
Kurs
Einführung in Data Science mit Python
4 Std.
498.3K

Der Data Engineer entwickelt, konstruiert, testet und pflegt Architekturen wie Datenbanken und große Verarbeitungssysteme. Der Datenwissenschaftler hingegen bereinigt, massiert und organisiert (große) Daten.
Du magst die Wahl des Verbs "massieren" besonders exotisch finden, aber es spiegelt den Unterschied zwischen Data Engineers und Data Scientists nur noch mehr wider.
Im Allgemeinen sind die Anstrengungen, die beide Parteien unternehmen müssen, um die Daten in ein brauchbares Format zu bringen, sehr unterschiedlich.
Datentechniker/innen arbeiten mit Rohdaten, die menschliche, maschinelle oder instrumentelle Fehler enthalten. Die Daten könnten nicht validiert sein und verdächtige Datensätze enthalten. Sie wird unformatiert sein und kann systemspezifische Codes enthalten.
Dateningenieure müssen Wege zur Verbesserung der Zuverlässigkeit, Effizienz und Qualität der Daten empfehlen und manchmal auch umsetzen. Dazu müssen sie eine Vielzahl von Sprachen und Werkzeugen einsetzen, um Systeme miteinander zu verbinden, oder sie müssen nach Möglichkeiten suchen, neue Daten aus anderen Systemen zu gewinnen, damit die systemspezifischen Codes beispielsweise zu Informationen werden, die von Datenwissenschaftlern weiterverarbeitet werden können.
Eng damit verbunden ist die Tatsache, dass Dateningenieure sicherstellen müssen, dass die bestehende Architektur die Anforderungen der Datenwissenschaftler, der Interessengruppen und des Unternehmens unterstützt.
Schließlich muss das Data-Engineering-Team Datensatzprozesse für die Datenmodellierung, das Mining und die Produktion entwickeln, um die Daten an das Data-Science-Team zu liefern.
In unserem vollständigen Artikel erfährst du mehr über die Aufgaben eines Datentechnikers.

Data Scientists erhalten in der Regel bereits Daten, die eine erste Bereinigungs- und Manipulationsrunde durchlaufen haben. Diese Daten können sie dann in ausgefeilte Analyseprogramme, maschinelles Lernen und statistische Methoden einspeisen, um die Daten für die Verwendung in der prädiktiven und präskriptiven Modellierung vorzubereiten. Um Modelle zu erstellen, müssen sie natürlich Branchen- und Geschäftsfragen erforschen und große Datenmengen aus internen und externen Quellen nutzen, um Geschäftsanforderungen zu erfüllen. Dazu gehört manchmal auch das Erforschen und Untersuchen von Daten, um versteckte Muster zu finden.
Sobald die Datenwissenschaftler/innen die Analysen durchgeführt haben, müssen sie den wichtigsten Interessengruppen eine klare Geschichte präsentieren. Wenn die Ergebnisse akzeptiert werden, müssen sie sicherstellen, dass die Arbeit automatisiert wird, damit die Erkenntnisse täglich, monatlich oder jährlich an die Stakeholder des Unternehmens weitergegeben werden können.
Es ist klar, dass beide Parteien zusammenarbeiten müssen, um die Daten zu verarbeiten und Erkenntnisse für geschäftskritische Entscheidungen zu gewinnen. Die Kompetenzen überschneiden sich zwar, aber die beiden werden in der Branche allmählich klarer voneinander getrennt: Während der Data Engineer mit Datenbanksystemen, Daten-APIs und ETL-Tools arbeitet und an der Datenmodellierung und der Einrichtung von Data Warehouse-Lösungen beteiligt ist, muss der Data Scientist über Statistik, Mathematik und maschinelles Lernen Bescheid wissen, um Vorhersagemodelle zu erstellen.
Der Data Scientist muss sich mit verteiltem Rechnen auskennen, da er Zugang zu den Daten haben muss, die vom Data Engineering Team verarbeitet werden. Er oder sie muss auch in der Lage sein, den Stakeholdern des Unternehmens Bericht zu erstatten, daher ist ein Fokus auf Storytelling und Visualisierung unerlässlich.
Was das für den Fokus auf die Schritte des Data Science Workflows bedeutet, siehst du in der Abbildung unten:

Diese unterschiedlichen Fähigkeiten spiegeln sich natürlich auch in den verschiedenen Sprachen, Werkzeugen und der Software wider, die beide verwenden. Die folgende Übersicht enthält sowohl kommerzielle als auch Open-Source-Alternativen.
