
Cours
Introduction à la Data Science en Python
4 h
498.4K

L'ingénieur en données développe, construit, teste et entretient des architectures telles que des bases de données et des systèmes de traitement à grande échelle. Le data scientist, quant à lui, nettoie, masse et organise les (grosses) données.
Vous trouverez peut-être le choix du verbe "masser" particulièrement exotique, mais il ne fait que refléter davantage la différence entre les ingénieurs de données et les scientifiques de données.
D'une manière générale, les efforts que les deux parties devront déployer pour obtenir les données dans un format utilisable sont considérablement différents.
Les ingénieurs des données traitent des données brutes qui contiennent des erreurs humaines, de machines ou d'instruments. Les données peuvent ne pas être validées et contenir des enregistrements suspects. Il n'est pas formaté et peut contenir des codes spécifiques au système.
Les ingénieurs des données devront recommander et parfois mettre en œuvre des moyens d'améliorer la fiabilité, l'efficacité et la qualité des données. Pour ce faire, ils devront utiliser une variété de langages et d'outils pour relier les systèmes entre eux ou rechercher des opportunités d'acquérir de nouvelles données à partir d'autres systèmes afin que les codes spécifiques au système, par exemple, puissent devenir des informations pour un traitement ultérieur par les scientifiques des données.
Dans le même ordre d'idées, les ingénieurs des données devront veiller à ce que l'architecture en place réponde aux exigences des scientifiques des données, des parties prenantes et de l'entreprise.
Enfin, l'équipe d'ingénierie des données devra développer des processus de modélisation, d'extraction et de production de données pour fournir les données à l'équipe de science des données.
Pour en savoir plus sur le travail d'un ingénieur en données, consultez notre article complet.

Les scientifiques des données obtiennent généralement déjà des données qui ont passé un premier cycle de nettoyage et de manipulation, qu'ils peuvent utiliser pour alimenter des programmes d'analyse sophistiqués et des méthodes d'apprentissage automatique et statistiques afin de préparer les données à une utilisation dans la modélisation prédictive et prescriptive. Bien entendu, pour élaborer des modèles, ils doivent effectuer des recherches sur des questions sectorielles et commerciales, et ils devront exploiter d'importants volumes de données provenant de sources internes et externes pour répondre aux besoins de l'entreprise. Cela implique aussi parfois d'explorer et d'examiner les données pour trouver des modèles cachés.
Une fois que les data scientists ont effectué les analyses, ils devront présenter un récit clair aux principales parties prenantes. Lorsque les résultats sont acceptés, ils doivent s'assurer que le travail est automatisé afin que les informations puissent être fournies aux parties prenantes de l'entreprise sur une base quotidienne, mensuelle ou annuelle.
Il est clair que les deux parties doivent travailler ensemble pour manipuler les données et fournir des informations permettant de prendre des décisions cruciales pour l'entreprise. Les compétences se chevauchent clairement, mais les deux se distinguent progressivement dans le secteur : alors que l'ingénieur des données travaillera avec des systèmes de base de données, des API de données et des outils à des fins d'ETL et sera impliqué dans la modélisation des données et la mise en place de solutions d'entrepôt de données, le data scientist doit s'y connaître en stats, en mathématiques et en apprentissage automatique pour construire des modèles prédictifs.
Le scientifique des données doit connaître l'informatique distribuée, car il devra avoir accès aux données traitées par l'équipe d'ingénierie des données. Il ou elle devra également être en mesure de rendre compte aux parties prenantes de l'entreprise, d'où la nécessité de mettre l'accent sur la narration et la visualisation.
Ce que cela signifie en termes de concentration sur les étapes du flux de travail de la science des données , vous pouvez le voir dans l'image ci-dessous :

Bien entendu, cette différence de compétences se traduit par des différences dans les langages, les outils et les logiciels utilisés par les uns et les autres. L'aperçu suivant comprend des alternatives commerciales et open-source.
