

programa
Aprendizaje profundo en Python
18 h
Imagina que bajas una colina, pero el terreno cambia a medida que avanzas: algunas partes son empinadas y otras llanas. Si cada vez das un paso del mismo tamaño, puede que te cueste o tardes demasiado en llegar abajo. En el aprendizaje automático, un reto similar ocurre con descenso de gradientedonde utilizar la misma tasa de aprendizaje para todos los parámetros puede ralentizar el aprendizaje.
Aquí es donde entra Adagrad. Ajusta el tamaño del paso para cada parámetro en función de cuánto ha cambiado durante el entrenamiento, ayudando al modelo a aprender más rápida y eficazmente, sobre todo cuando las distintas características tienen escalas diferentes. En este artículo, exploraremos cómo funciona Adagrad y desglosaremos las matemáticas que hay detrás. Además, te mostraremos cómo implementarlo utilizando PyTorch y lo compararemos con otros optimizadores para que puedas elegir el mejor para tus proyectos.
Adagrad (Gradiente Adaptativo) es un algoritmo de optimización utilizado en aprendizaje automáticoespecíficamente para entrenar redes neuronales profundas. Está diseñado para adaptar el ritmo de aprendizaje de cada parámetro en función de sus gradientes históricos. Este enfoque permite a Adagrad mejorar la eficacia de modelos de aprendizaje automáticoespecialmente en escenarios con datos dispersos o cuando los distintos parámetros tienen tasas de convergencia variables.
Adagrad proporciona tasas de aprendizaje más altas para las características menos frecuentes y tasas más bajas para las más frecuentes, lo que lo hace muy adecuado para trabajar con datos dispersos. Además, ¡reduce la necesidad de ajustar manualmente el ritmo de aprendizaje!
Desglosemos el algoritmo Adagrad:
Primero, empieza por:
Para cada parámetro 0t en el paso temporal tcalculas el gradiente de la función de pérdida con respecto a ese parámetro. Este gradiente nos indica cuánto y en qué dirección debemos actualizar el parámetro para reducir la pérdida. Llamemos a este gradiente gtdonde t es el paso temporal actual.
En lugar de actualizar los parámetros directamente, Adagrad realiza un seguimiento de la suma cuadrática de los gradientes de cada parámetro. Para cada parámetro icalcula y acumula el gradiente al cuadrado en cada paso temporal. Este gradiente acumulado se denota como Gt.
Gt =Gt-1 + gt2
Toma:
Este gradiente acumulado ayuda a Adagrad a ajustar el ritmo de aprendizaje de forma diferente para cada parámetro en función de cuánto se haya actualizado.
Ahora que tienes el gradiente acumulado al cuadrado Gtpodemos actualizar cada parámetro 0t. La regla de actualización de Adagrad es la siguiente:
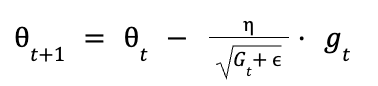
Esto es lo que ocurre:
El término:

reduce eficazmente el ritmo de aprendizaje de los parámetros que tienen un gradiente acumulado grande. Por el contrario, los parámetros con gradientes acumulados más pequeños tendrán un ritmo de aprendizaje mayor.
La fórmula de Adagrad adapta automáticamente el ritmo de aprendizaje, he aquí cómo:
PyTorch proporciona una implementación integrada de Adagrad, a la que se puede acceder a través del módulotorch.optim. Primero, instala PyTorch con pip:
pip install torch torchvisionAprende a construir tu primera red neuronal con nuestro curso gratuito, Introducción al Aprendizaje Profundo con PyTorch.
