Course
Machine Learning for Time Series Data in Python
4 hr
53.2K
For this tutorial, you will be working with a text dataset Deceptive Opinion Spam Corpus as an example.
In a nutshell, you'll address the following topics in today's tutorial:
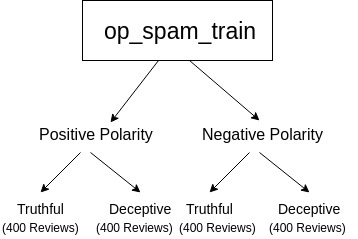
Before you go ahead and load in the data, it's good to take a look at what you'll exactly be working with! The Deceptive opinion spam dataset is a corpus consisting of truthful and deceptive hotel reviews of 20 Chicago hotels. The data is described in two papers according to the sentiment of the review. In particular, the article discusses positive sentiment reviews in 1 and negative sentiment reviews in 2, feel free to refer to the papers for more in-depth knowledge.
The corpus contains:
In total you have 1600 reviews, your task will be to classify the truthful and deceptive hotel reviews using a machine learning algorithm.
So, Let's get started!
You start with importing all the required modules like os, pandas, nltk, regex and most importantly Sklearn since in today's tutorial you will be using a machine learning algorithm Support Vector Machine that is provided by the Sklearn library!
You will need os for iterating over the folders and subfolders in which the text files reside, fnmatch will come handy for filtering only the text files and ignore everything else present in the folders, pandas will help you in putting your data in the form of rows and columns and you can perform various data manipulations using pandas. Regex helps in extracting data based on the pattern you specify it to match so that you will need that too! Nltk is a natural language toolkit which will help you to remove stopwords which you do not want your model to learn. Then most importantly you will import Sklearn that will provide you a bunch of libraries which you will use to manipulate the data, vectorize the data, learn the boundary between the data points using a machine learning algorithm and finally plot the accuracy.
import os
import fnmatch
from textblob import TextBlob
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.corpus import stopwords
from nltk import pos_tag,pos_tag_sents
import regex as re
import operator
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import svm
from sklearn.grid_search import GridSearchCV
import pickle
from nltk.corpus import stopwords
After importing the libraries, your next task is to extract the labels of the data. The labels will help the model in discriminating between the reviews, whether a particular review belongs to a truthful or a deceptive class.
You will first iterate over all the text files and get the absolute path of all the text files through which you will then extract the corresponding labels.
path = 'op_spam_train/'
label = []
configfiles = [os.path.join(subdir,f)
for subdir, dirs, files in os.walk(path)
for f in fnmatch.filter(files, '*.txt')]
There should be 1600 paths each representing a new text file. Let's quickly verify it!
len(configfiles)
1600
Let's also print one of the text file paths.
configfiles[1]
'op_spam_train/negative_polarity/deceptive_from_MTurk/fold4/d_swissotel_14.txt'
So, from the above output, you can observe that in order to extract the labels we need some kind of filter. And for that, you will use Regex also known as a regular expression.
for f in configfiles:
c = re.search('(trut|deceptiv)\w',f)
label.append(c.group())
Once the labels are extracted in a list called label, let's create a dataframe of the list.
labels = pd.DataFrame(label, columns = ['Labels'])
Let's print first five rows of the labels dataframe.
labels.head(5)
| Labels | |
|---|---|
| 0 | deceptive |
| 1 | deceptive |
| 2 | deceptive |
| 3 | deceptive |
| 4 | deceptive |
Once you have extracted all the labels, it's time to extract the reviews from the text files!
review = []
directory =os.path.join("op_spam_train")
for subdir,dirs ,files in os.walk(directory):
# print (subdir)
for file in files:
if fnmatch.filter(files, '*.txt'):
f=open(os.path.join(subdir, file),'r')
a = f.read()
review.append(a)
As before, you will now create a dataframe of the review list.
reviews = pd.DataFrame(review, columns = ['HotelReviews'])
Let's print first five rows of the reviews dataframe.
reviews.head(5)
| HotelReviews | |
|---|---|
| 0 | Grant it, this hotel seems very nice, but I wa... |
| 1 | I recently stayed at the Swissotel Chicago wit... |
| 2 | I was sorely disappointed with the Sheraton Ch... |
| 3 | My family and I stayed at the Sheraton Chicago... |
| 4 | I recently stayed at the Homewood Suites by Hi... |
Great! So, till now it was quite intuitive. Isn't it?
Let's now merge both the labels and the reviews dataframe!
result = pd.merge(reviews, labels,right_index=True,left_index = True)
result['HotelReviews'] = result['HotelReviews'].map(lambda x: x.lower())
After they are merged, you have a new dataframe by the name result. Let us also print few rows of this new dataframe.
result.head()
| HotelReviews | Labels | |
|---|---|---|
| 0 | grant it, this hotel seems very nice, but i wa... | deceptive |
| 1 | i recently stayed at the swissotel chicago wit... | deceptive |
| 2 | i was sorely disappointed with the sheraton ch... | deceptive |
| 3 | my family and i stayed at the sheraton chicago... | deceptive |
| 4 | i recently stayed at the homewood suites by hi... | deceptive |
When you deal with text data, it is vital to remove stopwords. Stopwords are not meaningful, and they do not give any information that can help the model learn a pattern in the data.
