
Cursus
Développer des LLM
16 h
Historiquement, de nombreux modèles d'apprentissage automatique ont été conçus pour l'apprentissage de tâches spécifiques, nécessitant de grands ensembles de données pour chaque nouvelle tâche. Compte tenu des limites techniques de l'époque, l'approche la plus efficace consistait à former des modèles d'apprentissage automatique à l'aide d'un vaste ensemble de données spécifiques à une tâche. En conséquence, les modèles de pointe ont été extrêmement efficaces pour prédire l'issue du problème pour lequel ils ont été formés. Cependant, ces modèles étaient encore loin de l'homme et de son étonnante capacité à apprendre de nouvelles tâches sur la base de ses expériences antérieures.
L'ajout de stratégies d'apprentissage adaptatif aux modèles d'apprentissage automatique est la mission centrale du méta-apprentissage, un sous-domaine de l'apprentissage automatique qui se concentre sur l'amélioration de la manière dont les modèles apprennent efficacement de nouvelles tâches. Le méta-apprentissage vise à enseigner aux modèles à s'adapter rapidement avec un recyclage limité et une intervention humaine, et à améliorer les performances au fil du temps.
Dans cet article, nous vous proposons une introduction au méta-apprentissage et à la façon dont il révolutionne l'apprentissage automatique. Nous aborderons les aspects techniques des modèles de méta-apprentissage, les approches et les applications les plus courantes, ainsi que les avantages et les défis. Par la suite, je vous encourage à essayer notre cursus sur les fondements de l'IA afin d'être vraiment compétent pour parler des différents concepts liés à l'IA.
La recherche sur le méta-apprentissage remonte aux années 1980, mais le domaine a gagné en importance dans les années 2010, avec l'essor des réseaux neuronaux et, plus récemment, à la suite du développement de l'IA générative. Le méta-apprentissage, en tant que sous-domaine de l'apprentissage automatique, vise à enseigner aux modèles comment apprendre de nouvelles tâches rapidement et efficacement. Il s'inspire de la capacité des humains à "apprendre à apprendre", pour ainsi dire.
Imaginez que vous souhaitiez apprendre à résoudre rapidement des problèmes mathématiques. Une approche traditionnelle consisterait à mémoriser les solutions de nombreux problèmes différents, de sorte que lorsque vous rencontrez un problème familier, vous puissiez vous souvenir immédiatement de la réponse. Toutefois, cette approche se heurte à des difficultés lorsque vous rencontrez un tout nouveau problème.
Et si vous vous concentriez sur l'apprentissage de stratégies de résolution de problèmes en général plutôt que sur la mémorisation de solutions spécifiques ? Vous pourriez étudier des techniques de résolution de problèmes, identifier des modèles et développer une intuition pour aborder de nouveaux défis. Ainsi, lorsque vous êtes confronté à un nouveau problème, vous pouvez rapidement vous adapter et appliquer la bonne méthode, même si vous n'avez jamais rencontré ce problème précis auparavant.
C'est l'essence même du méta-apprentissage. L'apprentissage automatique traditionnel mémorise des modèles à partir de grands ensembles de données pour une tâche unique, tandis que le méta-apprentissage forme des modèles qui s'adaptent rapidement à de nouvelles tâches en apprenant à apprendre efficacement.
Vous pouvez considérer les modèles de méta-apprentissage comme un système comprenant un sous-système d'apprentissage qui s'adapte dynamiquement en exploitant l'expérience acquise lors d'épisodes d'apprentissage précédents ou de tâches différentes.
Contrairement aux modèles traditionnels d'apprentissage automatique qui ne prennent en compte qu'une seule tâche avec un ensemble de données fixe et volumineux, les méta-modèles sont exposés à une série de tâches afin d'extraire des modèles généralisables. Normalement, chaque problème est associé à un ensemble de données de formation plus petit et spécifique à la tâche.
L'objectif du processus de méta-entraînement est d'extraire des informations générales sur le processus d'apprentissage pour des tâches individuelles afin d'améliorer la capacité du modèle à traiter de nouvelles tâches avec peu de réentraînement.
Le développement de modèles de méta-apprentissage suit un processus en deux étapes qui ré-échantillonne le processus de formation de l'apprentissage automatique traditionnel :
Le processus de méta-formation et de méta-test est illustré dans l'image suivante.