Auch wenn die von beiden Parteien verwendeten Tools stark davon abhängen, wie die Rolle im Unternehmenskontext konzipiert ist, arbeiten Data Engineers häufig mit Tools wie SAP, Oracle, Cassandra, MySQL, Redis, Riak, PostgreSQL, MongoDB, Neo4j, Hive und Sqoop.
Datenwissenschaftler/innen verwenden Sprachen wie SPSS, R, Python, SAS, Stata und Julia, um Modelle zu erstellen. Die beliebtesten Tools sind hier zweifelsohne Python und R. Wenn du mit Python und R für Data Science arbeitest, wirst du am häufigsten auf Pakete wie ggplot2 zurückgreifen, um erstaunliche Datenvisualisierungen in R zu erstellen, oder auf die Python-Bibliothek Pandas zur Datenbearbeitung. Natürlich gibt es noch viele weitere Pakete, die bei der Arbeit an Data-Science-Projekten nützlich sein können, z. B. scikit-learn, NumPy, Matplotlib, Statsmodels, etc.
In der Branche wirst du auch feststellen, dass kommerzielles SAS und SPSS gut abschneiden, aber auch andere Tools wie Tableau, Rapidminer, Matlab, Excel und Gephi finden ihren Weg in den Werkzeugkasten des Datenwissenschaftlers.
Du siehst wieder, dass sich einer der Hauptunterschiede zwischen Data Engineers und Data Scientists, nämlich die Betonung der Datenvisualisierung und des Storytellings, in den genannten Tools widerspiegelt.
Wie du vielleicht schon vermutet hast, sind Scala, Java und C # Werkzeuge, Sprachen und Software, die beide Parteien gemeinsam haben.

Diese Sprachen sind bei Datenwissenschaftlern und Ingenieuren nicht unbedingt beliebt. Man könnte argumentieren, dass Scala bei Dateningenieuren beliebter ist, weil seine Integration mit Spark besonders praktisch für die Einrichtung großer ETL-Flows ist.
Das Gleiche gilt für die Sprache Java: Sie erfreut sich derzeit bei Datenwissenschaftlern zunehmender Beliebtheit, wird aber insgesamt nicht täglich von Fachleuten verwendet. Aber alles in allem wirst du diese Sprachen in den Stellenausschreibungen für beide Rollen finden. Das Gleiche gilt auch für Tools, die beide Parteien gemeinsam haben könnten, wie Hadoop, Storm und Spark.
Natürlich muss der Vergleich von Tools, Sprachen und Software in dem spezifischen Kontext gesehen werden, in dem du arbeitest, und wie du die jeweiligen Data-Science-Rollen interpretierst; Data Science und Data Engineering können in einigen spezifischen Fällen eng beieinander liegen, wobei der Unterschied zwischen Data-Science- und Data-Engineering-Teams tatsächlich so gering ist, dass die beiden Teams manchmal zusammengelegt werden.
Ob das eine gute Idee ist oder nicht, ist Stoff genug für eine weitere Diskussion, die den Rahmen des heutigen Blogs sprengen würde.
Abgesehen von all dem haben Data Scientists und Data Engineers vielleicht noch etwas gemeinsam: ihren Informatik-Hintergrund. Dieses Studiengebiet ist bei beiden Berufen sehr beliebt. Natürlich wirst du auch sehen, dass Data Scientists oft Ökonometrie, Mathematik, Statistik und Operations Research studiert haben. Sie haben oft ein bisschen mehr Geschäftssinn als Dateningenieure. Du siehst oft, dass Dateningenieure auch aus dem Ingenieurwesen kommen; in den meisten Fällen haben sie eine Ausbildung in Computertechnik absolviert.
Das heißt aber nicht, dass du keine Dateningenieure findest, die sich in früheren Studiengängen Kenntnisse in Betriebsführung und Geschäftssinn angeeignet haben.

Du musst wissen, dass die Data-Science-Branche im Allgemeinen aus Fachleuten mit unterschiedlichen Hintergründen besteht: Es ist nicht ungewöhnlich, dass Physiker, Biologen oder Meteorologen ihren Weg in die Data Science finden. Andere haben ihren Beruf zu Data Science gewechselt und kommen aus der Webentwicklung, der Datenbankadministration, etc.
In den USA liegt das durchschnittliche Jahresgehalt von Data Scientists bei 123.069 $, mit einer Spanne von 78k bis 194k $. In den verschiedenen Ländern zeigt sich ein ähnlicher Trend: Das durchschnittliche Gehalt von Data Scientists liegt mindestens 30 % über dem nationalen Durchschnitt (und in Indien ist diese Zahl noch deutlich höher!).
Das durchschnittliche Jahresgehalt für Data Engineers in den USAliegt bei 125.686 $; in anderen Ländern ist das Durchschnittsgehalt dem eines Data Scientist sehr ähnlich.
Beide Rollen sind sehr gefragt. Zum Zeitpunkt der Erstellung dieses Artikels listet Indeed 10.000+ Stellen für Data Scientists und 5.000+ für Data Engineers in den USA auf. Führende Unternehmen wie Spotify, Meta, Amazon, Google und Microsoft stellen fast immer für beide Positionen ein.

Wie bereits beschrieben, ist die Schaffung von Rollen und Titeln notwendig, um den sich ändernden Bedürfnissen gerecht zu werden, aber manchmal werden sie auch geschaffen, um sich von anderen Personalvermittlern abzuheben.
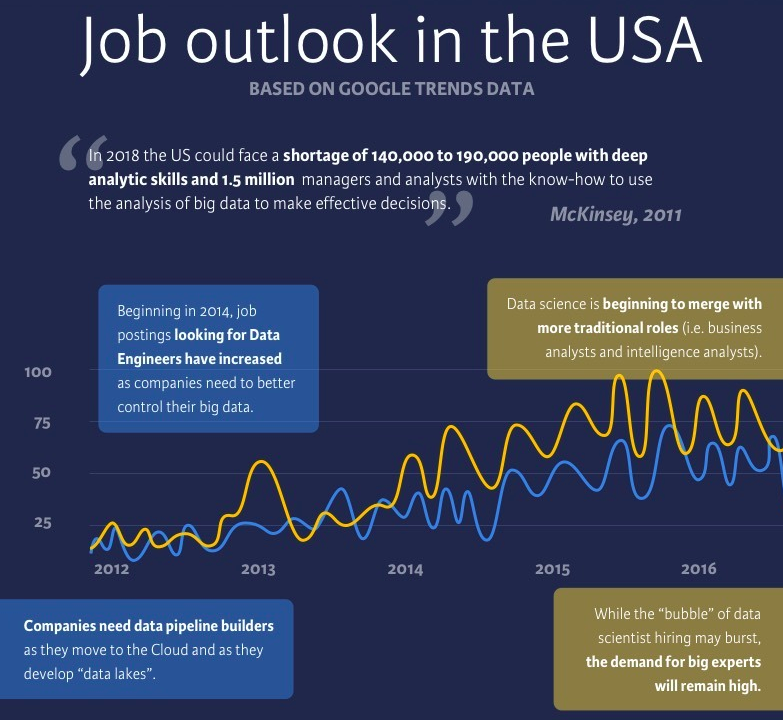
Neben dem steigenden Interesse an Fragen der Datenverwaltung suchen Unternehmen nach kostengünstigen, flexiblen und skalierbaren Lösungen für die Speicherung und Verwaltung ihrer Daten. Sie wollen ihre Daten in die Cloud verlagern und müssen dazu "Data Lakes" aufbauen, um die bereits vorhandenen Data Warehouses zu ergänzen oder den Operational Data Store (ODS) zu ersetzen.
Die Datenströme müssen in den kommenden Jahren neu ausgerichtet und ersetzt werden, weshalb der Fokus auf und die Zahl der Stellenausschreibungen für Dateningenieure im Laufe der Jahre allmählich zugenommen hat.
Die Rolle des Datenwissenschaftlers ist seit dem Beginn des Hypes gefragt, aber heutzutage suchen Unternehmen nach der Zusammenstellung von Data-Science-Teams, anstatt Einhorn-Data-Scientists einzustellen, die über Kommunikationsfähigkeiten, Kreativität, Cleverness, Neugierde, technisches Fachwissen usw. verfügen. Für Personalverantwortliche ist es schwer, Menschen zu finden, die all die Qualitäten verkörpern, die Unternehmen suchen, und die Nachfrage übersteigt eindeutig das Angebot.
