This article was written by Richie Cotton, with contributions from Ramnath Vaidyanathan, Dieter De Mesmaeker, and Martijn Theuwissen.
Online education is an exciting field right now because there is constant innovation. Every company in this space, including DataCamp, is still trying to figure out the best way to help people learn. DataCamp's product and engineering teams are constantly developing new tools to teach data science more effectively, which our content teams incorporate into our existing and future content.
Four DataCamp instructors—Ben Baumer, Andrew Bray, Mine Çetinkaya-Rundel, and Jo Hardin—recently published a paper in the Journal of Statistical Education on their experience of creating courses at DataCamp, and their thoughts on the differences between live and online learning. These instructors were all early supporters of DataCamp, and we appreciate them articulating their experiences.
In this post, we want to go over their feedback, talk about pedagogy at DataCamp, show some of the improvements we’ve made since the authors created their DataCamp courses, and clarify our position on certain remarks made in the paper.
The courses
The instructors created eight courses between 2016 and 2018. First came a series of four courses on descriptive statistics: Introduction to Data in R, Exploratory Data Analysis in R, Correlation and Regression in R, and Multiple and Logistic Regression in R, which are included in the Statistics Fundamentals with R skill track. These were followed by four courses on inferential statistics: Foundations of Inference, Inference for Categorical Data, Inference for Numerical Data, and Inference for Linear Regression, which comprise the Statistical Inference with R skill track.
In total, these courses reached over 94,000 students. The highest rated course has a rating of 4.55 (on 5) and the lowest rated course of 4.33. Being some of our more high-volume courses, these courses have earned so far in their lifetime $475,000 in royalty payments towards the four instructors.
The benefits of DataCamp
The paper highlights many of the strengths of DataCamp. To start with, the four academics note that universities are expensive.
our institutions [...] have an average annual cost of attendance of $71,156.25
That's the price of a luxury car each year, which certainly highlights DataCamp's fantastic value at a quarter of the price of a New York subway pass. While it is true that we are a for-profit entity, we'd like to highlight our free DataCamp for the Classroom program that provides teachers and students unlimited access to our full course library. Since its inception, we’ve had more than 200,000 students participate in this program. This sets us apart from the high tuition fees for private colleges and universities, and we are proud of that.
For learners, they noted that using video has an important benefit over live teaching in that it provides more control over pacing.
First, having videos instead of an in-person instructor means that the student can stop the video, slow it down, and/or go back and repeat the video. That is, each student can take the ideas in at their own pace. Additionally, unlike in a standard classroom, a student can pause the video to look up a definition or contextualize an example.
The instant feedback provided via the automated testing in our coding exercises was also favorably cited.
Students receive instant feedback on the DataCamp coding exercises. This relieves some of their frustration and also frees the instructor from having to answer some of the frantic emails from students.
For lecturers, learning and development managers, and other teachers, DataCamp’s scalability was noted as an important feature. Our platform liberates educators from the pressure and monotony of grading assignments.
Each additional student in your class requires extra time and effort from you to grade their assignments, meet with them during office hours, make room for them in the classroom, etc. Conversely, DataCamp will deliver content to an unlimited number of students asynchronously.
What's new?
Since 2016, DataCamp has invested in a lot of improvements.
The assess-learn-practice-apply loop
In 2016, DataCamp had one product: our courses, designed to help learners acquire new skills. Over time, DataCamp's pedagogical vision has coalesced around the cycle of assessing your current abilities, learning new skills, practicing those skills, applying the skills in new contexts, then back to assessment to see how much you've improved. The image below shows the assess-learn-practice-apply loop.