Méta-apprentissage pour la classification des images. Source : Dida
Le méta-apprentissage peut être utilisé pour résoudre n'importe quel type d'apprentissage automatique, qu'il s'agisse d'apprentissage supervisé, d'apprentissage non supervisé ou d'apprentissage par renforcement.
Il existe plusieurs approches du méta-apprentissage. Vous trouverez ci-dessous les trois plus courantes :
Les modèles de méta-apprentissage basés sur des modèles sont spécifiquement conçus pour un apprentissage rapide, c'est-à-dire qu'ils peuvent rapidement mettre à jour leurs paramètres avec quelques étapes d'apprentissage. Cette mise à jour rapide peut être réalisée par son architecture interne ou contrôlée par un autre modèle de méta-apprentissage.
Voici une liste des stratégies de méta-apprentissage basées sur des modèles les plus courantes :
Le méta-apprentissage basé sur des métriques se concentre sur l'apprentissage d'une métrique de distance qui calcule la similarité ou la dissimilarité entre des paires de points de données. Un score élevé est obtenu lorsque les objets sont similaires et un score faible est obtenu lorsque les images ou les objets sont différents.
L'idée de base de cette approche est similaire à celle des algorithmes du plus proche voisin, tels que K-NN ou K-means, qui utilisent la distance entre les points de données pour effectuer une classification ou un regroupement.
Par rapport aux problèmes de classification traditionnels, qui nécessitent un grand nombre de données d'apprentissage, les modèles basés sur des métriques peuvent fonctionner avec quelques instances seulement.
Les modèles les plus courants qui exploitent les stratégies de méta-apprentissage basées sur les métriques sont les suivants :
Les réseaux neuronaux utilisent la rétropropagation des gradients pour réduire progressivement l'erreur du modèle et améliorer ses performances. La fonction d'optimisation est chargée de trouver la manière la plus efficace de recalculer les poids et les biais du réseau. Cependant, la plupart des fonctions d'optimisation courantes sont conçues pour traiter de grandes quantités de données d'apprentissage, plutôt que de petits ensembles de données.
Le méta-apprentissage basé sur l'optimisation se concentre sur la conception de fonctions d'optimisation innovantes qui peuvent mettre à jour les paramètres du modèle simplement avec un petit ensemble de données d'entraînement, de sorte qu'ils peuvent s'adapter rapidement à de nouvelles tâches.
Les modèles de méta-apprentissage basés sur l'optimisation les plus populaires sont les suivants :
Contrairement aux méthodes traditionnelles d'apprentissage supervisé qui nécessitent de grandes quantités de données, le méta-apprentissage offre un changement de paradigme, permettant aux modèles d'IA de généraliser les tâches, de s'adapter rapidement avec un minimum de données et d'améliorer les performances au fil du temps.
Analysons quelques-unes des applications les plus prometteuses :
L'apprentissage à partir d'un petit nombre d'exemples est un sous-domaine de l'apprentissage automatique dans lequel les modèles apprennent à reconnaître des modèles et à faire des prédictions sur la base d'un nombre limité d'exemples d'apprentissage. L'apprentissage en quelques coups met l'accent sur la généralisation plutôt que sur la mémorisation, ce qui remet en question la nécessité d'une mise au point approfondie. Pour les partisans de cette approche, la clé réside dans la capacité à discerner la structure et les caractéristiques sous-jacentes qui définissent une catégorie.
