, la información sobre precios y las políticas de la empresa en una base de datos vectorial. Esto permite al sistema recuperar y consultar datos precisos y actualizados sin depender únicamente de datos de entrenamiento que pueden estar desactualizados. La memoria semántica suele almacenarse externamente y recuperarse cuando es necesario, lo que facilita su actualización y mantenimiento.
Mientras que la memoria semántica se ocupa de los hechos y el conocimiento, la memoria episódica se centra en experiencias específicas. La memoria episódica captura las interacciones pasadas, las preguntas que se hicieron, cómo respondió el modelo y el contexto que rodeó esos intercambios.
La memoria episódica permite al modelo hacer referencia a partes anteriores de la conversación de forma natural, diciendo cosas como «como hemos comentado anteriormente» o «basándome en lo que me has contado sobre tu proyecto». Este tipo de memoria suele ser no paramétrica y se almacena en búferes de conversación o bases de datos.
La memoria procedimental abarca las instrucciones del sistema y los procedimientos aprendidos. Esto incluye el mensaje del sistema que define el comportamiento de la IA, las pautas sobre cómo responder y las instrucciones específicas para cada tarea.
Cuando configuras un modelo para que «siempre responda con viñetas» o «priorice la precisión sobre la creatividad», estás estableciendo una memoria procedimental. Determina cómo el modelo procesa y responde a la información, más que qué información conoce.
Más allá de estos tipos de memoria fundamentales, las implementaciones prácticas, especialmente en marcos como LangChain, ofrecen diversas formas de memoria conversacional.
ConversationBufferMemory Almacena todos los mensajes en su totalidad, conservando el historial completo de la conversación, lo que resulta ideal para conversaciones breves en las que necesitas disponer de todo el contexto. ConversationSummaryMemory Comprime las interacciones anteriores en resúmenes, lo que reduce el uso de tokens y conserva la información clave de las conversaciones más largas. ConversationBufferWindowMemory guarda solo los N mensajes más recientes, creando una ventana deslizante de contexto que funciona bien cuando solo importan los intercambios recientes. ConversationSummaryBufferMemory combina enfoques, manteniendo los mensajes recientes textualmente y resumiendo los intercambios más antiguos, lo que ofrece un equilibrio entre el detalle y la eficiencia. Cada formulario ofrece una combinación de exhaustividad y eficiencia, lo que te permite elegir en función de las necesidades específicas de tu aplicación.Es fundamental comprender estos tipos de memoria, pero todos ellos funcionan dentro de una restricción fundamental: la ventana de contexto. Exploremos cómo esta limitación arquitectónica da forma a la implementación de la memoria.
Creo que quizás uno de los aspectos clave de la memoria LLM que hay que comprender es el concepto de ventanas de contexto. Veamos brevemente cómo funcionan.
Una ventana de contexto es la cantidad máxima de texto, medida en tokens, que un LLM puede procesar en una sola solicitud. Los tokens son fragmentos de texto que se corresponden aproximadamente con palabras o subpalabras.
La ventana de contexto funciona como la memoria de trabajo inmediata del modelo. Todo lo que el modelo tiene en cuenta debe encajar en esta ventana: indicaciones del sistema, historial de conversaciones, documentos recuperados y espacio de respuesta. A medida que las conversaciones crecen, los mensajes antiguos deben eliminarse para dar cabida a los nuevos.
El tamaño de la ventana contextual varía considerablemente. Por ejemplo, GPT-5 admite 400 000 tokens, Claude 4.5 Sonnet maneja 200 000 tokens y Gemini 3 Pro llega hasta 1,5 millones de tokens. Las ventanas más grandes permiten un contexto más rico, pero aumentan los costes computacionales de forma cuadrática.
Aunque disponer de ventanas de contexto grandes parece ideal, estas plantean importantes retos prácticos que afectan a su implementación en el mundo real.
Según mi experiencia, el mayor problema de las ventanas contextuales es que «se pierden en medio». Las investigaciones demuestran que los LLM prestan más atención a la información al principio y al final de la ventana de contexto, mientras que el contenido intermedio recibe menos atención. El simple hecho de llenar el contexto con información no garantiza un uso eficaz.
