
Track
Developing AI Applications
21 hr
As a Gen AI Engineer, I make it a priority to stay updated with the latest tools and technologies by continuously reading and exploring new advancements. Recently, I came across a research paper by Microsoft researchers introducing BridgeTower, a model that simplifies the integration of vision and language capabilities, making multimodal tasks much easier to implement.
In this guide, I’ll show you how to build a simple yet powerful image-text retrieval system using BridgeTower from the Hugging Face Transformers library. This tutorial is designed to be beginner-friendly and will walk you through the following steps:
By the end of this tutorial, you’ll have a fully functional system that can effectively match images with text queries, demonstrating the power and simplicity of multimodal AI.
The BridgeTower model, as explained in the paper BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning by Xiao Xu and others, aims to improve how vision and language models work together.
Imagine a task where the model needs to understand both an image and a text description, such as "a dog running in a park."
Typically, the model would process the image and text separately using vision and language encoders. The BridgeTower model adds a "bridge" between these encoders and the cross-modal encoder (which combines both vision and language), allowing them to interact better at each step.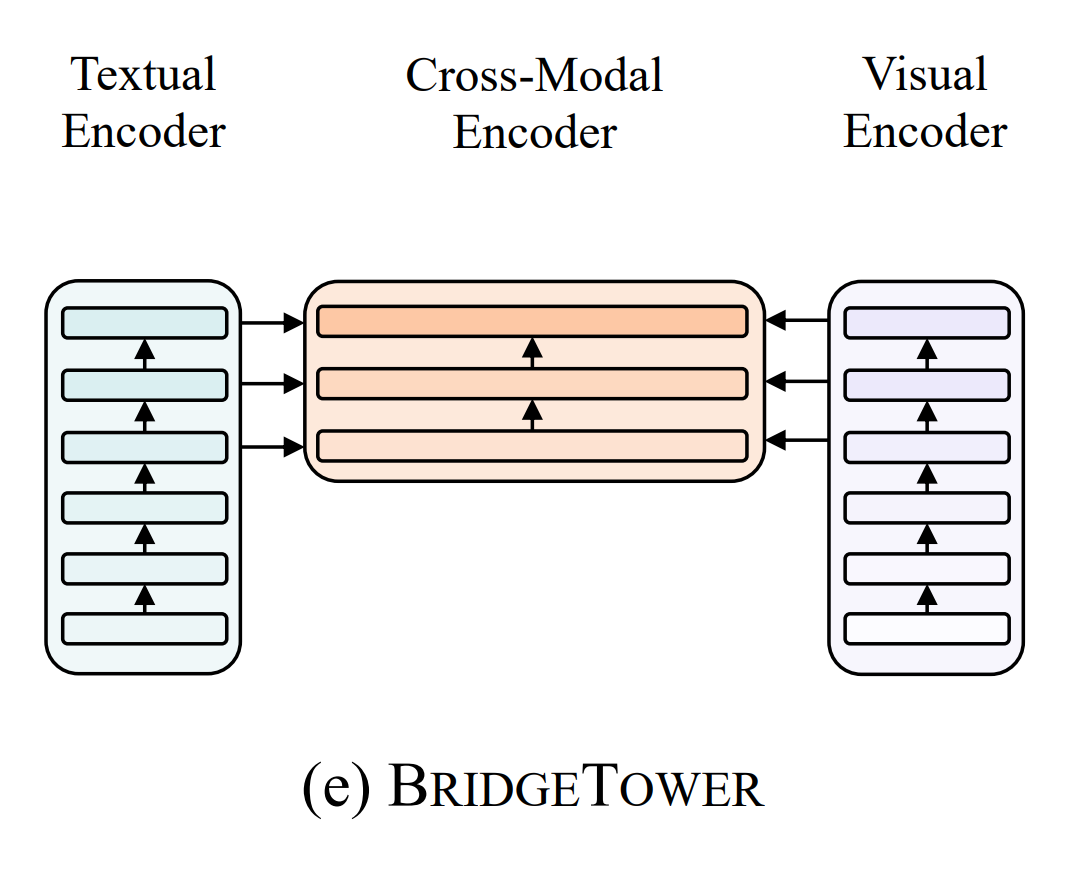
For example, while processing the image of the dog, the vision encoder might detect the dog’s shape and movement. Meanwhile, the language encoder understands the text "running" and "dog."
The bridge allows these two pieces of information to interact in detail, helping the model connect the visual and textual clues more effectively. This way, the model performs better in tasks like image captioning or question answering, without needing a lot of extra computation or slowing down.