Même si les outils utilisés par les deux parties dépendent fortement de la manière dont le rôle est conçu dans le contexte de l'entreprise, les ingénieurs des données travaillent souvent avec des outils tels que SAP, Oracle, Cassandra, MySQL, Redis, Riak, PostgreSQL, MongoDB, Neo4j, Hive et Sqoop.
Les data scientists utiliseront des langages tels que SPSS, R, Python, SAS, Stata et Julia pour construire des modèles. Les outils les plus populaires ici sont, sans aucun doute, Python et R. Lorsque vous travaillez avec Python et R pour la science des données, vous aurez le plus souvent recours à des packages tels que ggplot2 pour réaliser des visualisations de données étonnantes dans R ou à la bibliothèque de manipulation de données Python, Pandas. Bien entendu, de nombreux autres packages vous seront utiles lorsque vous travaillerez sur des projets de science des données, tels que scikit-learn, NumPy, Matplotlib, Statsmodels, etc.
Dans l'industrie, vous constaterez également que les outils commerciaux SAS et SPSS sont bien adaptés, mais que d'autres outils tels que Tableau, Rapidminer, Matlab, Excel et Gephi trouveront leur place dans la boîte à outils du scientifique des données.
Vous constatez à nouveau que l'une des principales distinctions entre les ingénieurs et les scientifiques des données, l'accent mis sur la visualisation des données et la narration, se reflète dans les outils mentionnés.
Comme vous l'avez peut-être déjà deviné, Scala, Java et C # sont des outils, des langages et des logiciels que les deux parties ont en commun.

Ces langages ne sont pas nécessairement populaires auprès des data scientists et des ingénieurs. On pourrait dire que Scala est plus populaire auprès des ingénieurs de données car son intégration avec Spark est particulièrement pratique pour mettre en place de grands flux ETL.
Il en va de même pour le langage Java : en ce moment, sa popularité est en hausse parmi les scientifiques des données, mais dans l'ensemble, il n'est pas largement utilisé au quotidien par les professionnels. Mais, dans l'ensemble, vous verrez ces langues apparaître dans les offres d'emploi pour les deux fonctions. On peut également en dire autant des outils que les deux parties pourraient avoir en commun, comme Hadoop, Storm et Spark.
Bien entendu, la comparaison des outils, des langages et des logiciels doit être envisagée dans le contexte spécifique dans lequel vous travaillez et dans la manière dont vous interprétez les rôles de la science des données en question ; la science des données et l'ingénierie des données peuvent être étroitement liées dans certains cas spécifiques, où la distinction entre les équipes de science des données et d'ingénierie des données est en fait si faible que les deux équipes sont parfois fusionnées.
La question de savoir s'il s'agit ou non d'une bonne idée mériterait un autre débat, qui sort du cadre du blog d'aujourd'hui.
En outre, les data scientists et les data engineers peuvent également avoir un point commun : leur formation en informatique. Cette zone d'étude est très prisée par les deux professions. Bien entendu, vous constaterez également que les data scientists ont souvent étudié l'économétrie, les mathématiques, les statistiques et la recherche opérationnelle. Ils ont souvent un peu plus de sens des affaires que les ingénieurs de données. Vous constaterez souvent que les ingénieurs en données sont également issus d'une formation d'ingénieur ; le plus souvent, ils ont suivi une formation préalable en ingénierie informatique.
Toutefois, cela ne signifie pas que vous ne trouverez pas d'ingénieurs en données qui ont acquis des connaissances en matière d'opérations et de sens des affaires au cours de leurs études antérieures.

Il faut savoir qu'en général, le secteur de la science des données est composé de professionnels venant d'horizons différents : il n'est pas rare que des physiciens, des biologistes ou des météorologues trouvent leur voie dans la science des données. D'autres ont changé de carrière pour se consacrer à la science des données et viennent du développement web, de l'administration de bases de données, etc.