Man könnte argumentieren, dass die "Datenwissenschaftler-Blase" geplatzt ist. Oder vielleicht war sie kurz davor zu platzen, bis KI-Fortschritte wie GPT-3 und GPT-4 die Welt im Sturm eroberten.
Eine Sache wird bei all dem konstant bleiben: Die Nachfrage nach Experten, die sich für Data Science-Themen begeistern, wird immer bestehen. Die Berufsaussichten für diese Fachkräfte sind sehr positiv. So rechnet das US Bureau of Labor Statistics für das nächste Jahrzehnt mit 20.800 offenen Stellen für Datenwissenschaftler/innen pro Jahr, die von 2023 bis 2033 um 36 Prozent wachsensollen, also viel schneller als der Durchschnitt aller Berufe. Ähnlich positiv sind die Aussichten für offene Stellen für Datentechniker.
| Aspekt | Datenwissenschaftler/in | Dateningenieur | Ähnlichkeiten |
|---|---|---|---|
| Primärer Fokus | Analysieren und Interpretieren von Daten, um Erkenntnisse zu gewinnen | Aufbau und Pflege der Dateninfrastruktur | Mit Daten arbeiten, um Entscheidungen zu ermöglichen |
| Zuständigkeiten | Modellierung, statistische Analyse und Storytelling | Erstellung von Datenpipelines, ETL-Prozesse und Data Warehousing | Zusammenarbeit, um sicherzustellen, dass die Daten sauber, zugänglich und nutzbar sind |
| Kernkompetenzen | Maschinelles Lernen, Statistik, Visualisierung | Datenarchitektur, Datenbankmanagement und Cloud-Tools | Kenntnisse in der Programmierung und im Umgang mit großen Datensätzen |
| Tools & Software | Python, R, TensorFlow, PyTorch, Tableau, Power BI | Python, Apache Spark, Kafka, Airflow, dbt, Snowflake, Databricks | Gemeinsame Nutzung von Tools wie Spark, Hadoop und SQL |
| Programmiersprachen | Python, R, SQL | Python, SQL, Scala, Java | Die Beherrschung von Python und SQL ist sowohl für |
| Datenverarbeitung | Konzentriert sich auf Datenbearbeitung und Modelltraining mit Tools wie Pandas, NumPy | Entwirft robuste ETL-Pipelines mit Apache Spark, Apache Flink | Häufig an Datenaufbereitungsprozessen mitarbeiten |
| Visualisierung | Schwerpunkt auf Data Storytelling mit Tableau, Power BI, Matplotlib | Die Visualisierung kann während der Datenvalidierung erfolgen, ist aber nicht der Hauptfokus | Kann gemeinsame Tools wie Looker für die Berichterstattung nutzen |
| Bildungshintergrund | Statistik, Mathematik, Informatik | Informatik, Data Engineering, Software Engineering | Gemeinsamer Hintergrund in technischen Disziplinen wie der Informatik |
| Gehalt (US-Durchschnitt) | ~123.000$/Jahr | ~125.000$/Jahr | Wettbewerbsfähige Gehälter und hohe Nachfrage für beide Funktionen |
| Berufsaussichten | Wachsender Fokus auf die Gewinnung verwertbarer Erkenntnisse und KI | Steigender Bedarf an robusten, skalierbaren Datenmanagementsystemen | Starkes Wachstum in datengesteuerten Branchen |
Wenn du deinen Weg zu einer Karriere in einem der beiden Berufe planen möchtest, sind unsere Leitfäden ein guter Startpunkt für dich:
Wenn du direkt mit dem Lernen beginnen möchtest, ist das DataCamp genau das Richtige für dich. Wir haben viele ideale Kurse für dich, wenn du mit dem Lernen von Data Engineering beginnen möchtest . Zum Beispiel die Kurse Importieren von Daten in Python und Importieren von Daten in R von DataCamp. Unsere Data Engineer-Zertifizierung ist eine weitere gute Option, um Personalchefs zu zeigen, dass du die erforderlichen Fähigkeiten für eine Einstiegsposition hast.
Für diejenigen, die in die Datenwissenschaft einsteigen wollen, gibt es die Kurse Exploratory Data Analysis, Introduction to R for Data Science, Machine Learning Toolbox und Introduction to Python for Data Science. Auch unsere Data Scientist-Zertifizierung ist hoch angesehen und wird dir helfen, bei führenden Unternehmen Fuß zu fassen.
Lerne mehr über Data Science und Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
