

Track
Deep Learning in Python
18 hr
Imagine you're walking down a hill, but the ground changes as you go—some parts are steep, and others are flat. If you take the same-sized step every time, you might struggle or take too long to reach the bottom. In machine learning, a similar challenge happens with gradient descent, where using the same learning rate for all parameters can slow down learning.
This is where Adagrad comes in. It adjusts the step size for each parameter based on how much it's changed during training, helping the model learn faster and more effectively, especially when different features have different scales. In this article, we'll explore how Adagrad works and break down the math behind it. Also, we’ll show you how to implement it using PyTorch and compare it with other optimizers so you can choose the best for your projects.
Adagrad (Adaptive Gradient) is an optimization algorithm used in machine learning, specifically for training deep neural networks. It is designed to adapt the learning rate for each parameter based on its historical gradients. This approach allows Adagrad to improve the efficiency of machine learning models, especially in scenarios where sparse data is involved or when different parameters have varying rates of convergence.
Adagrad provides higher learning rates for less frequent features and lower rates for more frequent ones, which makes it well-suited for working with sparse data. Additionally, it reduces the need to manually adjust the learning rate!
Let’s break down the Adagrad algorithm:
First, start with:
For each parameter 0t at the time step t, you compute the gradient of the loss function with respect to that parameter. This gradient tells us how much and in what direction we should update the parameter to reduce the loss. Let’s call this gradient gt, where t is the current time step.
Instead of updating the parameters directly, Adagrad keeps track of the squared sum of gradients for each parameter. For each parameter i, you compute and accumulate the squared gradient at every time step. This accumulated gradient is denoted as Gt.
Gt =Gt-1 + gt2
Here:
This accumulated gradient helps Adagrad adjust the learning rate differently for each parameter based on how much it has been updated.
Now that you have the accumulated squared gradient Gt, we can update each parameter 0t. The update rule for Adagrad is as follows:
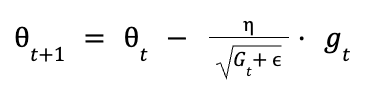
Here’s what’s happening:
The term:
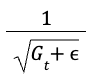
effectively reduces the learning rate for parameters that have a large accumulated gradient. In contrast, parameters with smaller accumulated gradients will have a larger learning rate.
Adagrad’s formula automatically adapts the learning rate, here’s how:
PyTorch provides a built-in implementation of Adagrad, which can be accessed through the torch.optim module. First, install PyTorch using pip:
pip install torch torchvisionLearn how to build your first neural network with our free course, Introduction to Deep Learning with PyTorch.
Here’s a step-by-step guide to implementing the Adagrad optimizer in PyTorch:
Step 1: Import Necessary Libraries
import torchimport torch.nn as nnimport torch.optim as optimStep 2: Define a Simple Neural Network
class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(10, 5) self.fc2 = nn.Linear(5, 2) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) return xStep 3: Initialize the Model and Optimizer
model = SimpleNN()criterion = nn.CrossEntropyLoss()optimizer = optim.Adagrad(model.parameters(), lr=0.01)Step 4: Training Loop
for epoch in range(10): # loop over the dataset multiple times inputs = torch.randn(1, 10) # random input tensor labels = torch.tensor([1]) # target labels # Zero the parameter gradients optimizer.zero_grad() # Forward pass outputs = model(inputs) loss = criterion(outputs, labels) # Backward pass and optimize loss.backward() optimizer.step() print(f'Epoch {epoch+1}, Loss: {loss.item()}')In this code, a simple linear model is trained using the AdaGrad optimizer. The learning rate is set to 0.01, but AdaGrad will adjust it for each parameter based on the accumulated squared gradients.
Run the code and you’ll see output similar to this:
The output shows the loss after each epoch, which indicates how well the model is learning. Initially, the loss is higher, but as the training progresses, the loss generally decreases, meaning the model is improving. Some fluctuations are normal, especially with random inputs, but overall, the model is gradually learning to make better predictions.
If you want to discover deep learning and explore how this branch of machine learning is changing the world. Check out our course on Deep Learning in Python.
Let’s compare the Adagrad with other optimizers such as Adam, SGD, and RMSProp.
Both Adagrad and Adam adapt the learning rate for each parameter, but they do so in different ways. Adagrad scales the learning rate based on the sum of squared gradients, which can lead to diminishing learning rates over time. On the other hand, Adam uses both the first and second moments of the gradients, allowing it to maintain a more stable learning rate throughout training.