Aux États-Unis, le salaire annuel moyen d'un data scientist est de 123 069 dollars, avec une fourchette de 78 000 à 194 000 dollars. Dans les différents pays, la tendance est la même : le salaire moyen d'un data scientist est supérieur d'au moins 30 % à la moyenne nationale (et en Inde, ce chiffre est nettement plus élevé !).
Le salaire annuel moyen des ingénieurs de données aux États-Unisest de 125 686 dollars; dans d 'autres pays, le salaire moyen est très similaire à celui d'un scientifique de données.
Ces deux fonctions sont très demandées. Au moment de la rédaction de cet article, Indeed recense plus de 10 000 postes de data scientist et plus de 5 000 postes d'ingénieur en données aux États-Unis. Des entreprises de premier plan telles que Spotify, Meta, Amazon, Google et Microsoft recrutent presque toujours pour ces deux types de postes.

Comme décrit précédemment, la création de rôles et de titres est nécessaire pour refléter l'évolution des besoins, mais dans d'autres cas, ils sont créés pour se différencier des autres entreprises de recrutement.
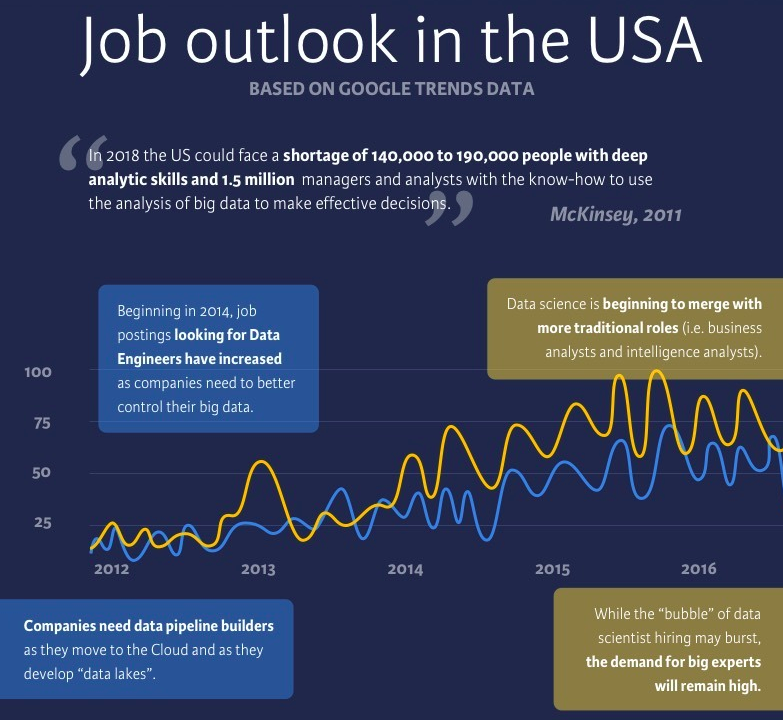
Outre l'intérêt croissant pour les questions de gestion des données, les entreprises recherchent des solutions moins coûteuses, flexibles et évolutives pour stocker et gérer leurs données. Ils veulent déplacer leurs données vers le cloud et, pour ce faire, ils doivent construire des "lacs de données" pour compléter les entrepôts de données déjà en place ou remplacer le magasin de données opérationnel (ODS).
Les flux de données devront être réorientés et remplacés dans les années à venir, ce qui explique que l'attention portée aux ingénieurs en données et le nombre d'offres d'emploi les concernant aient progressivement augmenté au fil des ans.
Le rôle de data scientist est en demande depuis le début de l'engouement, mais aujourd'hui, les entreprises cherchent à composer des équipes de data scientists plutôt que d'embaucher des data scientists licornes qui possèdent des compétences en communication, de la créativité, de l'intelligence, de la curiosité, de l'expertise technique, etc. Pour les recruteurs, il est difficile de trouver des personnes qui incarnent toutes les qualités recherchées par les entreprises, et la demande dépasse clairement l'offre.
On pourrait dire que la "bulle des scientifiques des données" a éclaté. Ou peut-être était-il sur le point d'exploser jusqu'à ce que les progrès de l'IA, tels que GPT-3 et GPT-4, prennent le monde d'assaut.
Une chose restera constante dans tout cela : la demande d'experts passionnés par les sujets liés à la science des données existera toujours. Les perspectives d'emploi pour ces experts sont très positives. Par exemple, le Bureau américain des statistiques du travail prévoit 20 800 offres d'emploi pour les data scientists chaque année au cours de la prochaine décennie, avec une croissanceprévue de 36 % entre 2023 et 2033, bien plus rapide que la moyenne de l'ensemble des professions. Les perspectives sont également haussières pour les postes d'ingénieurs en informatique.
| Aspect | Scientifique des données | Ingénieur de données | Similitudes |
|---|---|---|---|
| Objectif principal | Analyser et interpréter les données pour en tirer des enseignements | Mise en place et maintenance de l'infrastructure de données | Travailler avec des données pour faciliter la prise de décision |
| Responsabilités | Modélisation, analyse statistique et narration | Création de pipelines de données, processus ETL et entreposage de données | Collaborer pour s'assurer que les données sont propres, accessibles et utilisables |
| Compétences de base | Apprentissage automatique, statistiques, visualisation | Architecture des données, gestion des bases de données et outils cloud. | Maîtrise de la programmation et de la manipulation d'ensembles de données à grande échelle |
| Outils et logiciels | Python, R, TensorFlow, PyTorch, Tableau, Power BI | Python, Apache Spark, Kafka, Airflow, dbt, Snowflake, Databricks... | Utilisation partagée d'outils tels que Spark, Hadoop et SQL. |
| Langages de programmation | Python, R, SQL | Python, SQL, Scala, Java | La maîtrise de Python et de SQL est précieuse pour les deux. |
| Traitement des données | Se concentre sur la manipulation de données et l'apprentissage de modèles à l'aide d'outils tels que Pandas et NumPy. | Conçoit des pipelines ETL robustes avec Apache Spark, Apache Flink. | Collaborer souvent aux processus de préparation des données |
| Visualisation | Met l'accent sur le data storytelling en utilisant Tableau, Power BI, Matplotlib. | La visualisation peut intervenir lors de la validation des données, mais n'est pas un objectif prioritaire. | Possibilité d'utiliser des outils partagés tels que Looker pour l'établissement de rapports |
| Formation | Statistiques, mathématiques, informatique | Informatique, ingénierie des données, ingénierie logicielle | Formation commune dans des disciplines techniques telles que l'informatique |
| Salaire (moyenne américaine) | ~123 000 $/an | ~125 000 $/an | Des salaires compétitifs et une forte demande pour les deux fonctions |
| Perspectives d'emploi | L'accent est mis de plus en plus sur l'extraction d'informations exploitables et sur l'IA. | Besoin croissant de systèmes de gestion de données robustes et évolutifs | Forte croissance des industries basées sur les données |
Si vous souhaitez tracer votre chemin vers une carrière dans l'une ou l'autre de ces fonctions, nos guides sont un excellent point de départ :
Si vous souhaitez vous lancer directement dans votre parcours d'apprentissage, DataCamp a tout prévu. Nous proposons de nombreux cours idéaux si vous souhaitez commencer à apprendre l'ingénierie des données. Par exemple, les cours Importation de données en Python et Importation de données en R de DataCamp. Notre certification Data Engineer est une autre excellente option pour prouver aux responsables du recrutement que vous avez les compétences requises pour un poste de débutant.
Pour ceux qui veulent s'initier à la science des données, il y a les cours Analyse des données exploratoires, Introduction à R pour la science des données, Boîte à outils pour l'apprentissage automatique et Introduction à Python pour la science des données. De même, notre certification Data Scientist est très appréciée et vous aidera à franchir la porte d'entreprises de premier plan.
Apprenez-en plus sur la science des données et l'ingénierie des données avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Matt Crabtree
14 min
Tutoriel
Samuel Shaibu
Tutoriel
Matt Crabtree