Aquí tienes una guía paso a paso para implementar el optimizador Adagrad en PyTorch:
Paso 1: Importar bibliotecas necesarias
import torchimport torch.nn as nnimport torch.optim as optimPaso 2: Definir una red neuronal simple
class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(10, 5) self.fc2 = nn.Linear(5, 2) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) return xPaso 3: Inicializar el modelo y el optimizador
model = SimpleNN()criterion = nn.CrossEntropyLoss()optimizer = optim.Adagrad(model.parameters(), lr=0.01)Paso 4: Bucle de entrenamiento
for epoch in range(10): # loop over the dataset multiple times inputs = torch.randn(1, 10) # random input tensor labels = torch.tensor([1]) # target labels # Zero the parameter gradients optimizer.zero_grad() # Forward pass outputs = model(inputs) loss = criterion(outputs, labels) # Backward pass and optimize loss.backward() optimizer.step() print(f'Epoch {epoch+1}, Loss: {loss.item()}')En este código, se entrena un modelo lineal simple utilizando el optimizador AdaGrad. La tasa de aprendizaje se establece en 0,01, pero AdaGrad la ajustará para cada parámetro en función de los gradientes cuadrados acumulados.
Ejecuta el código y verás una salida similar a ésta:
La salida muestra la pérdida después de cada época, lo que indica lo bien que está aprendiendo el modelo. Al principio, la pérdida es mayor, pero a medida que avanza el entrenamiento, la pérdida suele disminuir, lo que significa que el modelo está mejorando. Algunas fluctuaciones son normales, sobre todo con entradas aleatorias, pero en general, el modelo está aprendiendo gradualmente a hacer mejores predicciones.
Si quieres descubrir el aprendizaje profundo y explorar cómo esta rama del aprendizaje automático está cambiando el mundo. Consulta nuestro curso sobre Aprendizaje profundo en Python.
Comparemos el Adagrad con otros optimizadores como Adán, SGDy RMSProp.
Tanto Adagrad como Adán adaptan la tasa de aprendizaje para cada parámetro, pero lo hacen de formas distintas. Adagrad escala la tasa de aprendizaje basándose en la suma de gradientes al cuadrado, lo que puede llevar a tasas de aprendizaje decrecientes con el tiempo. En cambio, Adam utiliza tanto el primer como el segundo momento de los gradientes, lo que le permite mantener un ritmo de aprendizaje más estable a lo largo del entrenamiento.
Adagrad es especialmente adecuado para manejar datos dispersos debido a su capacidad para asignar mayores tasas de aprendizaje a las características poco frecuentes. Esto lo convierte en una buena opción para aplicaciones como procesamiento del lenguaje naturaldonde los gradientes dispersos son frecuentes. Adam, aunque también es capaz de manejar datos dispersos, suele preferirse por su solidez y eficacia generales en una gama más amplia de aplicaciones.
Adam es a menudo favorecido por su convergencia más rápida y su rendimiento superior en la práctica, especialmente en aprendizaje profundo con grandes conjuntos de datos. Su uso del impulso y la corrección del sesgo ayuda a evitar que se atasque en mínimos locales y puntos de silla, que pueden ser una limitación para Adagrad.
Conoce las arquitecturas fundamentales del aprendizaje profundo, como las CNN, las RNN, las LSTM y las GRU, para modelar imágenes y datos secuenciales. Consulta nuestro curso Aprendizaje profundo intermedio con PyTorch.
Comparemos el Adagrad con el SGD y el RMSProp
Descenso Gradiente Estocástico es un algoritmo básico de optimización que actualiza los parámetros del modelo utilizando el gradiente de la función de pérdida con respecto a los parámetros. Es conocido por su sencillez y facilidad de aplicación. Sin embargo, el SGD tiene una tasa de aprendizaje constante, lo que puede ser una limitación cuando se trata de datos dispersos o escalas de rasgos variables.
RMSProp es una ampliación de AdaGrad que aborda el problema de la disminución de la velocidad de aprendizaje introduciendo un factor de decaimiento. Este factor de decaimiento permite a RMSProp mantener un ritmo de aprendizaje más estable a lo largo del proceso de entrenamiento.