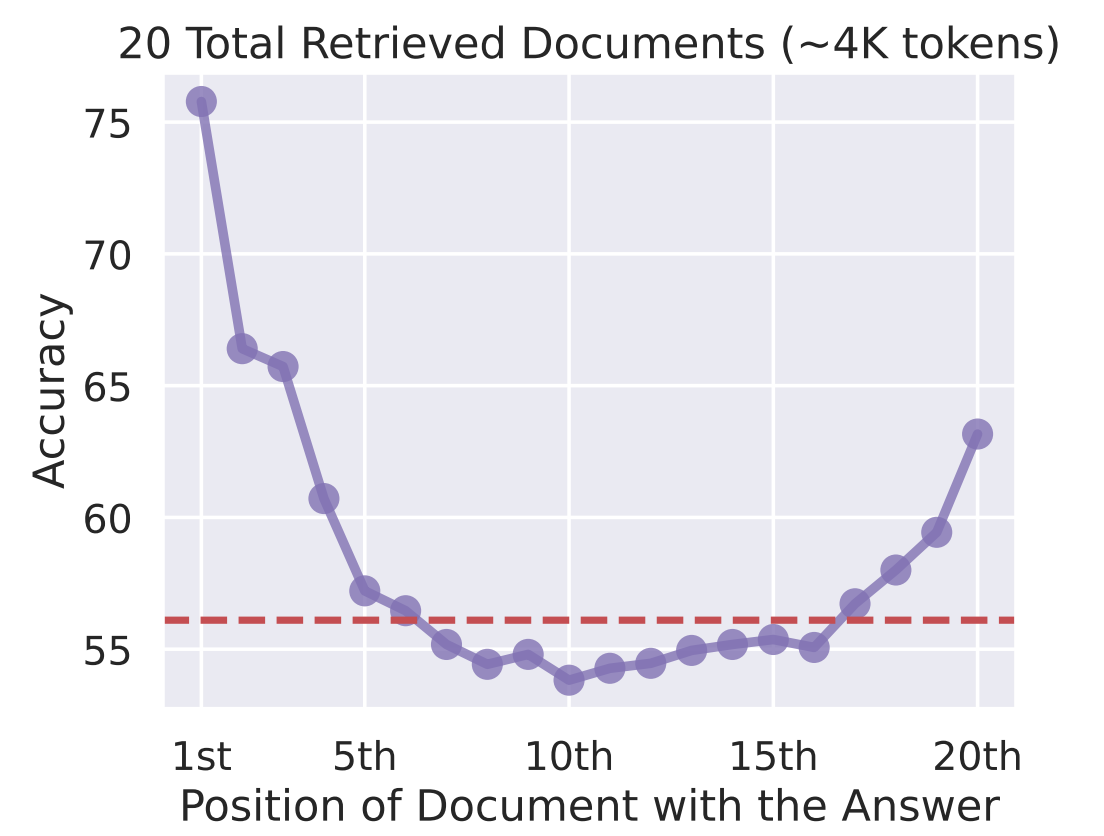
Precisión frente a Posición del documento con la respuesta
Las limitaciones computacionales hacen que ampliar las ventanas de contexto resulte costoso. El procesamiento de un contexto de 100 000 tokens requiere mucha más memoria GPU y tiempo que un contexto de 10 000 tokens.
En las aplicaciones de producción, estos costes se acumulan rápidamente, lo que hace necesario contar con sistemas de memoria inteligentes que incluyan de forma selectiva solo la información relevante.
Dadas estas limitaciones, la solución no consiste simplemente en ampliar las ventanas de contexto, sino en crear sistemas más inteligentes que las utilicen de manera eficiente.
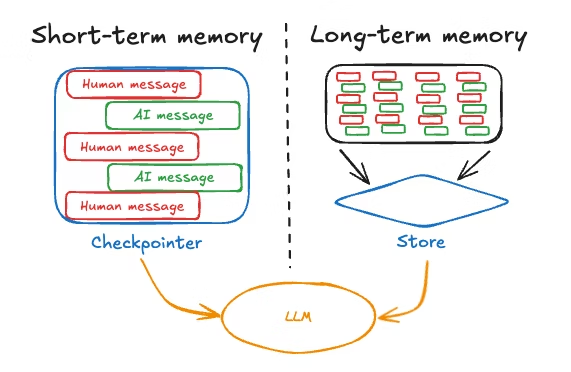
Las aplicaciones LLM eficaces combinan ventanas contextuales con sistemas de memoria que van más allá del contexto inmediato. El patrón consiste en utilizar la ventana de contexto para la información de alta prioridad y corto plazo, mientras que la memoria a largo plazo se almacena externamente y se recupera de forma selectiva.
Una arquitectura típica mantiene las conversaciones recientes en la ventana de contexto, almacena las conversaciones más antiguas en una base de datos y utiliza mecanismos de recuperación para recuperar información relevante del pasado cuando es necesario. Esto equilibra la exhaustividad con la eficiencia y el rendimiento.