L'apprentissage à partir de peu d'exemples fait partie de l'apprentissage à partir de n exemples, qui englobe diverses techniques basées sur le nombre d'exemples fournis :
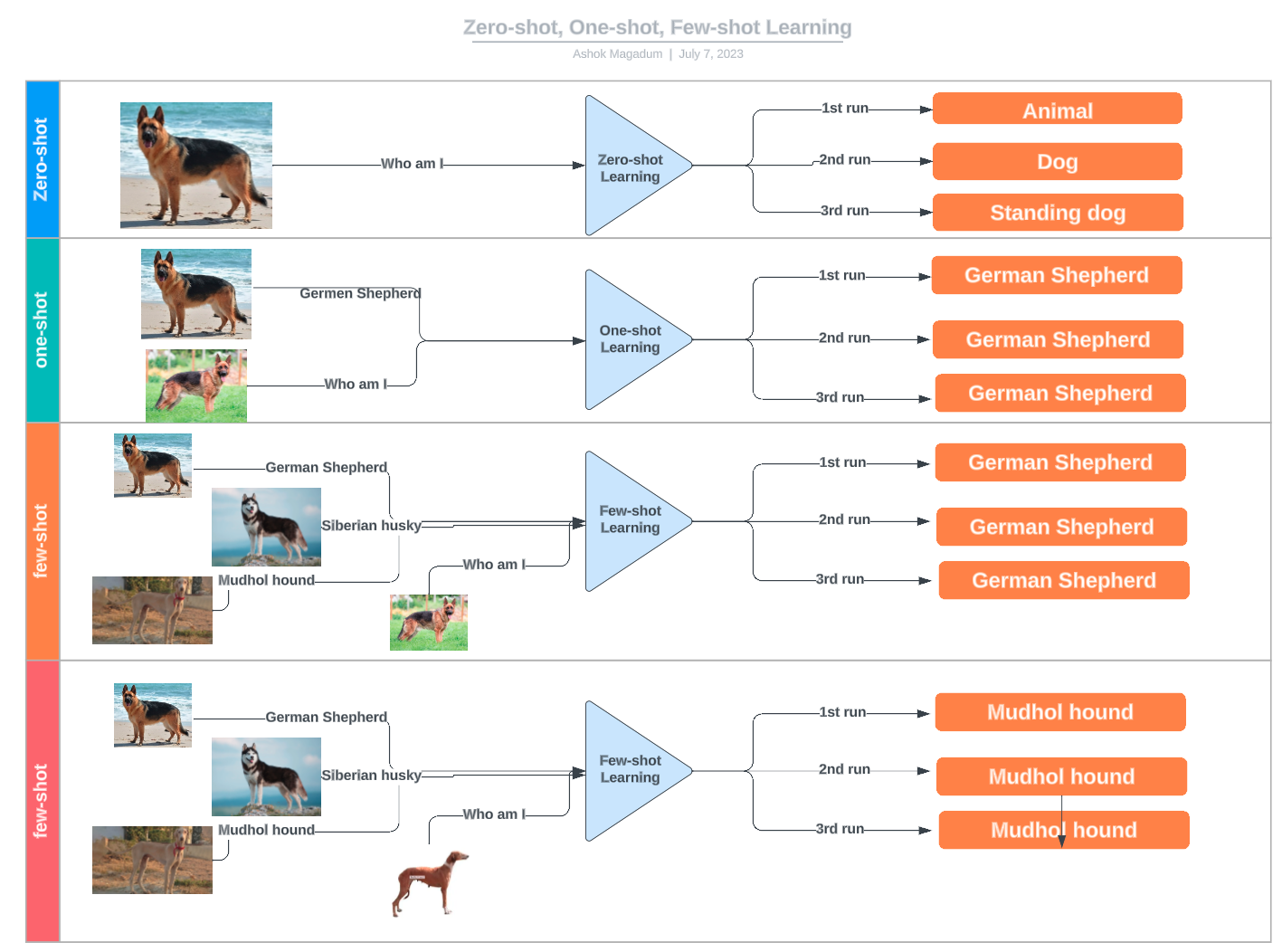
Exemples d'apprentissage à zéro coup, à un coup et à quelques coups. Source : LinkedIn
L'apprentissage par transfert permet de réutiliser un modèle formé pour une tâche donnée pour une tâche différente mais connexe, souvent en affinant un modèle préformé. Le méta-apprentissage, quant à lui, vise à enseigner aux modèles comment s'adapter rapidement à de nouvelles tâches avec un minimum de recyclage. Si le méta-apprentissage peut améliorer l'apprentissage par transfert dans certains cas, par exemple en optimisant les hyperparamètres ou en sélectionnant la meilleure stratégie de réglage fin, il n'est pas un élément indispensable de l'apprentissage par transfert. De nombreuses approches d'apprentissage par transfert s'appuient uniquement sur des techniques conventionnelles de réglage fin plutôt que sur le méta-apprentissage.
Les systèmes de recommandation utilisent le retour d'information des utilisateurs pour trouver de nouveaux éléments pertinents pour eux ou pour d'autres, en partant du principe que les utilisateurs qui ont des préférences similaires dans le passé sont susceptibles d'avoir des préférences similaires dans l'avenir.
L'objectif d'un système de recommandation est de fournir aux utilisateurs des recommandations personnalisées basées sur leurs préférences et leur comportement antérieur. Le méta-apprentissage peut contribuer à atteindre cet objectif en apprenant à optimiser l'algorithme de recommandation pour chaque utilisateur.
