
Course
Working with the OpenAI API
3 hr
142.5K
Ever since the release of ChatGPT in November 2022, LLM Chatbots have emerged as prominent features across many different use cases.
The idea of a chatbot is not new. We all have seen useless chatbots everywhere that have to be configured so deeply that it is almost scripted with if-and-else rules. It becomes a nightmare to maintain them, and they do not help the end-user; in fact, they do quite the opposite, frustrating end-users.
But now, in 2024, Chatbots are back, thanks to Large Language Models (LLMs).
In this blog, you will learn:
You can also check out our Vector Databases for Embeddings with Pinecone course, and the code-along on Building Chatbots with OpenAI API and Pinecone to learn more.
Large Language Models (LLMs) like GPT-4 are advanced machine learning algorithms that leverage deep learning techniques, particularly the transformer architecture, to understand and generate natural language.
They are trained on massive datasets containing trillions of words sourced from a wide range of texts available on the internet, such as books, articles, websites, and coding repositories. This extensive training enables them to perform a variety of complex tasks related to language processing.
One of the key features of LLMs is their ability to generate text on virtually any topic. This capability extends to various styles and formats, ranging from creative writing to technical documentation.
LLMs are proficient in tasks like summarization, where they can distill lengthy documents into concise summaries, and conversational AI, enabling them to engage in natural and fluent dialogue with users. They are also adept at translating text across languages, even capturing nuances like slang and regional dialects.
However, LLMs are not without challenges. One significant issue is LLMs can "hallucinate" or generate plausible but incorrect or nonsensical information, particularly when dealing with queries outside their training data or ambiguous prompts.
Another key problem is the potential for bias in LLM outputs, stemming from biases present in the training data or introduced during the model's development.
LLMs represent a significant advancement in AI, offering immense potential for innovation and efficiency in various fields, but they also require careful management to mitigate risks such as bias and misinformation
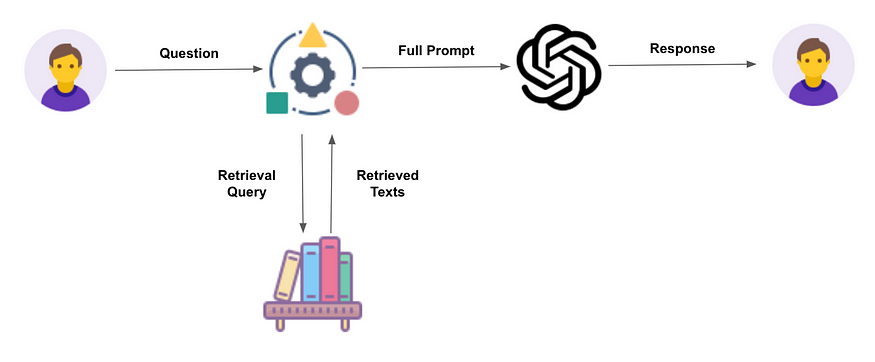
LLMs, while powerful, have certain limitations. They may provide outdated, generic, or even false information if the query extends beyond their training data scope.
They might also create factually incorrect or nonsensical information that the model presents as true or logical. This phenomenon is famously known as Hallucination.
RAG aims to mitigate these issues by directing LLMs to retrieve relevant information from predetermined sources. This approach enhances user trust, as the model's outputs are more accurate and can be attributed to reliable sources.
It also provides more control to developers over the responses generated by the LLM, improving the overall quality and applicability of the system.
You can learn more about retrieval augmented generation in our separate tutorial. However, below, we’ve outlined the main steps of the process.

Vector databases are specialized types of databases designed for handling high-dimensional vectors, which are mathematical representations of data attributes or features. These vectors can range from tens to thousands of dimensions, depending on data complexity and granularity.
This type of database is particularly adept at performing fast and accurate similarity searches and retrievals based on vector distance or similarity, enabling a more semantic or contextual data query approach rather than relying on traditional exact matches or predefined criteria.
In practical terms, vector databases can be utilized for various purposes. For instance, they can find images similar to a given image based on visual content and style, locate documents similar to a specific document based on topic and sentiment, or identify products similar to a certain product based on features and ratings.