Con estos conocimientos arquitectónicos, exploremos cómo implementar sistemas de memoria a corto plazo eficaces que funcionen dentro de estas limitaciones.
Los sistemas de memoria a corto plazo gestionan la información dentro de la sesión actual, aprovechando principalmente la ventana de contexto. Me gusta pensar en esto como la memoria de trabajo del modelo; la información que retiene activamente mientras procesa la conversación actual.
Veamos cómo maximizar este espacio de memoria limitado pero crucial.
El aprendizaje en contexto se refiere a la capacidad del modelo para adaptar su comportamiento basándose en ejemplos o instrucciones del mensaje. Enseñas al modelo mostrándole qué hacer dentro de la ventana de contexto en lugar de realizar ajustes precisos.
El mecanismo es sencillo:
Las ventajas de este enfoque incluyen:
Las limitaciones incluyen una eficacia reducida en muchos casos debido a la «pérdida en el medio», el aumento de los costes simbólicos y un rendimiento que rara vez iguala al de los modelos ajustados con precisión.
El aprendizaje en contexto muestra lo que es posible con la memoria a corto plazo, pero ¿cómo se almacena realmente la información para que el modelo la utilice? Exploremos los mecanismos que subyacen a la formación de la memoria.
La formación de la memoria en los sistemas LLM puede ser consciente (explícita) o subconsciente (implícita).
Muchos marcos mantienen automáticamente búferes de conversación, creando memoria implícita sin operaciones explícitas. El reto consiste en gestionar esta acumulación, asegurándote de que la información relevante se conserve y se eliminen los detalles menos importantes.
La memoria a corto plazo se encarga de las necesidades conversacionales inmediatas, pero ¿qué ocurre cuando necesitas que la información persista más allá de la sesión actual? Ahí es donde las soluciones de memoria a largo plazo se vuelven esenciales.
La memoria a largo plazo permite a los LLM conservar la información entre sesiones.
Mientras que la memoria a corto plazo es efímera y desaparece cuando termina la conversación, la memoria a largo plazo persiste, lo que permite a tu IA recordar las preferencias de los usuarios, las interacciones pasadas y los conocimientos acumulados a lo largo del tiempo.
Destacaré dos enfoques clave: los sistemas de memoria basados en texto que almacenan información externamente y el almacenamiento en caché de claves-valores que optimiza la forma en que el modelo accede a la información calculada previamente.
La memoria basada en texto almacena el historial de conversaciones y la información del usuario en bases de datos o almacenes vectoriales. La adquisición implica recopilar información relevante, preferencias, decisiones, hechos o detalles contextuales.
La gestión de la memoria requiere compresión y organización. Las técnicas de resumen comprimen las conversaciones en puntos clave. La organización jerárquica estructura los recuerdos por temas, períodos de tiempo o relevancia.
La utilización se centra en la recuperación. La búsqueda por similitud vectorial encuentra recuerdos relevantes según su significado semántico. La recuperación basada en el tiempo da prioridad a la información reciente. La puntuación de relevancia clasifica los recuerdos por importancia.
Los sistemas basados en texto se encargan de lo que se almacena, pero también se plantea la cuestión de cómo hacer que la recuperación sea más eficiente. Aquí es donde entra en juego el almacenamiento en caché de clave-valor.
El almacenamiento en caché de clave-valor (KV) mejora la eficiencia de la generación de tokens. Durante la generación de texto, el modelo calcula la atención sobre todos los tokens anteriores. El almacenamiento en caché de KV almacena estos cálculos intermedios, lo que permite reutilizarlos al generar tokens posteriores sin necesidad de volver a realizar los cálculos.
