Estadística en R
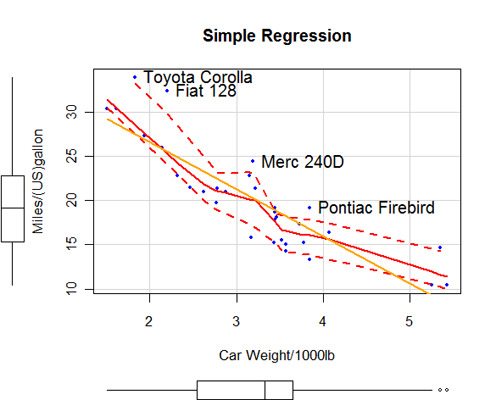
Esta sección describe estadísticas básicas (y no tan básicas). Incluye código para obtener estadísticas descriptivas, recuentos de frecuencias y tabulaciones cruzadas (incluidas pruebas de independencia), correlaciones(pearson, spearman, kendall, policóricas), pruebas t (con varianzas iguales y desiguales), pruebas no paramétricas de diferencias entre grupos (U de Mann Whitney, Wilcoxon Signed Rank, prueba de Kruskall Wallis, prueba de Friedman), regresión lineal múltiple (incluidos diagnósticos, validación cruzada y selección de variables), análisis de la varianza (incluidos ANCOVA y MANOVA) y estadística basada en remuestreo.
Dado que los análisis de datos modernos casi siempre implican evaluaciones gráficas de las relaciones y los supuestos, se proporcionan enlaces a métodos gráficos apropiados a lo largo de todo el documento.
Siempre es importante comprobar los supuestos del modelo antes de hacer inferencias estadísticas. Aunque resulta un tanto artificial separar el modelado de regresión y un marco ANOVA en este sentido, mucha gente aprende estos temas por separado, así que aquí he seguido la misma convención.
Los diagnósticos de regresión abarcan los valores atípicos, las observaciones influyentes, la no normalidad, la varianza de error no constante, la multicolinealidad, la no linealidad y la no independencia de los errores. Los supuestos de prueba clásicos para ANOVA/ANCOVA/MANCOVA incluyen la evaluación de la normalidad y la homogeneidad de las varianzas en el caso univariante, y la normalidad multivariante y la homogeneidad de las matrices de covarianza en el caso multivariante. También se considera la identificación de valores atípicos multivariantes.
El análisis de la potencia proporciona métodos de análisis estadístico de la potencia y de estimación del tamaño de la muestra para diversos diseños.
Por último, se describen dos funciones que ayudan a un procesamiento eficaz(con y por).
Estadística avanzada
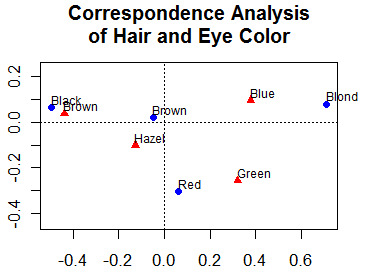
Esta sección describe métodos estadísticos más avanzados. Esto incluye el descubrimiento y la exploración de complejas relaciones multivariantes entre variables. También se proporcionan enlaces a métodos gráficos apropiados.
Es difícil ordenar estos temas de forma directa. He elegido los siguientes epígrafes (ciertamente arbitrarios).
Modelos predictivos
En modelos predictivos, tenemos modelos lineales generalizados (incluyen regresión logística, regresión de Poisson y análisis de supervivencia), análisis de funciones discriminantes (tanto lineales como cuadráticas) y modelización de series temporales.
Modelos de variables latentes
Esto incluye el análisis factorial (componentes principales, análisis factorial exploratorio y confirmatorio), el análisis de correspondencias y el escalado multidimensional(métrico y no métrico).
Métodos de partición
El Análisis de Conglomerados incluye enfoques de partición (k-means), aglomerativos jerárquicos y basados en modelos. Los métodos basados en árboles (¡que podrían haber ido fácilmente en modelos predictivos!) incluyen árboles de clasificación y regresión, bosques aleatorios y otras metodologías de partición.
Otras herramientas
Esta sección incluye herramientas de gran utilidad, como el bootstrapping en R y la programación de álgebra matricial (piensa en MATRIX en SPSS o PROC IML en SAS).
Ir más lejos
Para practicar la estadística en R de forma interactiva, prueba este curso de introducción a la estadística.
Prueba el curso Aprendizaje Supervisado en R, que incluye un ejercicio con Bosques Aleatorios.