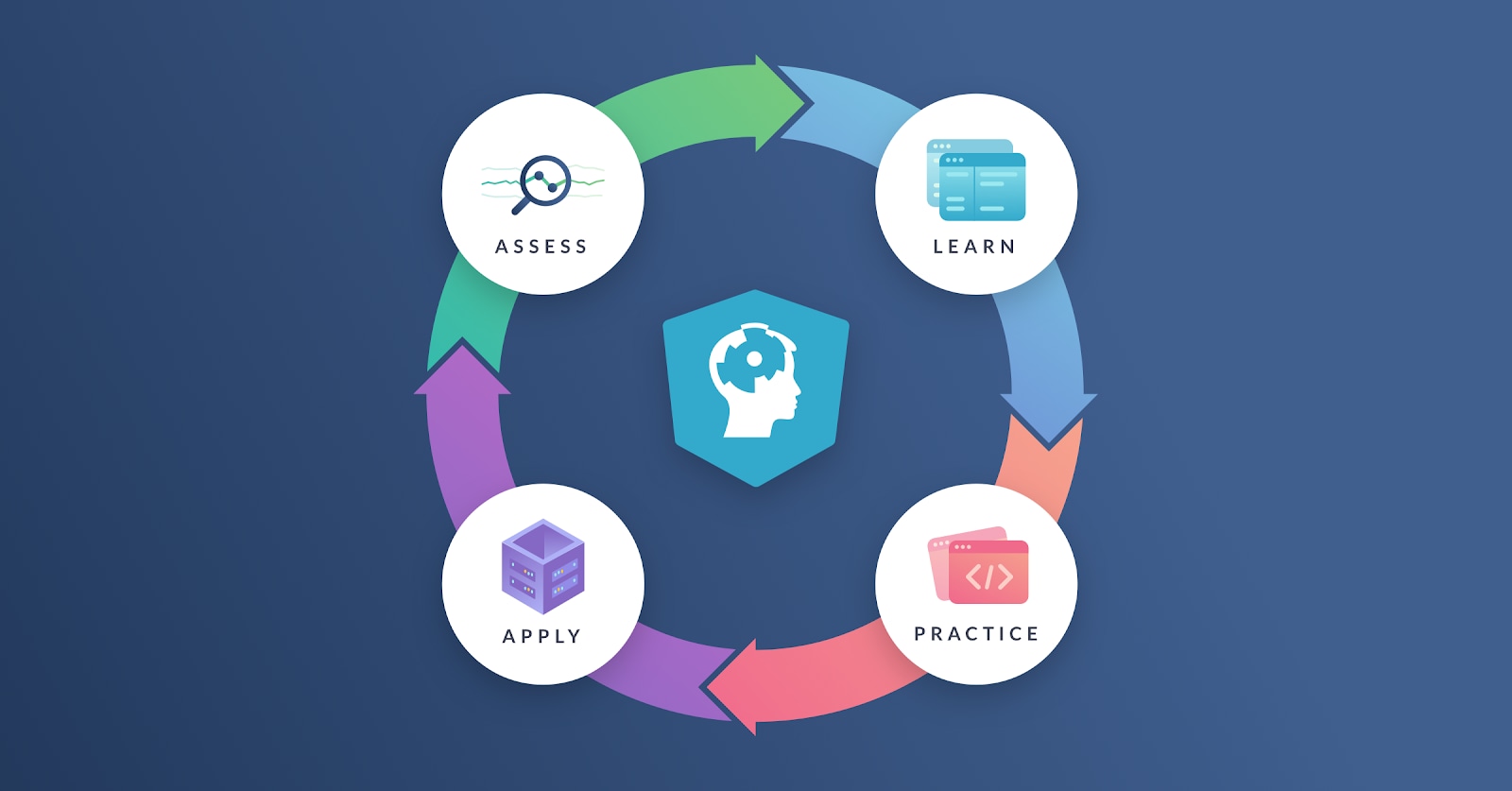
Figure 1: The assess-learn-practice-apply cycle that forms the basis for DataCamp's pedagogical philosophy.
To help learners complete this loop, we added three new products.
Practice
In 2017, we added DataCamp Practice, which contains short coding challenges that closely match the contents of courses to reinforce learning. The example below shows a multiple choice question testing skills learned in the Introduction to the Tidyverse course.
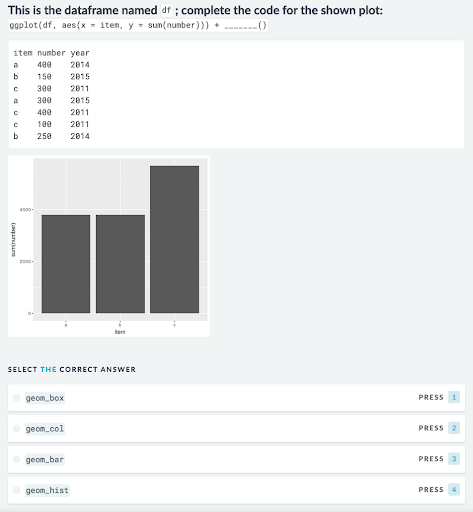
Figure 2: An exercise from DataCamp Practice testing data visualization skills.
Projects
That year also saw the launch of DataCamp Projects, which allows students to apply their skills to new, real-world problems using one of the most popular data science environments: Jupyter Notebooks.
