Programa
Fundamentos de machine learning Em Python
16 h
Ao criarmos modelos para prever resultados ou descobrir padrões, encontraremos vários desafios. Um obstáculo comum é a criação de um modelo que capture com precisão as tendências subjacentes em seus dados. Às vezes, os modelos são simples demais e não conseguem aprender as complexidades, o que leva a um desempenho ruim. Esse fenômeno é conhecido como Underfitting.
Um modelo subajustado não tem um desempenho ruim apenas nos dados em que foi treinado, mas também não consegue generalizar para dados novos e não vistos. Isso significa que suas previsões podem não ser confiáveis em cenários do mundo real. Reconhecer e lidar com a subadaptação é uma etapa importante para que você possa criar modelos de machine learning robustos e eficazes.
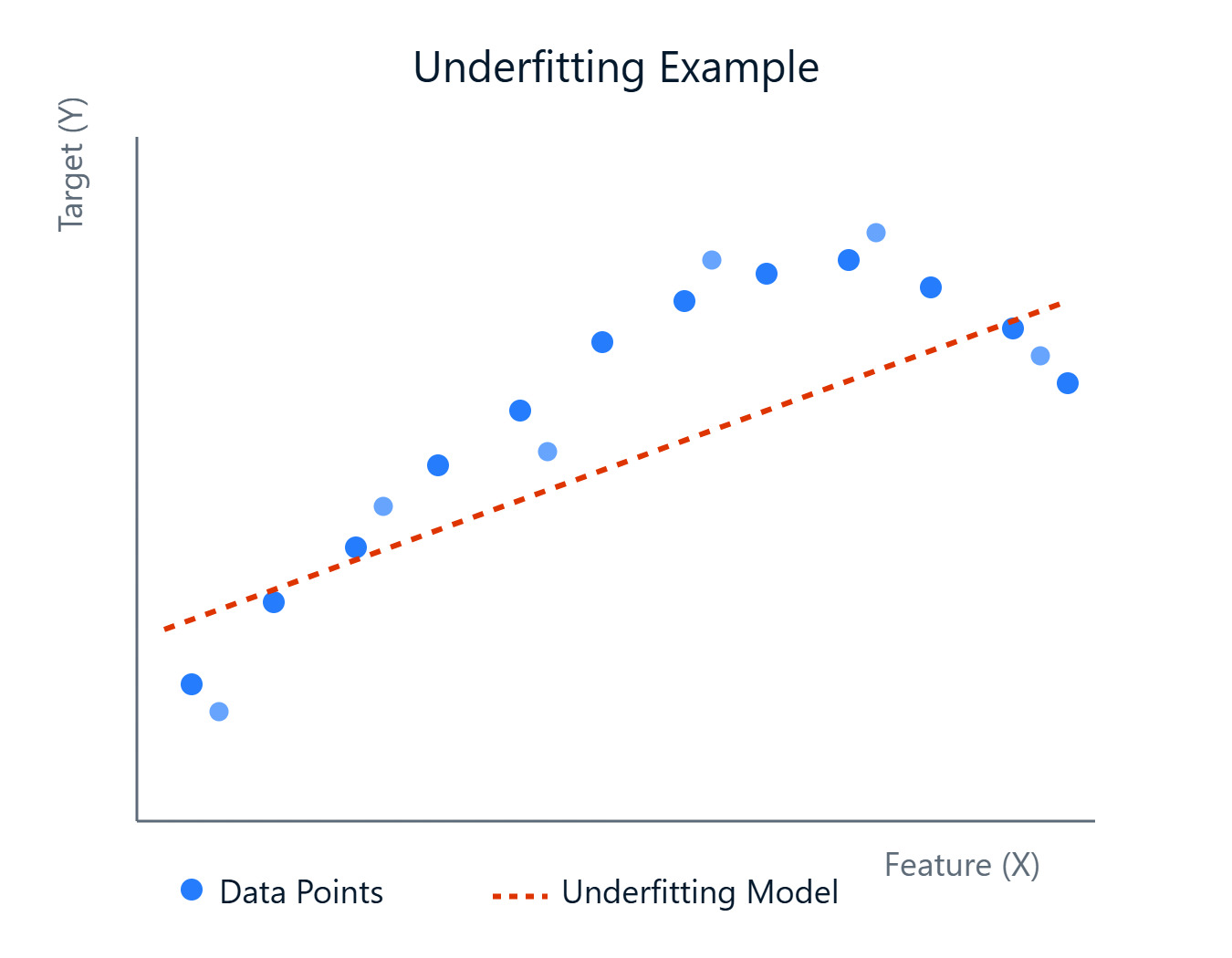
Imagem do autor
Neste artigo, daremos uma olhada no que é subajuste, por que ele ocorre, como identificá-lo e, o mais importante, como corrigi-lo. Você pode ver o que é subajuste, por que ele ocorre, como identificá-lo e, o mais importante, como corrigi-lo. Se você deseja colocar a mão na massa com o machine learning, não deixe de conferir nosso programa Fundamentos de machine learning em Python.
Vamos dar uma olhada mais profunda no conceito de subajuste e como ele contrasta com sua contraparte, o superajuste. Entender essa distinção é fundamental para o diagnóstico e o aprimoramento do modelo.