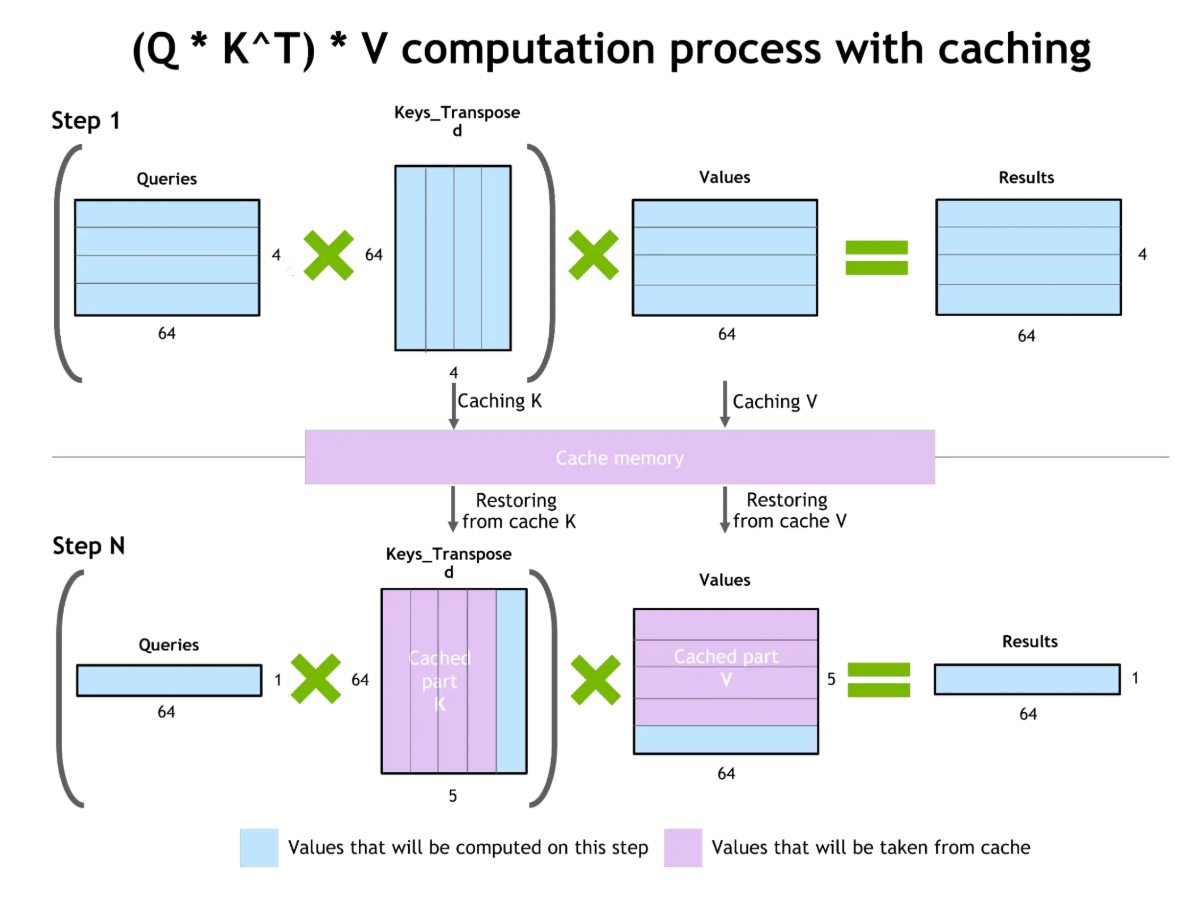
Almacenamiento en caché de valores clave y optimización de la atención
La ventaja es considerable: reducción del coste computacional, lo que permite respuestas más rápidas y un menor uso de recursos. Sin embargo, los pares clave-valor almacenados en caché consumen VRAM de la GPU. En contextos muy largos, el tamaño de la caché KV se convierte en una limitación.
Aunque el almacenamiento en caché KV optimiza la forma en que los modelos utilizan sus ventanas de contexto, no resuelve el problema fundamental de la capacidad limitada de la memoria. Aquí es donde la generación aumentada por recuperación ofrece un enfoque complementario.
Uno de los avances recientes que me parece más interesante es la generación aumentada por recuperación o RAG. RAG conecta la memoria interna y externa, ampliando la memoria de un LLM más allá de las limitaciones de la ventana de contexto.
En lugar de basarse únicamente en lo que el modelo ha aprendido durante el entrenamiento o en lo que se ajusta al contexto actual, RAG extrae dinámicamente información relevante de fuentes externas exactamente cuando es necesario. Exploremos RAG con más detalle.
La arquitectura RAG consta de dos componentes principales: un recuperador que busca información relevante en bases de conocimiento externas y un generador (el LLM) que produce respuestas basadas tanto en la consulta como en el contexto recuperado.
Cuando llega una consulta, el recuperador encuentra documentos relevantes en bases de datos vectoriales o bases de conocimiento. Los documentos recuperados se insertan en la ventana de contexto, proporcionando información específica para fundamentar la respuesta.
Entre las ventajas del RAG se incluyen la reducción de alucinaciones al hacer referencia a documentos reales, una mayor precisión al acceder a información actualizada más allá de los datos de entrenamiento y la incorporación de conocimientos propios sin necesidad de volver a entrenar.
Sin embargo, entre los retos se incluyen posibles alucinaciones cuando los documentos recuperados contienen errores, problemas de relevancia si la recuperación devuelve información inútil y la complejidad de gestionar bases de datos vectoriales.
El verdadero poder de RAG se hace evidente cuando consideramos cómo aborda una de las limitaciones más fundamentales que hemos comentado anteriormente: las restricciones de la ventana de contexto.
RAG amplía el contexto más allá del tamaño de la ventana recuperando selectivamente solo la información relevante. En lugar de mantener un historial completo de conversaciones, lo almacenas externamente y recuperas las partes pertinentes según sea necesario, lo que permite una duración ilimitada de las conversaciones dentro de las restricciones de la ventana de contexto.
Las estrategias para mejorar las ventanas contextuales con RAG incluyen la recuperación híbrida, que combina la búsqueda semántica con el filtrado de metadatos; la reclasificación de los resultados recuperados para dar prioridad a los documentos relevantes, y la recuperación recursiva, en la que la respuesta inicial del modelo guía la recuperación adicional.
RAG representa un enfoque práctico y listo para la producción en lo que respecta a la ampliación de la memoria, pero la comunidad investigadora sigue ampliando los límites con arquitecturas novedosas que replantean la forma en que los modelos gestionan la memoria a un nivel fundamental.
Las nuevas arquitecturas y los sistemas inspirados en la neurociencia están mejorando las capacidades de memoria de los LLM. Estos enfoques innovadores reinventan la forma en que los modelos manejan la información de contexto largo, superando las limitaciones tradicionales de los transformadores para crear sistemas de memoria más eficientes y similares a los humanos.
Arquitecturas como Mamba y los transformadores de memoria recurrente optimizan la eficiencia de la memoria. Mamba utiliza modelos de espacio de estado en lugar de mecanismos de atención, lo que permite un escalado lineal en lugar de cuadrático con la longitud de la secuencia, lo que permite procesar secuencias mucho más largas con recursos comparables.
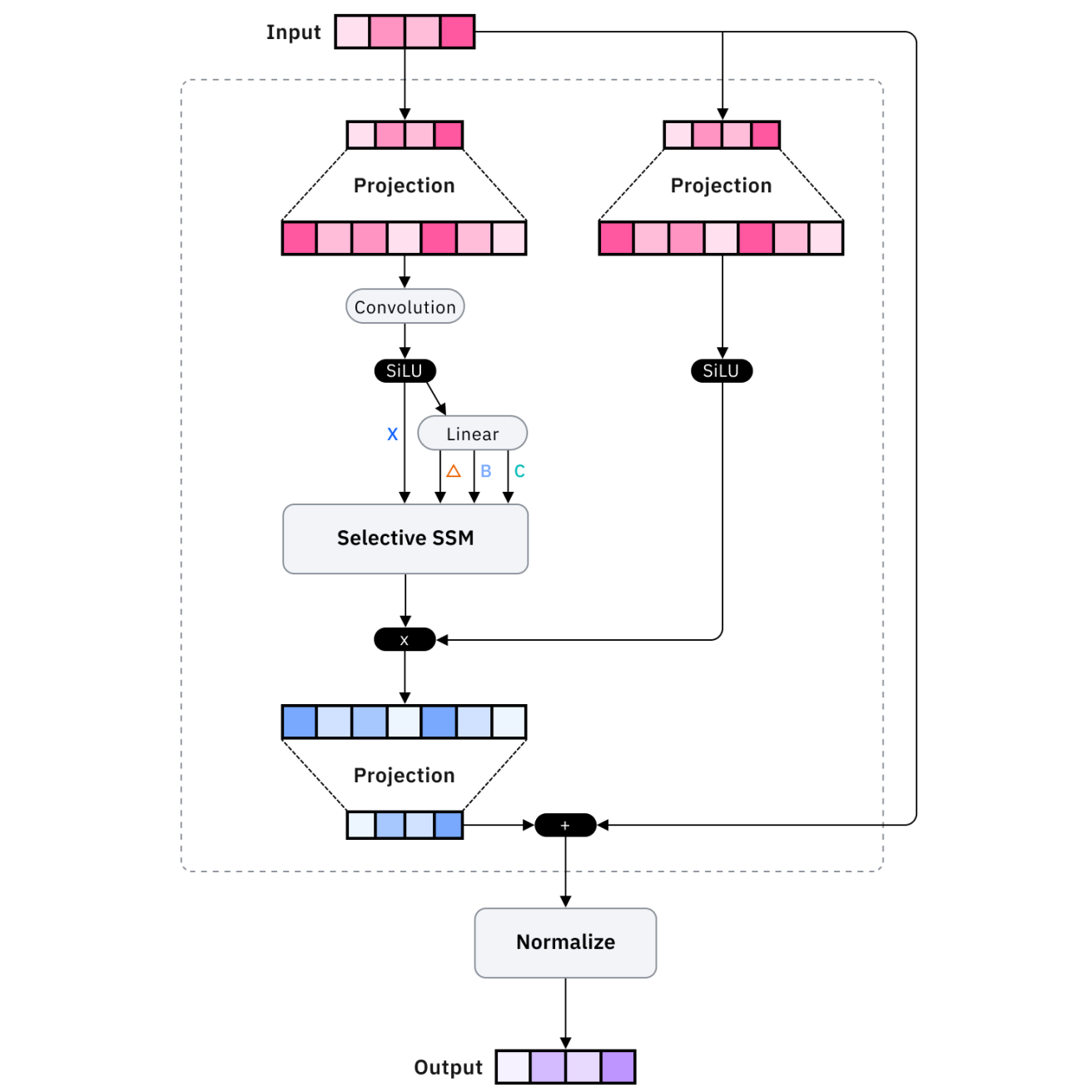
Los transformadores de memoria recurrente amplían los transformadores estándar con conexiones recurrentes que mantienen el estado a largo plazo, lo que permite que la información persista más allá de la ventana de contexto inmediata a través de mecanismos de memoria aprendidos.
