
Track
Developing Large Language Models
16 hr
Historically, many machine learning models were designed for task-specific learning, requiring large datasets for each new task. Given the technical limitations of the time, the most effective approach was to train machine learning models with a huge, task-specific dataset. As a result, state-of-the-art models were extremely effective at predicting the outcome of the problem they were trained for. However, these models were still far away from humans and our astonishing capacity to learn new tasks based on our previous experience.
Adding adaptive learning strategies to machine learning models is the central mission of meta learning, a subfield of machine learning that focuses on improving how models learn new tasks efficiently. Meta learning focuses on teaching models to adapt quickly with limited retraining and human intervention, and improve performance over time.
In this article, we will provide an introduction to meta learning and how it is revolutionizing machine learning. We will cover the technicalities of meta learning models, the most common approaches and applications, as well as the benefits and challenges. Afterwards, I encourage you to take try our AI Fundamentals skill track to really be skilled in talking about the different and related concepts in AI.
Meta learning research dates back to the 1980s, but the field gained relevance in the 2010s, with the rise of neural networks, and, more recently, following the development of generative AI. Meta learning as a subfield of machine learning focuses on teaching models how to learn new tasks quickly and efficiently. It’s inspired by humans' ability to “learn to learn," so to speak.
Imagine you want to learn how to solve math problems quickly. A traditional approach would be to memorize solutions for many different problems, so that when you see a familiar one, you can recall the answer immediately. However, this approach struggles when you encounter a brand-new problem.
Instead, what if you focused on learning strategies for solving problems in general rather than memorizing specific solutions? You might study problem-solving techniques, identify patterns, and develop an intuition for approaching new challenges. This way, when faced with a new problem, you can quickly adapt and apply the right method, even if you’ve never seen that exact problem before.
This is the essence of meta learning. Traditional machine learning memorizes patterns from large datasets for a single task, while meta learning trains models to quickly adapt to new tasks by learning how to learn effectively.
You can think of meta learning models as a system that includes a learning subsystem that is dynamically adapted by exploiting experience from previous learning episodes or from different tasks.
In contrast with traditional machine learning models that only consider a single task with a fixed and large dataset, meta models are exposed to a range of tasks to extract generalizable patterns. Normally, each problem is associated with a smaller, task-specific training dataset.
The aim of the meta training process is to extract general information about the learning process on individual tasks in order to improve the model’s ability to address novel tasks with little retraining.
Developing meta-learning models follows a two-step process that resamples the training process of traditional machine learning:
The meta-training and meta-testing process is illustrated in the following image.

Meta learning for image classification. Source: Dida
Meta learning can be used to solve any type of machine learning, whether supervised learning, unsupervised learning, or reinforcement learning.
There are several approaches to meta learning. Below you can find the three most common ones:
Model-based meta-learning models are specifically designed for fast learning, that is, they can rapidly update their parameters with a few training steps. This rapid update can be achieved by its internal architecture or controlled by another meta-learner model.
Here is a list of the most common model-based meta learning strategies:
Metric-based meta learning focuses on learning a distance metric that calculates the similarity or dissimilarity between pairs of data points. A high score is returned when the objects are similar and a low score is returned when the images or objects are different.
The core idea of this approach is similar to nearest neighbor algorithms, such as K-NN or K-means, which use the distance between data points to make classification or clustering.
Compared to traditional classification problems, where a lot of training data is necessary, metric-based models can work with just a few instances.
Some of the most common models that leverage metric-based meta learning strategies are:
Neural networks use backpropagation of gradients to progressively reduce the error of the model and improve its performance. The optimization function is responsible for finding the most effective way to recalculate the weights and biases of the network. However, most popular optimization functions are designed to address vast amounts of training data, rather than small datasets.
Optimization-based meta learning focuses on designing innovative optimization functions that can update the model’s parameters just with a small training dataset, so they can adapt to new tasks quickly.
Among the most popular optimization-based meta learning models are:
In contrast to traditional supervised learning methods that demand vast amounts of data, meta learning offers a paradigm shift, empowering AI models to generalize across tasks, adapt quickly with minimal data, and improve performance over time.
