Modelos lineares generalizados no R
Os modelos lineares generalizados são ajustados usando a função glm( ). A forma da função glm é
glm(fórmula , family= tipo de família(link=linkfunction), data=)
| Família | Função de link padrão |
| binomial | (link = "logit") |
| gaussiano | (link = "identity") |
| Gamma | (link = "inverse") |
| inverse.gaussian | (link = "1/mu^2") |
| poisson | (link = "log") |
| quasi | (link = "identity", variância = "constant") |
| quasibinomial | (link = "logit") |
| quasipoisson | (link = "log") |
Consulte help(glm) para obter outras opções de modelagem. Consulte help(family) para conhecer outras funções de link permitidas para cada família. Três subtipos de modelos lineares generalizados serão abordados aqui: regressão logística, regressão de poisson e análise de sobrevivência.
Regressão logística
A regressão logística é útil quando você está prevendo um resultado binário a partir de um conjunto de variáveis preditoras contínuas. Frequentemente, ela é preferida em relação à análise da função discriminante por causa de suas suposições menos restritivas.
# Logistic Regression
# where F is a binary factor and
# x1-x3 are continuous predictors
fit <- glm(F~x1+x2+x3,data=mydata,family=binomial())
summary(fit) # display results
confint(fit) # 95% CI for the coefficients
exp(coef(fit)) # exponentiated coefficients
exp(confint(fit)) # 95% CI for exponentiated coefficients
predict(fit, type="response") # predicted values
residuals(fit, type="deviance") # residualsVocê pode usar anova(fit1 , fit2, test="Chisq") para comparar modelos aninhados. Além disso, cdplot(F ~ x , data= mydata) exibirá o gráfico de densidade condicional do resultado binário F sobre a variável contínua x.
 clique para visualizar
clique para visualizar
Regressão de Poisson
A regressão de Poisson é útil para prever uma variável de resultado que representa contagens de um conjunto de variáveis preditoras contínuas.
# Poisson Regression
# where count is a count and
# x1-x3 are continuous predictors
fit <- glm(count ~ x1+x2+x3, data=mydata, family=poisson())
summary(fit) display resultsSe você tiver dispersão excessiva (veja se o desvio residual é muito maior do que os graus de liberdade), talvez seja melhor usar quasipoisson() em vez de poisson().
Análise de sobrevivência
A análise de sobrevivência (também chamada de análise do histórico de eventos ou análise de confiabilidade) abrange um conjunto de técnicas para modelar o tempo até um evento. Os dados podem ser censurados à direita - o evento pode não ter ocorrido até o final do estudo ou podemos ter informações incompletas sobre uma observação, mas saber que até um determinado momento o evento não ocorreu (por exemplo, o participante abandonou o estudo na semana 10, mas estava vivo naquele momento).
Enquanto os modelos lineares generalizados são normalmente analisados usando a função glm( ), a análise de sobrevivência é normalmente realizada usando funções do pacote survival. O pacote de sobrevivência pode lidar com problemas de uma e duas amostras, modelos de falha acelerada paramétricos e o modelo de riscos proporcionais de Cox.
Normalmente, os dados são inseridos no formato de hora de início, hora de término e status (1=evento ocorrido, 0=evento não ocorrido). Como alternativa, os dados podem estar no formato hora do evento e status (1=evento ocorreu, 0=evento não ocorreu). Um status=0 indica que a observação tem o código correto. Os dados são agrupados em um objeto Surv por meio da função Surv( ) antes das análises posteriores.
survfit( ) é usado para estimar uma distribuição de sobrevivência para um ou mais grupos.survdiff( ) testa as diferenças nas distribuições de sobrevivência entre dois ou mais grupos.coxph( ) modela a função de perigo em um conjunto de variáveis preditoras.
# Mayo Clinic Lung Cancer Data
library(survival)
# learn about the dataset
help(lung)
# create a Surv object
survobj <- with(lung, Surv(time,status))
# Plot survival distribution of the total sample
# Kaplan-Meier estimator
fit0 <- survfit(survobj~1, data=lung)
summary(fit0)
plot(fit0, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100,
main="Survival Distribution (Overall)")
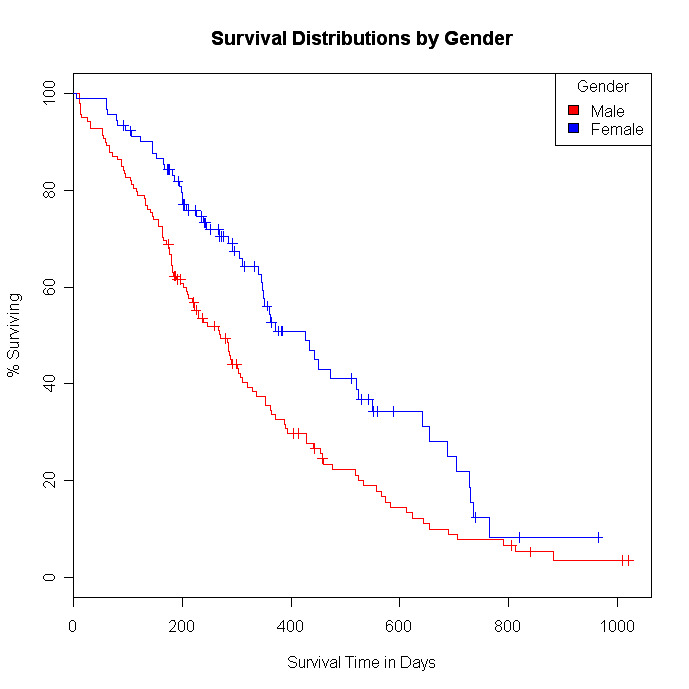
# Compare the survival distributions of men and women
fit1 <- survfit(survobj~sex,data=lung)
# plot the survival distributions by sex
plot(fit1, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100, col=c("red","blue"),
main="Survival Distributions by Gender")
legend("topright", title="Gender", c("Male", "Female"),
fill=c("red", "blue"))
# test for difference between male and female
# survival curves (logrank test)
survdiff(survobj~sex, data=lung)
# predict male survival from age and medical scores
MaleMod <- coxph(survobj~age+ph.ecog+ph.karno+pat.karno,
data=lung, subset=sex==1)
# display results
MaleMod
# evaluate the proportional hazards assumption
cox.zph(MaleMod)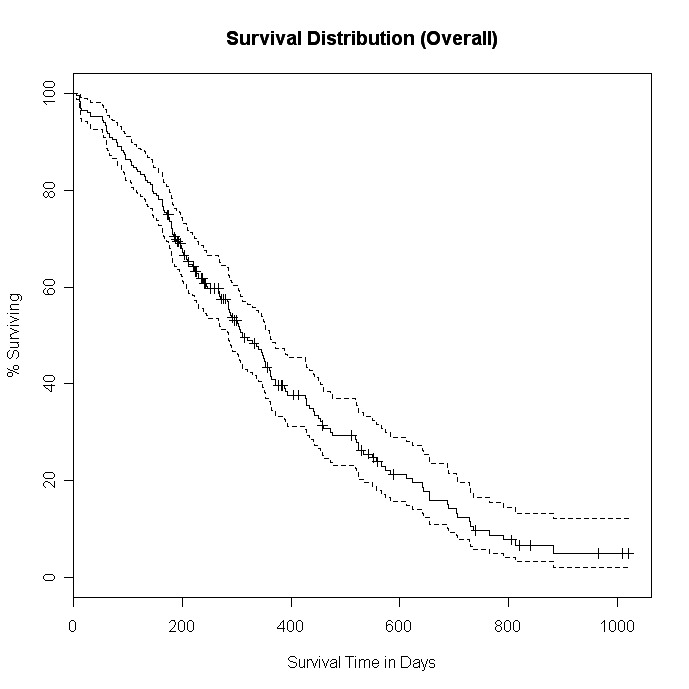
 clique para ver
clique para ver
Para obter mais informações, consulte o artigo da R news de Thomas Lumley sobre o pacote de sobrevivência. Outras boas fontes incluem Use R Software to do Survival Analysis and Simulation, de Mai Zhou, e M. J. O capítulo de Crawley sobre Análise de Sobrevivência.
Para praticar
Experimente este exercício interativo sobre regressão logística básica com o R usando a idade como preditor de risco de crédito.