
Course
Data Management Concepts
2 hr
10.6K
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more

Data federation is a data integration technique that provides a unified view of data from multiple sources without physically consolidating it. Picture it as a sophisticated mechanism that allows you to access and query data across various systems in real time as if it were all stored in a single location.
Many organizations handle vast amounts of data from disparate sources. It is important for making informed decisions to be able to access and analyze this data in real time without the hassle of data duplication. Data federation allows this to happen.
Data federation is also used in some data architectures to consolidate data, like in data fabrics (read more in this article on what a data fabric is).
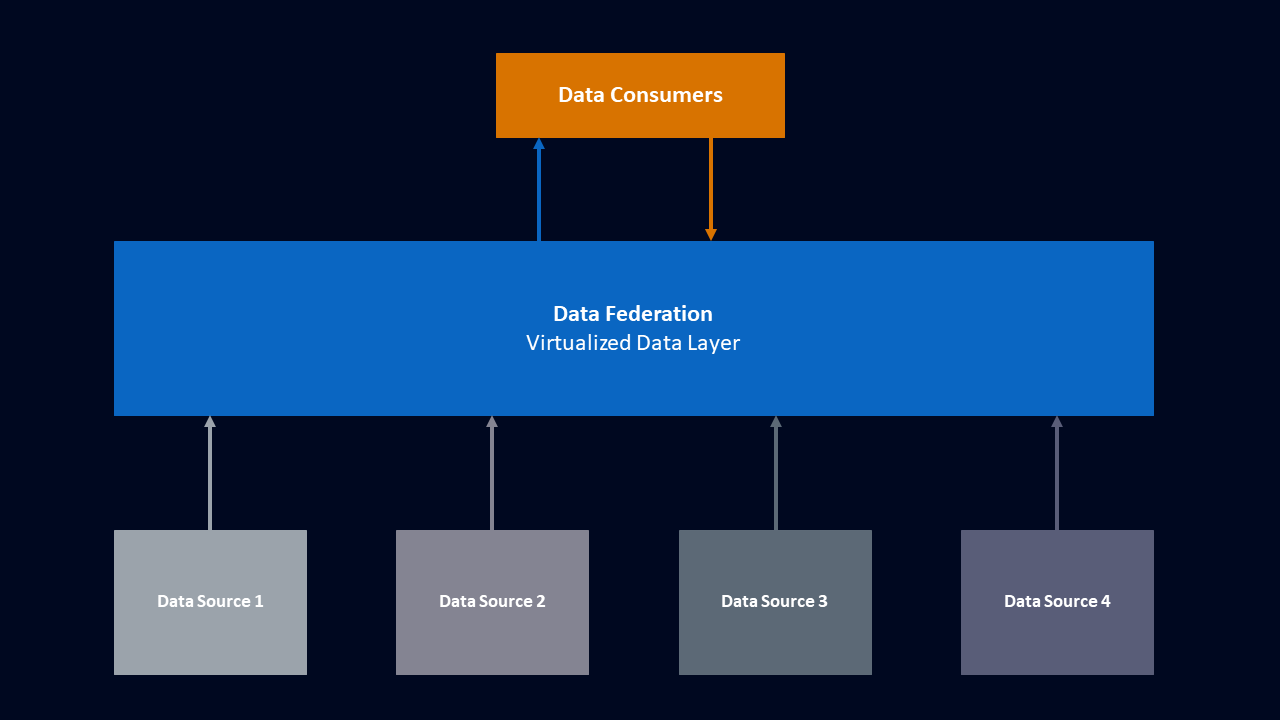
The above graphic is a simplified view of a data federation. The data federation virtualizes and aggregates data from many different sources for the data consumers to interact with.
A data federation operates on several core principles. Let’s go over a few of them.
Instead of physically relocating data, data federation keeps it in its original source location and makes it accessible through a virtual layer. This approach eliminates the need for data duplication while ensuring real-time access to the most current information. By virtualizing data access, organizations can maintain the integrity and security of their data in its original location while benefiting from a unified view.
Users interact with a single interface or query language, simplifying the process of accessing data from multiple sources. This unified access streamlines data retrieval. This process allows analysts, data scientists, and other stakeholders to easily query and analyze data without navigating the complexities of each data source.
A schema is a blueprint that defines how data is organized within a database. Data sources often have different schemas, meaning they organize and label their data differently. Schema mapping involves aligning these schemas to create a consistent data view.
For example, one data source might use "CustomerID" to refer to a customer identifier, while another might use "CustID." Schema mapping translates these different labels to be understood as the same entity.
By harmonizing the different schemas, data federation tools ensure that data from diverse sources can be integrated seamlessly. This provides a consistent and reliable data model that users can trust for accurate analysis and reporting.
Data federation emphasizes on-demand processing. Queries are executed in real time across federated sources, minimizing data duplication and ensuring users access the most up-to-date data. This dynamic processing capability is crucial for timely decision-making and analysis. By processing data on-demand, data federation supports agile and informed decision-making.
Now that we know what a data federation is, let’s look at how it works.
Data federation seamlessly integrates data from disparate sources. At its core lies a structured architecture designed to facilitate this integration efficiently. This architecture consists of three main parts:
Data sources can be thought of as islands, each holding valuable information. These sources range from structured data in databases to unstructured data in cloud storage and real-time data streams. Data federation integrates these diverse sources, creating a cohesive view of the data landscape.
The federation layer provides a unified interface for accessing and querying data. It translates user queries into commands that each data source can understand, facilitating real-time access and processing. This layer is crucial for maintaining data integrity, ensuring efficient data retrieval, and providing a consistent data view across all sources.
We can think of this federation layer like a live video stream of each of the data islands. It allows data consumers to see and use the data on each of the islands, without moving it or copying it.
Various applications and tools, such as business intelligence platforms, data science environments, and operational systems, interact with the federated data through the federation layer. Through these tools, data analysts, data scientists, and other data consumers can use the data. These data consumers can then leverage the integrated data for analysis, reporting, and decision-making.
When we submit a query to a federated system, it first goes to the federation layer. Think of the federation layer as a smart translator. It takes our main query and breaks it down into smaller sub-queries. Each sub-query is customized to fetch data from different sources where that information is stored, like databases or cloud storage.
These sub-queries are then sent to the various data sources in real time. Each source processes its part of the query and sends back the results. The federation layer then collects all these results and combines them into one aggregated result.
This streamlined process allows us to access and analyze data from multiple sources as if they were a single, unified dataset. This makes it easier to collect data from all over the organization.
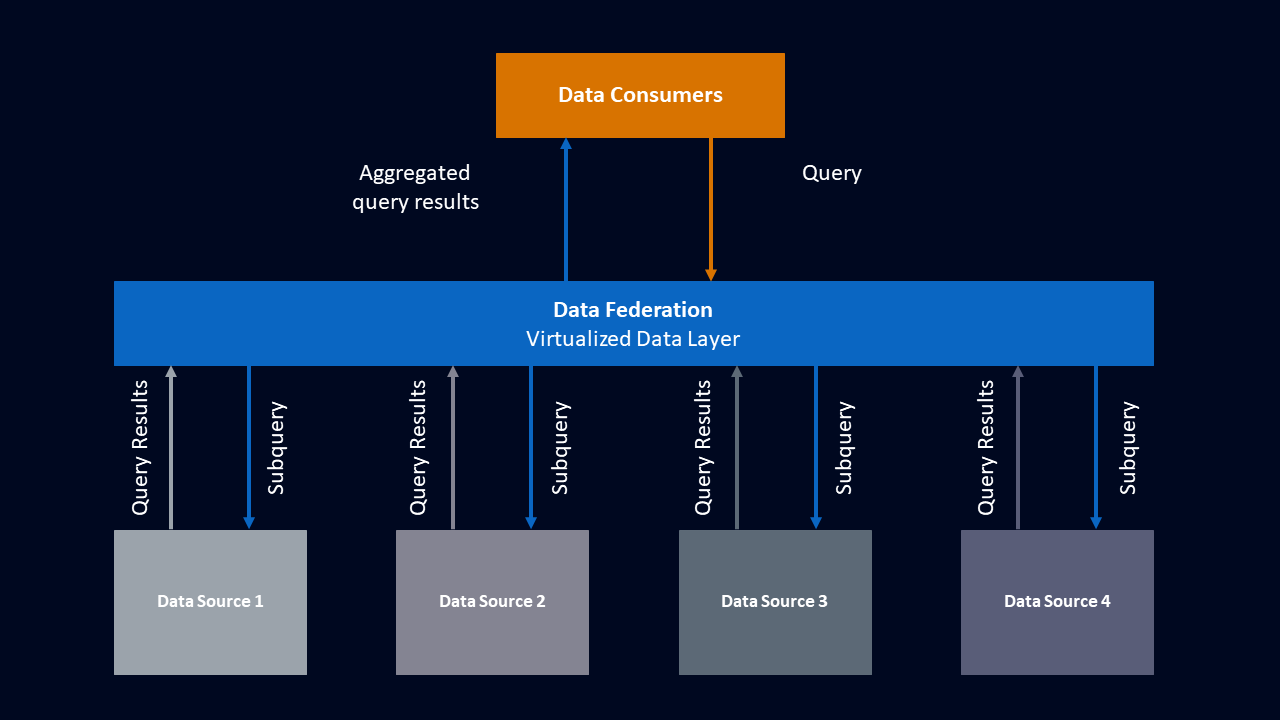
The above graphic is a simplified view of this process. A data consumer queries the data federation. It breaks up that query into a series of subqueries and sends them out to the appropriate data source. Each source sends back its results, which the data federation then aggregates to relay to the data consumer.
Data federation offers several key benefits for organizations with complex data landscapes.
By minimizing copies of the data, federation reduces storage costs and reduces the risk of inconsistencies across datasets. This streamlined approach optimizes resource allocation and enhances data integrity.
Data federation also simplifies data access by providing a single place to query data from across the organization. This centralized access point streamlines data retrieval and analysis. The real-time nature of data federation ensures that users have access to the most up-to-date data across all federated sources, which is important for timely decision-making.
Data federation streamlines data integration efforts by eliminating the need for complex ETL (extract, transform, load) processes traditionally associated with data consolidation. This accelerates the pace of data integration and reduces the potential for errors.
The inherent flexibility of data federation allows organizations to easily add or remove data sources as needed without disrupting existing applications or workflows. This flexibility allows organizations to adapt quickly to changing data needs without being constrained by rigid data architectures.
While offering numerous advantages, data federation also presents several challenges that organizations must address.
Performance issues may arise due to the complexity of queries across multiple sources. Optimization efforts can help to ensure efficient data retrieval and processing. It’s important to invest in robust infrastructure and use query optimization techniques. These can mitigate performance bottlenecks and maintain responsiveness in data access and analysis.
Another significant challenge is schema complexity. Mapping schemas from diverse sources can be daunting. The disparate structures of data sources require sophisticated tools and techniques to harmonize schemas and ensure consistency across the federated data. Data professionals can use data modeling and schema mapping strategies to overcome these challenges. This way, we can create a unified view of the data that accurately reflects its underlying semantics.
To learn more about schema mapping, I suggest you check out this Database Design course.
Data governance can be a challenge with federated data. Organizations must establish and enforce policies for data quality, security, and privacy across federated sources. It’s important to implement data governance processes, like data lineage tracking, access controls, and privacy measures. These help to mitigate risks and maintain the integrity of federated data.
For more information on data governance, check out Making Data Governance Fun and How Data Leaders Can Make Data Governance a Priority. This data governance cheat sheet is also a good resource.
Data federation is useful at all levels in an organization.
Data federation empowers analysts to create comprehensive reports and dashboards that aggregate data from different departments or systems. Organizations gain valuable insights into their operations by providing a unified view of information, enabling informed decision-making and strategic planning.
With easy access to diverse data sources for model training and validation, data scientists can harness the full spectrum of available information in their organization. This aggregated data can improve the accuracy and robustness of data models, which can enhance predictive capabilities. Data federation also frees up time for some data scientists who would otherwise need to build complex data pipelines to power their models.
By aggregating data streams from disparate sources, organizations gain a holistic view of their operations, identify bottlenecks, and optimize workflows. This improves the organization's overall efficiency. The data's real-time visibility also empowers decision-makers to respond swiftly to changing conditions.
Data federation is helpful when auditors require access to a complete view of your data across various sources. By providing a unified platform for accessing and analyzing data, data federation can make it easier to comply with regulations and perform audits. Data federation should be paired with data lineage and proper documentation to make compliance audits easier.
Check out What Is Data Lineage and Data Governance Concepts for more information.
Data federation is sometimes confused with data warehousing. However, there are some important distinctions between the two.
Data federation operates on the principle of virtualization, where data remains in its original locations and is accessed in real time through a virtual layer. This approach enables users to access the most current data without the need for duplication, minimizes storage costs, and reduces inconsistencies across datasets.
Data warehousing consolidates data into a centralized repository. This centralized approach is well-suited for storing historical data, providing a comprehensive view of past trends. However, data warehousing typically requires extensive ETL processes to consolidate data from various sources into the warehouse.
You can learn more about data warehouses in this Introduction to Data Warehousing Concepts course or this tutorial on Choosing the Right Cloud Data Warehouse Solution.
Data federation and data warehousing offer different approaches to data integration. Each approach has strengths and limitations.
Data federation excels in providing real-time access to current data while minimizing data duplication. It is ideal for dynamic and agile environments.
Data warehousing is best suited for storing and analyzing historical data. It may require more extensive ETL processes and lacks the flexibility of data federation.
When deciding between data federation and data warehousing, consider the specific use case, data volume, and the need for real time versus historical analysis.
Depending on your data landscape, implementing a data federation may be a challenge. But with careful planning, selection of appropriate tools, and consideration of our organization’s requirements, it is a manageable task that will pay dividends. Here are a few steps to consider in any federation implementation.
We must begin by thoroughly assessing our organization's current data landscape. Identify the data sources present across different systems, databases, and applications. Learn the types of data stored in each source and how often they are updated. This will help ensure that our data federation solution can accommodate real-time access to the most current data.
As with any project, it’s important to clearly define our goals. Lay out the use cases and requirements for data federation within the organization. Determine the specific business objectives you aim to achieve through data federation. These might be improving data accessibility, streamlining data integration processes, or enabling real-time analytics. Identify key stakeholders and involve them in this step to ensure the solution meets their needs, too.
Choose the appropriate tools and technologies based on the organization's requirements and budget constraints. Consider factors such as data virtualization capabilities, scalability, ease of integration with existing systems, and support for various data sources. Evaluate both commercial and open-source options to find the best fit for our needs. Below is a table with a few popular tools used in data federation.
|
Tool |
Features |
Licensing Model |
|
Real time data access, schema mapping, query optimization |
Paid |
|
|
Flexible and extensible, custom data federation solutions |
Open-source |
|
|
Query data stored in Amazon S3 using standard SQL |
Paid |
Design a federation that aligns with the organization's requirements and use cases. Determine the placement of the federation layer within the existing infrastructure and define the integration points with data sources and data consumers. Consider data security, performance optimization, and scalability to ensure that the federation can support both current and future data needs.
Once our data federation is set up and configured to connect to our data sources, it’s important to make sure it’s working properly. Test the solution thoroughly to identify any issues or performance bottlenecks and refine our implementation as needed.
Deploy the data federation solution into production and monitor its performance and reliability. Establish monitoring and alerting mechanisms to detect and address any issues proactively. Continuously optimize the federation architecture and data integration processes to ensure the solution remains effective and aligned with evolving business needs.
Data federation offers significant benefits for organizations looking to unlock the value of data scattered across different systems. By providing a virtualized, unified view of data from multiple sources, data federation enhances data access, reduces redundancy, and simplifies integration efforts.
Learn more about data management with An Introduction to Data Pipelines for Aspiring Data Professionals. I also recommend this course on Responsible AI Data Management.
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more
Learn data management with these courses!
Course
Course
Course
blog
Amberle McKee
13 min
blog
Amberle McKee
10 min
blog
Amberle McKee
8 min
blog
Vinita Silaparasetty
15 min
blog
Kenneth Leung
8 min
blog
Adel Nehme
4 min