
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
In der Vergangenheit wurden viele Modelle für maschinelles Lernen für aufgabenspezifisches Lernen entwickelt, sodass für jede neue Aufgabe große Datensätze benötigt wurden. Angesichts der damaligen technischen Beschränkungen war es am effektivsten, maschinelle Lernmodelle mit einem riesigen, aufgabenspezifischen Datensatz zu trainieren. Das Ergebnis war, dass die Modelle auf dem neuesten Stand der Technik das Ergebnis des Problems, für das sie trainiert wurden, sehr gut vorhersagen konnten. Diese Modelle waren jedoch noch weit entfernt vom Menschen und seiner erstaunlichen Fähigkeit, neue Aufgaben auf der Grundlage seiner bisherigen Erfahrungen zu lernen.
Das Hinzufügen von adaptiven Lernstrategien zu maschinellen Lernmodellen ist die zentrale Aufgabe des Meta-Lernens, einem Teilbereich des maschinellen Lernens, der sich darauf konzentriert, wie Modelle effizient neue Aufgaben lernen. Beim Meta-Lernen geht es darum, den Modellen beizubringen, sich mit begrenztem Nachschulungsaufwand und menschlichen Eingriffen schnell anzupassen und ihre Leistung im Laufe der Zeit zu verbessern.
In diesem Artikel geben wir eine Einführung in das Meta-Lernen und zeigen, wie es das maschinelle Lernen revolutioniert. Wir werden die technischen Aspekte von Meta-Lernmodellen, die gängigsten Ansätze und Anwendungen sowie die Vorteile und Herausforderungen behandeln. Danach empfehle ich dir, unseren Lernpfad KI-Grundlagen auszuprobieren, damit du wirklich über die verschiedenen und verwandten Konzepte der KI sprechen kannst.
Die Forschung im Bereich des Meta-Lernens reicht bis in die 1980er Jahre zurück, aber das Feld gewann in den 2010er Jahren mit dem Aufkommen neuronaler Netze und in jüngerer Zeit mit der Entwicklung der generativen KI an Bedeutung. Meta-Lernen als Teilgebiet des maschinellen Lernens konzentriert sich darauf, Modellen beizubringen, wie sie neue Aufgaben schnell und effizient lernen können. Es ist inspiriert von der Fähigkeit des Menschen, sozusagen "das Lernen zu lernen".
Stell dir vor, du willst lernen, wie du Matheaufgaben schnell lösen kannst. Eine traditionelle Herangehensweise wäre, sich die Lösungen für viele verschiedene Probleme einzuprägen, damit du die Antwort sofort abrufen kannst, wenn du ein bekanntes Problem siehst. Dieser Ansatz ist jedoch problematisch, wenn du auf ein brandneues Problem stößt.
Wie wäre es stattdessen, wenn du dich darauf konzentrierst, Strategien zum Lösen von Problemen im Allgemeinen zu lernen, anstatt spezielle Lösungen auswendig zu lernen? Du könntest Problemlösungstechniken studieren, Muster erkennen und ein Gespür dafür entwickeln, wie du an neue Herausforderungen herangehst. Auf diese Weise kannst du dich bei einem neuen Problem schnell anpassen und die richtige Methode anwenden, auch wenn du das Problem noch nie gesehen hast.
Das ist die Essenz des Meta-Lernens. Beim traditionellen maschinellen Lernen werden Muster aus großen Datensätzen für eine einzige Aufgabe gespeichert, während beim Meta-Lernen Modelle so trainiert werden, dass sie sich schnell an neue Aufgaben anpassen, indem sie lernen, wie man effektiv lernt.
Du kannst dir Meta-Lernmodelle als ein System vorstellen, das ein lernendes Teilsystem enthält, das sich dynamisch anpasst, indem es die Erfahrungen aus früheren Lernepisoden oder aus verschiedenen Aufgaben nutzt.
Im Gegensatz zu traditionellen maschinellen Lernmodellen, die nur eine einzige Aufgabe mit einem festen und großen Datensatz betrachten, werden Metamodelle mit einer Reihe von Aufgaben konfrontiert, um verallgemeinerbare Muster zu extrahieren. Normalerweise ist jedes Problem mit einem kleineren, aufgabenspezifischen Trainingsdatensatz verbunden.
Das Ziel des Meta-Trainings ist es, allgemeine Informationen über den Lernprozess bei einzelnen Aufgaben zu extrahieren, um die Fähigkeit des Modells zu verbessern, neue Aufgaben mit wenig Nachschulung zu bewältigen.
Die Entwicklung von Meta-Learning-Modellen erfolgt in einem zweistufigen Prozess, der den Trainingsprozess des traditionellen maschinellen Lernens nachahmt:
Der Prozess des Meta-Trainings und Meta-Tests wird in der folgenden Abbildung dargestellt.