Adagrad is particularly well-suited for handling sparse data due to its ability to assign larger learning rates to infrequent features. This makes it a good choice for applications like natural language processing, where sparse gradients are common. Adam, while also capable of handling sparse data, is generally preferred for its overall robustness and efficiency across a wider range of applications.
Adam is often favored for its faster convergence and superior performance in practice, especially in deep learning models with large datasets. Its use of momentum and bias correction helps it avoid getting stuck in local minima and saddle points, which can be a limitation for Adagrad.
Learn about fundamental deep learning architectures such as CNNs, RNNs, LSTMs, and GRUs for modeling image and sequential data. Check out our course Intermediate Deep Learning with PyTorch.
Let’s compare the Adagrad with SGD and RMSProp
Stochastic Gradient Descent is a basic optimization algorithm that updates the model parameters using the gradient of the loss function with respect to the parameters. It is known for its simplicity and ease of implementation. However, SGD has a constant learning rate, which can be a limitation when dealing with sparse data or varying feature scales.
RMSProp is an extension of AdaGrad that addresses its diminishing learning rate issue by introducing a decay factor. This decay factor allows RMSProp to maintain a more stable learning rate throughout the training process.
Let’s summarise the pros and cons of Adagrad, SGD, and RMSProp:
Optimizer | Pros | Cons |
Adagrad | 1. Automatically adapts learning rates for each parameter. 2. Effective for sparse data. 3. Eliminates the need for manual learning rate tuning. | 1. Learning rate decays over time, potentially leading to premature convergence. 2. May become too slow in later stages of training. |
SGD | 1. Simple and easy to implement. 2. Effective in escaping local minima due to stochastic nature. | 1. High variance in updates can lead to instability. 2. Requires careful tuning of learning rate and momentum. |
RMSProp | 1. Adapts learning rates based on the moving average of squared gradients. 2. Suitable for non-stationary environments. | 1. Requires careful tuning of hyperparameters. 2. Does not inherently incorporate momentum. |
Let’s explore the use cases and limitations of AdaGrad in various contexts.
Adagrad's unique ability to adapt learning rates for each parameter makes it ideal for several scenarios:
While Adagrad is powerful in certain situations, it does come with some set of limitations:
There are several strategies you can use to address Adagrad’s limitations:
Let’s build a simple neural network, train it using the Adagrad optimizer, and compare its performance with other popular optimizers.
If you want to learn more about PyTorch, then check out our guide on PyTorch Tutorial: Building a Simple Neural Network From Scratch.
Let's start by creating a basic neural network model in PyTorch. We'll design a network suitable for binary classification on sparse data where Adagrad shines well.
import torchimport torch.nn as nnclass SparseNN(nn.Module): def __init__(self, input_size): super(SparseNN, self).__init__() self.fc1 = nn.Linear(input_size, 50) self.fc2 = nn.Linear(50, 1) self.activation = nn.ReLU() self.output_activation = nn.Sigmoid() def forward(self, x): x = self.activation(self.fc1(x)) x = self.output_activation(self.fc2(x)) return xThis neural network has an input layer, one hidden layer with 50 neurons, and an output layer with a single neuron. We use ReLU activation for the hidden layer and Sigmoid activation for the output layer, making it suitable for binary classification.