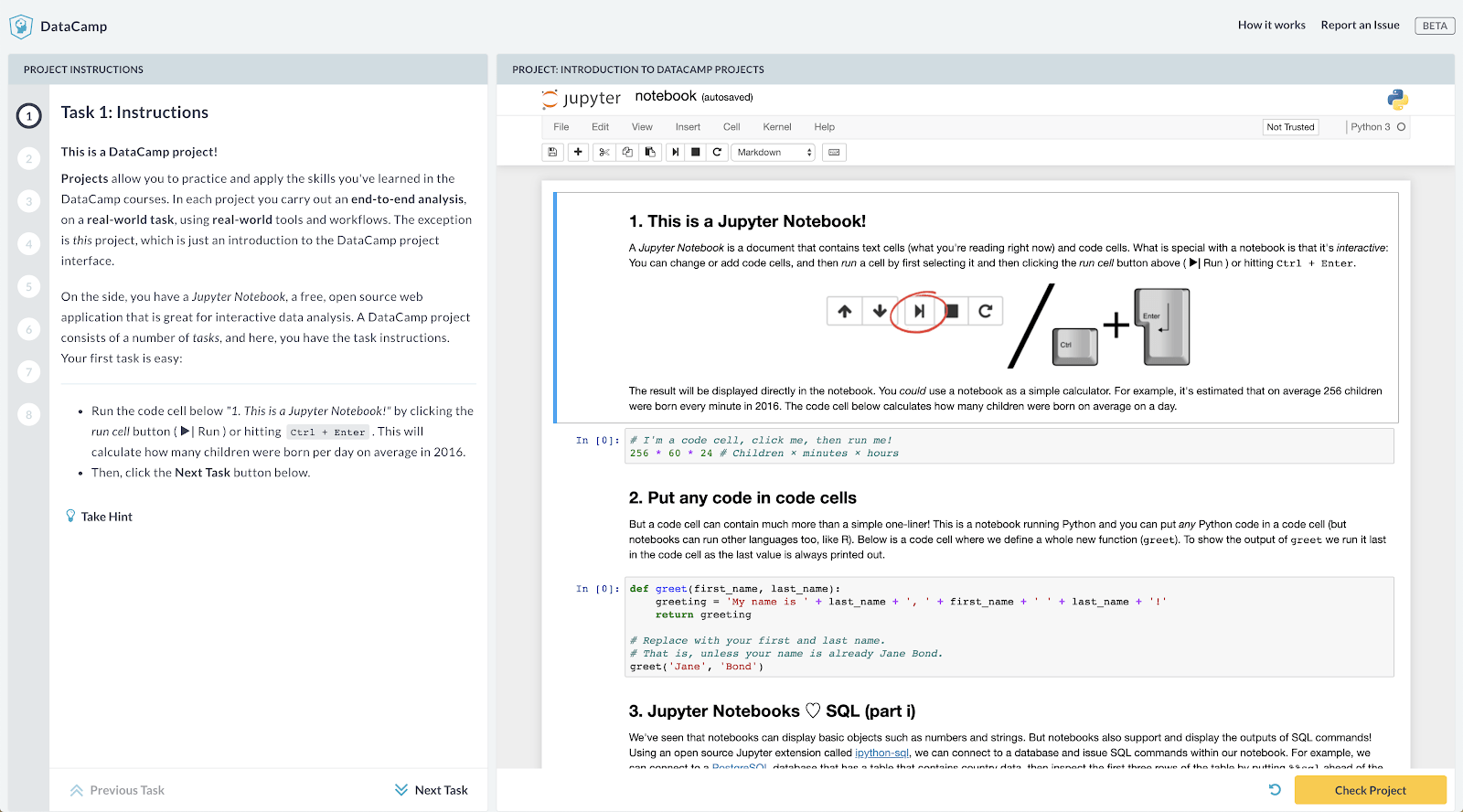
Figure 3: A Project letting learners apply their skills in SQL.
Assessments
The final step in the loop came in 2019 with the launch of DataCamp Signal, our skill assessment product allows learners to measure how much they have learned. Skill assessments are conceptually like practice mode taken under exam conditions: learners are tested on content related to corresponding courses, but each question has a time limit, and learners are given a score based on how many questions they answer correctly and their difficulty. You can read more about Signal’s use of adaptive testing and psychometry here.
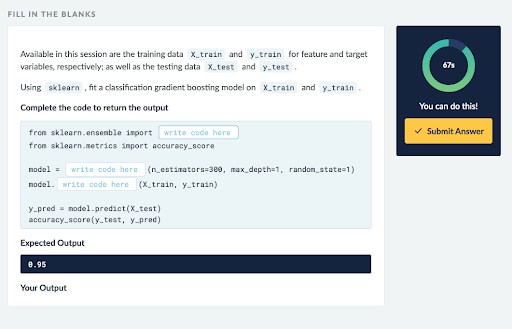
Figure 4: A Signal skill assessment question testing Python machine learning ability, under time pressure.
Improvements in courses
As well as introducing three new products, DataCamp has made improvements to our courses by adding several new exercise types. One area in which the JSE paper was particularly prescient was that DataCamp was in need of support for graphical "point and click" exercises.
Some teaching strategies were not possible using the DataCamp platform, but we could see the platform expanding to incorporate such methods as it develops more sophisticated presentation capabilities. In particular, it was not possible to use the DataCamp platform to walk through using an applet to explain a particular concept.
Explorable exercises
In 2019, DataCamp devised a new exercise type that we call an "explorable exercise." These allow dashboards, interactive visualizations, and even web-based software to be included in exercises. One way to create these exercises uses a tool called Shiny—a more modern version of the Java applets that the paper refers to. (We also have a series of courses on using Shiny for learners who are interested in making their own.)
The explorable exercises have been put to good use in DataCamp's "For Everyone" series of courses, which are designed for those who need to understand data but don't have a data science or analytics background. The Data Visualization For Everyone course, in particular, makes great use of dashboards to help learners explore how making changes to plots affects their ability to answer questions about them.
In the example below, learners can explore how changing the colors in a plot affects their interpretation of survey responses.
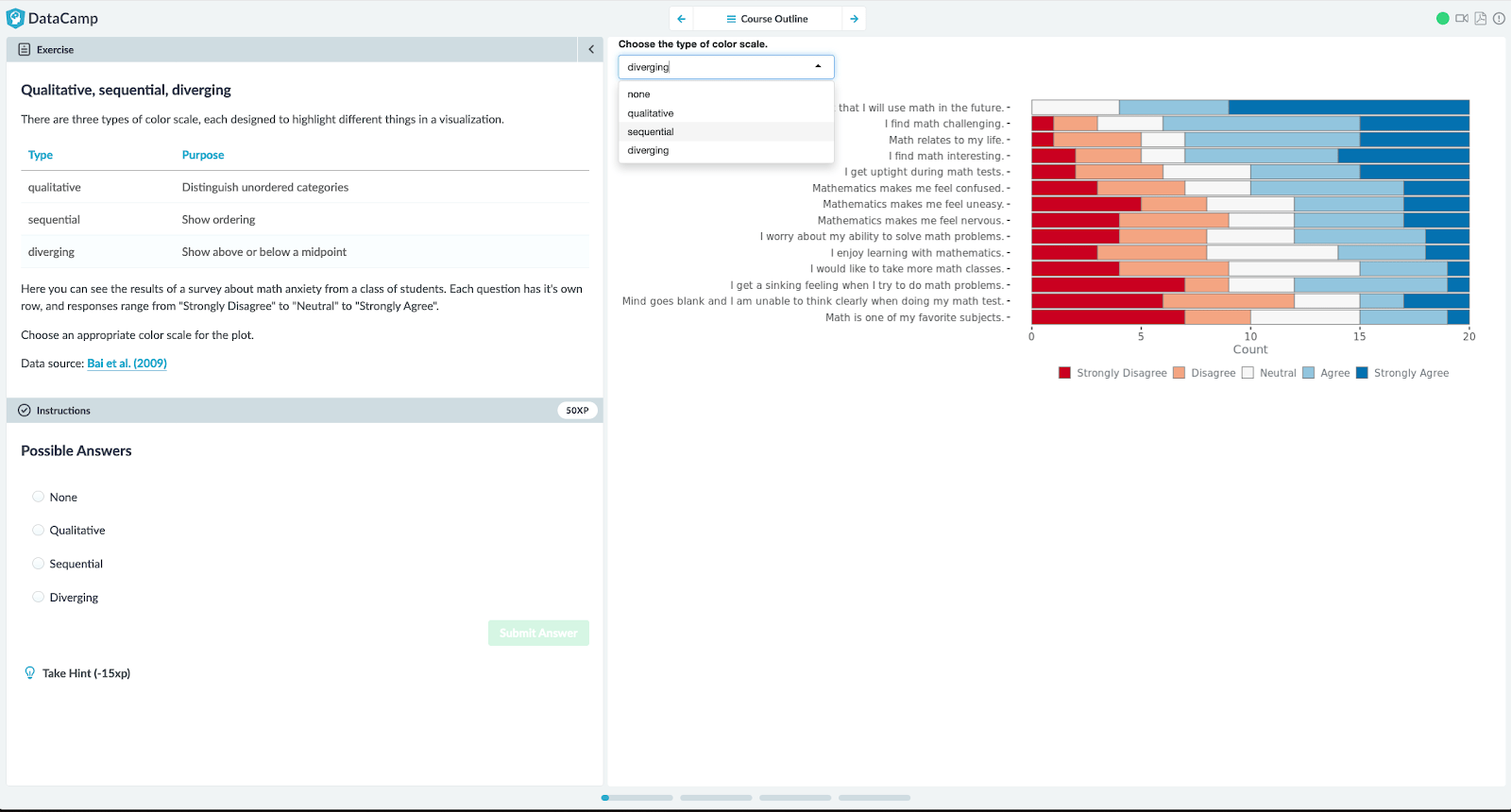
Figure 5: An explorable exercise featuring a dashboard to let learners explore the effects of color choices in a stacked bar plot.
One area where DataCamp received criticism in the early days was that although our coding exercises are excellent at teaching how to write chunks of code, it was easy for learners to get lost in the weeds without knowing how to combine them together. While DataCamp has always understood the value of teaching workflows and encouraged instructors to describe them in videos, we needed a more powerful tool. Last year, we implemented another new exercise type to do just that. Drag-and-drop exercises let learners solve exercises by moving items around on the screen. There are several variants, but the most important one for teaching workflows is called an "ordering exercise."
In the example below taken from Introduction to Writing Functions in R, learners are asked to reorder steps in a workflow for converting a script into a reusable function. By stepping away from asking learners to write code, they’re able to focus on the concept.
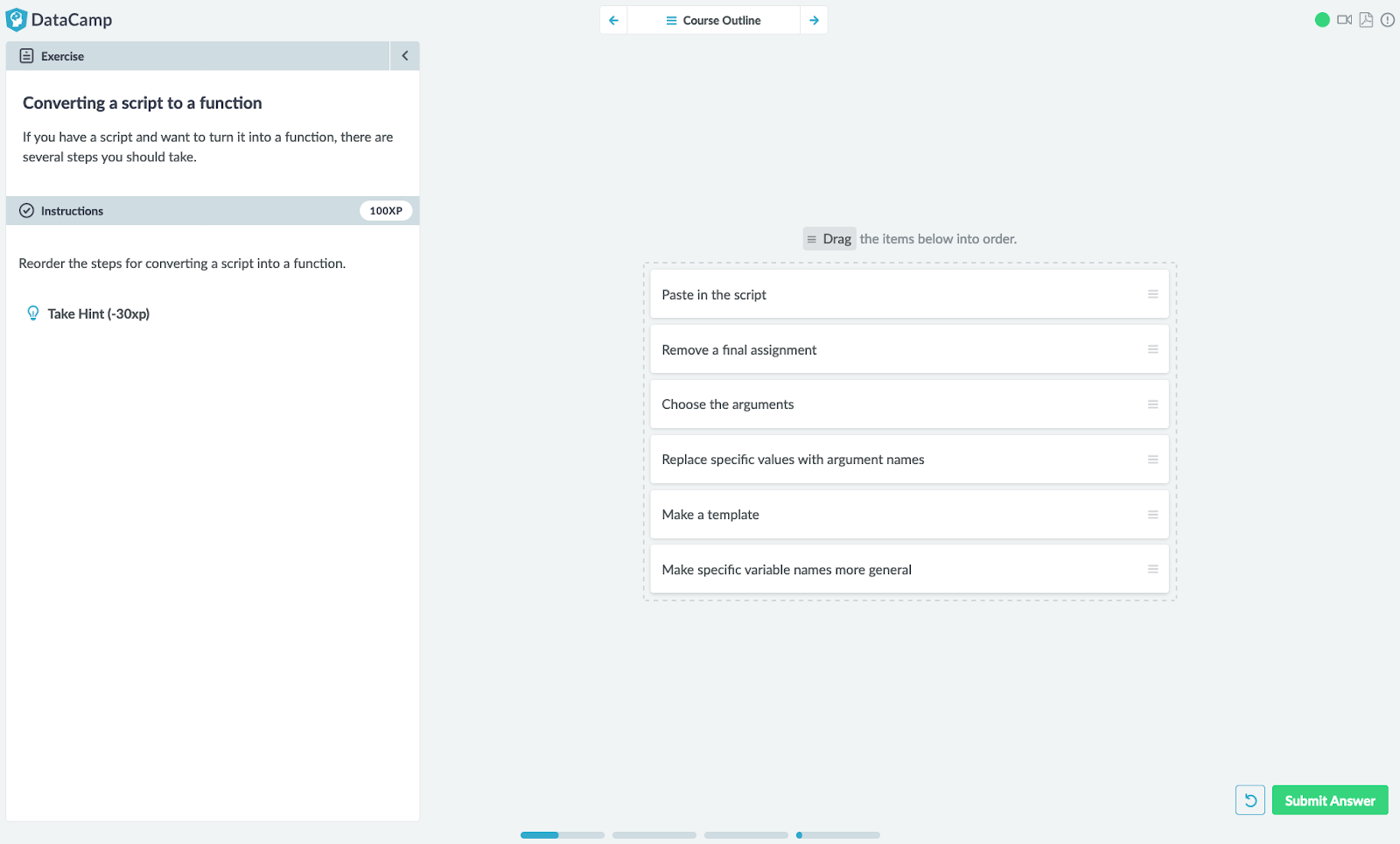
Figure 6: A drag-and-drop exercise to teach a workflow by ordering steps.
In addition to the explorable exercise and drag-and-drop exercises, we added many more exercise types and content modalities. Some of the most notable are:
IDE exercises
The IDE exercise uses one of the most popular code editors called Visual Studio Code. This exercise type is used in our more advanced data engineering content.
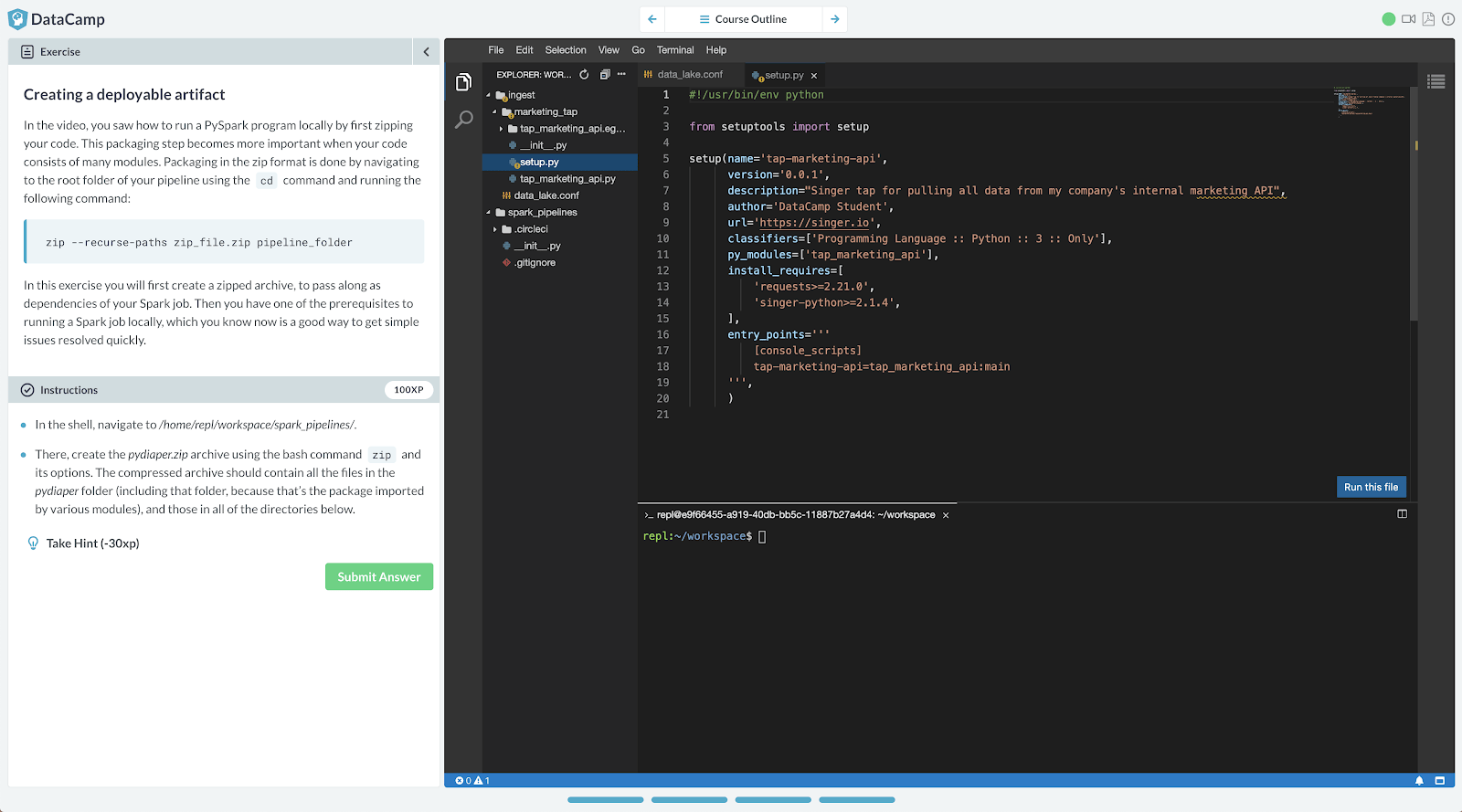
Figure 7: An IDE exercise, testing "devops" skills to deploy code using the Visual Studio Code development environment.
VM exercises
And most recently, we created the VM exercise, which runs a Windows Virtual Machine with specific software pre-installed. These are mostly used in our Tableau content.
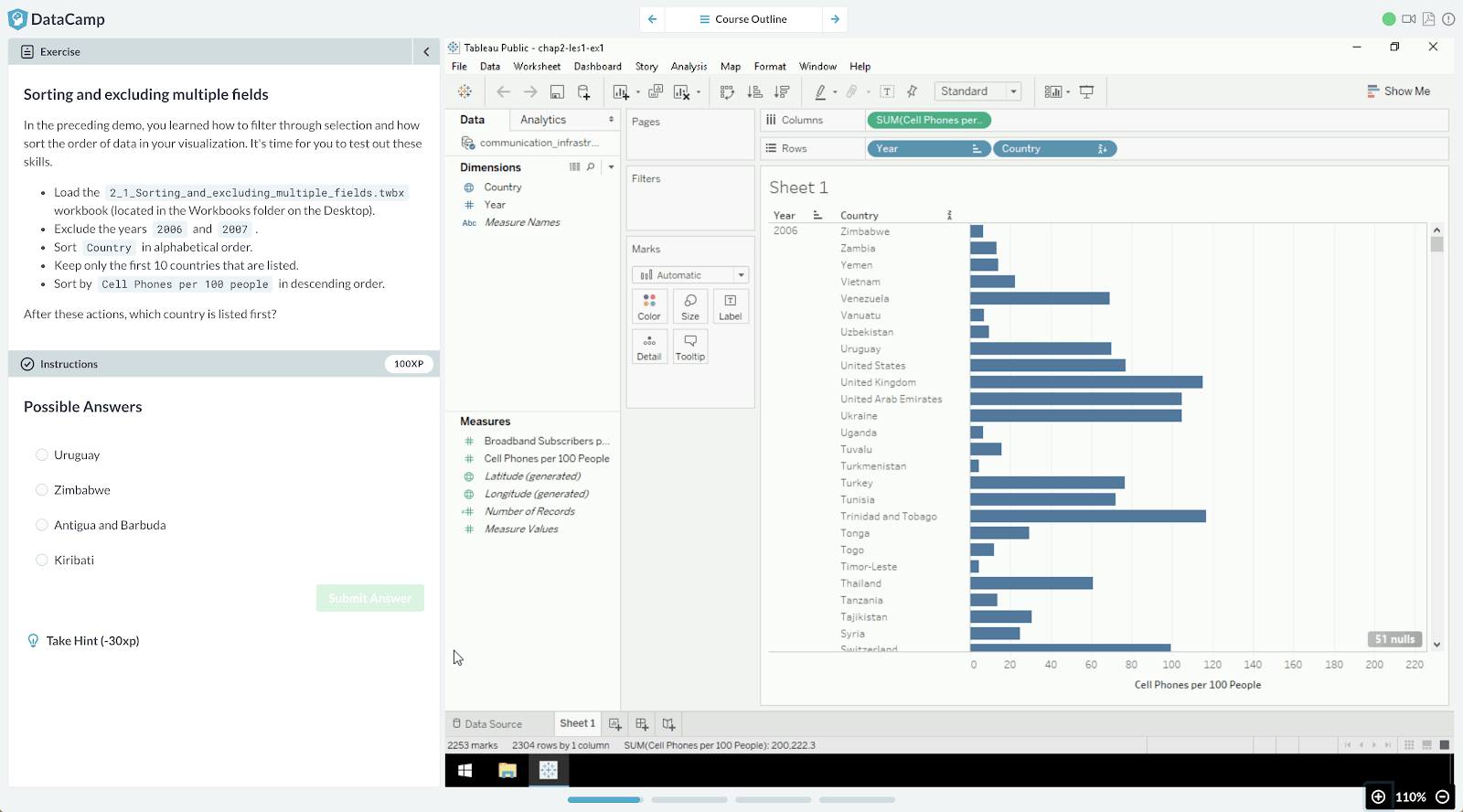
Figure 8: A VM exercise teaching learners how to manipulate data in the Tableau business intelligence tool.
Some of the suggestions made in the paper are tricky for an online platform like DataCamp to implement, like the following:
In the brick-and-mortar classroom, we divide students into teams and each team receives a bag with 20 pieces of paper, each with the rent of a sampled apartment printed on it. Then, each team is asked to take a bootstrap sample of 20 apartments from their bag, calculate the median, and record it on the board by placing a dot on the dotplot. The process provides students with personal experience sampling with replacement in order to build a bootstrap distribution of sample medians.
While instructors can’t interact with learners on our platform, we certainly agree that fun games are an important component of live teaching. That’s why, in our latest Hackathon, one of our engineering teams explored the creation of DataCamp VR. Although this might be a few years away, we see innovation as a critical part of our company (and we had a lot of fun!).
More seriously, it's a misconception that online education and live instruction are in competition. At DataCamp, we certainly see them as complementary. That's why DataCamp has launched a series of live coding webinars, where learners can interact with an instructor more closely. Find our upcoming webinars and live trainings here.
Continuous improvement
Unlike other education media like textbooks, which are effectively considered complete when they are published, on DataCamp, the development of learning materials does not stop when a course is launched. Instructors are actively encouraged to improve their courses to deliver a better experience to their learners by rewriting unclear instructions, clarifying unclear concepts, and keeping the contents up to date in the fast-moving world of data science.
Interestingly, the series of inferential statistics courses created by the authors of the paper were a major motivating factor for some of the technical and process improvements made by DataCamp. While the courses were certainly popular, quantitative data such as course ratings and completion rates led us to understand that there was significant room for improvement. The big problem is that inferential statistics is both conceptually difficult, and requires moderately advanced programming skills in order to expose those concepts.
To remedy the situation, DataCamp's Content Quality team worked with the instructors to completely rewrite the four courses. Content Quality Analysts helped change the pacing to more gradually introduce new code, rewrote instructions, and simplified the code to help learners focus on the conceptual aspects. The result is that these are now four great courses—for advanced learners.
In the spirit of continuous improvement, an upcoming challenge for DataCamp's Content team is to figure out how to teach inferential statistics to complete beginners. Watch this space!
Improvements for Learning and Development Managers
The JSE paper performed a great job of highlighting the pros and cons of teaching on DataCamp, but it had a slight inaccuracy when it stated that
DataCamp courses are asynchronous and self-paced, so [there are] no deadlines for the student to worry about.
This is true for the majority of learners. If you take a personal subscription to DataCamp, you can learn at your own pace and consume content in a way that suits your lifestyle. However, for our business and academic customers, DataCamp has developed a set of administrative tools to help administrators and instructors keep track of how their employees and students are progressing:
- Assignments: We support instructors and admins to set course or XP assignments with a deadline. The group admin will automatically receive an export of the relevant data once the deadline has passed.
