Verallgemeinerte lineare Modelle in R
Verallgemeinerte lineare Modelle werden mit der Funktion glm( ) angepasst. Die Form der glm-Funktion ist
glm(Formel , family= familytype(link=linkfunction), data=)
| Familie | Standard Link Funktion |
| binomisch | (link = "logit") |
| gaussian | (Link = "Identität") |
| Gamma | (link = "invers") |
| invers.gaussian | (link = "1/mu^2") |
| poisson | (link = "log") |
| quasi | (link = "Identität", variance = "konstant") |
| Quasibinomisch | (link = "logit") |
| quasipoisson | (link = "log") |
Siehe help(glm) für andere Modellierungsoptionen. Siehe help(family) für weitere zulässige Linkfunktionen für jede Familie. Drei Unterarten von verallgemeinerten linearen Modellen werden hier behandelt: logistische Regression, Poisson-Regression und Überlebensanalyse.
Logistische Regression
Die logistische Regression ist nützlich, wenn du ein binäres Ergebnis aus einer Reihe kontinuierlicher Prädiktorvariablen vorhersagen willst. Sie wird häufig der Diskriminanzfunktionsanalyse vorgezogen, weil sie weniger restriktive Annahmen trifft.
# Logistic Regression
# where F is a binary factor and
# x1-x3 are continuous predictors
fit <- glm(F~x1+x2+x3,data=mydata,family=binomial())
summary(fit) # display results
confint(fit) # 95% CI for the coefficients
exp(coef(fit)) # exponentiated coefficients
exp(confint(fit)) # 95% CI for exponentiated coefficients
predict(fit, type="response") # predicted values
residuals(fit, type="deviance") # residualsDu kannst anova(fit1 , fit2, test="Chisq") verwenden, um verschachtelte Modelle zu vergleichen. Außerdem zeigt cdplot(F ~ x , data= mydata) den bedingten Dichteplot des binären Ergebnisses F für die kontinuierliche Variable x an.
 Zur Ansicht klicken
Zur Ansicht klicken
Poisson-Regression
Die Poisson-Regression ist nützlich, wenn eine Ergebnisvariable, die Zählungen darstellt, aus einer Reihe von kontinuierlichen Prädiktorvariablen vorhergesagt werden soll.
# Poisson Regression
# where count is a count and
# x1-x3 are continuous predictors
fit <- glm(count ~ x1+x2+x3, data=mydata, family=poisson())
summary(fit) display resultsWenn du eine übermäßige Streuung hast (sieh nach, ob die Restabweichung viel größer ist als die Freiheitsgrade), solltest du quasipoisson() anstelle von poisson() verwenden.
Survival-Analyse
Die Survival-Analyse (auch Ereignisverlaufsanalyse oder Zuverlässigkeitsanalyse genannt) umfasst eine Reihe von Techniken zur Modellierung der Zeit bis zum Eintreten eines Ereignisses. Daten können richtig zensiert sein - das Ereignis kann bis zum Ende der Studie nicht eingetreten sein oder wir haben unvollständige Informationen zu einer Beobachtung, wissen aber, dass das Ereignis bis zu einem bestimmten Zeitpunkt nicht eingetreten ist (z. B. hat der Teilnehmer die Studie in Woche 10 abgebrochen, war aber zu diesem Zeitpunkt noch am Leben).
Während verallgemeinerte lineare Modelle in der Regel mit der Funktion glm( ) analysiert werden, wird die Überlebensanalyse in der Regel mit Funktionen aus dem Survival-Paket durchgeführt. Das Survival-Paket kann mit Ein- und Zweistichprobenproblemen, parametrischen beschleunigten Versagensmodellen und dem Cox Proportional Hazards Model umgehen.
Die Daten werden normalerweise im Format Startzeit, Stoppzeit und Status (1=Ereignis eingetreten, 0=Ereignis nicht eingetreten) eingegeben. Alternativ können die Daten auch im Format Zeit bis Ereignis und Status (1=Ereignis eingetreten, 0=Ereignis nicht eingetreten) angegeben werden. Ein Status=0 bedeutet, dass die Beobachtung richtig eingestuft wurde. Die Daten werden vor der weiteren Analyse mit der Funktion Surv( ) in einem Surv-Objekt gebündelt.
survfit( ) wird verwendet, um eine Überlebensverteilung für eine oder mehrere Gruppen zu schätzen.survdiff( ) testet auf Unterschiede in den Überlebensverteilungen zwischen zwei oder mehreren Gruppen.coxph( ) modelliert die Hazard-Funktion für einen Satz von Prädiktorvariablen.