Resumamos los pros y los contras de Adagrad, SGD y RMSProp:
Optimizador | Pros | Contras |
Adagrad | 1. Adapta automáticamente los ritmos de aprendizaje para cada parámetro. 2. Eficaz para datos dispersos. 3. Elimina la necesidad de ajustar manualmente la velocidad de aprendizaje. | 1. La tasa de aprendizaje decae con el tiempo, lo que puede provocar una convergencia prematura. 2. Puede volverse demasiado lento en etapas posteriores del entrenamiento. |
SGD | 1. Sencillo y fácil de poner en práctica. 2. Eficaz para escapar de los mínimos locales debido a su naturaleza estocástica. | 1. Una gran variación en las actualizaciones puede provocar inestabilidad. 2. Requiere un ajuste cuidadoso de la velocidad de aprendizaje y del impulso. |
RMSProp | 1. Adapta los ritmos de aprendizaje basándote en la media móvil de los gradientes al cuadrado. 2. Adecuado para entornos no estacionarios. | 1. Requiere un ajuste cuidadoso de los hiperparámetros. 2. No incorpora inherentemente el impulso. |
Exploremos los casos de uso y las limitaciones de AdaGrad en diversos contextos.
La capacidad única de Adagrad de adaptar los ritmos de aprendizaje para cada parámetro lo hace ideal para varios escenarios:
Aunque Adagrad es poderoso en determinadas situaciones, tiene una serie de limitaciones:
Hay varias estrategias que puedes utilizar para abordar las limitaciones de Adagrad:
Construyamos una red neuronal sencilla, entrenémosla con el optimizador Adagrad y comparemos su rendimiento con otros optimizadores populares.
Si quieres aprender más sobre PyTorch, consulta nuestra guía en Tutorial de PyTorch: Construir una red neuronal sencilla desde cero.
Empecemos creando un modelo básico de red neuronal en PyTorch. Diseñaremos una red adecuada para la clasificación binaria en datos dispersos, donde Adagrad brilla con luz propia.
import torchimport torch.nn as nnclass SparseNN(nn.Module): def __init__(self, input_size): super(SparseNN, self).__init__() self.fc1 = nn.Linear(input_size, 50) self.fc2 = nn.Linear(50, 1) self.activation = nn.ReLU() self.output_activation = nn.Sigmoid() def forward(self, x): x = self.activation(self.fc1(x)) x = self.output_activation(self.fc2(x)) return xEsta red neuronal tiene una capa de entrada, una capa oculta con 50 neuronas y una capa de salida con una sola neurona. Utilizamos la activación ReLU para la capa oculta y la activación Sigmoide para la capa de salida, lo que la hace adecuada para la clasificación binaria.
Ahora, vamos a configurar nuestro proceso de entrenamiento utilizando el optimizador Adagrad. Crearemos una función para gestionar el entrenamiento:
import torch.optim as optimfrom torch.utils.data import DataLoader, TensorDataset# Function to train the modeldef train_model(model, optimizer, criterion, train_loader, num_epochs=100): losses = [] for epoch in range(num_epochs): # loop for each training epoch for inputs, targets in train_loader: # Clear gradients before each batch to avoid accumulation optimizer.zero_grad() # Reset gradients to zero # Forward pass - get model predictions outputs = model(inputs) # Calculate loss based on predictions and targets loss = criterion(outputs, targets) # Backward pass - calculate gradients for parameter updates based on the loss loss.backward() # Update model parameters based on calculated gradients optimizer.step() # Track loss for monitoring training progress losses.append(loss.item()) return losses# Setup for trainingX, y = generate_sparse_data() # This function generates our sparse datasetinput_size = X.shape[1]train_size = int(0.8 * len(X))X_train, X_test = X[:train_size], X[train_size:]y_train, y_test = y[:train_size], y[train_size:]train_dataset = TensorDataset(X_train, y_train)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)model = SparseNN(input_size)criterion = nn.BCELoss() # Assuming binary classification with BCE lossoptimizer = optim.Adagrad(model.parameters(), lr=0.01)# Train the modellosses = train_model(model, optimizer, criterion, train_loader)En esta configuración, nosotros:
Ahora, para evaluar el rendimiento de nuestro modelo, crearemos una función de evaluación:
def evaluate_model(model, test_loader): model.eval() correct = 0 total = 0 with torch.no_grad(): for inputs, targets in test_loader: outputs = model(inputs) predicted = (outputs > 0.5).float() total += targets.size(0) correct += (predicted == targets).sum().item() accuracy = correct / total return accuracy# Evaluate the modeltest_dataset = TensorDataset(X_test, y_test)test_loader = DataLoader(test_dataset, batch_size=32)accuracy = evaluate_model(model, test_loader)print(f"Adagrad Accuracy: {accuracy:.4f}")Esta función calcula la precisión de nuestro modelo en el conjunto de pruebas.
A continuación, comparémoslo con otros optimizadores populares: SGD, Adam y RMSprop. Crearemos una función para ejecutar el experimento para cada optimizador:
def run_experiment(optimizer_class, lr=0.01): model = SparseNN(input_size) criterion = nn.BCELoss() if optimizer_class == optim.SGD: optimizer = optimizer_class(model.parameters(), lr=lr, momentum=0.9) elif optimizer_class == optim.RMSprop: optimizer = optimizer_class(model.parameters(), lr=lr, alpha=0.99) else: optimizer = optimizer_class(model.parameters(), lr=lr) losses = train_model(model, optimizer, criterion, train_loader) accuracy = evaluate_model(model, test_loader) return losses, accuracy# Compare optimizersoptimizers = { 'Adagrad': optim.Adagrad, 'SGD': optim.SGD, 'Adam': optim.Adam, 'RMSprop': optim.RMSprop}results = {}for name, opt_class in optimizers.items(): losses, accuracy = run_experiment(opt_class) results[name] = {'losses': losses, 'accuracy': accuracy}print("Final accuracies:")for name, data in results.items(): print(f"{name}: {data['accuracy']:.4f}")Tras ejecutar este código, obtenemos los siguientes resultados:
Final accuracies:Adagrad: 0.9350SGD: 0.8950Adam: 0.9300RMSprop: 0.8600Estos resultados muestran que Adagrad fue el que mejor se comportó en nuestro problema de datos dispersos, alcanzando la mayor precisión del 95,00%. Esto demuestra que Adagrad se adapta bien a los escenarios de datos dispersos. Adam quedó en segundo lugar, mientras que SGD y RMSprop obtuvieron peores resultados en este caso concreto.
Para visualizar el proceso de entrenamiento, podemos trazar las curvas de pérdidas:
import matplotlib.pyplot as pltplt.figure(figsize=(12, 6))for name, data in results.items(): plt.plot(data['losses'], label=f"{name} (Accuracy: {data['accuracy']:.4f})")plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Training Loss Comparison (Sparse Data)')plt.legend()plt.show()Combinemos todos los fragmentos de código y aquí tienes el código completo.
import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoader, TensorDatasetimport matplotlib.pyplot as plt# Step 1: Generate sparse synthetic datadef generate_sparse_data(n_samples=1000, n_features=100, sparsity=0.95): X = torch.randn(n_samples, n_features) mask = torch.rand(n_samples, n_features) < sparsity X[mask] = 0 weights = torch.randn(n_features) y = (torch.matmul(X, weights) > 0).float().view(-1, 1) return X, y# Step 2: Define the neural networkclass SparseNN(nn.Module): def __init__(self, input_size): super(SparseNN, self).__init__() self.fc1 = nn.Linear(input_size, 50) self.fc2 = nn.Linear(50, 1) self.activation = nn.ReLU() self.output_activation = nn.Sigmoid() def forward(self, x): x = self.activation(self.fc1(x)) x = self.output_activation(self.fc2(x)) return x# Step 3: Train the modeldef train_model(model, optimizer, criterion, train_loader, num_epochs=100): losses = [] for epoch in range(num_epochs): for inputs, targets in train_loader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) loss.backward() optimizer.step() losses.append(loss.item()) return losses# Step 4: Evaluate the modeldef evaluate_model(model, test_loader): model.eval() correct = 0 total = 0 with torch.no_grad(): for inputs, targets in test_loader: outputs = model(inputs) predicted = (outputs > 0.5).float() total += targets.size(0) correct += (predicted == targets).sum().item() accuracy = correct / total return accuracy# Step 5: Main function to run the experimentdef run_experiment(optimizer_class, lr=0.01): # Generate sparse data X, y = generate_sparse_data() input_size = X.shape[1] train_size = int(0.8 * len(X)) X_train, X_test = X[:train_size], X[train_size:] y_train, y_test = y[:train_size], y[train_size:] # Create data loaders train_dataset = TensorDataset(X_train, y_train) test_dataset = TensorDataset(X_test, y_test) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=32) # Initialize model and training components model = SparseNN(input_size) criterion = nn.BCELoss() # Use default hyperparameters for each optimizer if optimizer_class == optim.SGD: optimizer = optimizer_class(model.parameters(), lr=lr, momentum=0.9) elif optimizer_class == optim.RMSprop: optimizer = optimizer_class(model.parameters(), lr=lr, alpha=0.99) else: optimizer = optimizer_class(model.parameters(), lr=lr) # Train the model losses = train_model(model, optimizer, criterion, train_loader) # Evaluate the model accuracy = evaluate_model(model, test_loader) return losses, accuracy# Step 6: Compare Adagrad with other optimizersoptimizers = { 'Adagrad': optim.Adagrad, 'SGD': optim.SGD, 'Adam': optim.Adam, 'RMSprop': optim.RMSprop}results = {}for name, opt_class in optimizers.items(): losses, accuracy = run_experiment(opt_class) results[name] = {'losses': losses, 'accuracy': accuracy}# Step 7: Plot resultsplt.figure(figsize=(12, 6))for name, data in results.items(): plt.plot(data['losses'], label=f"{name} (Accuracy: {data['accuracy']:.4f})")plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Training Loss Comparison (Sparse Data)')plt.legend()plt.show()print("Final accuracies:")for name, data in results.items(): print(f"{name}: {data['accuracy']:.4f}")He aquí el resultado:
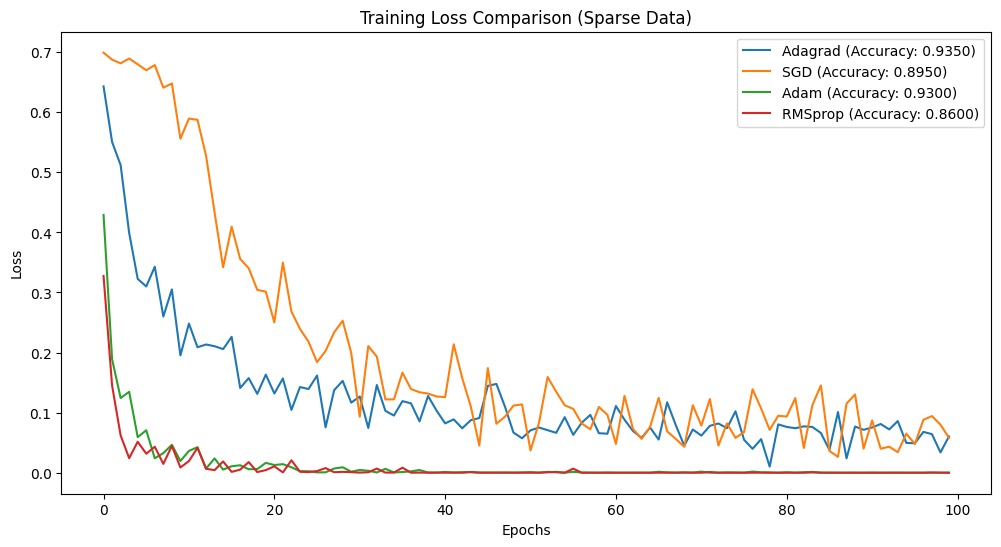
Adagrad es útil cuando se trabaja con datos dispersos gracias a su tasa de aprendizaje adaptativa. Construimos una red neuronal básica y la entrenamos utilizando Adagrad, y luego comparamos su rendimiento con el de otros algoritmos de optimización bien conocidos. Los resultados favorecieron fuertemente a Adagrad, demostrando que maneja mejor los datos dispersos.
También he seleccionado algunos de los mejores recursos sobre PyTorch, aprendizaje profundo y otros algoritmos de optimización. No dejes de consultarlas para conocerlas más a fondo:
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Zoumana Keita
15 min
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes
Tutorial
Kurtis Pykes
Tutorial
Richmond Alake
Tutorial
Abid Ali Awan