We’ll keep things clean and organized. Your project directory should look like this:
/image-search-app/
│
├── app.py # Frontend (Streamlit UI)
├── search.py # Backend logic (embeddings & similarity search)
├── images/ # Directory for uploaded images
│ ├── image1.jpg
│ ├── image2.png
│ ├── image3.jpeg
│
└── requirements.txt # Python dependenciesBefore diving into the code, let’s set up the environment to ensure a smooth development and testing process. Follow these steps:
First, ensure you have Python installed (version 3.7 or higher is recommended). Then, run the following command in your terminal to install the necessary libraries:
pip install torch transformers streamlit PillowTo test the application, place some sample images in the /images directory. Make sure these images are in supported formats such as JPG, PNG, or JPEG, as these are universally recognized and compatible with most libraries.
Use a variety of images to ensure the model can accurately retrieve matches based on the text query.
The core functionality of the application is divided into two main components: the Backend (search.py) and the Frontend (app.py). Each component plays a crucial role in ensuring the app operates seamlessly.
This file contains the logic for text and image embeddings and the search mechanism.
from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
from PIL import Image
import torch.nn.functional as F
import osprocessor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)This initializes the model and processor required for embeddings.
def image_search(query, image_dir):
image_files = [os.path.join(image_dir, img) for img in os.listdir(image_dir) if img.lower().endswith(('jpg', 'jpeg', 'png'))]
scores = {}
for img_path in image_files:
image = Image.open(img_path).convert("RGB")
encoding = processor(text=query, images=image, return_tensors="pt").to(device)
outputs = model(**encoding)
scores[img_path] = outputs.logits[0, 1].item()
best_match = max(scores, key=scores.get)
return best_matchHow it works:
This file uses Streamlit to provide a user-friendly interface.
import streamlit as st
from search import search_best_match
import osst.title("🖼️ AI-Powered Image Search App")
uploaded_files = st.file_uploader("Upload images", accept_multiple_files=True, type=['jpg', 'jpeg', 'png'])
image_folder = 'images'
os.makedirs(image_folder, exist_ok=True)
if uploaded_files:
for uploaded_file in uploaded_files:
with open(os.path.join(image_folder, uploaded_file.name), 'wb') as f:
f.write(uploaded_file.getbuffer())
st.image(uploaded_file, caption="Uploaded Image", use_column_width=True)Users can upload multiple images. Images are saved in the images/ folder and displayed.
query = st.text_input("Enter your search query:")
if query and uploaded_files:
best_match, score = search_best_match(image_folder, query)
st.write("### Most Relevant Image:")
st.image(best_match, caption=f"Score: {score:.4f}", use_column_width=True)Users enter a search query. The app searches for the best-matching image and displays it.
from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
from PIL import Image
import torch
import torch.nn.functional as F
import os
# Load Bridgetower processor and model
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
# Search for the best matching image
def image_search(query, image_dir):
image_files = [os.path.join(image_dir, img) for img in os.listdir(image_dir) if img.lower().endswith(('jpg', 'jpeg', 'png'))]
scores = {}
for img_path in image_files:
image = Image.open(img_path).convert("RGB")
encoding = processor(text=query, images=image, return_tensors="pt").to(device)
outputs = model(**encoding)
scores[img_path] = outputs.logits[0, 1].item()
best_match = max(scores, key=scores.get)
return best_matchimport streamlit as st
from search import image_search
import os
# Title of the app
st.title("🖼️ Image Search Application with BridgeTower")
# Image upload section
uploaded_files = st.file_uploader("Upload your images", accept_multiple_files=True, type=['jpg', 'jpeg', 'png'])
# Create image folder if not exists
image_folder = 'images'
os.makedirs(image_folder, exist_ok=True)
if uploaded_files:
for uploaded_file in uploaded_files:
with open(os.path.join(image_folder, uploaded_file.name), 'wb') as f:
f.write(uploaded_file.getbuffer())
st.image(uploaded_file, caption="Uploaded Image", use_column_width=True)
# Text input for query
query = st.text_input("Enter your search query:")
# Display search results
if query and uploaded_files:
best_match, score = image_search(image_folder, query)
st.write("### Most Relevant Image:")
st.image(best_match, caption=f"Similarity Score: {score:.4f}", use_column_width=True)streamlit run app.pyHere’s an example of the app in action! An image was uploaded, and the user typed in the search query “cat.” The app quickly analyzed the image and text, then matched them using BridgeTower model.
It found the best match and displayed the correct image of a cat. This shows how well the app connects images and text to give accurate results.