Let’s analyze some of the most promising applications:
Few-shot learning is a subfield of machine learning where models learn to recognize patterns and make predictions based on a limited number of training examples. Few-shot learning emphasizes generalization over memorization, challenging the need for extensive fine-tuning. For proponents of this approach, the key lies in the ability to discern the underlying structure and features that define a category.
Few-shot learning falls under the broader umbrella of n-shot learning, encompassing various techniques based on the number of examples provided:
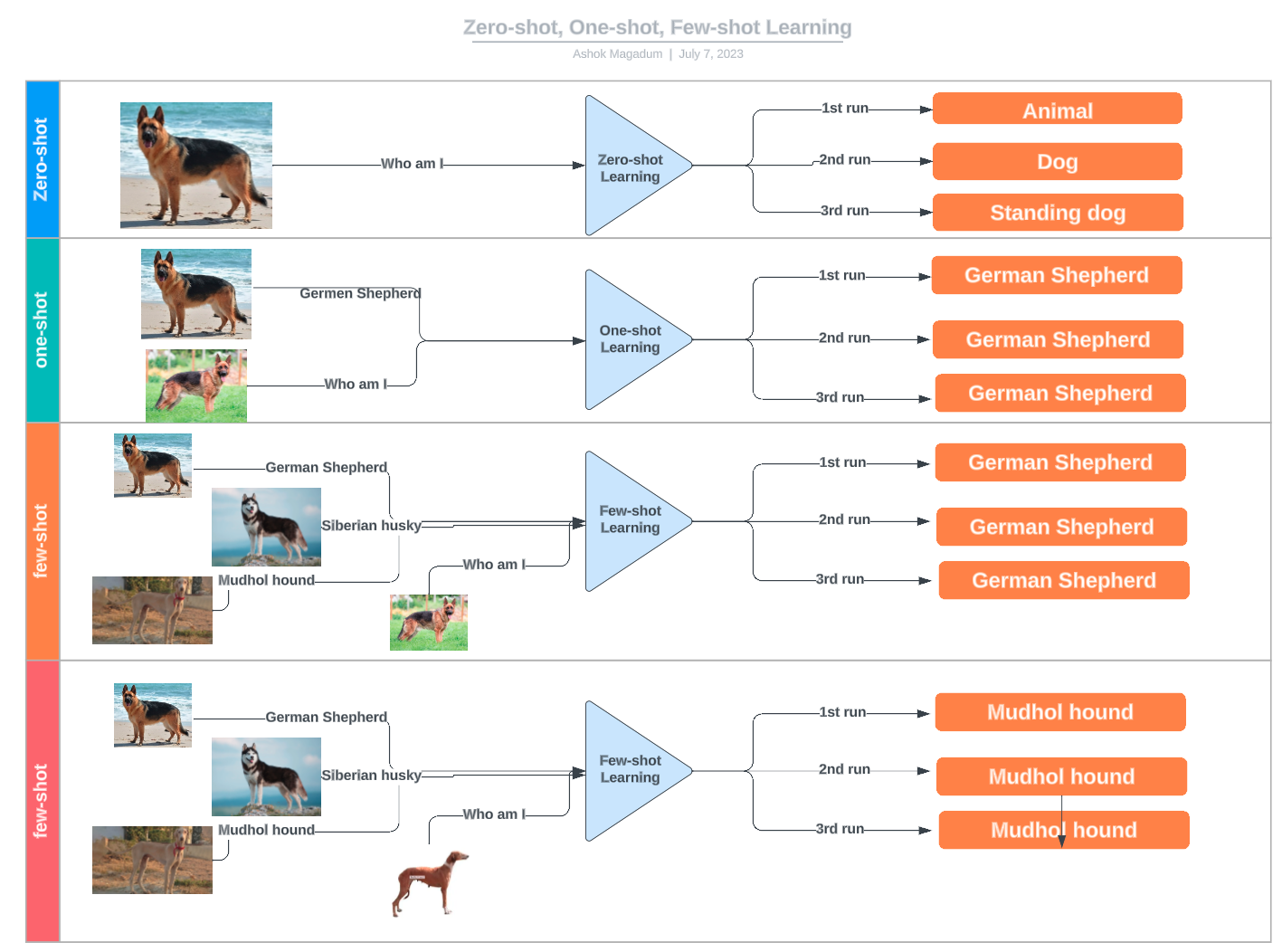
Zero-shot, one-shot, and few-shot learning examples. Source: LinkedIn
Transfer learning allows a model trained for one task to be repurposed for a different but related task, often by fine-tuning a pre-trained model. Meta learning, on the other hand, focuses on teaching models how to adapt quickly to new tasks with minimal retraining. While meta learning can enhance transfer learning in some cases, such as by optimizing hyperparameters or selecting the best fine-tuning strategy, it is not a necessary component of transfer learning. Many transfer learning approaches rely solely on conventional fine-tuning techniques rather than meta learning.