You will create a new column in the dataframe by the name review_without_stopwords. The lambda function will process on all the rows of the HotelReviews column. You will use a list comprehension and store only those words in the new column which are not present in the stop variable.
import ntlk
nltk.download('stopwords')
Note: In order to execute the below cell, you might need to run the above lines of code in your terminal.
stop = stopwords.words('english')
result['review_without_stopwords'] = result['HotelReviews'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
Let's quickly print the dataframe without stopwords!
result.head()
| HotelReviews | Labels | review_without_stopwords | |
|---|---|---|---|
| 0 | grant it, this hotel seems very nice, but i wa... | deceptive | grant it, hotel seems nice, pleased stay here.... |
| 1 | i recently stayed at the swissotel chicago wit... | deceptive | recently stayed swissotel chicago husband two ... |
| 2 | i was sorely disappointed with the sheraton ch... | deceptive | sorely disappointed sheraton chicago. outside ... |
| 3 | my family and i stayed at the sheraton chicago... | deceptive | family stayed sheraton chicago hotel towers be... |
| 4 | i recently stayed at the homewood suites by hi... | deceptive | recently stayed homewood suites hilton chicago... |
As per 1 which suggests that truthful and deceptive opinions might be classified into informative and imaginative genres, respectively. There is a strong distributional difference between informative and imaginative writing, namely that the former typically consists of more nouns, adjectives, prepositions, determiners, and coordinating conjunctions, while the latter includes more verbs, adverbs, pronouns, and pre-determiners. However, that deceptive opinions contain more superlatives is not unexpected since deceptive writing (but not necessarily imaginative writing in general) often contains exaggerated language.
So, let us now for each word in the row of the dataframe extract its respective part of speech and you will then feed this as a feature vector into your model.
For pos tagging, you will use TextBlob, which is a Python library for processing textual data. It provides a simple API for diving into ordinary natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
Note: In order to run the pos function cell, you might need to run the following lines of code in your terminal window.
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
def pos(review_without_stopwords):
return TextBlob(review_without_stopwords).tags
os = result.review_without_stopwords.apply(pos)
os1 = pd.DataFrame(os)
os1 dataframe's each row will consist of a list of words with their respective part of speech. You will not be able to vectorize a list which you will be feeding into the model. So, you will have to convert these rows of lists into string.
os1.head()
| review_without_stopwords | |
|---|---|
| 0 | [(grant, NN), (it, PRP), (hotel, NN), (seems, ... |
| 1 | [(recently, RB), (stayed, VBN), (swissotel, NN... |
| 2 | [(sorely, RB), (disappointed, JJ), (sheraton, ... |
| 3 | [(family, NN), (stayed, VBD), (sheraton, JJ), ... |
| 4 | [(recently, RB), (stayed, VBN), (homewood, NN)... |
Let's convert each row into a string, where each word will be joined with its corresponding pos using a forward slash, and a single space will separate the words.
os1['pos'] = os1['review_without_stopwords'].map(lambda x:" ".join(["".join(x) for x in x ]) )
Finally, let's merge the pos column with the main result dataframe and print first few rows of it!
result = result = pd.merge(result, os1,right_index=True,left_index = True)
result.head()

Once you have the features extracted, now is the time to split the data into training and testing. For this tutorial, you will be splitting the 80% of the data into training and the remaining 20% into testing.
review_train, review_test, label_train, label_test = train_test_split(result['pos'],result['Labels'], test_size=0.2,random_state=13)
Let's understand in detail about TfidfVectorizer
Tfidf has two parts :
The weighting technique helps machine learning (ML) model during classification as we explicitly tell which word weighs more/less.
Now, that you know about it, let us implement it on the training and testing data.
tf_vect = TfidfVectorizer(lowercase = True, use_idf=True, smooth_idf=True, sublinear_tf=False)
X_train_tf = tf_vect.fit_transform(review_train)
X_test_tf = tf_vect.transform(review_test)
Now, you will be implementing a machine learning model known as Support Vector Machines (SVM). In order to understand it you can follow this link.
To select the best hyperparameters for your ML algorithm, you will use GridSearchCV, which based on your training data and labels suggests you the best hyperparameter values out of the values that you specify as a list. You will choose five different values for Cs and gammas and based on your data; you will get the best hyperparameter values.
def svc_param_selection(X, y, nfolds):
Cs = [0.001, 0.01, 0.1, 1, 10]
gammas = [0.001, 0.01, 0.1, 1]
param_grid = {'C': Cs, 'gamma' : gammas}
grid_search = GridSearchCV(svm.SVC(kernel='linear'), param_grid, cv=nfolds)
grid_search.fit(X, y)
return grid_search.best_params_
svc_param_selection(X_train_tf,label_train,5)
{'C': 10, 'gamma': 0.001}
clf = svm.SVC(C=10,gamma=0.001,kernel='linear')
clf.fit(X_train_tf,label_train)
pred = clf.predict(X_test_tf)
Let's save the model that you just trained along with the Tfidf vectorizer using the pickle library that you had imported in the beginning, so that later on you can just simply load the data, vectorize it and predict using the ML model.
with open('vectorizer.pickle', 'wb') as fin:
pickle.dump(tf_vect, fin)
with open('mlmodel.pickle','wb') as f:
pickle.dump(clf,f)
pkl = open('mlmodel.pickle', 'rb')
clf = pickle.load(pkl)
vec = open('vectorizer.pickle', 'rb')
tf_vect = pickle.load(vec)
/home/naveksha/.local/lib/python3.5/site-packages/sklearn/base.py:311: UserWarning: Trying to unpickle estimator SVC from version pre-0.18 when using version 0.19.1. This might lead to breaking code or invalid results. Use at your own risk.
UserWarning)
/home/naveksha/.local/lib/python3.5/site-packages/sklearn/base.py:311: UserWarning: Trying to unpickle estimator TfidfTransformer from version pre-0.18 when using version 0.19.1. This might lead to breaking code or invalid results. Use at your own risk.
UserWarning)
/home/naveksha/.local/lib/python3.5/site-packages/sklearn/base.py:311: UserWarning: Trying to unpickle estimator TfidfVectorizer from version pre-0.18 when using version 0.19.1. This might lead to breaking code or invalid results. Use at your own risk.
UserWarning)
X_test_tf = tf_vect.transform(review_test)
pred = clf.predict(X_test_tf)
print(metrics.accuracy_score(label_test, pred))
0.96875
print (confusion_matrix(label_test, pred))
[[149 6]
[ 4 161]]
The above confusion matrix is a 2 x 2 matrix in which, first row first element is True Positive (TP), first row second element is False Negative (FN), second row first element is False Positive (FP) and second row first element is True Negative (TN).
From the above confusion matrix, you can conclude the only 10 test samples out of 320 were misclassified.
print (classification_report(label_test, pred))
precision recall f1-score support
deceptive 0.97 0.96 0.97 155
truth 0.96 0.98 0.97 165
avg / total 0.97 0.97 0.97 320
review_train, review_test, label_train, label_test = train_test_split(result['pos'],result['Labels'], test_size=0.2,random_state=1)
X_test_tf = tf_vect.transform(review_test)
pred = clf.predict(X_test_tf)
print(metrics.accuracy_score(label_test, pred))
0.978125
print (confusion_matrix(label_test, pred))
[[146 5]
[ 2 167]]
print (classification_report(label_test, pred))
precision recall f1-score support
deceptive 0.99 0.97 0.98 151
truth 0.97 0.99 0.98 169
avg / total 0.98 0.98 0.98 320
review_train, review_test, label_train, label_test = train_test_split(result['pos'],result['Labels'], test_size=0.2,random_state=10)
X_test_tf = tf_vect.transform(review_test)
pred = clf.predict(X_test_tf)
print(metrics.accuracy_score(label_test, pred))
0.98125
print (confusion_matrix(label_test, pred))
[[155 5]
[ 1 159]]
print (classification_report(label_test, pred))
precision recall f1-score support
deceptive 0.99 0.97 0.98 160
truth 0.97 0.99 0.98 160
avg / total 0.98 0.98 0.98 320
review_train, review_test, label_train, label_test = train_test_split(result['pos'],result['Labels'], test_size=0.2,random_state=42)
X_test_tf = tf_vect.transform(review_test)
pred = clf.predict(X_test_tf)
print(metrics.accuracy_score(label_test, pred))
0.984375
print (confusion_matrix(label_test, pred))
[[165 3]
[ 2 150]]
print (classification_report(label_test, pred))
precision recall f1-score support
deceptive 0.99 0.98 0.99 168
truth 0.98 0.99 0.98 152
avg / total 0.98 0.98 0.98 320
From the above predictions, you can observe that the Model did a Fantastic Job and is not overfitting since you tested the model several times by splitting the data differently everytime.
def test_string(s):
X_test_tf = tf_vect.transform([s])
y_predict = clf.predict(X_test_tf)
return y_predict
test_string("The hotel was good.The room had a 27-inch Samsung led tv, a microwave.The room had a double bed")
array(['truth'], dtype=object)
test_string("My family and I are huge fans of this place. The staff is super nice, and the food is great. The chicken is very good, and the garlic sauce is perfect. Ice cream topped with fruit is delicious too. Highly recommended!")
array(['deceptive'], dtype=object)
Well, the model predicted the above two reviews correctly. The first review is a Truthful review while the second review is a deceptive one!
Note
The model's performance varies when implemented on a different processing system having different specifications, this is an unusual behavior observed. If the community can help figure out this problem, it would help a lot of people including the author of this post. By community, it means the readers who will go through this tutorial!
Happy Learning!
Hope this tutorial was indeed helpful and adds some value to your skill sets.
If you would like to learn more about Machine Learning, take DataCamp's Building Chatbots in Python course.
Learn more about Python and Machine Learning
Course
Course
Course
podcast
Tutorial
Katharine Jarmul
Tutorial
Moez Ali
Tutorial
Sayak Paul
code-along
Justin Saddlemyer
code-along
Filip Schouwenaars