Curiosity should not stop just here. The potential of applications like this goes far beyond what is currently implemented, opening up exciting opportunities for growth and innovation. The possibilities for enhancing user experience, performance, and functionality are vast. Below, I am proposing a few enhancements that can take such applications to the next level.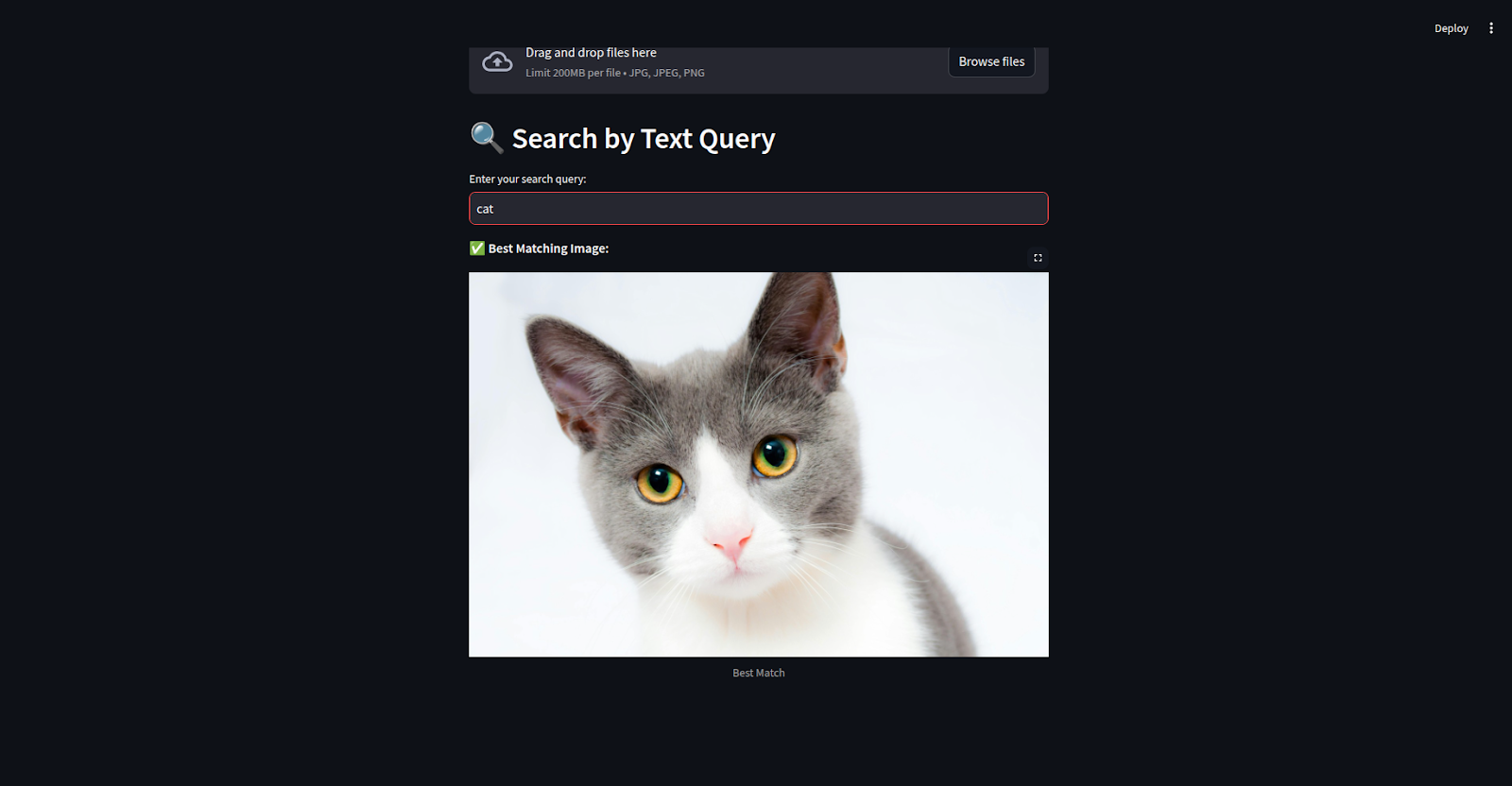
There are several ways you can enhance the app we created, for example:
Implement FAISS indexing to improve the speed of image searches in large datasets. This will allow you to convert images into feature vectors, build an index, and perform similarity searches quickly, ensuring that image retrieval remains efficient even as the dataset grows.
Deploy the app on Streamlit Cloud for a fast, easy setup, especially if you’re working with Python and Streamlit. Alternatively, deploy it on AWS for more control, scalability, and the ability to handle higher traffic, ensuring better performance as the app expands.
Set up real-time updates so that when new images are uploaded, they instantly appear for all users without needing a page refresh. Using technologies like WebSockets or Socket.IO, you can push updates to all connected users as soon as an image is uploaded, enhancing the interactivity and experience of the app.
We’ve successfully built an AI-powered image search application using Bridgetower, Streamlit, and PyTorch, showcasing how AI can simplify and enhance interactions with digital content.
While fully functional, there’s room for improvement, such as optimizing search speed with FAISS indexing, deploying on platforms like AWS for scalability, and adding real-time updates for a smoother user experience. This project is a strong foundation for further innovation in intelligent search systems.
If you’re keen to learn more, I can recommend these resources:
Top DataCamp Courses
Track
Track
Course
Tutorial
Bex Tuychiev
Tutorial
Tim Lu
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Bhavishya Pandit
code-along
Korey Stegared-Pace
code-along
Jacob Marquez