Now, let's set up our training process using the Adagrad optimizer. We'll create a function to handle the training:
import torch.optim as optimfrom torch.utils.data import DataLoader, TensorDataset# Function to train the modeldef train_model(model, optimizer, criterion, train_loader, num_epochs=100): losses = [] for epoch in range(num_epochs): # loop for each training epoch for inputs, targets in train_loader: # Clear gradients before each batch to avoid accumulation optimizer.zero_grad() # Reset gradients to zero # Forward pass - get model predictions outputs = model(inputs) # Calculate loss based on predictions and targets loss = criterion(outputs, targets) # Backward pass - calculate gradients for parameter updates based on the loss loss.backward() # Update model parameters based on calculated gradients optimizer.step() # Track loss for monitoring training progress losses.append(loss.item()) return losses# Setup for trainingX, y = generate_sparse_data() # This function generates our sparse datasetinput_size = X.shape[1]train_size = int(0.8 * len(X))X_train, X_test = X[:train_size], X[train_size:]y_train, y_test = y[:train_size], y[train_size:]train_dataset = TensorDataset(X_train, y_train)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)model = SparseNN(input_size)criterion = nn.BCELoss() # Assuming binary classification with BCE lossoptimizer = optim.Adagrad(model.parameters(), lr=0.01)# Train the modellosses = train_model(model, optimizer, criterion, train_loader)In this setup, we:
Now, to assess our model's performance, we'll create an evaluation function:
def evaluate_model(model, test_loader): model.eval() correct = 0 total = 0 with torch.no_grad(): for inputs, targets in test_loader: outputs = model(inputs) predicted = (outputs > 0.5).float() total += targets.size(0) correct += (predicted == targets).sum().item() accuracy = correct / total return accuracy# Evaluate the modeltest_dataset = TensorDataset(X_test, y_test)test_loader = DataLoader(test_dataset, batch_size=32)accuracy = evaluate_model(model, test_loader)print(f"Adagrad Accuracy: {accuracy:.4f}")This function calculates the accuracy of our model on the test set.
Next, let's compare it with other popular optimizers: SGD, Adam, and RMSprop. We'll create a function to run the experiment for each optimizer:
def run_experiment(optimizer_class, lr=0.01): model = SparseNN(input_size) criterion = nn.BCELoss() if optimizer_class == optim.SGD: optimizer = optimizer_class(model.parameters(), lr=lr, momentum=0.9) elif optimizer_class == optim.RMSprop: optimizer = optimizer_class(model.parameters(), lr=lr, alpha=0.99) else: optimizer = optimizer_class(model.parameters(), lr=lr) losses = train_model(model, optimizer, criterion, train_loader) accuracy = evaluate_model(model, test_loader) return losses, accuracy# Compare optimizersoptimizers = { 'Adagrad': optim.Adagrad, 'SGD': optim.SGD, 'Adam': optim.Adam, 'RMSprop': optim.RMSprop}results = {}for name, opt_class in optimizers.items(): losses, accuracy = run_experiment(opt_class) results[name] = {'losses': losses, 'accuracy': accuracy}print("Final accuracies:")for name, data in results.items(): print(f"{name}: {data['accuracy']:.4f}")After running this code, we get the following results:
Final accuracies:Adagrad: 0.9350SGD: 0.8950Adam: 0.9300RMSprop: 0.8600These results show that Adagrad performed the best on our sparse data problem, achieving the highest accuracy of 95.00%. This shows that Adagrad is well-suited for sparse data scenarios. Adam came in a close second, while SGD and RMSprop performed less well in this particular case.
To visualize the training process, we can plot the loss curves:
import matplotlib.pyplot as pltplt.figure(figsize=(12, 6))for name, data in results.items(): plt.plot(data['losses'], label=f"{name} (Accuracy: {data['accuracy']:.4f})")plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Training Loss Comparison (Sparse Data)')plt.legend()plt.show()Let’s combine all the code snippets and here is the complete code.