Estas innovaciones arquitectónicas son fascinantes desde el punto de vista de la investigación, pero ¿qué pasa con las soluciones listas para la producción? Ahí es donde entran en juego las plataformas de memoria externa.
Plataformas como Mem0 y Zep proporcionan soluciones de memoria externa listas para la producción. Mem0 ofrece una capa de memoria gestionada que extrae, almacena y recupera automáticamente la información relevante. Zep se centra en la memoria conversacional con resumen integrado, extracción de datos y búsqueda vectorial.
Aunque estas plataformas ofrecen soluciones prácticas, algunos investigadores se están inspirando en una fuente inesperada: cómo el cerebro humano forma y gestiona realmente los recuerdos.
CAMELoT (Consolidated Associative Memory Enhanced Long Transformer) aplica principios de neurociencia a la memoria LLM, implementando la consolidación, la detección de novedades y la ponderación de la actualidad. Estos principios reflejan los sistemas de memoria humanos, creando un comportamiento de memoria más natural.
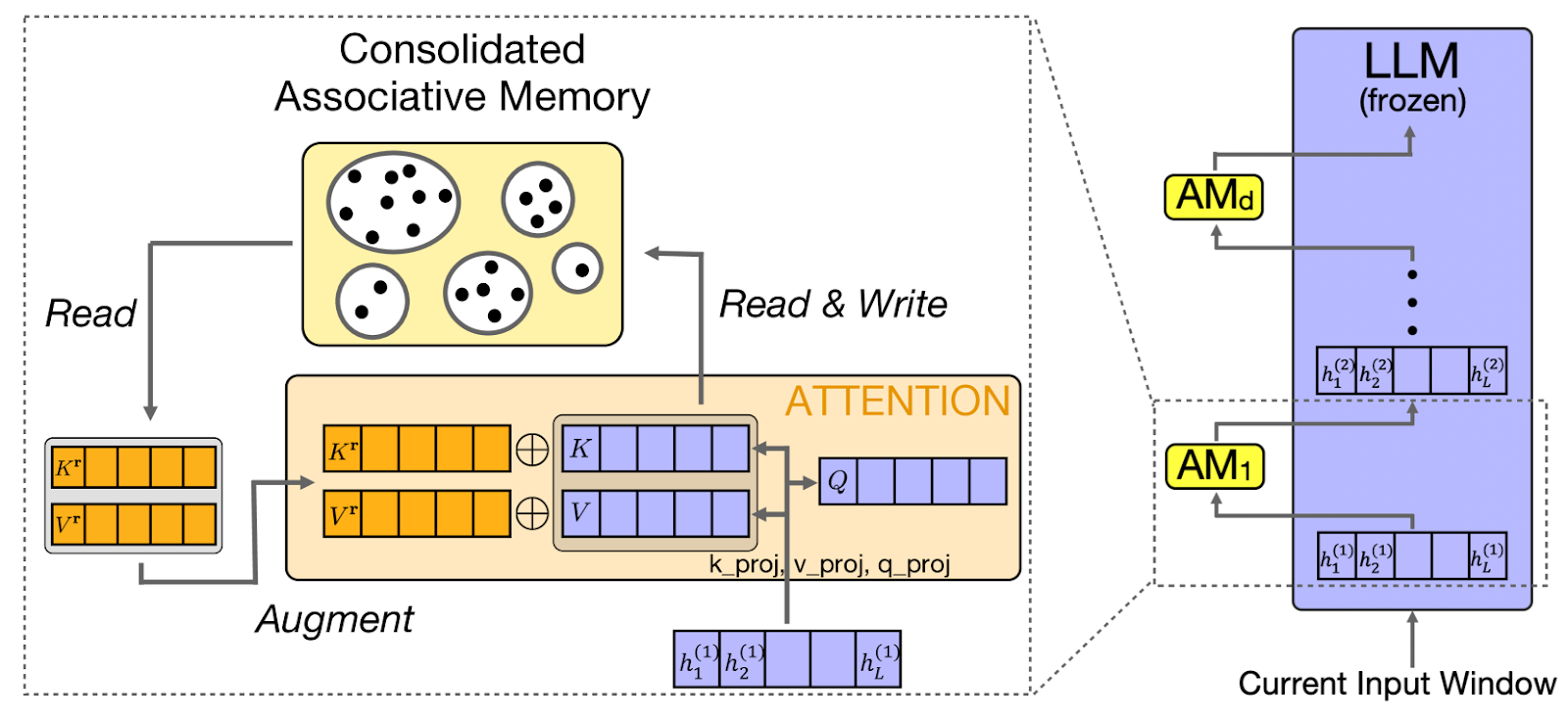
Basándose en estos principios de la neurociencia, otro enfoque, como el de Laminar, se centra específicamente en cómo los seres humanos recordáis experiencias y acontecimientos concretos.
