How DataCamp creates the best data science curriculum
At DataCamp, we pride ourselves on having the best platform and the best curriculum for learning data science. To this end, we put a lot of effort into ensuring that every exercise is both effective at educating and enjoyable. After a course is launched, we don't consider it to be complete: the launch is just the start of data collection. Whenever a student attempts an exercise in a course, we capture data points such as how many attempts it took them to solve the exercise, and whether or not they needed assistance by asking for the hint or solution. By aggregating this data over all our students, we can get a picture of how difficult an exercise is. Additionally, students can rate exercises from one star to five stars, and provide feedback to us, letting us know how well liked an exercise is.
Our Content Quality team works with the instructors to act upon this data to improve the courses. This takes a variety of forms since many things can go wrong with an exercise.
1. Fixing missing data
Sometimes, small things can upset a lot of students. In Data Science Toolbox (Part 1), students learn how to write Python lambda functions using a dataset based upon J.R.R. Tolkien's Fellowship of the Ring, from the Lord of the Rings trilogy of books. Unfortunately, the dataset was missing Gandalf and Pippin. Our students quite rightly complained, so we listened and fixed the problem.

2. Avoiding misconceptions and confusions for DataCamp learners
Analyzing the feedback over many exercises can reveal patterns in misconceptions that students have. Many data analyses keep their data in a rectangular form where each row is some record, and each column is a value belonging to that record. For example, each row could correspond to a person, and the columns could be their name, their height, and their favorite color.
A really common data manipulation practice is to filter the rows of that rectangular data. An instructor might write an instruction like:
Filter the dataset to remove rows where people are shorter than 170cm.
This is OK, but most statistical software, including R's dplyr package and Python's Pandas package, make you filter datasets by specifying the things that you want to keep. If the instruction is rewritten in the following way:
Filter the dataset to keep rows where people are taller than 170cm.
Then the instruction matches the way that the code works, and avoids a point of confusion for students. For advanced courses where students are expected to be familiar with data manipulation, this phrasing would be less of an issue. In our Pandas Foundations course, we spotted that many students were struggling with this problem, and changed the language.
3. Creating a happy learning path using more comprehensive and granular feedbacks
All DataCamp exercise are automatically graded using software built by our Content Engineering team. This allows instantaneous intelligent feedback for the students if they get an answer wrong. It's perhaps the greatest feature of our platform. One of the hardest parts about this is anticipating what students will do wrong in order to give them good advice about what to differently next time. That means that occasionally a correct solution gets marked as incorrect. When this happens, students really hate it. In one case, a student complained:

In our Cluster Analysis in R course, many students had spotted that although the suggested solution to an exercise used the well-known min() function to calculate a minimum value, there was a simpler and more elegant solution using the lesser-known parallel minimum function, pmin().

Originally, the exercise only allowed one solution but based upon the students' ingenious idea, both solutions are now accepted. One of the Content Engineering team's goals in developing DataCamp's feedback system is to improve the flexibility of the grading, allowing students to solve problems in their own way.
Another frustration that students can encounter with our automated feedback is seeing the same piece of feedback repeatedly when taking an exercise. The principle is shown in the diagram below, where a student is asked to create a Python array with three elements.
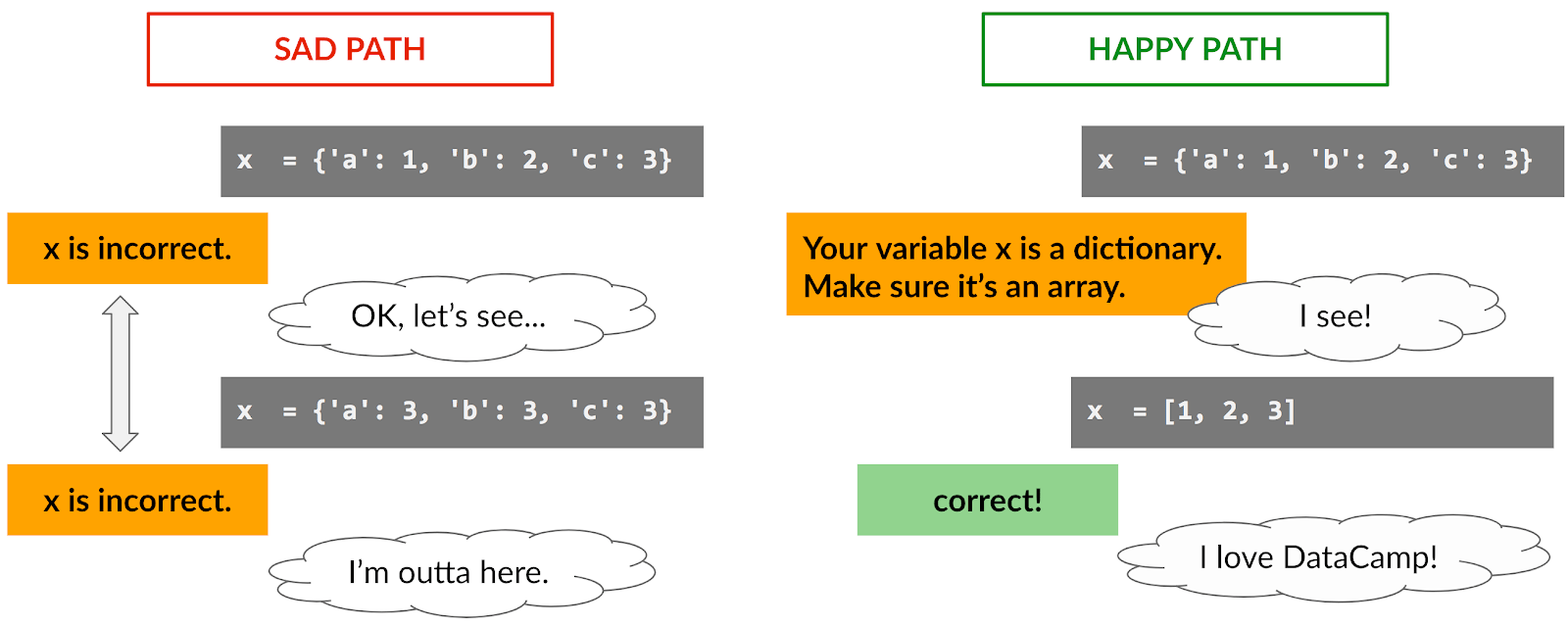
By providing more granular feedback, to address specific problems with a student's answer, we can provide a more positive learning experience. The results of improved feedback are encouraging. In an exercise from our Intermediate Python for Data Science course, switching to granular feedback meant that the percentage of students seeing the same feedback message more than once dropped from around 65% to under 10%.
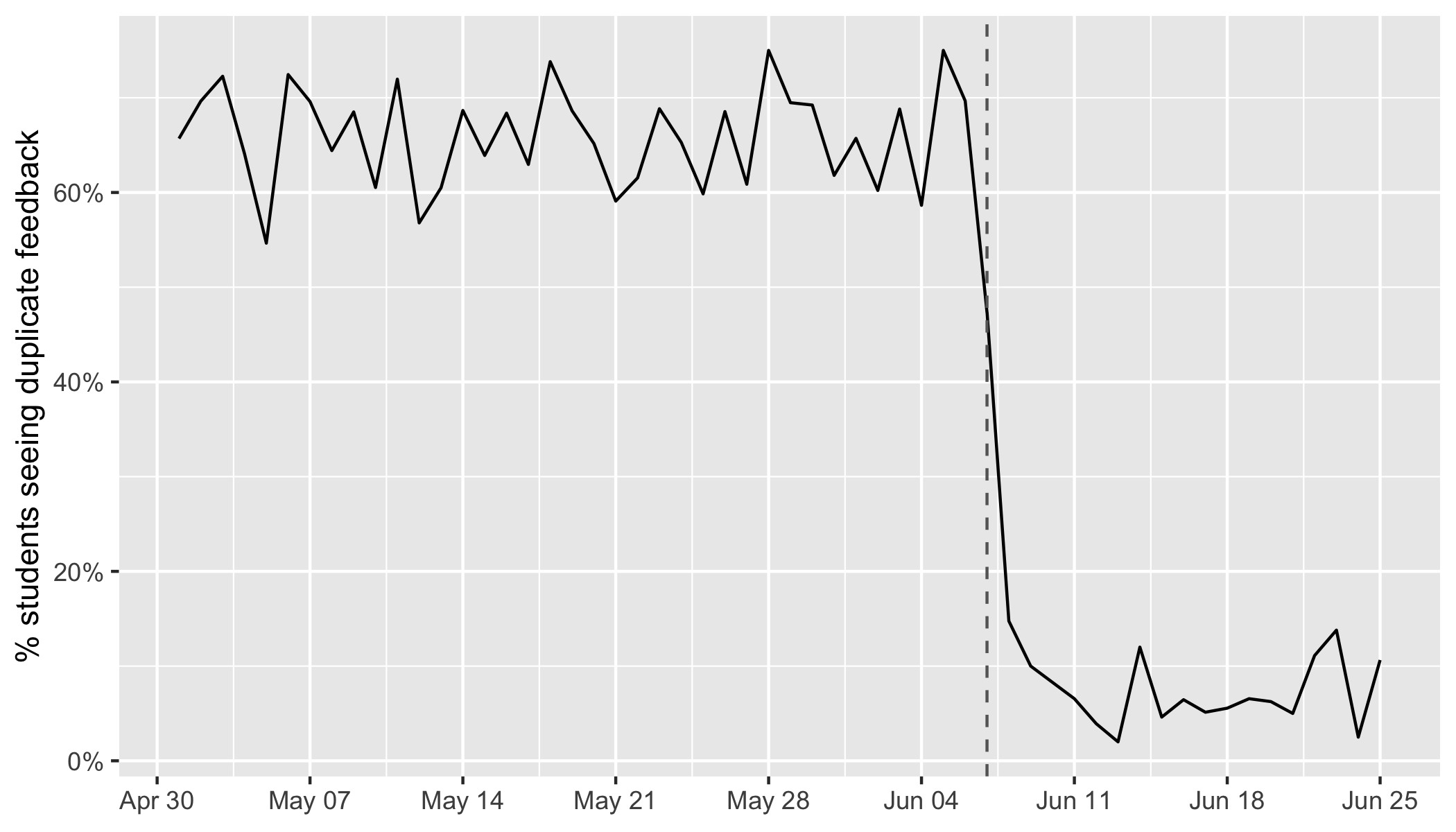
The percentage of users seeing the same feedback message more than once is a metric we monitor for all exercises and courses. In combination with the popularity of courses, we created a data-driven way to keep improving the learning experience in the most impactful way.
Conclusion
Our goal for the end of the year is that for the most popular half of all courses, the average of the repeated feedback percentage over all exercises is below 30% for each course.
We will continue to add these improvements across all the technologies students can learn on DataCamp. Internally we also improve the tools we use to create the feedback and analyze student submissions to make sure we keep improving the learning experience for all current and future content.
There are many more things that can go wrong with an exercise, but I hope that this gives you some encouragement that DataCamp listens to student feedback, and is continually working to improve student satisfaction with our courses.