import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoader, TensorDatasetimport matplotlib.pyplot as plt# Step 1: Generate sparse synthetic datadef generate_sparse_data(n_samples=1000, n_features=100, sparsity=0.95): X = torch.randn(n_samples, n_features) mask = torch.rand(n_samples, n_features) < sparsity X[mask] = 0 weights = torch.randn(n_features) y = (torch.matmul(X, weights) > 0).float().view(-1, 1) return X, y# Step 2: Define the neural networkclass SparseNN(nn.Module): def __init__(self, input_size): super(SparseNN, self).__init__() self.fc1 = nn.Linear(input_size, 50) self.fc2 = nn.Linear(50, 1) self.activation = nn.ReLU() self.output_activation = nn.Sigmoid() def forward(self, x): x = self.activation(self.fc1(x)) x = self.output_activation(self.fc2(x)) return x# Step 3: Train the modeldef train_model(model, optimizer, criterion, train_loader, num_epochs=100): losses = [] for epoch in range(num_epochs): for inputs, targets in train_loader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) loss.backward() optimizer.step() losses.append(loss.item()) return losses# Step 4: Evaluate the modeldef evaluate_model(model, test_loader): model.eval() correct = 0 total = 0 with torch.no_grad(): for inputs, targets in test_loader: outputs = model(inputs) predicted = (outputs > 0.5).float() total += targets.size(0) correct += (predicted == targets).sum().item() accuracy = correct / total return accuracy# Step 5: Main function to run the experimentdef run_experiment(optimizer_class, lr=0.01): # Generate sparse data X, y = generate_sparse_data() input_size = X.shape[1] train_size = int(0.8 * len(X)) X_train, X_test = X[:train_size], X[train_size:] y_train, y_test = y[:train_size], y[train_size:] # Create data loaders train_dataset = TensorDataset(X_train, y_train) test_dataset = TensorDataset(X_test, y_test) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=32) # Initialize model and training components model = SparseNN(input_size) criterion = nn.BCELoss() # Use default hyperparameters for each optimizer if optimizer_class == optim.SGD: optimizer = optimizer_class(model.parameters(), lr=lr, momentum=0.9) elif optimizer_class == optim.RMSprop: optimizer = optimizer_class(model.parameters(), lr=lr, alpha=0.99) else: optimizer = optimizer_class(model.parameters(), lr=lr) # Train the model losses = train_model(model, optimizer, criterion, train_loader) # Evaluate the model accuracy = evaluate_model(model, test_loader) return losses, accuracy# Step 6: Compare Adagrad with other optimizersoptimizers = { 'Adagrad': optim.Adagrad, 'SGD': optim.SGD, 'Adam': optim.Adam, 'RMSprop': optim.RMSprop}results = {}for name, opt_class in optimizers.items(): losses, accuracy = run_experiment(opt_class) results[name] = {'losses': losses, 'accuracy': accuracy}# Step 7: Plot resultsplt.figure(figsize=(12, 6))for name, data in results.items(): plt.plot(data['losses'], label=f"{name} (Accuracy: {data['accuracy']:.4f})")plt.xlabel('Epochs')plt.ylabel('Loss')plt.title('Training Loss Comparison (Sparse Data)')plt.legend()plt.show()print("Final accuracies:")for name, data in results.items(): print(f"{name}: {data['accuracy']:.4f}")Here’s the result:
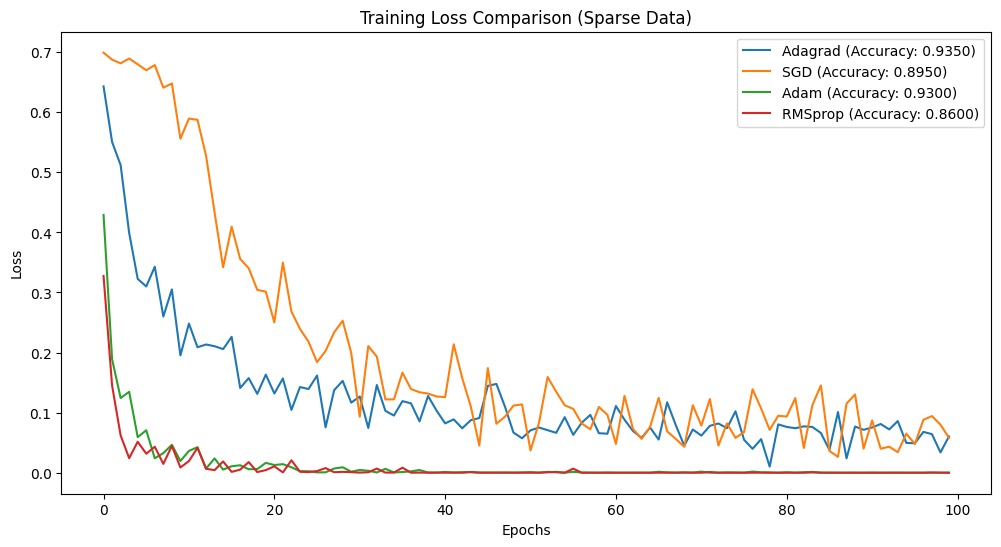
Adagrad is useful when working with sparse data due to its adaptive learning rate. We built a basic neural network and trained it using Adagrad, and then compared its performance to other well-known optimization algorithms. The results strongly favoured Adagrad showing that it handles sparse data better.
I've also handpicked some of the best resources on PyTorch, deep learning, and other optimization algorithms. Make sure to check them out to learn more in-depth:
Top DataCamp Courses
Track
Course
Course
Tutorial
Bex Tuychiev
Tutorial
DataCamp Team
Tutorial
Bex Tuychiev
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes
Tutorial
Avinash Navlani