Larimar permite a los LLM mantener episodios de memoria diferenciados. En lugar de tratar toda la información pasada de manera uniforme, la memoria episódica estructura la información en eventos discretos. Esto permite la generalización de la longitud del contexto. El modelo hace referencia a episodios específicos del pasado sin cargar el historial completo.
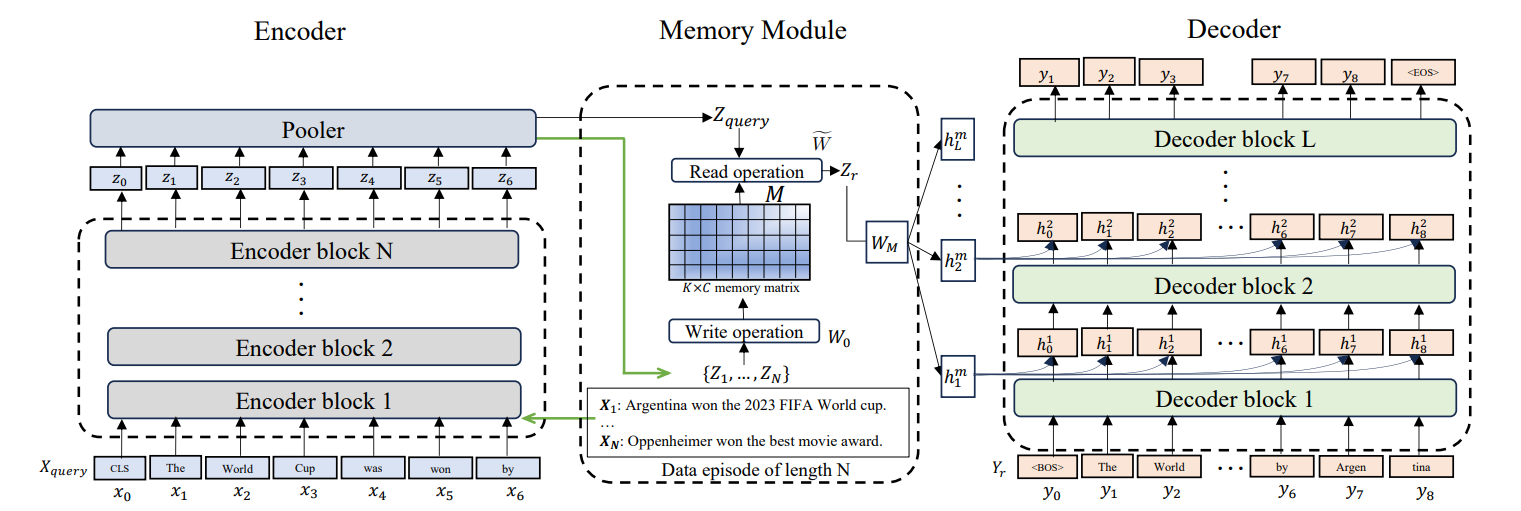
Estas arquitecturas avanzadas son muy prometedoras, pero también introducen nuevas complejidades. Examinemos los retos prácticos que surgen al implementar sistemas de memoria y las estrategias para superarlos.