Les systèmes de méta-recommandation se composent de deux couches : un système de recommandation de base et un optimiseur de méta-niveau. Le système de recommandation de base génère des recommandations pour les utilisateurs sur la base de leur comportement passé, tandis que l'optimiseur de méta-niveau apprend à optimiser le système de recommandation de base pour chaque utilisateur.
L'apprentissage automatique, également connu sous le nom d'AutoML, est le processus d'automatisation de bout en bout de la construction de modèles d'apprentissage automatique. Cela comprend des tâches telles que le prétraitement des données, l'ingénierie des caractéristiques, la sélection des modèles et l'ajustement des hyperparamètres.
Les techniques de méta-apprentissage peuvent soutenir ces processus, par exemple en automatisant l'optimisation et l'adaptation des hyperparamètres, ou même en trouvant le modèle le plus approprié pour résoudre une tâche spécifique.
Plusieurs raisons convaincantes expliquent pourquoi les chercheurs en apprentissage automatique se tournent de plus en plus vers les stratégies de méta-apprentissage pour développer leurs modèles.
Efficacité de la formation: Le méta-apprentissage réduit le temps de formation en évitant d'avoir à former des modèles avec d'énormes ensembles de données et permet un réglage fin avec des données limitées.
Réduire les coûts opérationnels: Le méta-apprentissage réduit les coûts en évitant d'avoir à former des modèles à partir de zéro, où l'acquisition des données et l'utilisation des ressources informatiques pour former un modèle peuvent être coûteuses.
Amélioration de l'adaptabilité et de la réutilisation: Le méta-apprentissage est une technique clé qui permet aux modèles de s'adapter à de multiples scénarios et tâches, augmentant ainsi leur potentiel et leur utilité.
Modèle de performance: Outre l'amélioration de l'adaptabilité, le méta-apprentissage peut également améliorer la précision des modèles d'apprentissage automatique existants.
Cependant, le méta-apprentissage n'est pas une stratégie universelle. Elle présente des limites et des pièges potentiels qu'il convient d'aborder avec prudence. Les défis les plus courants en matière de méta-apprentissage sont les suivants :
Mauvaise correspondance des domaines: Le méta-apprentissage a plus de chances de fonctionner correctement lorsque les tâches source et cible sont liées dans une certaine mesure. Si la nouvelle tâche est très différente, les connaissances généralisables transférées peuvent ne pas être suffisantes pour effectuer la nouvelle tâche avec précision et peuvent même réduire les performances dans toutes les tâches.
Rareté des données: Une certaine quantité de données de formation est toujours nécessaire. Si les données d'apprentissage sont extrêmement limitées ou si la qualité des données est médiocre, le modèle risque d'être sous-adapté.
Surajustement: Le méta-apprentissage n'est pas non plus à l'abri d'un surajustement. Si le modèle est trop finement ajusté à une tâche, il peut apprendre des caractéristiques spécifiques à cette tâche qui ne se généralisent pas bien à de nouvelles données.
Complexité et coût: Parfois, la tâche cible est si complexe que le processus de réglage fin peut s'avérer difficile, coûteux en termes de calcul et chronophage.
Le méta-apprentissage est une approche de conception essentielle pour accroître l'efficacité et le potentiel des réseaux neuronaux. Il est juste de dire que la révolution actuelle de l'IA n'aurait pas été possible sans les nombreuses techniques d'apprentissage par transfert disponibles.
Le domaine évolue rapidement et certains domaines nécessitent des recherches plus approfondies :
Les modèles d'apprentissage automatique devenant plus grands et plus complexes, il est essentiel de trouver de nouvelles techniques pour les rendre plus efficaces et plus polyvalents afin que l'industrie de l'IA tienne ses promesses, que les chiffres marchent et que la durabilité du secteur progresse.
Le méta-apprentissage a beaucoup à dire à cet égard. Ce domaine de recherche évolue rapidement et propose un ensemble de techniques et de stratégies cruciales pour faire progresser les capacités de l'IA. Restez à l'écoute de DataCamp pour connaître les dernières nouveautés en matière de méta-apprentissage, d'IA, et bien plus encore :
Qu'est-ce que l'apprentissage profond ? Un tutoriel pour les débutants
Comprendre le superalignement : Aligner l'IA sur les valeurs humaines
Qu'est-ce que l'alignement de l'IA ? Faire en sorte que l'IA soit au service de l'humanité
Qu'est-ce que l'apprentissage par transfert dans l'IA ? Guide d'introduction avec exemples
Apprenez avec DataCamp
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach