Track
Containerization and Virtualization with Docker and Kubernetes
13 hr
Containerization has transformed how engineering teams manage and scale applications, particularly in data management, analytics, and machine learning. By packaging applications into isolated and lightweight environments, containers ensure consistent performance from development to production.
Docker stands out as the most popular solution among the different platforms available. Its flexibility and simplicity enable data professionals to build reproducible, scalable, and efficient pipelines while fostering collaboration.
In this article, we’ll outline a practical learning plan for Docker, including steps to deploy your first simple application. Let’s dive in!
Docker is an open-source platform that simplifies the deployment, scaling, and management of applications using containerization.
Containers are lightweight, portable environments that include everything needed to run an application—code, runtime, libraries, and settings—for consistent performance across different systems. In data projects, Docker is used to build and manage these containers, allowing applications to run reliably across any infrastructure.
Unlike virtual machines (VMs), which require their own operating system and a hypervisor to manage them, Docker virtualizes only the application layer. This results in containers that are faster to start, less resource-intensive, and easier to configure.
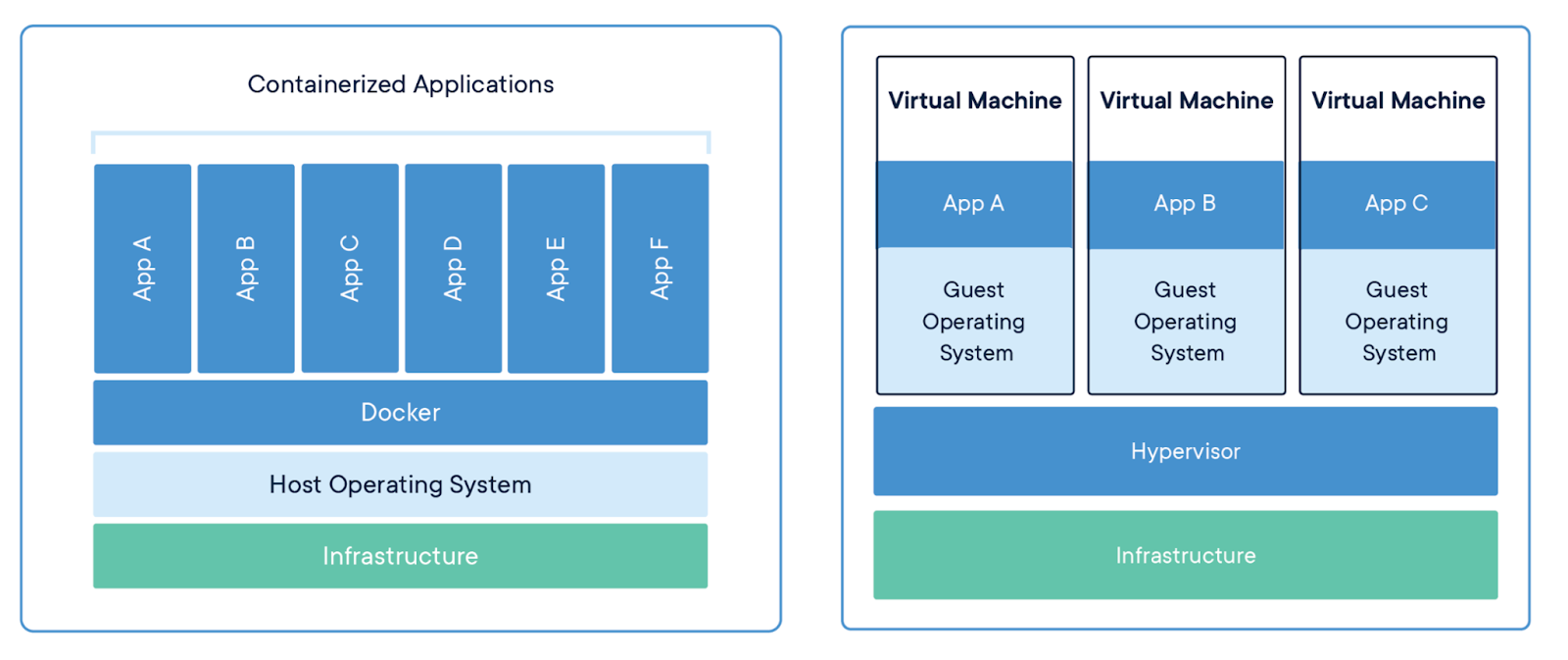
Containerized applications versus virtual machines. Image source: Docker
For data professionals, Docker helps create reproducible environments, enabling data pipelines to run consistently from development to production. It minimizes dependency issues, streamlines workflows, and fosters team collaboration by providing standardized, shareable environments.
