Modèles linéaires généralisés en R
Les modèles linéaires généralisés sont ajustés à l'aide de la fonction glm( ). La forme de la fonction glm est la suivante
glm(formule , family= type de famille(lien=linkfunction), data=)
| Famille | Fonction de liaison par défaut |
| binomiale | (lien = "logit") |
| gaussien | (link = "identity") |
| Gamma | (lien = "inverse") |
| inverse.gaussien | (lien = "1/mu^2") |
| poisson | (link = "log") |
| quasi | (lien = "identité", variance = "constante") |
| quasibinôme | (lien = "logit") |
| quasipoisson | (link = "log") |
Voir help(glm) pour d'autres options de modélisation. Voir help(family) pour les autres fonctions de lien autorisées pour chaque famille. Trois sous-types de modèles linéaires généralisés seront abordés ici : la régression logistique, la régression de Poisson et l'analyse de survie.
Régression logistique
La régression logistique est utile lorsque vous prévoyez un résultat binaire à partir d'un ensemble de variables prédictives continues. Elle est souvent préférée à l'analyse de la fonction discriminante en raison de ses hypothèses moins restrictives.
# Logistic Regression
# where F is a binary factor and
# x1-x3 are continuous predictors
fit <- glm(F~x1+x2+x3,data=mydata,family=binomial())
summary(fit) # display results
confint(fit) # 95% CI for the coefficients
exp(coef(fit)) # exponentiated coefficients
exp(confint(fit)) # 95% CI for exponentiated coefficients
predict(fit, type="response") # predicted values
residuals(fit, type="deviance") # residualsVous pouvez utiliser anova(fit1 , fit2, test="Chisq") pour comparer des modèles imbriqués. En outre, cdplot(F ~ x , data= mydata) affiche le graphique de densité conditionnelle du résultat binaire F sur la variable continue x.
 cliquez pour voir
cliquez pour voir
Régression de Poisson
La régression de Poisson est utile pour prédire une variable de résultat représentant des effectifs à partir d'un ensemble de variables prédictives continues.
# Poisson Regression
# where count is a count and
# x1-x3 are continuous predictors
fit <- glm(count ~ x1+x2+x3, data=mydata, family=poisson())
summary(fit) display resultsSi vous avez une surdispersion (voir si la déviance résiduelle est beaucoup plus grande que les degrés de liberté), vous pouvez utiliser quasipoisson() au lieu de poisson().
Analyse de survie
L'analyse de survie (également appelée analyse de l'historique des événements ou analyse de fiabilité) couvre un ensemble de techniques permettant de modéliser le temps écoulé avant un événement. Les données peuvent être censurées à droite - l'événement peut ne pas s'être produit à la fin de l'étude ou nous pouvons disposer d'informations incomplètes sur une observation mais savoir que jusqu'à un certain moment, l'événement ne s'est pas produit (par exemple, le participant a abandonné l'étude au cours de la semaine 10 mais était en vie à ce moment-là).
Alors que les modèles linéaires généralisés sont généralement analysés à l'aide de la fonction glm( ), l'analyse de survie est généralement effectuée à l'aide des fonctions du progiciel survival. Le module de survie peut traiter des problèmes à un ou deux échantillons, des modèles paramétriques de défaillance accélérée et le modèle des risques proportionnels de Cox.
Les données sont généralement saisies sous la forme d'une heure de début, d'une heure de fin et d'un état (1=l'événement s'est produit, 0=l'événement ne s'est pas produit). Les données peuvent également se présenter sous la forme d'une heure de l'événement et d'un état (1=l'événement s'est produit, 0=l'événement ne s'est pas produit). Un statut=0 indique que l'observation est codée à droite. Les données sont regroupées dans un objet Surv via la fonction Surv( ) avant d'être analysées.
survfit( ) est utilisé pour estimer une distribution de survie pour un ou plusieurs groupes.survdiff( ) teste les différences dans les distributions de survie entre deux ou plusieurs groupes.coxph( ) modélise la fonction de hasard sur un ensemble de variables prédictives.
# Mayo Clinic Lung Cancer Data
library(survival)
# learn about the dataset
help(lung)
# create a Surv object
survobj <- with(lung, Surv(time,status))
# Plot survival distribution of the total sample
# Kaplan-Meier estimator
fit0 <- survfit(survobj~1, data=lung)
summary(fit0)
plot(fit0, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100,
main="Survival Distribution (Overall)")
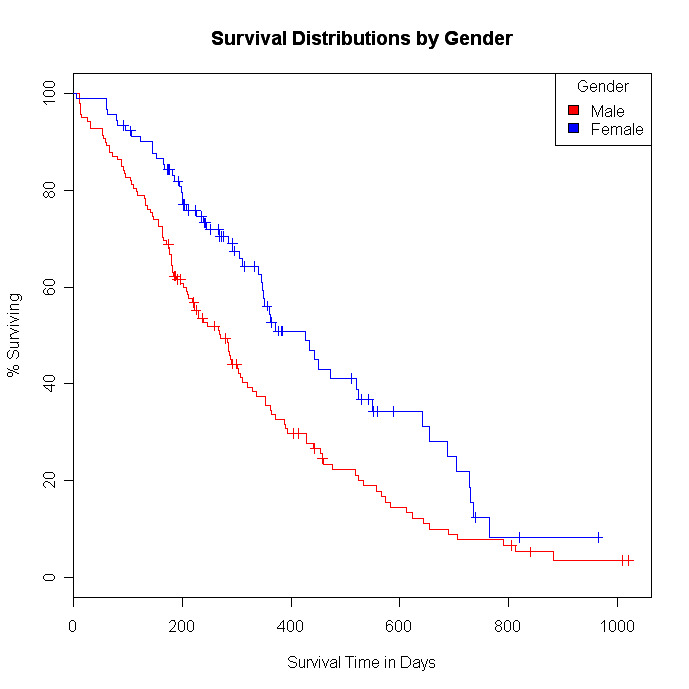
# Compare the survival distributions of men and women
fit1 <- survfit(survobj~sex,data=lung)
# plot the survival distributions by sex
plot(fit1, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100, col=c("red","blue"),
main="Survival Distributions by Gender")
legend("topright", title="Gender", c("Male", "Female"),
fill=c("red", "blue"))
# test for difference between male and female
# survival curves (logrank test)
survdiff(survobj~sex, data=lung)
# predict male survival from age and medical scores
MaleMod <- coxph(survobj~age+ph.ecog+ph.karno+pat.karno,
data=lung, subset=sex==1)
# display results
MaleMod
# evaluate the proportional hazards assumption
cox.zph(MaleMod)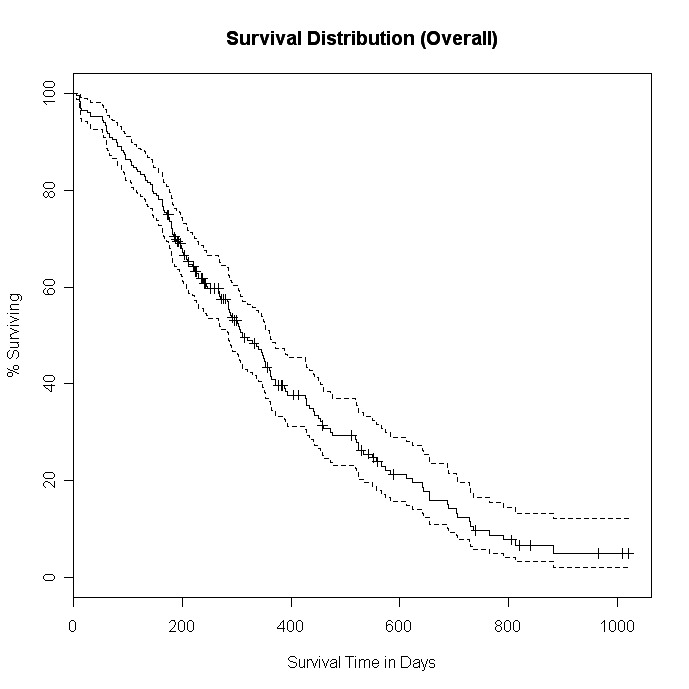
 cliquez pour voir
cliquez pour voir
Pour plus d'informations, consultez l' article de Thomas Lumley sur le paquet de survie. Parmi les autres bonnes sources, citons Use R Software to do Survival Analysis and Simulation de Mai Zhou et M. J. Le chapitre de Crawley sur l' analyse de survie.
Pratiquer
Essayez cet exercice interactif sur la régression logistique de base avec R en utilisant l'âge comme prédicteur du risque de crédit.