
Course
Introduction to Data Security
2 hr
12.8K
AI and ML are usually used interchangeably. But if I had to define them and show their differences quickly, I’d say that AI refers to the technology that builds machines to imitate cognitive functions associated with human intelligence, while ML refers to a subset of AI algorithms that learn and improve from data.
In this article, I want to take a journey into the applicability of machine learning techniques in cybersecurity, showcasing a range of use cases and the challenges of explainability, interpretability, and robustness that must be addressed to take advantage of its potential.
Threat detection and response refers to the detection of cyberthreats against networks or systems, followed by swift and effective mitigation strategies. This process involves detecting anomalous behaviors within networks and systems, identifying unauthorized intrusions, and analyzing malware samples to protect our systems.
Detecting anomalies refers to identifying patterns in data that do not conform to a well-defined notion of normal behavior.
This fundamental concept finds applicability across diverse fields, and cybersecurity is no exception. I use anomaly detection for identifying diverse malicious activities such as detecting data exfiltration, Distributed Denial of Service (DDoS) attacks, malware infections, and others.Various machine learning algorithms, such as Local outlier factor (LOF), Isolation forest, One-class support vector machine (OC-SVM), have been employed to detect anomalies. However, selecting the appropriate technique for identifying outliers is a complex task that requires careful consideration of several factors, including:
We’ll explore how we select the right machine learning techniques and also explain how they detect malicious cybersecurity activities. Our focus will be on two critical applications in cybersecurity: intrusion detection and malware analysis.
Intrusion detection systems (IDS) are the eyes and ears of computer networks and systems, monitoring and analyzing network traffic (network-based IDS) and system calls (host-based IDS) for malicious activities.
Throughout my experiments, I have witnessed the power of anomaly detection approaches for both systems in detecting the presence of new or previously unknown threats that evade signature-based techniques, which rely on predefined attack patterns for detection.
Before diving into host-based IDS, it’s important to understand what system calls are. They’re essentially requests made by a program to the operating system to perform specific tasks. Suppose you use a text editor to modify a file on a Linux operating system. Behind the scenes, your text editor requests to open a file using the system call open(), write changes to it using write(), and then save it by closing the file using close().
While a text editor’s system calls are straightforward and predictable, a malicious actor’s system call sequence is often deceptive. A malicious program might employ a series like open(), write() to drop a hidden file, then use execve() to execute it with elevated privileges. This is followed by network-related calls like socket() to potentially establish a command-and-control channel attack.
To address this, system call sequences are often transformed into a static feature representation suitable for machine learning algorithms. But, you might be wondering, which learning technique is most suitable for training machine learning models in this case?
