Análisis de funciones discriminantes en R
El paquete MASS contiene funciones para realizar análisis de funciones discriminantes lineales y cuadráticas. A menos que se especifiquen probabilidades a priori, cada una asume probabilidades a priori proporcionales (es decir, las probabilidades a priori se basan en el tamaño de las muestras). En los ejemplos siguientes, las letras minúsculas son variables numéricas y las mayúsculas son factores categóricos.
Función discriminante lineal
# Linear Discriminant Analysis with Jacknifed Prediction
library(MASS)
fit <- lda(G ~ x1 + x2 + x3, data=mydata,
na.action="na.omit", CV=TRUE)
fit # show resultsEl código anterior realiza un LDA, utilizando la eliminación por listas de los datos que faltan. CV=TRUE genera predicciones jacknifed (es decir, deja una fuera). El código siguiente evalúa la precisión de la predicción.
# Assess the accuracy of the prediction
# percent correct for each category of G
ct <- table(mydata$G, fit$class)
diag(prop.table(ct, 1))
# total percent correct
sum(diag(prop.table(ct)))lda() imprime funciones discriminantes basadas en variables centradas (no estandarizadas). La "proporción de traza" que se imprime es la proporción de varianza entre clases que explican las funciones discriminantes sucesivas. No se producen pruebas de significación. Consulta la sección sobre MANOVA para realizar dichas pruebas.
Función discriminante cuadrática
Para obtener una función discriminante cuadrática, utiliza qda( ) en lugar de lda( ). La función discriminante cuadrática no asume la homogeneidad de las matrices de varianza-covarianza.
# Quadratic Discriminant Analysis with 3 groups applying
#
resubstitution prediction and equal prior probabilities.
library(MASS)
fit <- qda(G ~ x1 + x2 + x3 + x4, data=na.omit(mydata),
prior=c(1,1,1)/3))Fíjate en la forma alternativa de especificar la eliminación por lista de los datos que faltan. La re-sustitución (utilizar los mismos datos para derivar las funciones y evaluar su precisión de predicción) es el método por defecto, a menos que se especifique CV=TRUE. La re-sustitución será demasiado optimista.
Visualizar los resultados
Puedes trazar cada observación en el espacio de las 2 primeras funciones discriminantes lineales utilizando el código siguiente. Los puntos se identifican con el ID de grupo.
# Scatter plot using the 1st two discriminant dimensions
plot(fit) # fit from lda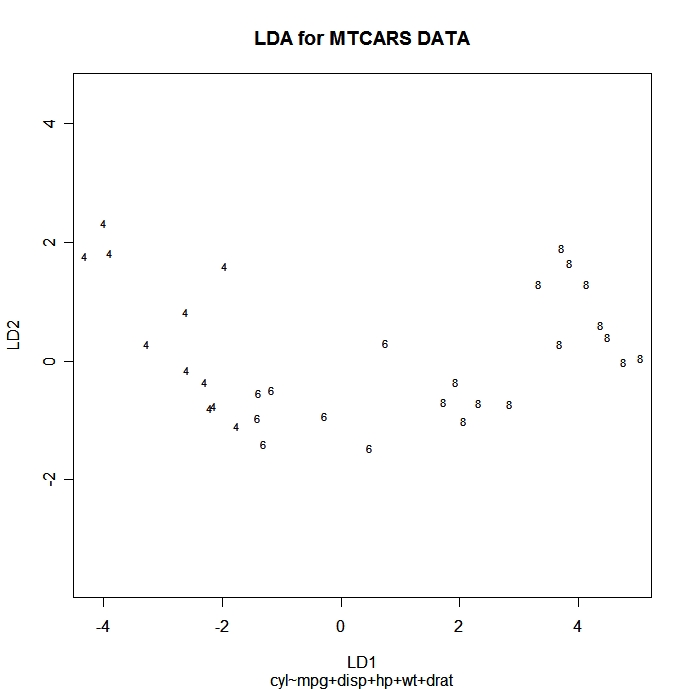
El código siguiente muestra histogramas y gráficos de densidad para las observaciones de cada grupo en la primera dimensión discriminante lineal. Hay un panel para cada grupo y todos aparecen alineados en el mismo gráfico.
# Panels of histograms and overlayed density plots
# for 1st discriminant function
plot(fit, dimen=1, type="both") # fit from lda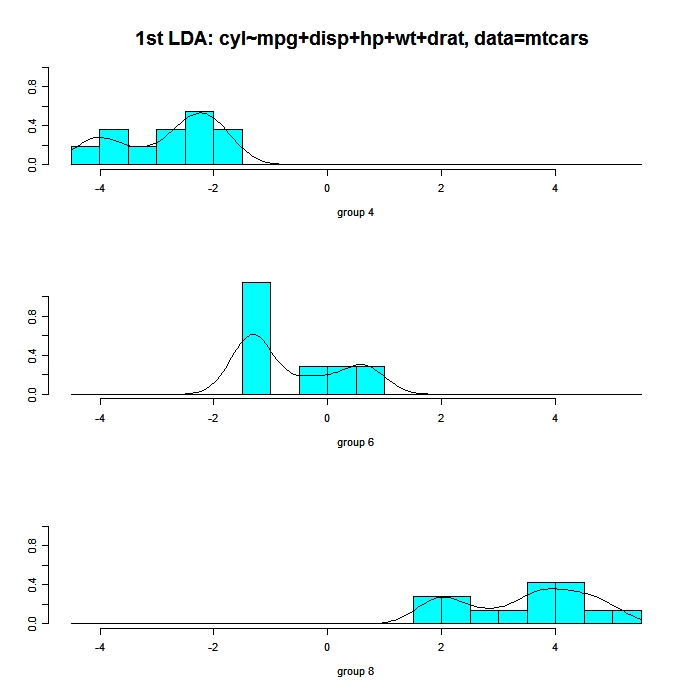
La función partimat( ) del paquete klaR puede mostrar los resultados de una clasificación lineal o cuadrática de 2 variables a la vez.
# Exploratory Graph for LDA or QDA
library(klaR)
partimat(G~x1+x2+x3,data=mydata,method="lda")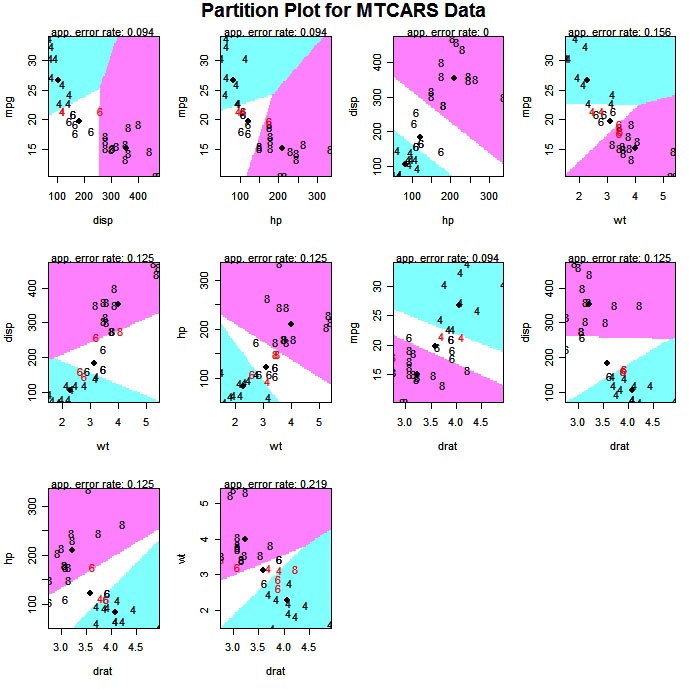
También puedes producir una matriz de dispersión con codificación de colores por grupos.
# Scatterplot for 3 Group Problem
pairs(mydata[c("x1","x2","x3")], main="My Title ", pch=22,
bg=c("red", "yellow", "blue")[unclass(mydata$G)])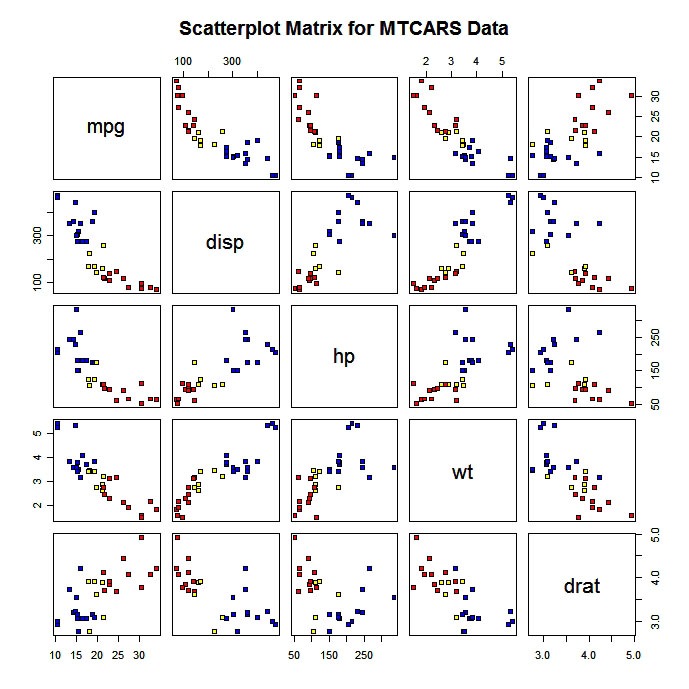
Supuestos de prueba
Ver Supuestos (M)ANOVAparalos métodos de evaluación de la normalidad multivariante y la homogeneidad de las matrices de covarianza.
Practicar
Para practicar la mejora de las predicciones, prueba el curso Aprendizaje supervisado en R</a > .