Incluso con arquitecturas sofisticadas, he descubierto que los sistemas de memoria se enfrentan a retos que a menudo requieren una mitigación cuidadosa. Comprender estos obstáculos y sus soluciones es fundamental para crear sistemas de producción sólidos en los que los usuarios puedan confiar.
El olvido catastrófico se produce cuando los modelos pierden información aprendida previamente. Las soluciones incluyen la consolidación de la memoria, el refuerzo de los recuerdos importantes, las jerarquías de la memoria, la conservación de la información crítica y la actualización periódica de la memoria.
Más allá del olvido, otro reto crítico es cuando los sistemas de memoria engañan activamente al modelo. Las alucinaciones (generación de información plausible pero incorrecta) se ven agravadas por una memoria defectuosa. La mitigación implica la atribución de la fuente, la puntuación de confianza de los recuerdos recuperados y los pasos de verificación.
Por último, el almacenamiento de las conversaciones y preferencias de los usuarios plantea importantes cuestiones relacionadas con la privacidad. Las consideraciones de privacidad y seguridad son fundamentales a la hora de almacenar datos de usuarios. Implementa el cifrado de datos, políticas de retención que purguen automáticamente los datos antiguos y controles de acceso que garanticen que los usuarios solo accedan a sus propios recuerdos.
La integración de la memoria requiere un diseño cuidadoso de la API. Los patrones básicos incluyen la integración con estado, en la que el sistema de memoria mantiene el estado entre solicitudes, y la integración sin estado, en la que cada solicitud incluye los identificadores necesarios.
La gestión eficiente de la memoria emplea el recorte (eliminación de los mensajes más antiguos o menos relevantes), la eliminación (eliminación de elementos específicos) y el resumen (compresión de mensajes). Estos patrones mantienen la memoria dentro del presupuesto y conservan el contexto esencial.
Comprender estos patrones teóricos y retos es valioso, pero la verdadera prueba está en la implementación. Traduzcamos estos conceptos en pautas prácticas que puedas aplicar a tus propios proyectos.
Estas son algunas de las formas en que he visto a los programadores sacar el máximo partido a los sistemas de memoria LLM.
Una gestión eficaz del contexto comienza por comprender tu presupuesto de tokens. Calcula cuántos tokens necesitan tu sistema, memoria y respuesta, asegurándote de que la suma se mantenga dentro de los límites. Estructura los datos jerárquicamente, colocando la información importante donde el modelo mejor la atienda: al principio o al final.
Igualmente importante es cómo preparas los datos antes de que entren en tu sistema de memoria. La preparación de los datos es muy importante. Divide los documentos grandes en fragmentos semánticos en lugar de límites arbitrarios de tokens. Superpón ligeramente los fragmentos para mantener la continuidad del contexto. Incluye metadatos con cada fragmento para permitir la recuperación filtrada.
Una vez que tu sistema esté en funcionamiento, necesitarás formas de medir si realmente está funcionando. La evaluación de la memoria requiere el seguimiento de métricas como la precisión de la recuperación, la tasa de alucinaciones y la satisfacción de los usuarios. Supervisa la latencia del sistema de memoria, el uso de tokens y la relevancia de la recuperación.
Por último, tu estrategia de recuperación debe adaptarse a la complejidad de las consultas de los usuarios. Las estrategias de recuperación flexibles se adaptan a la complejidad de las consultas. Las consultas simples utilizan la búsqueda por palabras clave, mientras que las preguntas complejas se benefician de la búsqueda por similitud semántica. Implementa espacios de nombres de memoria para organizar la información por usuario, tema o período de tiempo.
La memoria de los modelos lingüísticos de gran tamaño transforma estos modelos de generadores de texto sin estado en asistentes de IA sensibles al contexto, capaces de mantener interacciones coherentes y personalizadas. A lo largo de este tutorial, he explorado los fundamentos de la memoria LLM, desde las ventanas de contexto hasta las arquitecturas avanzadas.
Creo que las conclusiones clave son empezar con ventanas de contexto y búferes de conversación bien gestionados para las necesidades inmediatas, implementar RAG para un acceso escalable al conocimiento más allá de la memoria paramétrica, aprovechar las plataformas de memoria externa para aplicaciones de producción y evaluar continuamente la eficacia de la memoria a través de métricas y comentarios de los usuarios.
A medida que avancen las capacidades de LLM, los sistemas de memoria serán cada vez más sofisticados. Para los profesionales, centrarse en crear sistemas de memoria que satisfagan las necesidades de los usuarios: mantener el contexto relevante, olvidar lo que conviene y permitir interacciones naturales que hagan que las aplicaciones de IA sean realmente útiles.
Para seguir aprendiendo, te recomiendo que consultes los siguientes recursos:
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita


