Modelos lineales generalizados en R
Los modelos lineales generalizados se ajustan mediante la función glm( ). La forma de la función glm es
glm(fórmula , family= familytype(enlace=función de enlace), data=)
| Familia | Función de enlace por defecto |
| binomio | (enlace = "logit") |
| gaussiano | (enlace = "identidad") |
| Gamma | (enlace = "inverso") |
| inverse.gaussian | (enlace = "1/mu^2") |
| poisson | (enlace = "registro") |
| cuasi | (enlace = "identidad", varianza = "constante") |
| quasibinomial | (enlace = "logit") |
| quasipoisson | (enlace = "registro") |
Consulta help(glm ) para conocer otras opciones de modelado. Consulta help(familia ) para conocer otras funciones de enlace permitidas para cada familia. Aquí se tratarán tres subtipos de modelos lineales generalizados: la regresión logística, la regresión de Poisson y el análisis de supervivencia.
Regresión logística
La regresión logística es útil cuando predices un resultado binario a partir de un conjunto de variables predictoras continuas. Con frecuencia se prefiere al análisis de la función discriminante por sus supuestos menos restrictivos.
# Logistic Regression
# where F is a binary factor and
# x1-x3 are continuous predictors
fit <- glm(F~x1+x2+x3,data=mydata,family=binomial())
summary(fit) # display results
confint(fit) # 95% CI for the coefficients
exp(coef(fit)) # exponentiated coefficients
exp(confint(fit)) # 95% CI for exponentiated coefficients
predict(fit, type="response") # predicted values
residuals(fit, type="deviance") # residualsPuedes utilizar anova(fit1 , fit2, test="Chisq") para comparar modelos anidados. Además, cdplot(F ~ x , data= mydata) mostrará el gráfico de densidad condicional del resultado binario F sobre la variable continua x.
 haz clic para ver
haz clic para ver
Regresión de Poisson
La regresión de Poisson es útil cuando se predice una variable de resultado que representa recuentos a partir de un conjunto de variables predictoras continuas.
# Poisson Regression
# where count is a count and
# x1-x3 are continuous predictors
fit <- glm(count ~ x1+x2+x3, data=mydata, family=poisson())
summary(fit) display resultsSi tienes sobredispersión (observa si la desviación residual es mucho mayor que los grados de libertad), quizá te convenga utilizar quasipoisson() en lugar de poisson().
Análisis de supervivencia
El análisis de supervivencia (también llamado análisis histórico de sucesos o análisis de fiabilidad) abarca un conjunto de técnicas para modelizar el tiempo transcurrido hasta un suceso. Los datos pueden estar censurados a la derecha: el acontecimiento puede no haberse producido al final del estudio o podemos tener información incompleta sobre una observación, pero saber que hasta cierto momento el acontecimiento no se había producido (por ejemplo, el participante abandonó el estudio en la semana 10, pero estaba vivo en ese momento).
Mientras que los modelos lineales generalizados se suelen analizar con la función glm( ), el análisis de supervivencia se suele realizar con las funciones del paquete de supervivencia. El paquete de supervivencia puede manejar problemas de una y dos muestras, modelos paramétricos de fallo acelerado y el modelo de riesgos proporcionales de Cox.
Los datos suelen introducirse en el formato hora de inicio, hora de finalización y estado (1=evento ocurrido, 0=evento no ocurrido). Alternativamente, los datos pueden estar en el formato hora del suceso y estado (1=sucedió el suceso, 0=no ocurrió el suceso). Un estado=0 indica que la observación tiene el cenit derecho. Los datos se agrupan en un objeto Surv mediante la función Surv( ) antes de los análisis posteriores.
survfit( ) se utiliza para estimar una distribución de supervivencia para uno o más grupos.survdiff( ) comprueba las diferencias en las distribuciones de supervivencia entre dos o más grupos.coxph( ) modela la función de riesgo en un conjunto de variables predictoras.
# Mayo Clinic Lung Cancer Data
library(survival)
# learn about the dataset
help(lung)
# create a Surv object
survobj <- with(lung, Surv(time,status))
# Plot survival distribution of the total sample
# Kaplan-Meier estimator
fit0 <- survfit(survobj~1, data=lung)
summary(fit0)
plot(fit0, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100,
main="Survival Distribution (Overall)")
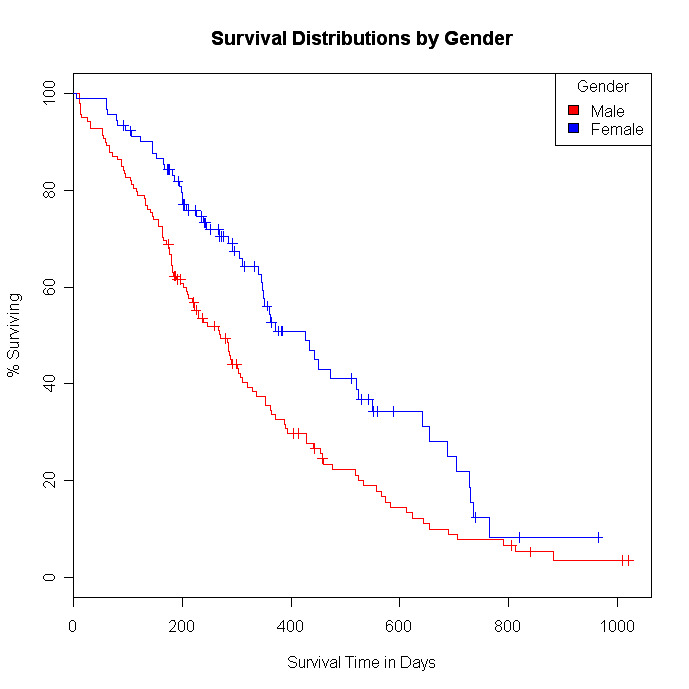
# Compare the survival distributions of men and women
fit1 <- survfit(survobj~sex,data=lung)
# plot the survival distributions by sex
plot(fit1, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100, col=c("red","blue"),
main="Survival Distributions by Gender")
legend("topright", title="Gender", c("Male", "Female"),
fill=c("red", "blue"))
# test for difference between male and female
# survival curves (logrank test)
survdiff(survobj~sex, data=lung)
# predict male survival from age and medical scores
MaleMod <- coxph(survobj~age+ph.ecog+ph.karno+pat.karno,
data=lung, subset=sex==1)
# display results
MaleMod
# evaluate the proportional hazards assumption
cox.zph(MaleMod)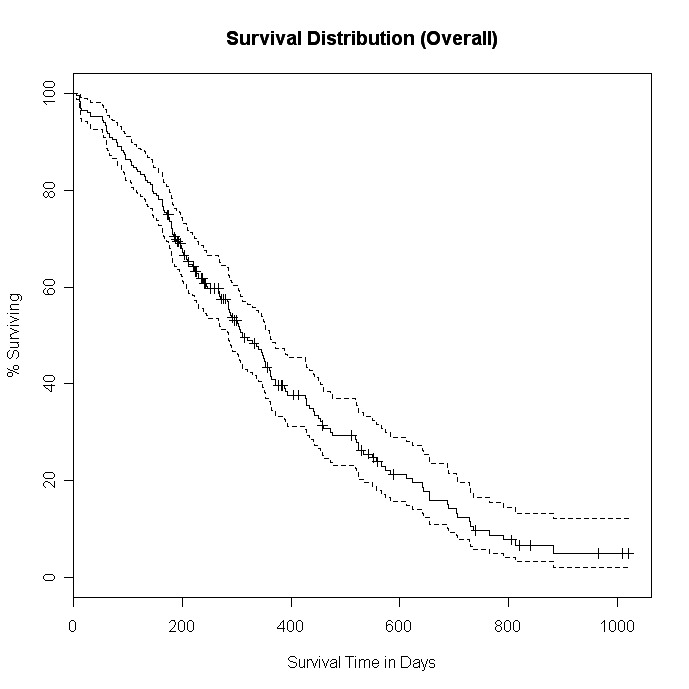
 haz clic para ver
haz clic para ver
Para más información, consulta el artículo de R news de Thomas Lumley sobre el paquete de supervivencia. Otras buenas fuentes son Use R Software to do Survival Analysis and Simulation, de Mai Zhou, y M. J. El capítulo de Crawley sobre Análisis de Supervivencia.
Practicar
Prueba este ejercicio interactivo sobre regresión logística básica con R utilizando la edad como predictor del riesgo crediticio.