The choice of the learning technique highly depends on the availability of labels. If a balanced dataset comprising both normal and anomalous sequences of system calls is accessible, I would certainly go for supervised anomaly detection models such as Support Vector Machines (SVM).
Conversely, in the absence of labeled data, I can use unsupervised learning models like Isolation Forest. For scenarios where only normal behavior is represented in the training data, I seek semi-supervised learning techniques such as One-Class SVM or DBSCAN.
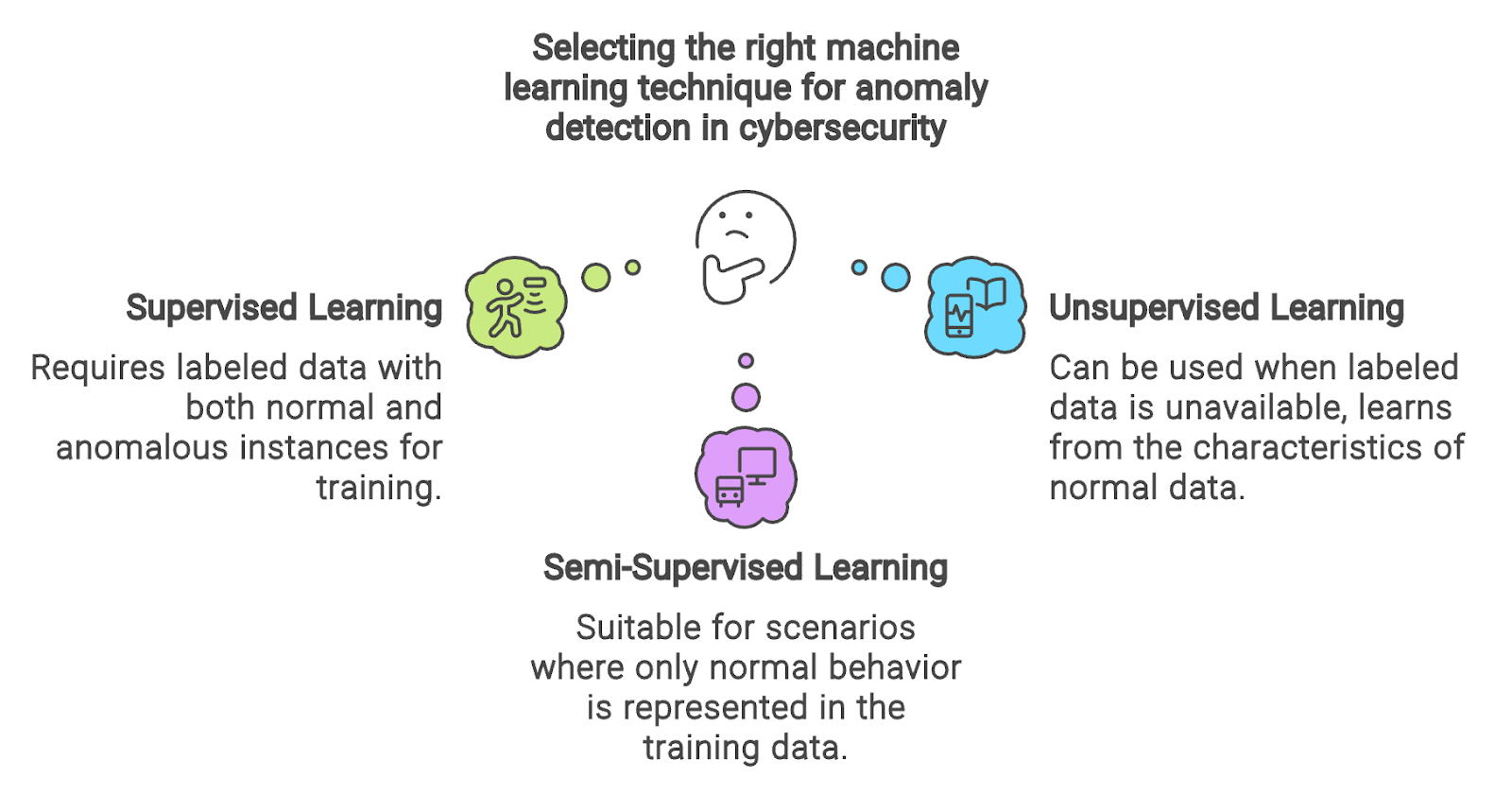
Diagram created with Napkin.ai
Now that we have understood how ML is applied to host-based IDS, let’s move into the realm of network-based IDS. While host-based systems focus on individual machines, network-based IDS identify intrusions in network data; that is, instead of analyzing system calls, network IDS inspect information theft and network disruption activities by monitoring network flow statistics, payload data, and packet headers.
A quick glance at the following table can help you get an idea of what a network flow dataset looks like.
|
Destination Port |
Source Port |
Flow Duration (ms) |
Total Fwd Packets |
Total Bckwd Packets |
Label |
|
54865 |
9910 |
6 |
5000 |
600 |
0 |
|
54810 |
9010 |
2 |
2000 |
200 |
1 |
Synthetic normal and abnormal network flow statistics.
Each row in the dataset represents an independent network communication session between two endpoints, with no inherent relations to other flows in the dataset.
Each flow is defined by attributes such as source and destination port numbers, flow duration in milliseconds, and the total number of packets exchanged in both directions. A categorical label indicates whether the network flow is classified as anomalous or an attack, providing essential ground truth for intrusion detection models.
Notably, each row represents an independent network flow without sequential or relational dependencies to other network flows in the data set.
Given the independent nature of network flows, the dataset can be fed after some feature engineering techniques into machine learning algorithms for anomaly detection. As discussed previously in the context of host-based IDS, the selection of suitable machine learning techniques is conditioned on the availability of labeled data.
Before getting to malware analysis, we must first explain what malware is and how it operates.
Malware is a term for malicious software or binary executables designed to carry out an attacker’s harmful intentions. This piece of code intentionally exploits vulnerabilities in target systems to compromise their integrity, steal sensitive data, delete data, and even encrypt data for ransom. It can come in many categories including viruses, worms, spyware, trojans, ransomware, etc.
To understand the type of malware, its functionality, and its potential impact, several features are extracted from static and dynamic analysis and fed into appropriate machine learning algorithms.
Consider malware analysis of Windows executables, i.e. Portable Executables (PEs). We can extract diverse features coming from both dynamic and static analysis of PEs such as byte sequences, APIs/System calls, opcodes, network, file system, CPU registers, PE file characteristics and strings and then feed them into suitable supervised, unsupervised and semi-supervised machine learning models to detect malware.
To mitigate the risks of being exposed to cyberattacks, we have to swiftly identify, assess and address potential security weaknesses in our networks, computers and applications. Let’s look at the role played by AI and ML algorithms in improving vulnerability management through vulnerability scanning, patch management, and risk assessment.
As a cybersecurity researcher, I frequently develop custom tools to automate cybersecurity tasks such as network traffic logs’ parsers, fuzzers, and others.
While these tools can significantly enhance our security operations, it’s important to subject them to rigorous vulnerability scanning before using them and sharing them with my colleagues.
Otherwise, an attacker can exploit undiscovered and unpatched vulnerabilities in my custom script to gain unauthorized access, compromise sensitive information, or disrupt services in our company.
Machine learning models have the ability to see the forest for the trees. They excel at extracting meaningful features from large datasets by discovering subtle patterns and correlations. Having this in mind, I’ve begun exploring them to see if they are capable of automating vulnerability detection, doing faster analysis, and identifying previously undisclosed vulnerabilities.
To build an ML-based vulnerability detection model, I start by collecting various types of vulnerable and non-vulnerable data for training the model from various sources, including NVD (National Vulnerability Database), OWASP, etc.
The collection is then preprocessed and embedded to be fed into the chosen model. The input could be represented as a Graph or Tree showing relationships between different code elements, such as Code Property Graph (CPG) or Abstract Syntax Trees (AST).
The input can also have a token-based representation, in which the source code is transformed into token vectors. Various embedding techniques can later be applied, including Word2Vec, Graph embedding, One hot embedding, N-gram features, etc.
As explained in previous applications, picking a machine learning model and its learning technique depends mainly on the availability of labels. In the training phase, the vulnerability detection dataset is separated into training and validation sets, and the model learns from labeled data.
The model’s parameters are updated iteratively depending on the prediction errors using optimization techniques. After the model completes its learning process, its ability to detect vulnerabilities is measured using unseen data. Key performance indicators like accuracy, precision, recall, and F1 score are computed to assess the model’s ability to detect vulnerabilities.
Upon detecting vulnerabilities in my custom script, a comprehensive risk assessment is essential. If existing security controls prevent the exploitation of the discovered vulnerabilities or the potential consequences are minimal, the risk might be accepted.
Alternatively, avoiding using the developed code entirely could also be considered to eliminate any exploitation risk. However, if complete elimination is impractical, implementing mitigation strategies is crucial.
Next, we’ll explore patching vulnerable software as a primary mitigation tactic.
While addressing all open and critical vulnerabilities is ideal, it’s often impractical. A more strategic approach is essential. By using machine learning, we can proactively predict which vulnerabilities will most likely be exploited to cause security incidents. This enables us to prioritize patching efforts.
Created with Napkin.ai
To streamline our patch prioritization process, we utilize the tree-based pre-trained Exploit Prediction Scoring System (EPSS) model that combines vulnerability information with real-world exploit activity to predict the likelihood that attackers will attempt to use a specific vulnerability over the next thirty days.
The EPSS machine learning model identifies patterns and relationships between vulnerability information, like CVSS, and exploitation activity to mathematically identify the likelihood that attackers will use a vulnerability.
Following vulnerability prioritization, patches undergo rigorous acquisition, validation, and testing to mitigate operational risks. Patch deployment is a complex process that depends on several factors, including:
Given the scale and diversity of modern IT environments, manual patch deployment is often labor-intensive and time-consuming. AI-driven automation can streamline this process by intelligently selecting and deploying the appropriate patch to each system based on these critical factors.
Clustering algorithms, such as K-means, can be leveraged in this case to group similar systems together for more efficient patch deployment.
Cyber-risk assessment is important for identifying, evaluating and mitigating potential threats and detected vulnerabilities.
Since traditional approaches often fall short in finding indicators of unpredictable cyber-risks, researchers have started to turn to machine learning.
By using supervised and multi-class classification ML, researchers can improve cyber-risk assessment through a comprehensive analysis of key factors.
As outlined in the table below, these factors include cybersecurity investment, workforce characteristics, attack history, infrastructure vulnerabilities, external advisory, and associated risk. Their proof-of-concept SecRiskAI ML-based framework demonstrates the potential of ML in predicting the likelihood of DDoS or phishing attacks.
|
Information |
Example |
|
Revenue |
2,500,000 |
|
Cybersecurity Investment |
500,000 |
|
Successful Attacks |
5 |
|
Failed Attacks |
10 |
|
Number of Employees |
4,450 |
|
Employee Training |
Medium |
|
Known Vulnerabilities |
9 |
|
External Cybersecurity advisor |
No |
|
Risk |
Low |
An example of key attributes for cyber-risk assessment (Source)
Now let’s explore how AI and ML are changing incident response. We’ll explore how they automate incident response workflows, reduce response times, proactively uncover hidden threats, and improve forensic analysis to trace the origins and impact of cyberattacks.
I have observed firsthand how SOAR systems are designed to take in alerts from Security Information and Event Management (SIEM) systems and activate appropriate playbooks that automate and coordinate a series of security tasks.
These tasks may include investigative actions, like checking URL reputations or retrieving user and asset details, as well as response actions, such as blocking an IP address on a firewall or killing a malicious process on an endpoint.
However, we currently face significant limitations within these systems. Security analysts are required to manually define, create, and change playbooks, and the selection between multiple playbooks is governed by rules set by security analysts.
To overcome these limitations, I have seen how the integration of AI and ML into SOC platforms can revolutionize this process, enabling us to automatically generate playbooks that can effectively
respond to unknown alerts.
This not only enhances the efficiency of our response but also empowers analysts to focus on more tasks. Using ML algorithms, we can also train it to calculate the penalty cost of each response action depending on the received alert and select the response with the lowest penalty.
Imagine how stressful it would be to sift through millions of logs, trying to identify potential threats.
Now, amplify the challenge to the scale of an enterprise level, where each and every log must be examined one by one and classified as either malicious or benign.
By incorporating machine learning into the process, we can make this task simpler and accelerate threat detection. AI and ML algorithms, i.e., SVM, Random Forest, can be trained to analyze and categorize logs efficiently, allowing for rapid identification of threats and reducing the burden on security teams.
As digital data continues to grow in volume and complexity, integrating AI and ML into digital forensics—the analysis of digital evidence for investigating cyber crimes—has become essential.
This integration allows us to enhance the speed, accuracy, and effectiveness of identifying and responding to cyber threats.
AI and ML can be used in forensic triage, for example. In this case, we use ML algorithms to classify and categorize large numbers of digital files based on their relevance to an investigation.
The integration of AI in cybersecurity presents significant opportunities. However, it’s important to also acknowledge its inherent challenges and limitations.
Many AI systems are susceptible to adversarial attacks, i.e., poisoning, evasion, model extraction, prompt injection, and inference, that exploit their vulnerabilities.
In these attacks, adversaries carefully add perturbations to the input that are imperceptible to humans but can cause models to make incorrect predictions. This raises safety concerns about the deployment of these systems in safety-critical environments, and cybersecurity is no exception.
To effectively combat these attacks, we employ various defensive mechanisms such as adversarial training, defensive distillation, and gradient masking.
While AI algorithms demonstrate effectiveness in achieving outcomes and predictions, I struggle to understand their internal working mechanisms.
This is very important in my field since entrusting critical choices to an unexplainable system presents evident risks.
Here, Explainable AI (XAI) offers a path forward into developing AI-driven cybersecurity systems with greater explainability while maintaining high performance. By providing transparency in AI decision-making, XAI helps me to make well-informed analyses and take the most appropriate actions in response to security incidents.
Recent advances in XAI techniques, i.e. feature importance analysis and decision tree visualization, are making this transparency achievable.
Whenever I select a dataset for training my AI-based cybersecurity solutions, I make sure that it is not biased. Otherwise, my developed models could result in unfair or discriminatory outputs. I employ data preprocessing techniques to identify and remove biases, present the training in data, and implement fairness techniques to evaluate the model’s output for potential bias.
If you’ve read this far, you’ve seen how AI and ML are changing how we protect our computers, mobile devices, networks, and applications. You’ve witnessed how they empower security teams, detect threats faster, and strengthen various cybersecurity tools.
And here’s what is exciting: I think we’re just getting started.
The future of cybersecurity lies in the continued evolution of AI and ML, especially in large language models (LLMs). Due to their expanded token limit, code interpretation ability, and detailed analysis, these advanced models will enhance our ability to analyze and respond to threats by scaling up malware analysis with greater speed and accuracy.
Consider the case of Gemini 1.5 model which is currently being used to detect malware within huge files. Despite lacking cybersecurity-specific training, they can solve relevant tasks through prompt engineering, in-context learning, and chains-of-thought.
We’re also getting glimpses of that future through the fine-tuning of open-weights LLMs, including Llama, for cybersecurity-related tasks such as Hackmentor.
In this blog, we have examined how AI- and ML-based cybersecurity tools are useful for tackling the dynamic and complex nature of modern cyber threats. These tools are effective at detecting, responding to, and mitigating risks through targeted applications in threat detection, vulnerability management, and incident response.
However, we must also consider the significant challenges and ethical implications associated with developing and deploying AI-based cybersecurity solutions.
Despite these challenges, the ongoing advancement of AI and ML technologies holds great promise for strengthening our defenses against evolving cyber threats.
Learn more about data security!
Course
Course
Course
blog
Javier Canales Luna
10 min
blog
Matt Crabtree
10 min
blog
Tom Farnschläder
14 min
blog
Javier Canales Luna
12 min
blog
Vidhi Chugh
9 min
podcast