Meta-Lernen für die Bildklassifizierung. Quelle: Dida
Meta-Lernen kann für jede Art von maschinellem Lernen eingesetzt werden, egal ob überwachtes Lernen, unüberwachtes Lernen oder Reinforcement Learning.
Es gibt verschiedene Ansätze für das Metalernen. Im Folgenden findest du die drei gängigsten davon:
Modellbasierte Meta-Learning-Modelle sind speziell für schnelles Lernen konzipiert, d.h. sie können ihre Parameter mit wenigen Trainingsschritten schnell aktualisieren. Diese schnelle Aktualisierung kann durch seine interne Architektur erreicht oder durch ein anderes Meta-Lernmodell gesteuert werden.
Hier ist eine Liste der gängigsten modellbasierten Metalernstrategien:
Metrikbasiertes Meta-Lernen konzentriert sich auf das Erlernen einer Abstandsmetrik, die die Ähnlichkeit oder Unähnlichkeit zwischen Paaren von Datenpunkten berechnet. Eine hohe Punktzahl wird vergeben, wenn die Objekte ähnlich sind, und eine niedrige, wenn die Bilder oder Objekte unterschiedlich sind.
Der Kerngedanke dieses Ansatzes ähnelt den Nearest Neighbour-Algorithmen wie K-NN oder K-Means, die den Abstand zwischen Datenpunkten zur Klassifizierung oder Clusterbildung nutzen.
Im Vergleich zu traditionellen Klassifizierungsproblemen, für die eine große Anzahl von Trainingsdaten erforderlich ist, können metrikbasierte Modelle mit nur wenigen Instanzen arbeiten.
Einige der gängigsten Modelle, die metrikbasierte Meta-Lernstrategien nutzen, sind:
Neuronale Netze verwenden Backpropagation von Gradienten, um den Fehler des Modells schrittweise zu reduzieren und seine Leistung zu verbessern. Die Optimierungsfunktion ist dafür verantwortlich, den effektivsten Weg zur Neuberechnung der Gewichte und Verzerrungen des Netzes zu finden. Die meisten gängigen Optimierungsfunktionen sind jedoch auf große Mengen von Trainingsdaten ausgelegt und nicht auf kleine Datensätze.
Optimierungsbasiertes Meta-Lernen konzentriert sich auf die Entwicklung innovativer Optimierungsfunktionen, die die Parameter des Modells nur mit einem kleinen Trainingsdatensatz aktualisieren können, sodass sie sich schnell an neue Aufgaben anpassen können.
Zu den beliebtesten optimierungsbasierten Metalernmodellen gehören:
Im Gegensatz zu den traditionellen überwachten Lernmethoden, die riesige Datenmengen benötigen, bietet das Meta-Lernen einen Paradigmenwechsel, der es KI-Modellen ermöglicht, Aufgaben zu verallgemeinern, sich mit minimalen Daten schnell anzupassen und ihre Leistung im Laufe der Zeit zu verbessern.
Analysieren wir einige der vielversprechendsten Anwendungen:
Few-Shot-Learning ist ein Teilbereich des maschinellen Lernens, bei dem Modelle lernen, Muster zu erkennen und Vorhersagen auf der Grundlage einer begrenzten Anzahl von Trainingsbeispielen zu treffen. Beim Few-Shot-Lernen wird der Schwerpunkt auf die Verallgemeinerung statt auf das Auswendiglernen gelegt, was die Notwendigkeit einer umfangreichen Feinabstimmung in Frage stellt. Für die Befürworter dieses Ansatzes liegt der Schlüssel in der Fähigkeit, die zugrunde liegende Struktur und die Merkmale zu erkennen, die eine Kategorie definieren.
Das Few-Shot-Lernen fällt unter den weiter gefassten Begriff des n-Shot-Lernens und umfasst verschiedene Techniken, die auf der Anzahl der bereitgestellten Beispiele basieren:
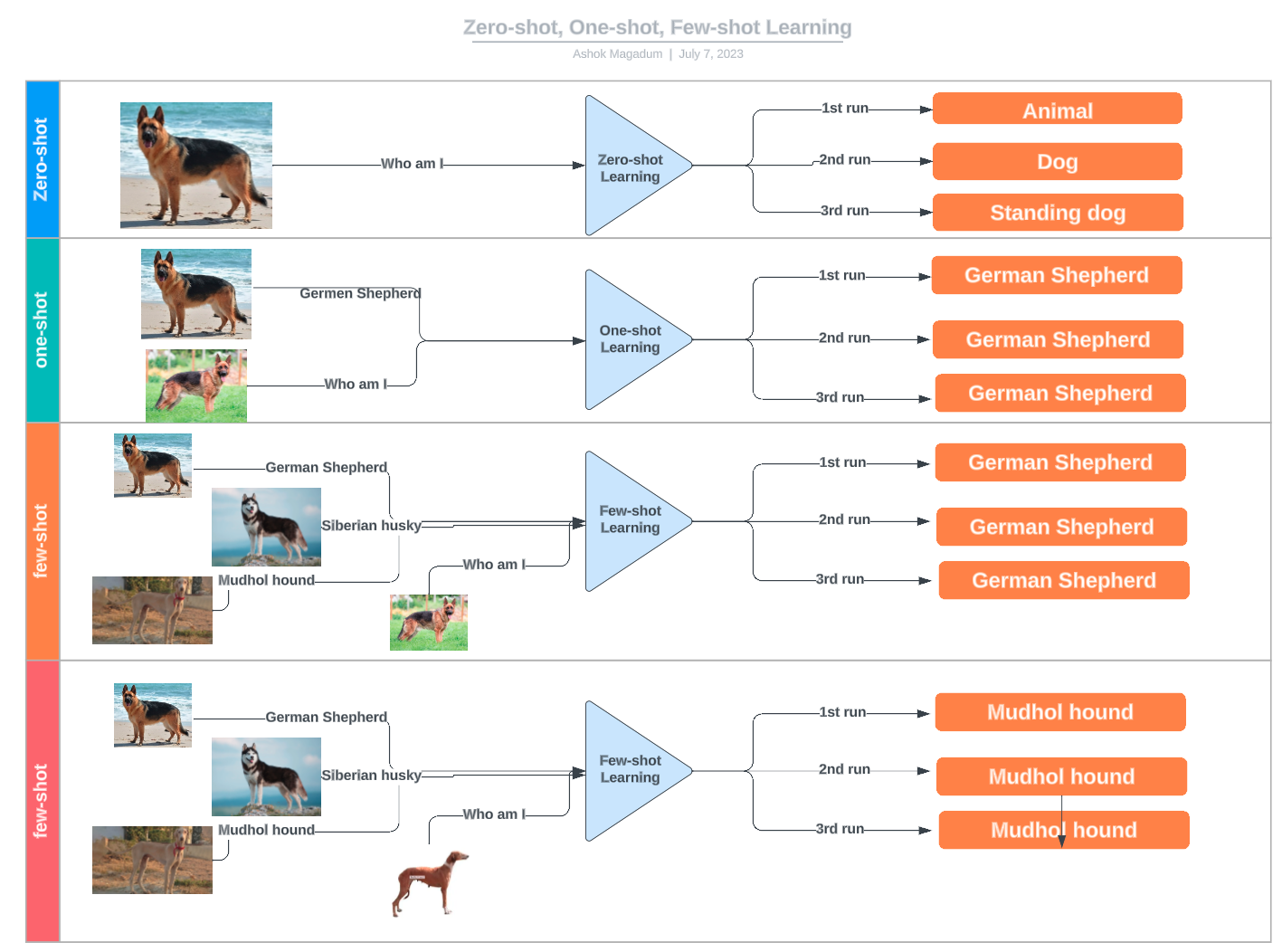
Beispiele für Null-Schuss-, Ein-Schuss- und Wenig-Schuss-Lernen. Quelle: LinkedIn
Beim Transfer-Lernen kann ein Modell, das für eine Aufgabe trainiert wurde, für eine andere, aber verwandte Aufgabe verwendet werden, oft durch Feinabstimmung eines zuvor trainierten Modells. Beim Meta-Lernen hingegen geht es darum, den Modellen beizubringen, wie sie sich schnell und mit minimaler Umschulung an neue Aufgaben anpassen können. Obwohl Meta-Lernen in einigen Fällen das Transfer-Lernen verbessern kann, z. B. durch die Optimierung von Hyperparametern oder die Auswahl der besten Feinabstimmungsstrategie, ist es kein notwendiger Bestandteil des Transfer-Lernens. Viele Transfer-Learning-Ansätze verlassen sich ausschließlich auf konventionelle Feinabstimmungstechniken und nicht auf Meta-Lernen.
Empfehlungssysteme nutzen das Feedback der Nutzer/innen, um neue relevante Artikel für sie selbst oder für andere zu finden. Dabei wird davon ausgegangen, dass Nutzer/innen, die in der Vergangenheit ähnliche Vorlieben hatten, wahrscheinlich auch in Zukunft ähnliche Vorlieben haben werden.
Das Ziel eines Empfehlungssystems ist es, den Nutzern personalisierte Empfehlungen zu geben, die auf ihren Vorlieben und ihrem bisherigen Verhalten basieren. Meta-Lernen kann helfen, dieses Ziel zu erreichen, indem es lernt, wie der Empfehlungsalgorithmus für jeden Nutzer optimiert werden kann.
Meta-Empfehlungssysteme bestehen aus zwei Schichten: einem Basis-Empfehlungssystem und einem Optimierer auf der Meta-Ebene. Das Basis-Recommender-System generiert Empfehlungen für die Nutzer/innen auf der Grundlage ihres bisherigen Verhaltens, während der Meta-Level-Optimierer lernt, wie er das Basis-Recommender-System für jede/n Nutzer/in optimieren kann.
Automatisiertes maschinelles Lernen, auch AutoML genannt, ist der Prozess der Automatisierung des gesamten Prozesses der Erstellung von maschinellen Lernmodellen. Dazu gehören Aufgaben wie die Vorverarbeitung der Daten, das Feature Engineering, die Modellauswahl und die Abstimmung der Hyperparameter.
Meta-Learning-Techniken können diese Prozesse unterstützen, indem sie zum Beispiel die Optimierung und Anpassung von Hyperparametern automatisieren oder sogar das am besten geeignete Modell zur Lösung einer bestimmten Aufgabe finden.
Es gibt mehrere zwingende Gründe, warum Forscher/innen, die sich mit maschinellem Lernen befassen, zunehmend auf Meta-Learning-Strategien zurückgreifen, um ihre Modelle zu entwickeln.
Trainingseffizienz: Meta-Lernen verkürzt die Trainingszeit, da die Modelle nicht mit großen Datensätzen trainiert werden müssen, und ermöglicht eine Feinabstimmung mit begrenzten Daten.
Senkung der Betriebskosten: Meta-Lernen senkt die Kosten, weil es nicht mehr nötig ist, Modelle von Grund auf zu trainieren, wobei sowohl die Beschaffung der Daten als auch der Einsatz von Rechenressourcen zum Trainieren eines Modells teuer sein können.
Verbesserte Anpassungsfähigkeit und Wiederverwendbarkeit: Meta-Lernen ist eine Schlüsseltechnik, die es den Modellen ermöglicht, sich an verschiedene Szenarien und Aufgaben anzupassen und so ihr Potenzial und ihre Nutzbarkeit zu erhöhen.
Modellleistung: Neben der Verbesserung der Anpassungsfähigkeit kann Meta-Lernen auch die Genauigkeit bestehender maschineller Lernmodelle verbessern.
Meta-Lernen ist jedoch keine Einheitsstrategie. Es gibt Grenzen und potenzielle Fallstricke, die sorgfältig beachtet werden müssen. Einige der häufigsten Herausforderungen beim Metalernen sind:
Die Domäne stimmt nicht überein: Meta-Lernen funktioniert eher, wenn die Ausgangs- und die Zielaufgaben in gewissem Maße miteinander verbunden sind. Wenn die neue Aufgabe sehr unterschiedlich ist, reicht das übertragene verallgemeinerbare Wissen möglicherweise nicht aus, um die neue Aufgabe genau auszuführen, und es kann sogar die Leistung in allen Aufgaben verringern.
Datenknappheit: Es ist immer eine bestimmte Menge an Trainingsdaten erforderlich. Wenn die Trainingsdaten extrem begrenzt sind oder die Qualität der Daten schlecht ist, wird das Modell wahrscheinlich nicht richtig angepasst.
Überanpassung: Auch Meta-Lernen ist nicht immun gegen Overfitting. Wenn das Modell für eine Aufgabe zu sehr verfeinert wird, kann es aufgabenspezifische Merkmale lernen, die sich nicht gut auf neue Daten übertragen lassen.
Komplexität und Kosten: Manchmal ist die Zielaufgabe so komplex, dass der Feinabstimmungsprozess schwierig, rechenintensiv und zeitaufwändig sein kann.
Meta-Lernen ist ein wichtiger Ansatz, um die Effizienz und das Potenzial neuronaler Netze zu erhöhen. Man kann mit Fug und Recht behaupten, dass die derzeitige KI-Revolution ohne die vielen verfügbaren Transfer-Learning-Techniken nicht möglich gewesen wäre.
Das Feld entwickelt sich rasant weiter und es gibt einige Bereiche, die noch weiter erforscht werden müssen, z. B:
Da die Modelle des maschinellen Lernens immer größer und komplexer werden, ist es für die KI-Branche von entscheidender Bedeutung, neue Techniken zu finden, um sie effizienter und vielseitiger zu machen, damit sie ihre Versprechen einhalten, die Zahlen funktionieren und die Nachhaltigkeit in der Branche voranbringen kann.
Meta-Lernen hat in dieser Hinsicht eine Menge zu sagen. Dieser Forschungsbereich entwickelt sich schnell weiter und bietet eine Reihe von Techniken und Strategien, die für die Weiterentwicklung der KI entscheidend sind. Bleib auf dem Laufenden mit DataCamp, um die neuesten Nachrichten in Sachen Meta Learning, KI und vielem mehr zu erfahren:
Lernen mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
