
Track
Artificial Intelligence (AI) Leadership
6 hr
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more

If you want to learn more about data management, check out my other articles in this series:
A data warehouse is a specialized storage system designed to collect and organize large amounts of data. It has several key characteristics that define its purpose and functionality.
In a data warehouse, data is organized around specific subjects or business areas (e.g., sales, marketing, inventory). This makes it easier to analyze specific aspects of the business.
Data from diverse sources is combined and transformed into a consistent format in a data warehouse. This structured integration ensures uniformity and reliability in the data, which makes it easier to analyze and understand.
Data is stored historically in a data warehouse. This means that past versions of the data are not overwritten when new versions are added. This time variance allows for trend analyses and comparisons over time. The historical perspective provided by data warehouses is important for understanding long-term trends and patterns.
Unlike real-time data systems, data in a warehouse is typically not updated in real-time. Instead, it is loaded in batches for stability and consistency. Once entered, the data is not changed. This non-volatility helps ensure a reliable and consistent record of business transactions.
Data warehouses focus on specific areas of the business, combine data from different sources into a consistent format, keep historical records to track changes over time, and store data in a stable way that doesn't change once it's added.
Data warehouses and data lakes are both involved in modern data architecture, serving complementary roles. Both systems are designed to manage and analyze large volumes of data. But they use different approaches.
|
Feature |
Data Warehouse |
Data Lake |
|
Data Structure |
Structured |
Unstructured, semi-structured, and structured |
|
Schema |
Predefined schema |
Schema-on-read (schema defined during processing) |
|
Data Processing |
ETL (Extract, Transform, Load) before storage |
Data stored in raw format, processed as needed |
|
Primary Use Cases |
Business intelligence, reporting, historical analysis |
Exploratory analytics, machine learning, advanced analytics |
|
Query Performance |
Optimized for fast queries |
Varies depending on processing framework and data organization |
|
Data Storage |
Optimized for structured data |
Accommodates diverse data types and formats |
|
Flexibility |
Less flexible, requires data transformation before storage |
More flexible, allows for schema evolution |
|
Common Usage |
Used for well-defined reporting and analysis needs |
Used for exploratory analysis and discovery of insights |
|
Integration |
Often used with data lakes as a source of curated data |
Often used alongside data warehouses for raw data storage and processing |
Check out this Data Lakes Vs Data Warehouses tutorial for a more in-depth comparison.
The diagram below is an example of how data from multiple sources can flow into a data warehouse.
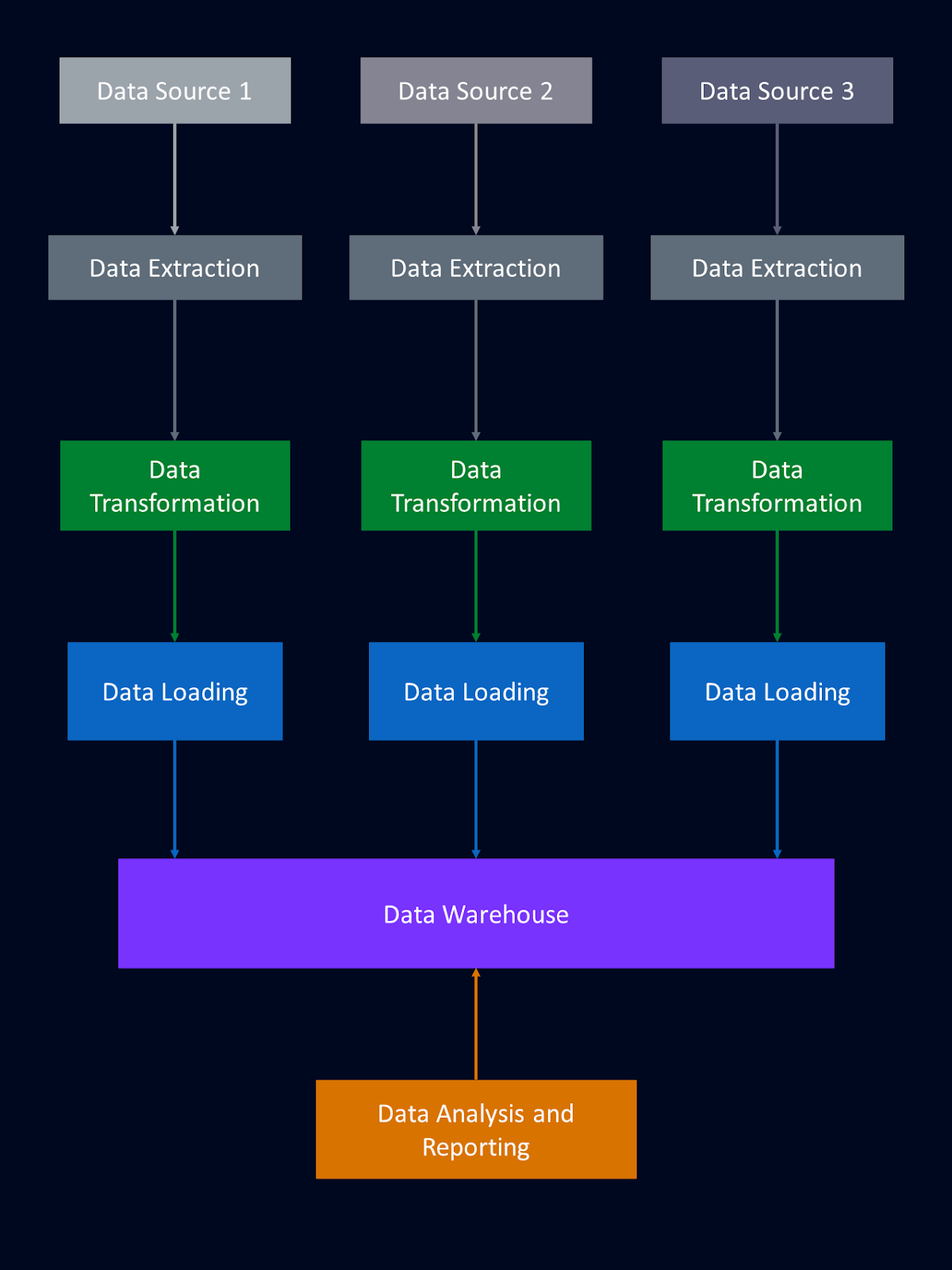
Setting up a data warehouse involves structuring data from various sources into a centralized repository. Let's explore the components that make up a data warehouse architecture and how they support critical functions in data management and analytics.
The staging area can be thought of as a landing area for raw data in the data pipeline. It is an intermediate storage location where raw data is initially extracted from various source systems like databases, APIs, data lakes, and files. This raw data is often diverse and unstructured, requiring initial processing before we can integrate it into the data warehouse.