Recommendation systems use the feedback of users to find new relevant items for them or for others with the assumption that users who have similar preferences in the past are likely to have similar preferences in the future.
The goal of a recommendation system is to provide users with personalized recommendations based on their preferences and past behavior. Meta-learning can help achieve this goal by learning how to optimize the recommendation algorithm for each user.
Meta-recommendation systems consist of two layers: a base recommender system and a meta-level optimizer. The base recommender system generates recommendations for users based on their past behavior, while the meta-level optimizer learns how to optimize the basic recommender system for each user.
Automated machine learning, also known as AutoML, is the process of automating the end-to-end process of building machine learning models. This includes tasks such as data preprocessing, feature engineering, model selection, and hyperparameter tuning.
Meta learning techniques can support these processes, for example by automating hyperparameter optimization and adaption, or even by finding the most appropriate model to solve a specific task.
There are several compelling reasons why machine learning researchers are increasingly turning to meta learning strategies to develop their models.
Training efficiency: Meta learning reduces training time by avoiding the need to train models with huge datasets and allows fine-tuning with limited data.
Reducing operational costs: Meta learning reduces costs by obviating the need to train models from scratch, where both acquiring the data and using computational resources to train a model can be expensive.
Enhanced adaptability and reusability: Meta learning is a key technique that allows models to adapt to multiple scenarios and tasks, thereby increasing their potential and usability.
Model performance: In addition to enhancing adaptability, meta learning can also improve the accuracy of existing machine learning models.
However, meta learning is not a one-size-fits-all strategy. It has limitations and potential pitfalls that must be addressed carefully. Some of the most common challenges in meta learning are:
Domain mismatch: Meta learning is more likely to work well where the source and the target tasks are related to some extent. If the new task is very different, the generalizable knowledge transferred may not be enough to perform the new task accurately, and it can even reduce the performance in all the tasks.
Data scarcity: A certain amount of training data is always required. If the training data is extremely limited or the quality of the data is poor, the model is likely to suffer from underfitting.
Overfitting: Meta learning is also not immune to overfitting. If the model is fine-tuned too much on a task, it may learn task-specific features that do not generalize well to new data.
Complexity and cost: Sometimes, the target task is so complex that the fine-tuning process can be challenging, computationally costly, and time-consuming.
Meta learning is a critical design approach to increasing the efficiency and potential of neural networks. It’s fair to say that the current AI revolution wouldn’t have been possible without the many transfer learning techniques available.
The field is rapidly evolving, with some areas that require further research, including:
As machine learning models become bigger and more complex, finding novel techniques to make them more efficient and more versatile is crucial for the AI industry to deliver its promises, make the numbers work, and advance sustainability in the sector.
Meta learning has a lot to say in thai regard. This field of research is rapidly evolving, offering a set of techniques and strategies that are crucial in advancing the capabilities of AI. Stay tuned with DataCamp to know the latest news in meta learning, AI, and much more:
Learn with DataCamp
Track
Course
Course
blog
Abid Ali Awan
5 min
blog
Abid Ali Awan
9 min
blog
Stanislav Karzhev
12 min
blog
Abid Ali Awan
5 min
blog
Vinod Chugani
9 min
Tutorial
DataCamp Team