Additionally, Docker integrates with popular data tools like Jupyter, TensorFlow, and Apache Hadoop.
Mastering Docker can boost productivity, optimize workflows, and make your projects scalable and easily deployable!
The best way to learn Docker is by getting hands-on. So, let me guide you through your first simple deployment. After this, we will explore learning plans to deepen your knowledge.
Before jumping into Docker hands-on, grasping some fundamental concepts is important. Here’s a breakdown of the main Docker concepts:
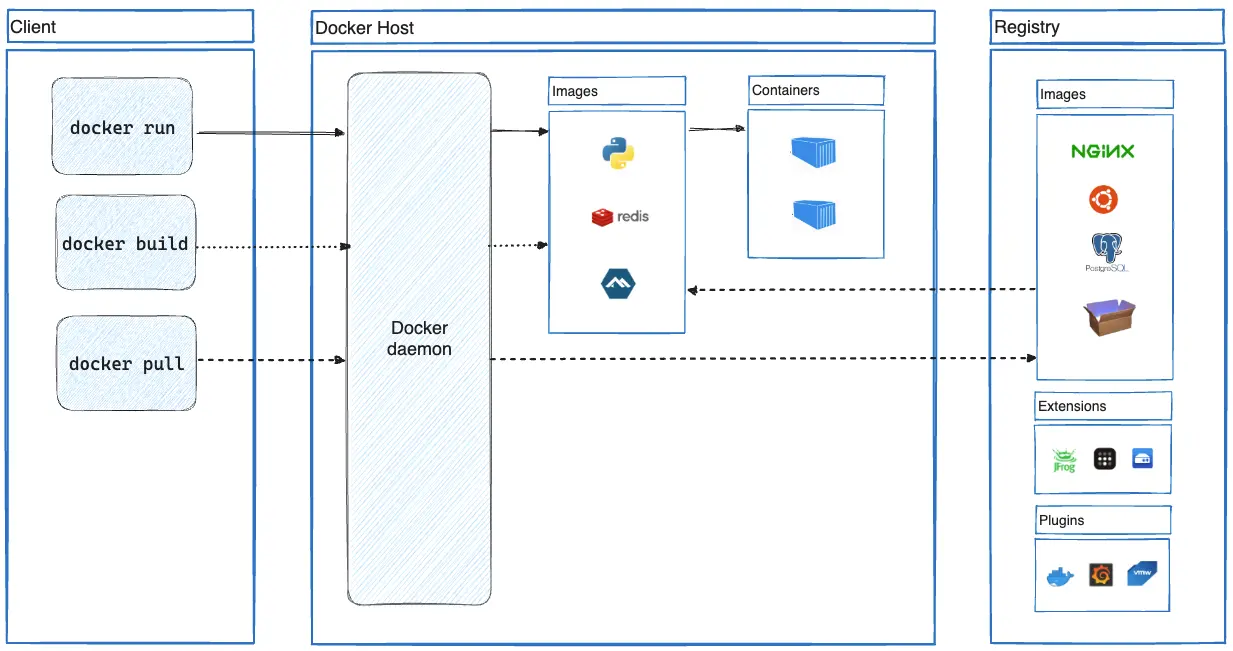
Docker architecture overview. Image source: Docker
Understanding these core concepts is essential before you begin deploying applications with Docker. Mastering these basics will provide a solid foundation, making the hands-on practice more effective.
The Introduction to Docker course can significantly help solidify your current knowledge.
To start using Docker, you'll need to install it on your system. Below are the instructions for different platforms. For more detailed guidance, follow the links to the official Docker documentation.
Requirements:
Steps:
1. Enable WSL 2 (Windows Subsystem for Linux):
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart wsl --set-default-version 22. Install Docker Desktop for Windows:
3. Start Docker Desktop:
4. Verify installation:
sudo docker --versionOfficial documentation: Docker Desktop for Windows
Requirements:
Steps:
1. Download Docker Desktop for macOS:
2. Install Docker Desktop:
.dmg file you downloaded.3. Start Docker Desktop:
4. Verify installation:
docker --versionOfficial documentation: Docker Desktop for Mac
Supported Distributions:
Steps for Ubuntu/Debian:
1. Uninstall old versions:
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done2. Set up Docker’s apt repository:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update3. Install Docker packages:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin4. Verify installation:
sudo docker --versionOfficial documentation: Docker Engine on Debian
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Learn more about Docker with these courses!
Track
Course
Course
blog
Matt Crabtree
8 min
blog
Matt Crabtree
15 min
cheat-sheet
Richie Cotton
Tutorial
Arunn Thevapalan
Tutorial
Bex Tuychiev
Tutorial
Amberle McKee