In the staging area, data undergoes preliminary cleansing and validation. This may include removing duplicates, handling missing values, and ensuring data integrity. You can read more about data cleaning in this Beginner’s Guide to Data Cleaning tutorial or this Data Cleaning in Python course. The data may also be transformed into a standardized format to facilitate seamless integration with the data warehouse schema.
The staging area is a buffer that decouples the extraction process from the process of loading the data into the warehouse. This separation allows for flexibility in managing data flow and ensures that only validated and properly formatted data enters the warehouse. By preparing data in the staging area, we can enhance the quality and reliability of the data that is stored in our data warehouse.
Once in the staging area, data goes through the normal steps of Extraction, Transformation, and Loading (ETL). The ETL process is an important component of data management. Let's briefly outline these three stages:
The ETL process is a fundamental part of data management, ensuring that raw data is converted into a usable and valuable asset for an organization.
The storage layer of a data warehouse dictates how the data is stored, managed, and accessed. Modern data warehouses often use a combination of storage solutions to leverage the strengths of different technologies. Let’s explore a few common storage solutions for data warehouses: relational databases, columnar databases, and cloud-based storage.
Relational databases are traditionally the backbone of data storage in data warehouses. These databases use tables with predefined relationships between them, following a relational model. Structured data is stored in rows and columns, making them easily interpretable. SQL (Structured Query Language) is often used to manage and query data in relational databases.
Relational databases excel in scenarios with structured transactional data, such as financial systems and customer relationship management systems. However, they can struggle with performance issues when dealing with very large volumes of data. Horizontal scaling (adding more servers) can also be complex and expensive. As a result, while relational databases are suitable for many applications, they are often complemented by other types of storage optimized for different needs.
Columnar databases are a more specialized type of data storage, designed specifically for read-heavy operations and analytical queries. Instead of storing data in rows, columnar databases store data in columns, hence the name. This allows for more efficient retrieval and processing of large datasets. They are particularly well-suited for data warehousing and business intelligence applications.
One of the key benefits of columnar databases is their ability to optimize storage and query performance for analytical workloads. By storing each column separately, these databases can quickly access the necessary data points without scanning entire rows. This significantly speeds up query times. Additionally, columnar databases often provide better data compression, reducing storage costs.
Despite their advantages for analytical queries, columnar databases can be less efficient for transactional workloads that involve frequent writes and updates. We generally use them in scenarios requiring fast aggregation and summarization of large datasets. They are not as suited to systems where frequent updates and insertions are common.
Cloud-based storage has become an increasingly popular choice for data warehousing due to its scalability, flexibility, and cost-effectiveness. Cloud storage solutions are provided by services such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure, which offer a range of tools and services to support data storage and processing.
One of the primary advantages of cloud-based storage is its scalability. Organizations can easily scale their storage needs up or down based on demand without the need for significant upfront investments in hardware. This flexibility is particularly beneficial for handling large and fluctuating volumes of data. Cloud storage also provides high availability and disaster recovery capabilities, ensuring that data is accessible and secure even in the event of hardware failures.
Cloud-based platforms often integrate both relational and columnar databases, meaning we can take advantage of the best features of each. This hybrid approach supports diverse data types and workloads, optimizing performance and cost.
However, data security and privacy can be concerns, as sensitive data is stored off-premises. Latency issues can also arise depending on the proximity of data to cloud servers. Additionally, we need to be mindful of long-term cost considerations and the potential for vendor lock-in.
The data storage layer of a data warehouse can incorporate a mix of relational databases, columnar databases, and cloud-based storage to meet the diverse needs of modern data management and analytics.
Data marts are smaller, focused subsets of the data warehouse tailored for specific departments or business functions. It’s essentially a segment of a data warehouse, designed to serve the particular needs of a specific group of users within an organization.
Unlike the enterprise-wide data warehouse that consolidates data from across the entire organization, a data mart focuses on a single subject area or business function. By providing a more focused view of data, data marts empower departments to perform more targeted analyses relevant to their specific needs.
Data marts are particularly useful when specific departments require quick access to relevant data for decision-making. They provide tailored data solutions without the complexity and cost of a full-scale data warehouse. Data marts are also useful for incrementally developing a data warehousing solution, starting with smaller, focused data marts.
However, data marts are not suitable for every situation. Data marts can encounter integration issues, requiring robust ETL processes and data governance to ensure alignment with the central data warehouse. Maintaining performance and scalability as data volumes grow can also be difficult. Data marts require careful planning and resource allocation, especially when scaling.
If you find yourself using lots of data marts, you might consider switching strategies to use a data mesh.
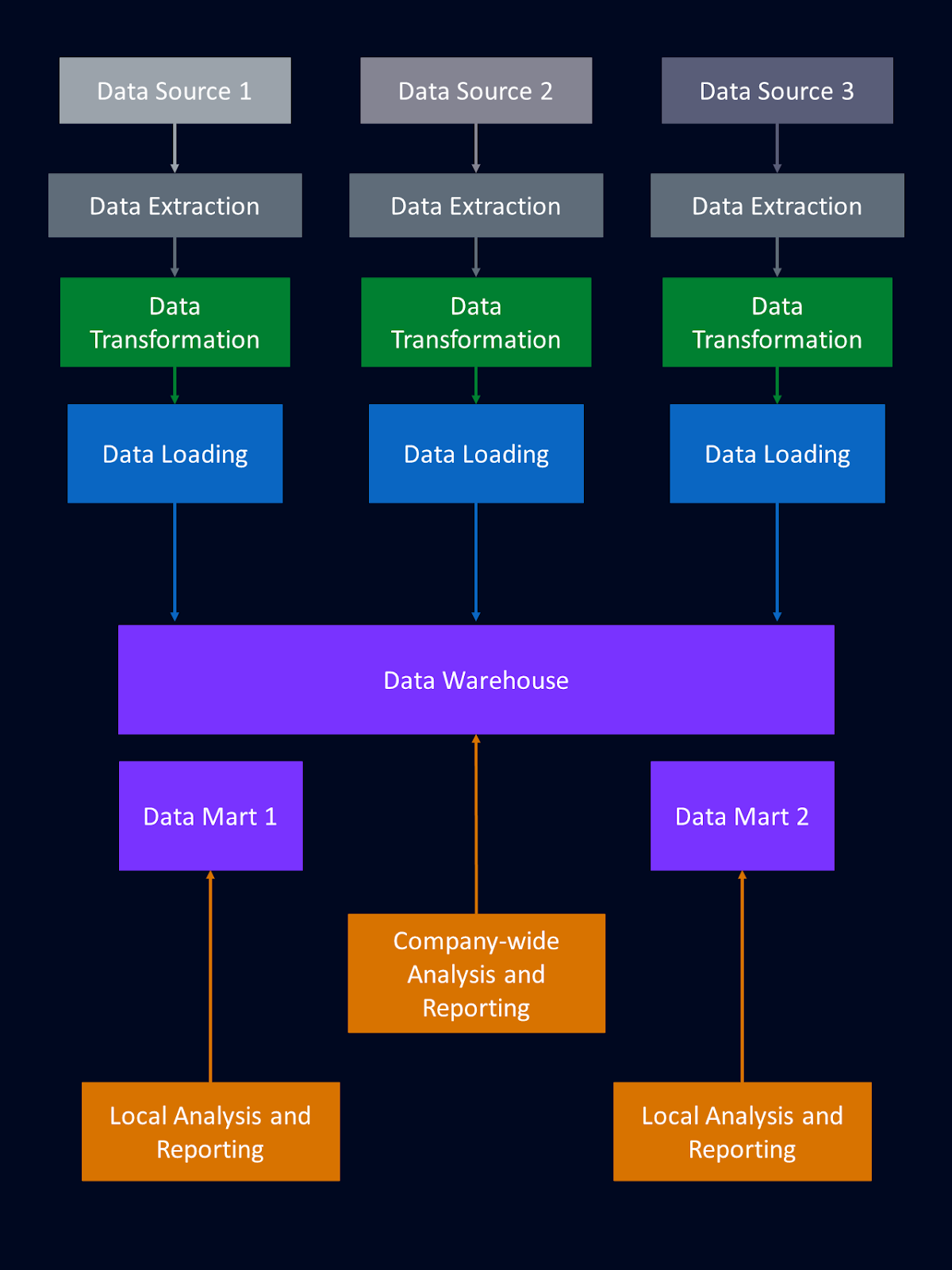
The above diagram shows how subsections of the data warehouse can be set up as independent data marts.
To access and analyze data in the warehouse, we use a variety of tools designed for data retrieval, manipulation, and visualization.
A SQL client is a software application that allows us to connect to a database. They help us to write and execute SQL queries to retrieve and manipulate data. SQL clients help us perform tasks like querying data, updating records, and creating tables. You may be familiar with some popular SQL clients like MySQL Workbench and pgAdmin. If you’re interested in managing server systems, Introduction to SQL Servers is a great place to start! Or check out the SQL Server Developer Track.
Business Intelligence platforms provide a comprehensive suite of tools for data analysis, reporting, and visualization. They empower us to create detailed reports and gain insights from our data. Visualization tools, such as Tableau, Power BI, and Looker, are particularly popular. They make it easy to create interactive dashboards and visualizations. Learn more about common BI tools in Tableau Fundamentals or PowerBI Fundamentals.
Analysis tools like these empower us to harness the full potential of the data stored in our warehouse.
A data warehouse offers advantages that can enhance an organization's data management capabilities.
A data warehouse offers the benefit of centralized data management. It provides a single source of truth for reporting and analysis. This centralization ensures consistency and reliability across an organization’s data, eliminating inconsistencies that can occur when data is scattered across multiple sources.
Another significant advantage is the ability to perform historical analysis. Data warehouses store historical data, allowing us to conduct trend analysis and make historical comparisons. This ability provides insights into long-term trends and patterns in our data, which can be important when planning or forecasting future trends.
Improved data quality is a key benefit of using any centralized data management system, including a data warehouse. The data is standardized and cleaned to ensure accuracy and consistency. Any analysis or reporting based on this data is more reliable because of this consistency.
Data warehouses are optimized for complex analytical queries. This optimization provides quicker and more efficient data retrieval, which is particularly important when we rely on timely insights to drive business decisions.
BI tools leverage the centralized data in the warehouse to provide actionable insights. Most common BI tools are well-equipped to use data from a data warehouse.
A data warehouse serves as a rich source of data for advanced analytics, including data mining and machine learning. The structured nature of data in a warehouse makes it easy to develop sophisticated predictive models. These models, in turn, help us anticipate trends, identify opportunities, and mitigate risks.
While a data warehouse is not ideal for every situation, there are circumstances where we should definitely consider if it’s the right solution for our needs. Let’s cover a few situations where we should consider using a data warehouse.
If our organization faces challenges with managing data scattered across various systems and applications, we may consider using a centralized data management system, like a data warehouse. A data warehouse can consolidate this diverse data landscape, streamlining comprehensive analyses.
For situations requiring historical analysis or where we need to understand trends and patterns over time, a data warehouse may offer the necessary historical context.
If our operational systems struggle with running complex queries efficiently, creating a more structured data system may improve efficiency. In this case, we may consider using a data warehouse. A data warehouse optimizes performance, supporting quicker access to data.
A data warehouse can be part of a robust data management plan in many situations. And a good data management plan is necessary to making our data work for us.
A data warehouse is a powerful tool for harnessing the full potential of our data. Data warehouses provide a centralized, integrated, and structured repository for our data.
Learn more about data warehouses in DataCamp’s Data Warehousing Concepts course. I also recommend What Is a Data Federation and What Is a Data Fabric as good further reading on this subject.
Ensure compliance and protect your business with DataCamp for Business. Specialized courses and centralized tracking to safeguard your data.
Learn AI for business!
Track
Course
Course
blog
DataCamp Team
4 min
blog
Amberle McKee
13 min
blog
Amberle McKee
12 min
blog
Vinita Silaparasetty
15 min
blog
Amberle McKee
10 min
Tutorial
Josep Ferrer