- Reporting: Since we first launched DataCamp for business and academic customers, we greatly increased our reporting capabilities, and offering automated insights on the group’s engagement, adoption, content usage, assessments usage, etc. within the application.
- Low-level data: Admins can export low-level data from their groups and classes so they can make their own dashboards locally if preferred.
- LMS integrations and SSO: In 2019, we extended our learning management system (LMS) integrations to other providers like SAP SuccessFactors and Degreed, and we added single sign-on (SSO) for increased security.
Improvements for instructors
When DataCamp first launched, we rushed to create as many courses as possible because without any courses, we had no learners. As our course library has grown and our user base has become more diverse, racing to fill in curriculum gaps has become less important than other considerations like "where does this course fit relative to our other courses?" and "who will be interested in taking this course?"
That means that at the beginning of course development, we spend considerable time discussing the target audience with the instructor. For example, the approach to explaining concepts to an audience of machine learning experts is very different than the approach to explaining concepts to managers of data scientists, who may be less technical but have to give critical feedback on the results of an analysis.
It's also become clear that many of our learners prefer to take sequences of courses via our career tracks and skill tracks. That means that during development, we ask a lot of questions about what learners are expected to know before they begin the course, which other courses they should have taken before, what they are expected to learn by the time they have completed the course, and which other courses it might lead to. Taking courses isn't done in isolation—it's a journey to being more data literate.
Once the scope of the course is determined, we need to ensure that learners actually learn something! DataCamp works with our instructors to determine a set of learning objectives for the course using Bloom's taxonomy—a framework for describing the level of proficiency at a given task. These learning objectives feed into the DataCamp Signal skill assessments.
Of course, all this can be a lot to take in for new instructors. That's why DataCamp provides a lot of support during the course creation process. Each instructor typically receives over 80 hours of guidance from DataCamp employees—all professional data scientists and educators—on how to structure the course to provide a good narrative, how to write good exercises, and to provide technical peer reviews on their content. Additionally, we have a meta-course on how to create DataCamp courses, and extensive documentation providing guidance on how to find interesting datasets and how to record high quality audio, among other things.
Once courses are launched, DataCamp provides another benefit over live instruction: instructors get quantitative feedback on how their courses are performing. The difficulty level of each exercise is assessed via the proportion of learners asking for hints and solutions, allowing instructors to determine where learners get stuck. Wrong answers are also recorded, so instructors can determine what sort of mistakes learners are making and update exercises for clarity. Learn more about DataCamp's approach to improving course quality in this blog post.
In some cases, we've found that DataCamp exercises are hard just because the underlying code we want to teach is difficult to use. In fact, the inferential statistics courses mentioned in the JSE paper were based on an R package called infer, and several DataCamp employees helped develop that package in order to make it easier to use. At DataCamp, we are really proud of this feedback loop of teaching inspiring development. Identifying complex bits of code and helping developers fix problems makes software easier to use for everyone.
Conclusion
We’re glad that our instructors took the time to articulate their experience of creating content for DataCamp. Two hundred and seventy-six people have now gone through the instruction process, contributing to our mission of democratizing data science.
Online education is extremely relevant right now given that many people are at home. In our mission to democratize data literacy for individuals and companies, our product, content, and engineering teams are constantly looking to improve the way we teach data skills. Look out for further developments!
Happy learning.
Appendix: Clarifying DataCamp's position on remarks in the paper
We'd like to clarify our stance on some of the points presented in the JSE paper.
- The JSE paper questioned the maximum length of DataCamp videos and proposed that instructors should be able to "dedicate 10-20 min to talking through topics." The time limit we impose on videos is based on a research post by edX on optimal video length for student engagement. We have some long-form video content via webinar recordings, but feel that longer videos would spoil the flow in courses.
- At DataCamp, we support open source contributions. Both past and current DataCamp team members contributed to the infer package in both their free and working time: Chester Ismay, Nick Solomon, and Richie Cotton (source).
- Although mentioned in the paper, we have no exclusive contracts in place with instructors. Intellectual property remains with the instructor.
- We recognize that as a for-profit entity we make decisions differently, but always in the best interest of the learner. Our incentives are fully aligned toward creating high quality learning material, which directly influence the value for our customers. This is why we keep track of such detailed metrics as mentioned in the paper.
- Similarly to how the commercial relationship with DataCamp was disclosed, we believe it would have been appropriate to disclose the commercial relationship by one of the authors with RStudio when referencing LearnR, a package created by the team at RStudio.
- In regards to the BuzzFeed article referenced in the paper: DataCamp commissioned an independent, third-party review of the events of October 2017, led by Anurima Bhargava, a former Department of Justice official in the Obama administration, and Pamela Coukos from Working IDEAL. The resulting report was made public and shared online via this blog post. Members of the Instructor Advisory Board (the “IAB”) (including one of the authors of the paper) were invited to participate in the review, as well as other stakeholders, including members of our instructor community.