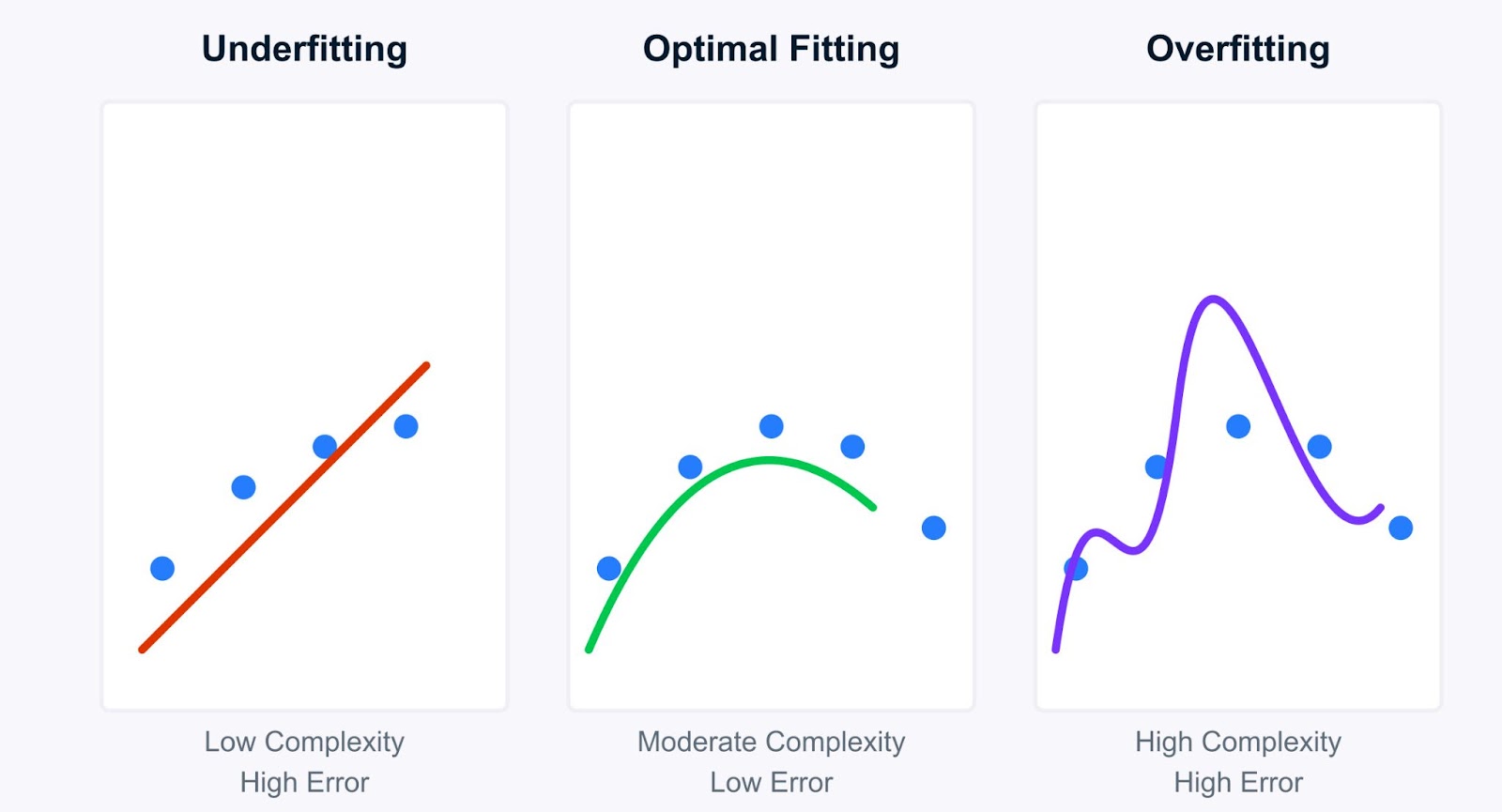
Imagem do autor
Em termos simples, o subajuste ocorre quando um modelo de machine learning é simples demais para capturar os padrões subjacentes nos dados de treinamento. Imagine você tentando ajustar uma linha reta através de pontos de dados que claramente seguem uma curva, e a linha (nosso modelo) simplesmente não é complexa o suficiente. Um modelo de subajuste sofre de alta tendência, o que significa que ele faz suposições fortes sobre os dados (por exemplo, supor uma relação linear quando não existe).
Como ele não consegue aprender bem os dados, seu desempenho é ruim não apenas nos dados de treinamento, mas também em dados novos e não vistos (dados de teste). No entanto, esses modelos tendem a ter baixa variância, o que significa que suas previsões não mudam muito se você treiná-los em diferentes subconjuntos de dados. A simplicidade os torna consistentes, embora consistentemente errados.
Matematicamente, isso está relacionado à decomposição da variância de viés do erro esperado do modelo. O erro esperado de um modelo pode ser dividido em três componentes: viés ao quadrado, variância e erro irredutível:
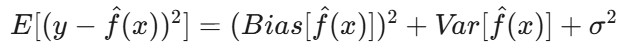
Onde:
E[(y - f̂(x))²] é o erro quadrático esperado da previsão.Bias(f̂(x)) mede o erro introduzido pela aproximação da função real f(x) com o modelo.
Var(f̂(x)) é a variabilidade da previsão do modelo para diferentes conjuntos de dados de treinamento.
σ² representa o erro irredutível - o ruído inerente nos dados que não pode ser previsto.
Na subadaptação, o termoBias(f̂(x)) domina o erro. O modelo é simples demais, o que leva a erros sistemáticos e à incapacidade de capturar a verdadeira relação entre os dados.