# Mayo Clinic Lung Cancer Data
library(survival)
# learn about the dataset
help(lung)
# create a Surv object
survobj <- with(lung, Surv(time,status))
# Plot survival distribution of the total sample
# Kaplan-Meier estimator
fit0 <- survfit(survobj~1, data=lung)
summary(fit0)
plot(fit0, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100,
main="Survival Distribution (Overall)")
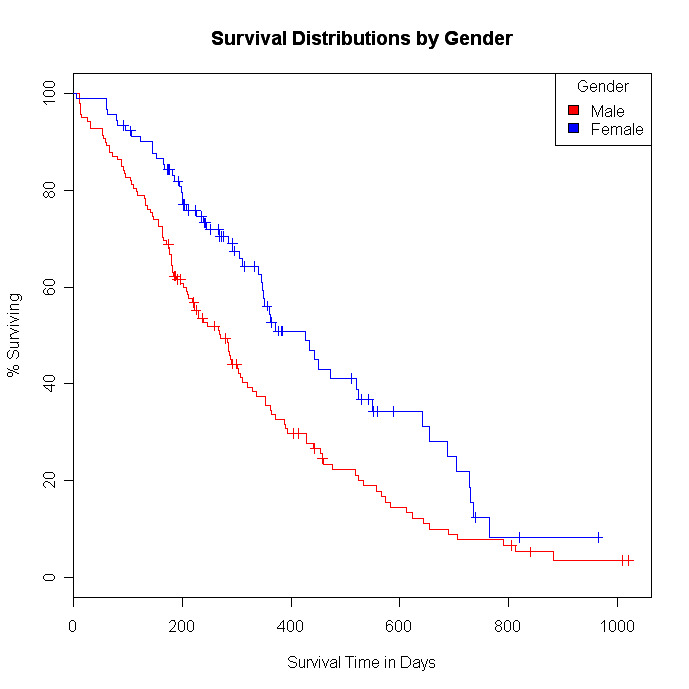
# Compare the survival distributions of men and women
fit1 <- survfit(survobj~sex,data=lung)
# plot the survival distributions by sex
plot(fit1, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100, col=c("red","blue"),
main="Survival Distributions by Gender")
legend("topright", title="Gender", c("Male", "Female"),
fill=c("red", "blue"))
# test for difference between male and female
# survival curves (logrank test)
survdiff(survobj~sex, data=lung)
# predict male survival from age and medical scores
MaleMod <- coxph(survobj~age+ph.ecog+ph.karno+pat.karno,
data=lung, subset=sex==1)
# display results
MaleMod
# evaluate the proportional hazards assumption
cox.zph(MaleMod)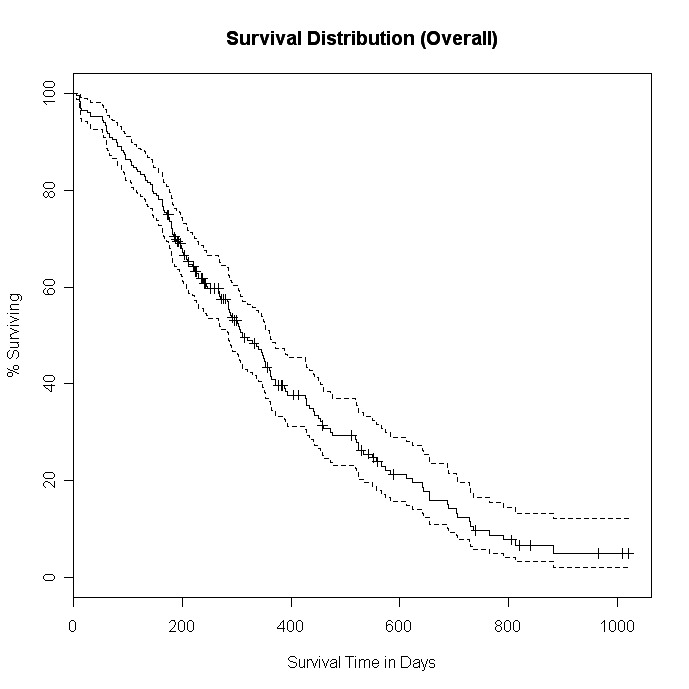
 Zur Ansicht klicken
Zur Ansicht klicken
Weitere Informationen findest du in Thomas Lumleys R-News-Artikel über das Überlebenspaket. Weitere gute Quellen sind Mai Zhou's Use R Software to do Survival Analysis and Simulation und M. J. Crawleys Kapitel über die Survival-Analyse.
Zum Üben
Probiere diese interaktive Übung zur grundlegenden logistischen Regression mit R aus und verwende das Alter als Prädiktor für das Kreditrisiko.