The querying process in a vector database involves using a query vector that represents the desired information or criteria and applying a similarity measure to determine the closeness of vectors in the vector space. This process results in a ranked list of vectors with high similarity scores to the query vector, allowing access to the corresponding raw data associated with each vector.
Vector databases are powered by various algorithms, such as k-nearest neighbor (k-NN) indexes and are built with methods like the Hierarchical Navigable Small World (HNSW) and Inverted File Index (IVF) algorithms.
Vector databases are integral to retrieval augmented generation (RAG) applications. They provide efficient similarity search, content expansion, diversity, and dynamic multi-modal data retrieval. This capability is crucial in generative AI, where access to large-scale, diverse datasets is essential for reducing biases and hallucinations in AI models.
Pinecone is a popular vector database that stands out for its efficiency and ease of use, especially in handling large-scale data scenarios. It's designed for developers and data scientists seeking to implement vector search capabilities in various applications.
Pinecone employs advanced indexing techniques like product quantization and locality-sensitive hashing, enabling efficient and accurate similarity searches in high-dimensional vector spaces. This makes it particularly useful for RAG applications. You can learn more about mastering vector databases with Pinecone in our separate tutorial.
In this tutorial, we will use Pinecone as our vector database.
OpenAI's API platform provides access to all the models trained by OpenAIthat are available to the public. This includes GPT, DALL-E, Whisper, and other models.
The API is accessed via HTTP requests, so you can integrate it with any programming language that supports making HTTP requests. However, for Python, there is a library called openai that you can install with pip install openai and it will make it even easier to work with these API’s.
Working with OpenAI API in Python using openai library is just a few lines of code.
Python Example:
import os
os.environ["OPENAI_API_KEY"] = " "
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are expert in Machine Learning."},
{"role": "user", "content": "Explain how does random forest works?."}
]
)
print(completion.choices[0].message)LangChain is a framework for developing applications powered by language models. It provides a certain level of abstraction that makes it easy and fast to develop prototypes as well as go faster from prototype to production quickly. The growth and popularity of this framework is evident from the # of stars on their Github page.
It is an amazing framework. However, one caution at this point is that it is still not stable. The API keeps changing and it is also possible that by the time you are reading the code in the next section, it’s not working anymore. This is expected because the library is still in pre-release. As of writing this blog, the latest version of Langchain is 0.1.4.
To be able to implement a RAG back-end, we need embeddings of external data. If we start from raw data, we will have to embed it using OpenAI embedding API or any other open-source embeddings.
It is straightforward to embed raw data. However, if you are using OpenAI API’s, you will be charged per token.
For the purpose of this tutorial, I have reproduced the majority of the code in this section from the Official Pinecone guide on LangChain. Pinecone documentation is exceptionally well and always up-to-date.
After you sign up for OpenAI account simply head over to https://platform.openai.com/api-keys
You must copy the key when you generate one because you don’t have any option to see or copy the key afterwards.
For Pinecone, login to your account and click on API Keys. You can click on the `Click API Key` button in the right corner.
Unlike OpenAI, with Pinecone, you don’t necessarily need to copy the API key when you generate one because there is a copy icon under the Actions column that you can use anytime you want.
Once you have the API keys from OpenAI and Pinecone, set them in variables in the Notebook. Alternatively, you can also use the `os` module in Python and set these keys as environment variables. You have then accordingly made changes in the code below, should you choose to do that.
OPENAI_API_KEY = '...'
PINECONE_API_KEY = '...'To implement this tutorial, you need the following libraries installed using pip.
!pip install -qU \
langchain==0.1.1 \
langchain-community==0.0.13 \
openai==0.27.7 \
tiktoken==0.4.0 \
pinecone-client==3.0.0 \
pinecone-datasets==0.7.0pinecone-datasets library provides a few sample datasets that are already embedded using OpenAI’s embedding-ada-002 model. We will use one of the sample dataset called wikipedia-simple-text-embedding-ada-002-100K.
As the name suggests, there are 100,000 documents. However, we will sample only the first 30,000 records in this tutorial. Even though there isn’t any cost impact because embeddings are provided for all 100,000 documents, sampling is just done to make the process faster.
import pinecone_datasets
dataset = pinecone_datasets.load_dataset('wikipedia-simple-text-embedding-ada-002-100K')
# drop metadata column and renamed blob to metadata
dataset.documents.drop(['metadata'], axis=1, inplace=True)
dataset.documents.rename(columns={'blob': 'metadata'}, inplace=True)
# sample 30k documents
dataset.documents.drop(dataset.documents.index[30_000:], inplace=True)from pinecone import Pinecone, ServerlessSpec
# configure client
pc = Pinecone(api_key=PINECONE_API_KEY)
# configure serverless spec
spec = ServerlessSpec(cloud='aws', region='us-west-2')
# check for and delete index if already exists
index_name = 'langchain-retrieval-augmentation-fast'
if index_name in pc.list_indexes().names():
pc.delete_index(index_name)
# we create a new index
pc.create_index(
index_name,
dimension=1536, # dimensionality of text-embedding-ada-002
metric='dotproduct',
spec=spec
)
To connect to the index and check the stats of index:
index = pc.Index(index_name)
index.describe_index_stats()
This will be the output:
{'dimension': 1536,
'index_fullness': 0.0,
'namespaces': {},
'total_vector_count': 0}
1536 is the shape of embeddings from the ada-002 model. You can see the vector count is zero because we haven’t ingested any data (vectors) yet.
Inserting data into this index langchain-retrieval-augmentation-fast is pretty straightforward:
for batch in dataset.iter_documents(batch_size=100):
index.upsert(batch)
This command will take a few minutes to complete.
After inserting data, you can also see it on Pinecone UI:
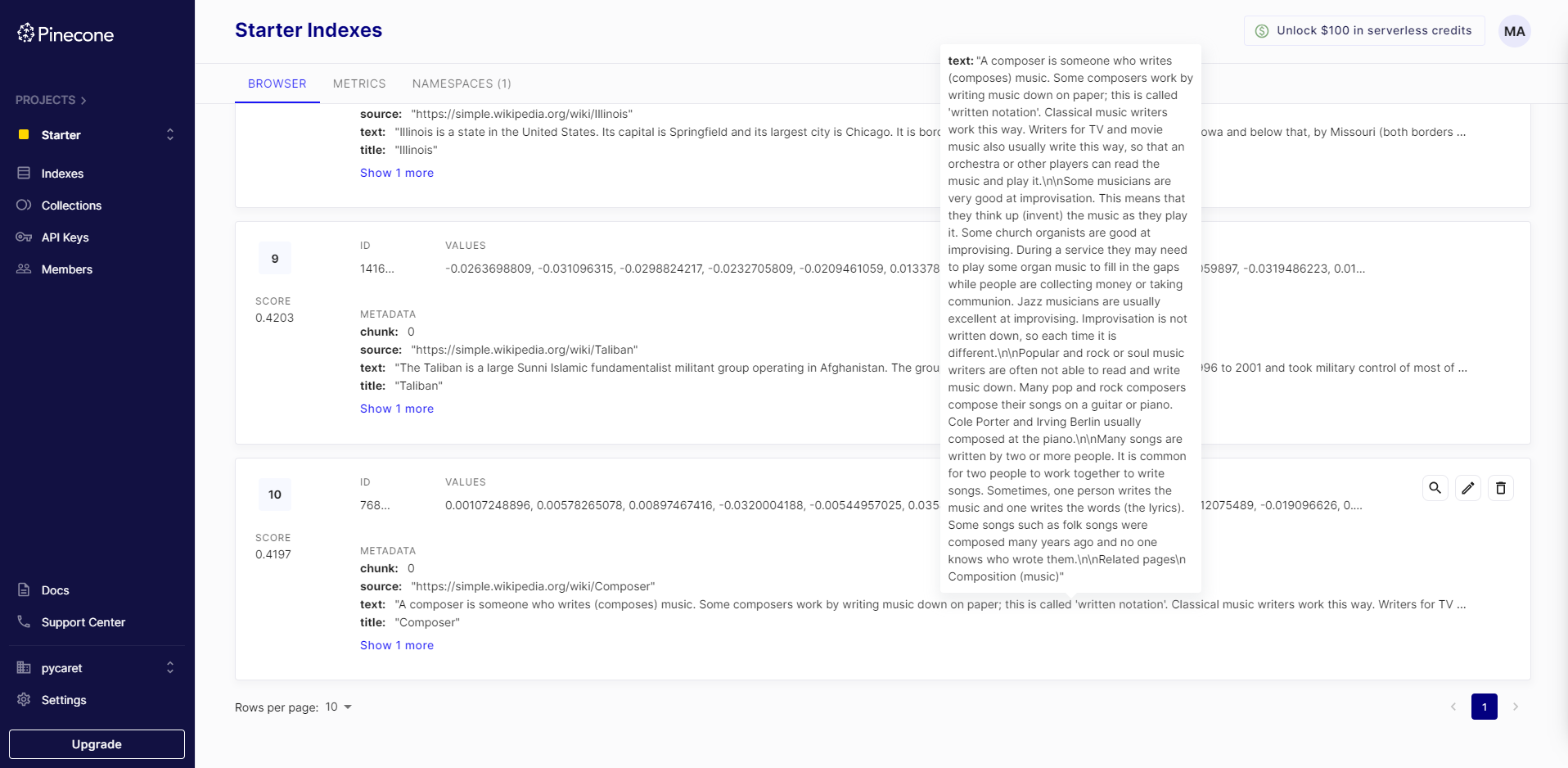
Now that we have created an index and inserted the data in the index using Pinecone API, we will transition to using LangChain. The next step involves initializing a LangChain vector store using LangChain and utilizing the same index we have created.
from langchain.embeddings.openai import OpenAIEmbeddings
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(model=model_name, openai_api_key=OPENAI_API_KEY)
To initialize the vector store:
from langchain.vectorstores import Pinecone
vectorstore = Pinecone(index, embed.embed_query, "text")
You can now use vectorstore object to query the data and see the Top N results:
query = "What is Schizophrenia?"
vectorstore.similarity_search(query, k=3)The output is a document object from which you can easily parse strings, but essentially, it is showing the top 3 matching documents based on the metric we have chosen in Step 4, which in this case is dotmatrix.

This is the final step of our application. We now want to wrap LLM around it. To do that, you will import ChatOpenAI and RetrievalQA class from Langchain.
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# completion llm
llm = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
model_name='gpt-4',
temperature=0.0
)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
qa.run(query)
The output of qa.run(query) is the response from the language model.
Schizophrenia is a mental illness where people may see, hear or believe things that are not real. It often first appears in teenage years and is a chronic condition....This answer is coming from one of the documents in the `dataset`. If you also want to fetch the source (which is often needed in RAG applications) you will have to make one minor change to the code above.
from langchain.chains import RetrievalQAWithSourcesChain
qa_with_sources = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
qa_with_sources(query)
Output:
{'question': 'What is Schizophrenia?',
'answer': 'Schizophrenia is a mental illness where people may see, hear or believe things that are not real. It is a relatively common condition ...',
'sources': 'https://simple.wikipedia.org/wiki/Schizophrenia'}Notice the output this time is a dictionary in which you can find the `source.`
In this blog, we've explored the most popular application of LLM, the Retrieval Augmented Generation (RAG) technique, offering a deep dive into how it enhances the reliability and relevance of chatbot responses based on Large Language Models like GPT-4.
The evolution of chatbots from simplistic, rule-based systems to sophisticated, AI-driven conversational agents marks a significant leap in technological advancement. LLMs bring a new level of versatility and intelligence to chatbots, capable of engaging in more natural, contextually-aware conversations.
We also explored the role of vector databases, focusing on Pinecone, in storing and retrieving high-dimensional data vectors. These databases are pivotal in implementing RAG.
The practical implementation of these concepts was demonstrated through code examples, leveraging OpenAI's and Pinecone API and the LangChain framework in Python. These tools simplify the development process, making it more accessible for developers to create AI-powered chatbots tailored to a wide range of applications quickly and efficiently.
To learn more about Vector Databases for Embeddings with Pinecone or working with the OpenAI API, check out our courses, which can help you expand your knowledge in these areas.
Start Your AI Journey Today!
Course
Course
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
code-along
James Briggs
code-along
Vincent Vankrunkelsven
code-along
James Briggs
code-along
Richie Cotton