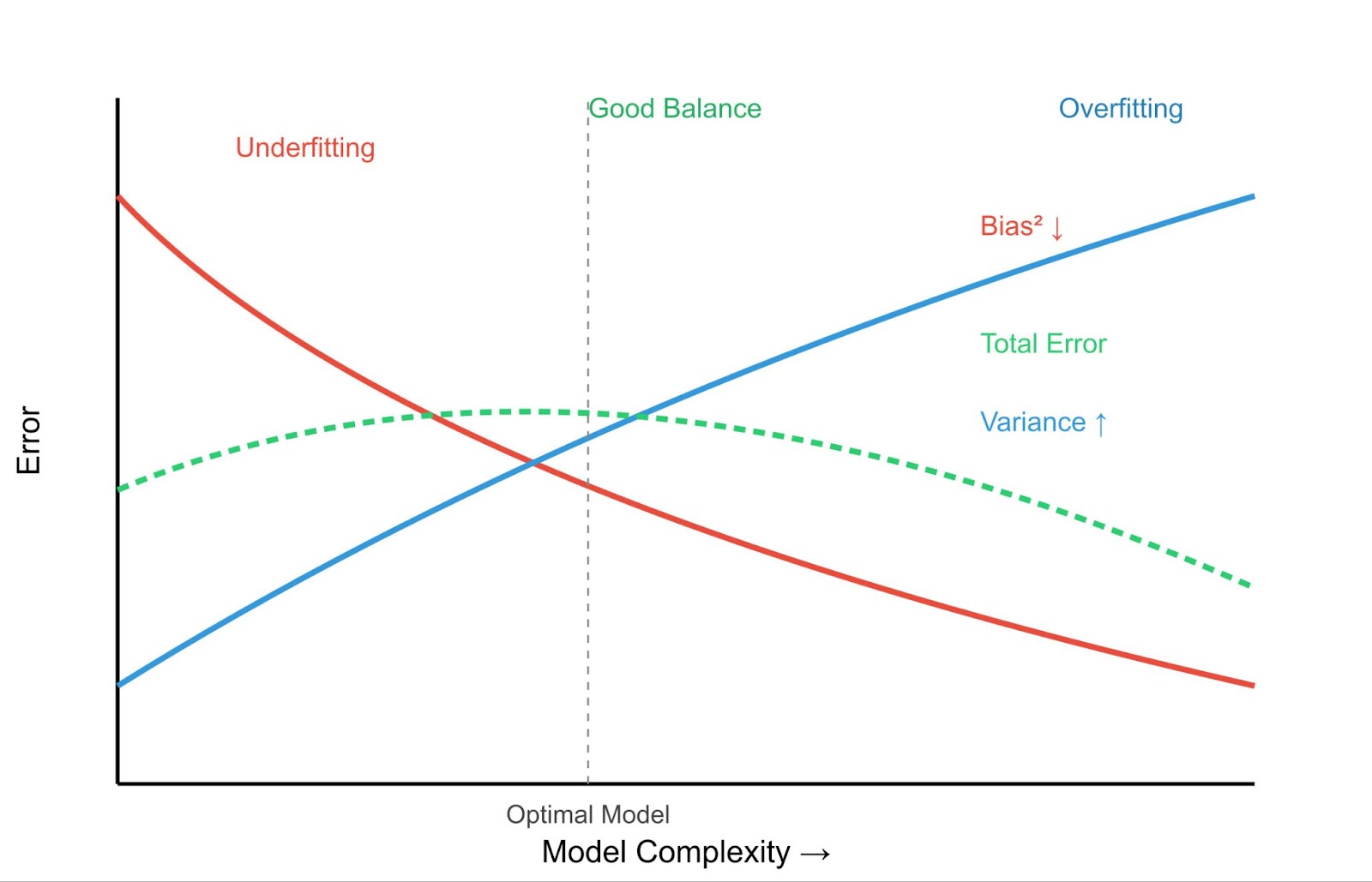
A compreensão do subajuste fica mais clara quando comparada ao superajuste. Enquanto os modelos com ajuste insuficiente são muito simples, os modelos com ajuste excessivo são muito complexos. Eles aprendem os dados de treinamento muito bem, capturando não apenas os padrões subjacentes, mas também o ruído e as flutuações aleatórias.
Compensação de variância de viés - Imagem do autor
Vejamos as principais diferenças entre subajuste e sobreajuste:
|
Característica |
Ajuste insuficiente |
Ajuste excessivo |
|
Erro de treinamento |
Alta |
Muito baixo |
|
Erro de teste |
Alta |
Alta |
|
Complexidade do modelo |
Baixa |
Alta |
|
Comportamento de previsão |
Consistente, mas impreciso |
Precisão nos dados de treinamento, mas baixa nos novos dados |
Isso leva ao conceito crucial da compensação entre viés e variância.
O objetivo é encontrar um ponto ideal: um modelo complexo o suficiente para capturar os padrões verdadeiros (baixa tendência), mas não tão complexo que aprenda o ruído (baixa variação).
Exemplos:
Entender onde o seu modelo se enquadra nesse espectro é importante para o desenvolvimento de soluções eficazes de machine learning, como veremos nas seções a seguir sobre como detectar e lidar com o subajuste.
Agora que entendemos o que é subajuste, vamos ver por que ele acontece e como você pode detectá-lo em seus próprios projetos. Identificar a causa raiz é essencial para que você escolha a estratégia de mitigação correta.
Vários fatores podem levar a um modelo com ajuste insuficiente:
O algoritmo escolhido pode ser simples demais para a estrutura subjacente dos dados. Por exemplo, usar um modelo de regressão linear quando a relação entre os recursos e a variável-alvo é altamente não linear. O modelo não tem, inerentemente, a capacidade de capturar as complexidades.
O modelo pode não ter sido treinado por tempo suficiente (por exemplo, poucas épocas em redes neurais) ou com parâmetros de aprendizagem adequados. Se o processo de treinamento for interrompido prematuramente, o modelo não terá tido oportunidade suficiente para aprender os padrões, mesmo que tenha capacidade para isso.
Os recursos usados para treinar o modelo podem não representar adequadamente os fatores subjacentes que influenciam a variável-alvo. Isso pode significar:
As técnicas de regularização (como as penalidades L1 ou L2) são usadas principalmente para evitar o ajuste excessivo, adicionando uma penalidade para a complexidade. No entanto, se a força da regularização (por exemplo, o parâmetro lambda) for definida como muito alta, ela poderá penalizar excessivamente o modelo, forçando-o a se tornar muito simples e, portanto, causando subajuste. Saiba mais sobre regularização em Towards Preventing Overfitting in Machine Learning: Regularização.
Como você pode saber se o seu modelo está subajustado? Aqui estão algumas técnicas comuns de diagnóstico:
O indicador mais direto é o desempenho ruim em ambos os conjuntos de treinamento e de validação/teste. Se o seu modelo obtiver um erro alto (ou baixa precisão, baixo R-quadrado, etc.) nos dados em que foi treinado, é um forte sinal de que ele não aprendeu os padrões de forma eficaz. Ao contrário do superajuste, em que o desempenho do treinamento é excelente, mas o desempenho do teste é ruim, o subajuste mostra um desempenho ruim em todos os aspectos.
A representação gráfica do desempenho do modelo (por exemplo, erro ou precisão) nos conjuntos de treinamento e validação em função do tempo de treinamento ou do tamanho do conjunto de dados pode ser muito esclarecedora. Para um modelo de subajuste, as curvas de aprendizado normalmente mostram:
Analise os recursos usados. Eles são relevantes? Há alguma interação que você não tenha capturado? Os recursos numéricos são dimensionados? Os recursos categóricos são codificados adequadamente?
Às vezes, revisitar a engenharia de recursos pode revelar por que o modelo está com problemas. Os conceitos básicos são abordados em Fundamentos de machine learning em R. Para obter insights mais profundos sobre as relações estatísticas, considere recursos como Inferência estatística em R.
Treine um modelo mais complexo (por exemplo, uma árvore de decisão ou uma máquina de aumento de gradiente se você tiver usado inicialmente a regressão linear) com os mesmos dados. Se o modelo mais complexo superar significativamente o modelo inicial nos conjuntos de treinamento e validação, isso sugere que o modelo original provavelmente estava subajustado devido à complexidade insuficiente.
Você pode acompanhar essas comparações usando as ferramentas discutidas em Machine Learning Experimentation: Uma introdução aos pesos e vieses.
Ao compreender essas causas e métodos de detecção, você pode diagnosticar com eficácia um modelo com ajuste insuficiente e tomar medidas para melhorar seu desempenho.
Depois que você identificar o subajuste, a próxima etapa é saber como corrigi-lo. Felizmente, várias estratégias eficazes podem ajudar a aumentar a capacidade do seu modelo de aprender os padrões subjacentes nos dados. Vamos dar uma olhada em alguns deles:
Se o seu modelo for muito simples (alta tendência), torná-lo mais complexo pode, muitas vezes, resolver o problema da falta de ajuste. Você pode fazer isso das seguintes maneiras:
Mude para um modelo mais potente. Se a regressão linear não estiver se ajustando bem, tente a regressão polinomial, árvores de decisão, florestas aleatórias, máquinas de aumento de gradiente (como o XGBoost ou LightGBM) ou máquinas de vetores de suporte (SVMs) com núcleos não lineares. Esses modelos têm inerentemente mais capacidade de capturar relacionamentos complexos.
Para problemas de regressão, você pode criar recursos polinomiais a partir dos recursos numéricos existentes. Isso permite que os modelos lineares se ajustem a relações mais complexas e curvas. Por exemplo, se você tiver um recurso x, poderá adicionar x2, x3, etc., como novos recursos. O Scikit-learn fornece PolynomialFeatures para isso.
Muitos modelos complexos têm hiperparâmetros que controlam sua complexidade (por exemplo, a profundidade de uma árvore de decisão, o número de neurônios em uma camada de rede neural, o parâmetro C em SVMs). O ajuste desses hiperparâmetros para permitir maior complexidade pode reduzir a tendência.
Técnicas como Grid Search ou Randomized Search são essenciais aqui. Saiba mais com cursos como Ajuste de hiperparâmetros em Python ou Ajuste de hiperparâmetros em R. Consulte também nosso tutorial sobre Otimização de hiperparâmetros em modelos de machine learning.
Às vezes, o modelo não é o problema, mas sim a representação dos dados. Melhorar os recursos pode ajudar significativamente. Podemos fazer isso das seguintes maneiras:
Use seu conhecimento sobre o domínio do problema para criar novos recursos que possam ser mais informativos. Por exemplo, na previsão de preços de casas, combinando "número de quartos" e "número de banheiros" em um recurso de "total de cômodos", ou calculando a "idade da casa" a partir do "ano de construção".
Crie recursos que representem a interação entre os recursos existentes (por exemplo, multiplicar dois recursos). Isso pode ajudar os modelos a capturar efeitos sinérgicos.
Aumente seu conjunto de dados com fontes de dados externas, se possível. Por exemplo, adicionar dados demográficos às informações do cliente ou dados meteorológicos às previsões de vendas.
No caso de dados de imagem ou texto, técnicas como girar/virar imagens ou usar substituição de sinônimos no texto podem aumentar artificialmente o tamanho e a diversidade do conjunto de treinamento, o que pode ajudar o modelo a aprender padrões mais robustos.
Se a subadaptação for causada por uma regularização excessiva destinada a evitar a subadaptação, você precisará reduzi-la. Diminua o valor do parâmetro de regularização (por exemplo, alfa em Ridge/Lasso, C em SVMs - observe que, para SVMs, um C menor significa uma regularização mais forte, portanto, você deve aumentar C).
Se estiver usando o abandono, reduza a taxa de abandono (a fração de neurônios abandonados durante o treinamento). Uma taxa mais baixa retém mais capacidade de rede.
Encontrar o equilíbrio certo geralmente requer um ajuste cuidadoso, destacando novamente a importância da otimização dos hiperparâmetros.
Os métodos de conjunto combinam previsões de vários modelos individuais (alunos fracos) para produzir uma previsão final mais forte e mais robusta. Em geral, eles são muito eficazes para reduzir a tendência e a variação. Alguns dos métodos de conjunto são os seguintes:
Ao aplicar essas estratégias, muitas vezes combinadas, você pode lidar efetivamente com o subajuste e criar modelos que capturem melhor as complexidades dos seus dados.
Ver o underfitting em ação com conjuntos de dados e código pode esclarecer significativamente o conceito. Vamos examinar exemplos práticos para demonstrar como um modelo de subajuste se comporta e como seu desempenho pode ser aprimorado.
Um cenário comum de subadaptação ocorre quando um modelo linear simples é usado para descrever uma relação não linear. Vamos ilustrar isso tentando ajustar um modelo de regressão linear aos dados que seguem um padrão quadrático.
Vamos gerar dados sintéticos em que a variável-alvo y tem uma relação quadrática com um recurso X. Primeiro, ajustaremos um modelo de regressão linear simples. Observaremos seu baixo desempenho (alto erro quadrático médio - MSE) e visualizaremos como ele não consegue capturar a curva dos dados.
Em seguida, expandiremos os recursos adicionando um termo polinomial e ajustaremos um modelo de regressão polinomial. Isso demonstrará como o aumento da complexidade do modelo pode reduzir a tendência e melhorar significativamente a precisão do modelo.
Vamos começar importando as bibliotecas necessárias da seguinte forma:
# Import necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_squared_errorVamos gerar dados sintéticos não lineares. Criaremos dados com uma relação quadrática: y = 0,5*X^2 + X + 2 + ruído.
np.random.seed(42) # for reproducibility
num_samples = 100
X = np.sort(10 * np.random.rand(num_samples, 1) - 5, axis=0) # Feature X (sorted for plotting)
y_true = 0.5 * X**2 + X + 2 # True quadratic relationship
y = y_true + np.random.randn(num_samples, 1) * 5 # Add some noise to make it realisticAgora, ajustaremos um modelo de regressão linear simples (Underfitting Model), conforme mostrado abaixo:
linear_model = LinearRegression()
linear_model.fit(X, y)
y_pred_linear = linear_model.predict(X)
mse_linear = mean_squared_error(y, y_pred_linear)
print(f"--- Simple Linear Regression (Potential Underfitting Model) ---")
print(f"Mean Squared Error (MSE): {mse_linear:.2f}")
print(f"Model Coefficients (slope): {linear_model.coef_[0][0]:.2f}")
print(f"Model Intercept: {linear_model.intercept_[0]:.2f}")Saída:
--- Simple Linear Regression (Potential Underfitting Model) ---
Mean Squared Error (MSE): 34.03
Model Coefficients (slope): 1.00
Model Intercept: 6.42Agora, ajustaremos um modelo de regressão polinomial (modelo aprimorado). Para fazer isso, criamos recursos polinomiais (grau 2) e, em seguida, ajustamos um modelo linear a esses recursos. A etapa PolynomialFeatures adiciona novos recursos. A etapa LinearRegression tem coeficientes para cada um deles.
Para o grau 2, esperamos coeficientes para X e X^2. Um pipeline torna esse processo mais limpo. O atributo named_steps do pipeline permite o acesso a etapas individuais, conforme mostrado abaixo:
polynomial_model = make_pipeline(PolynomialFeatures(degree=2, include_bias=False), LinearRegression())
polynomial_model.fit(X, y)
y_pred_poly = polynomial_model.predict(X)
mse_poly = mean_squared_error(y, y_pred_poly)
print(f"\n--- Polynomial Regression (Degree 2) ---")
print(f"Mean Squared Error (MSE): {mse_poly:.2f}")
poly_reg_coeffs = polynomial_model.named_steps['linearregression'].coef_[0]
poly_reg_intercept = polynomial_model.named_steps['linearregression'].intercept_[0]
print(f"Model Coefficients (for X, X^2): {poly_reg_coeffs[0]:.2f}, {poly_reg_coeffs[1]:.2f}")
print(f"Model Intercept: {poly_reg_intercept:.2f}")Saída:
--- Polynomial Regression (Degree 2) ---
Mean Squared Error (MSE): 20.48
Model Coefficients (for X, X^2): 1.13, 0.50
Model Intercept: 2.04Agora vamos visualizar o ajuste do modelo conforme mostrado abaixo:
# Visualization
plt.figure(figsize=(10, 4))
plt.scatter(X, y, s=30, label="Actual Data Points", alpha=0.7, edgecolors='k')
plt.plot(X, y_pred_linear, color='red', linewidth=2, label=f'Linear Fit (Underfitting)\nMSE: {mse_linear:.2f}')
plt.plot(X, y_pred_poly, color='green', linewidth=2, label=f'Polynomial Fit (Degree 2)\nMSE: {mse_poly:.2f}')
plt.title('Demonstrating Underfitting with Linear vs. Polynomial Regression', fontsize=16)
plt.xlabel('Feature X', fontsize=14)
plt.ylabel('Target y', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()Saída:
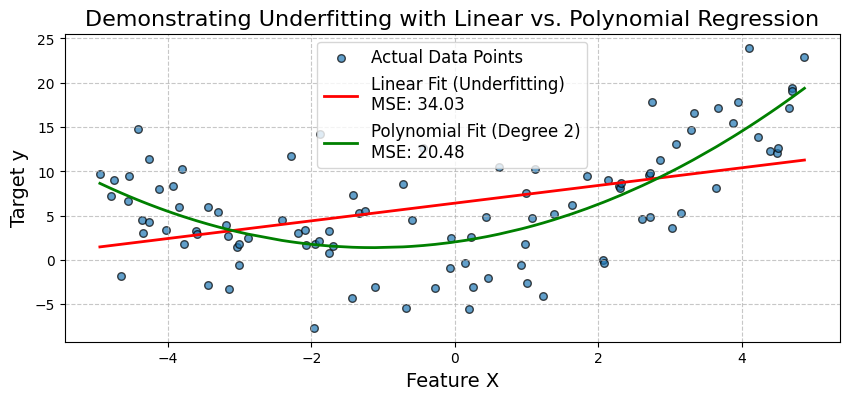
O gráfico confirma visualmente a falta de ajuste do modelo linear simples. Ele não consegue capturar a curva nos dados. O modelo de regressão polinomial, ao incorporar o termo X^2, proporciona um ajuste muito melhor, conforme evidenciado por seu menor MSE.
Isso mostra como a expansão dos recursos (aumento da complexidade do modelo) pode reduzir a tendência e melhorar a precisão quando a relação subjacente é não linear. A seguir, vamos examinar um estudo de caso de diagnóstico médico.
Vamos simular um cenário de diagnóstico médico usando o conhecido conjunto de dados Breast Cancer Wisconsin (Diagnostic) disponível em scikit-learn.
Primeiro, tentaremos criar um modelo de classificação usando apenas um subconjunto muito limitado de recursos, o que pode levar a uma subadaptação. Em seguida, usaremos um conjunto mais abrangente de recursos e, possivelmente, um algoritmo mais complexo para demonstrar o aprimoramento.
Vamos começar importando as bibliotecas necessárias da seguinte forma:
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix, ConfusionMatrixDisplayAgora, vamos carregar e preparar os dados:
cancer = load_breast_cancer()
X = pd.DataFrame(cancer.data, columns=cancer.feature_names)
y = cancer.target # 0 for malignant, 1 for benignPara fins de demonstração, vamos selecionar um subconjunto muito limitado de recursos para o cenário de subajuste. Esses podem não ser os mais preditivos por si só:
features_limited = ['mean texture', 'mean symmetry']
X_limited = X[features_limited]Para o modelo aprimorado, usaremos um subconjunto maior (ou todos os recursos). Vamos escolher os 10 primeiros recursos para que você tenha um conjunto mais abrangente:
features_comprehensive = cancer.feature_names[:10]
X_comprehensive = X[features_comprehensive]Vamos dividir os dados. Para maior clareza, faremos isso separadamente para cada conjunto de recursos:
X_train_lim, X_test_lim, y_train, y_test = train_test_split(X_limited, y, test_size=0.3, random_state=42, stratify=y)
X_train_comp, X_test_comp, _, _ = train_test_split(X_comprehensive, y, test_size=0.3, random_state=42, stratify=y) # y_train and y_test are the sameVamos dimensionar os recursos, pois isso é importante para a regressão logística e muitos outros algoritmos:
scaler_lim = StandardScaler().fit(X_train_lim)
X_train_lim_scaled = scaler_lim.transform(X_train_lim)
X_test_lim_scaled = scaler_lim.transform(X_test_lim)
scaler_comp = StandardScaler().fit(X_train_comp)
X_train_comp_scaled = scaler_comp.transform(X_train_comp)
X_test_comp_scaled = scaler_comp.transform(X_test_comp)Agora, vamos ajustar uma regressão logística com recursos limitados:
print("Scenario 1: Logistic Regression (Limited Features - Potential Underfitting)")
log_reg_limited = LogisticRegression(random_state=42, solver='liblinear') # liblinear is good for small datasets
log_reg_limited.fit(X_train_lim_scaled, y_train)
y_pred_lim = log_reg_limited.predict(X_test_lim_scaled)
y_proba_lim = log_reg_limited.predict_proba(X_test_lim_scaled)[:, 1]
acc_lim = accuracy_score(y_test, y_pred_lim)
auc_lim = roc_auc_score(y_test, y_proba_lim)
print(f"Features used: {features_limited}")
print(f"Accuracy: {acc_lim:.4f}")
print(f"AUC: {auc_lim:.4f}")Saída:
Scenario 1: Logistic Regression (Limited Features - Potential Underfitting)
Features used: ['mean texture', 'mean symmetry']
Accuracy: 0.7544
AUC: 0.8151Vamos adotar uma estratégia de mitigação. Vamos ajustar um modelo de regressão logística com mais recursos:
print("Scenario 2: Logistic Regression (Comprehensive Features)")
log_reg_comp = LogisticRegression(random_state=42, solver='liblinear')
log_reg_comp.fit(X_train_comp_scaled, y_train)
y_pred_comp_lr = log_reg_comp.predict(X_test_comp_scaled)
y_proba_comp_lr = log_reg_comp.predict_proba(X_test_comp_scaled)[:, 1]
acc_comp_lr = accuracy_score(y_test, y_pred_comp_lr)
auc_comp_lr = roc_auc_score(y_test, y_proba_comp_lr)
print(f"Features used: First 10 features") # For brevity
print(f"Accuracy: {acc_comp_lr:.4f}")
print(f"AUC: {auc_comp_lr:.4f}")Saída:
Scenario 2: Logistic Regression (Comprehensive Features)
Features used: First 10 features
Accuracy: 0.9181
AUC: 0.9831Agora, vamos ajustar um modelo mais complexo, como o Random Forest, com mais recursos:
print("Scenario 3: Random Forest (Comprehensive Features)")
rf_comp = RandomForestClassifier(random_state=42, n_estimators=100) # n_estimators is a key hyperparameter
rf_comp.fit(X_train_comp_scaled, y_train) # RF can also benefit from scaled data, though less sensitive
y_pred_comp_rf = rf_comp.predict(X_test_comp_scaled)
y_proba_comp_rf = rf_comp.predict_proba(X_test_comp_scaled)[:, 1]
acc_comp_rf = accuracy_score(y_test, y_pred_comp_rf)
auc_comp_rf = roc_auc_score(y_test, y_proba_comp_rf)
print(f"Features used: First 10 features")
print(f"Accuracy: {acc_comp_rf:.4f}")
print(f"AUC: {auc_comp_rf:.4f}")Saída:
Scenario 3: Random Forest (Comprehensive Features)
Features used: First 10 features
Accuracy: 0.9415
AUC: 0.9878Vamos plotar e comparar a matriz de confusão para cada caso:
fig, axes = plt.subplots(1, 3, figsize=(20, 5))
fig.suptitle('Comparison of Model Performance (Confusion Matrices on Test Set)', fontsize=16)
# Model 1: Logistic Regression (Limited Features)
cm_lim = confusion_matrix(y_test, y_pred_lim)
disp_lim = ConfusionMatrixDisplay(confusion_matrix=cm_lim, display_labels=cancer.target_names)
disp_lim.plot(ax=axes[0], cmap='Blues')
axes[0].set_title(f'LogReg (Limited Features)\nAcc: {acc_lim:.2f}, AUC: {auc_lim:.2f}')
# Model 2: Logistic Regression (Comprehensive Features)
cm_comp_lr = confusion_matrix(y_test, y_pred_comp_lr)
disp_comp_lr = ConfusionMatrixDisplay(confusion_matrix=cm_comp_lr, display_labels=cancer.target_names)
disp_comp_lr.plot(ax=axes[1], cmap='Greens')
axes[1].set_title(f'LogReg (Comprehensive Features)\nAcc: {acc_comp_lr:.2f}, AUC: {auc_comp_lr:.2f}')
# Model 3: Random Forest (Comprehensive Features)
cm_comp_rf = confusion_matrix(y_test, y_pred_comp_rf)
disp_comp_rf = ConfusionMatrixDisplay(confusion_matrix=cm_comp_rf, display_labels=cancer.target_names)
disp_comp_rf.plot(ax=axes[2], cmap='Oranges')
axes[2].set_title(f'Random Forest (Comprehensive Features)\nAcc: {acc_comp_rf:.2f}, AUC: {auc_comp_rf:.2f}')
plt.tight_layout(rect=[0, 0, 1, 0.96]) # Adjust layout to make space for suptitle
plt.show()Saída:
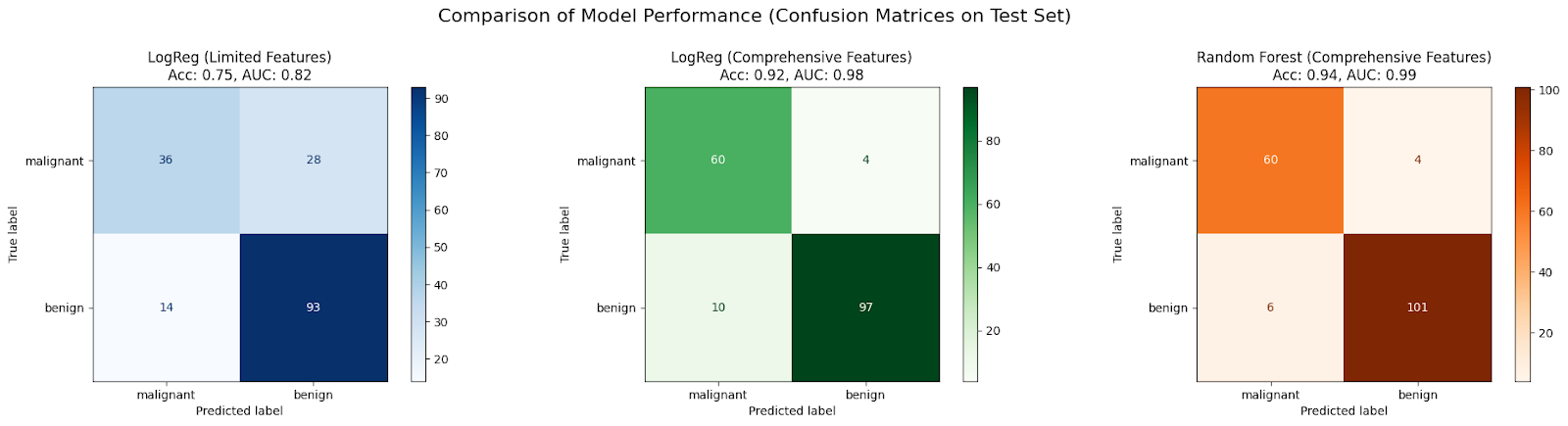
Neste estudo de caso, espera-se que um modelo inicial do LogisticRegression treinado com apenas dois recursos (Cenário 1) não seja adequado devido a informações insuficientes, resultando em baixa precisão e AUC.
Normalmente, o desempenho melhora quando o mesmo algoritmo recebe um conjunto mais abrangente de recursos (Cenário 2), pois ele tem mais dados para aprender, reduzindo a tendência.
Muitas vezes, você pode observar melhorias adicionais ao usar um algoritmo mais complexo, como o RandomForestClassifier, com o conjunto abrangente de recursos (Cenário 3), porque ele pode capturar não linearidades e interações de recursos de forma mais eficaz, reduzindo ainda mais a distorção e aprimorando o ajuste do modelo aos dados.
Embora tenhamos abordado os fundamentos, o cenário do machine learning está sempre evoluindo. Aqui está uma breve visão de como o subajuste se relaciona com áreas mais avançadas.
Os modelos de aprendizagem profunda, especialmente as redes neurais profundas com muitas camadas, são conhecidos por sua alta capacidade, o que significa que, teoricamente, podem aproximar funções muito complexas.
Devido à sua complexidade inerente, os modelos de aprendizagem profunda geralmente são menos propensos a subajustes do que os modelos mais simples, desde que sejam treinados adequadamente com dados suficientes. Sua estrutura permite que eles aprendam automaticamente representações complexas de recursos a partir de dados brutos (como pixels em imagens ou palavras em textos).
No entanto, a aprendizagem profunda não está imune a problemas que parecem ser de subajuste. Se uma rede for mal projetada (por exemplo, profundidade/largura insuficiente para a tarefa), não for treinada por tempo suficiente ou usar funções de ativação ou algoritmos de otimização inadequados, ela ainda poderá não convergir e apresentar um alto erro de treinamento.
Inovações arquitetônicas, como conexões residuais (ResNets) e técnicas de normalização (Batch Normalization), ajudam a treinar redes muito profundas de forma eficaz, atenuando os problemas de gradiente de desaparecimento/explodimento e permitindo que elas atinjam sua capacidade total, evitando assim problemas de convergência que imitam o subajuste.
Encontrar o modelo, os recursos e os hiperparâmetros corretos para evitar tanto o subajuste quanto o superajuste pode consumir muito tempo. O AutoML tem o objetivo de automatizar esse processo.
As estruturas do AutoML podem explorar automaticamente diferentes tipos de modelos (de modelos lineares a conjuntos complexos e redes neurais), executar engenharia e seleção de recursos e otimizar hiperparâmetros. Ao pesquisar sistematicamente um vasto espaço de possibilidades, o AutoML pode identificar configurações de modelos que tenham complexidade suficiente para evitar a subadaptação dos dados.
Métodos como o Neural Architecture Search (NAS) projetam automaticamente arquiteturas de rede, enquanto técnicas sofisticadas de otimização de hiperparâmetros (por exemplo, otimização bayesiana) encontram com eficiência boas configurações de hiperparâmetros. Essas ferramentas podem acelerar significativamente o processo de encontrar um modelo bem ajustado, reduzindo o esforço manual necessário para diagnosticar e corrigir um modelo mal ajustado.
Para que você tenha sucesso no machine learning, é fundamental entender o dilema underfitting vs overfitting. Vimos que a subadaptação ocorre quando um modelo é simples demais (alta polarização) para capturar as tendências subjacentes nos dados, o que leva a um desempenho ruim nos dados de treinamento e nos dados não vistos. As principais causas incluem complexidade insuficiente do modelo, recursos ruins, treinamento inadequado e regularização excessiva.
O diagnóstico de subajuste envolve examinar as métricas de desempenho, traçar curvas de aprendizado e comparar modelos, muitas vezes com o auxílio de código. Felizmente, temos várias estratégias para corrigir o subajuste: aumento da complexidade do modelo (escolha de melhores algoritmos, expansão de recursos, ajuste de hiperparâmetros), aprimoramento de recursos (engenharia de recursos, enriquecimento de dados), ajuste da regularização e emprego de métodos de conjunto avançados, conforme demonstrado em nossos exemplos de código.
Para saber mais sobre essas técnicas e outras com exemplos práticos, confira nosso programa de habilidades Fundamentos de machine learning em Python.
Principais cursos de machine learning
Programa
Programa
Curso
blog
Abid Ali Awan
7 min
blog
Abid Ali Awan
5 min
blog
Matt Crabtree
14 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer


