ANOVA
Si vous avez analysé des plans d'ANOVA dans des progiciels statistiques traditionnels, vous trouverez probablement l'approche de R moins cohérente et moins conviviale. Une bonne présentation en ligne de l'ANOVA en R est disponible dans la section ANOVA</a > du Projet Personnalité. (Note : J'ai constaté que ces pages s'affichent correctement dans les navigateurs Chrome et Safari, mais qu'elles peuvent être déformées dans iExplorer).
1. Adapter un modèle
Dans les exemples suivants, les lettres minuscules sont des variables numériques et les lettres majuscules sont des facteurs.
# One Way Anova (Completely Randomized Design)
fit <- aov(y ~ A, data=mydataframe)# Randomized Block Design (B is the blocking factor)
fit <- aov(y ~ A + B, data=mydataframe)# Two Way Factorial Design
fit <- aov(y ~ A + B + A:B, data=mydataframe)
fit <- aov(y ~ A*B, data=mydataframe)
# same thing# Analysis of Covariance
fit <- aov(y ~ A + x, data=mydataframe)Pour les modèles à l'intérieur des sujets, la base de données doit être réorganisée de manière à ce que chaque mesure sur un sujet soit une observation distincte. Voir R et Analyse de la variance.
# One Within Factor
fit <- aov(y~A+Error(Subject/A),data=mydataframe)# Two Within Factors W1 W2, Two Between Factors B1 B2
fit <- aov(y~(W1*W2*B1*B2)+Error(Subject/(W1*W2))+(B1*B2),
data=mydataframe)2. Examinez les diagrammes de diagnostic
Les graphiques de diagnostic permettent de vérifier l'hétéroscédasticité, la normalité et les observations influentes. ``R layout(matrix(c(1,2,3,4),2,2)) # disposition optionnelle
plot(fit) # diagnostic plots
Pour plus de détails sur l'évaluation des exigences des tests, voir [(M)ANOVA Assumptions](/stats/anovaAssumptions.html). ### 3. Évaluer les effets du modèle **Attention** : R fournit [Type I sequential SS](http://afni.nimh.nih.gov/sscc/gangc/SS.html), et non le [Type III marginal SS](http://afni.nimh.nih.gov/sscc/gangc/SS.html) par défaut indiqué par SAS et SPSS. Dans un plan non orthogonal comportant plus d'un terme du côté droit de l'équation, **l'ordre est important** (c'est-à-dire que A+B et B+A produiront des résultats _différents_) ! Nous devrons utiliser la fonction **drop1( )** pour produire les résultats familiers de type III. Il comparera chaque terme avec le modèle complet. Nous pouvons également utiliser anova(fit.model1, fit.model2) pour comparer directement les modèles imbriqués. ```R summary(fit) # afficher le tableau des ANOVA de type I drop1(fit,~.,test="F") # tests SS et F de type III
Des alternatives non paramétriques et de rééchantillonnage sont disponibles.
Comparaisons multiples
Vous pouvez obtenir les tests HSD de Tukey à l'aide de la fonction ci-dessous. Par défaut, il calcule des comparaisons post hoc sur chaque facteur du modèle. Vous pouvez spécifier des facteurs spécifiques en option. Encore une fois, n'oubliez pas que les résultats sont basés sur le type I SS !
# Tukey Honestly Significant Differences
TukeyHSD(fit) # where fit comes from aov()Visualisation des résultats
Utilisez des diagrammes en boîte et des diagrammes linéaires pour visualiser les différences entre les groupes. Il existe également deux fonctions spécialement conçues pour visualiser les différences de moyenne dans les présentations ANOVA. interaction.plot( ) dans le package stats de base produit des graphiques pour les interactions à deux voies. plotmeans( ) dans le package gplots</a > produit des graphiques de moyenne pour les facteurs uniques, et inclut des intervalles de confiance.
# Two-way Interaction Plot
attach(mtcars)
gears <- factor(gears)
cyl <- factor(cyl)
interaction.plot(cyl, gear, mpg, type="b", col=c(1:3),
leg.bty="o", leg.bg="beige", lwd=2, pch=c(18,24,22),
xlab="Number of Cylinders",
ylab="Mean Miles Per Gallon",
main="Interaction Plot")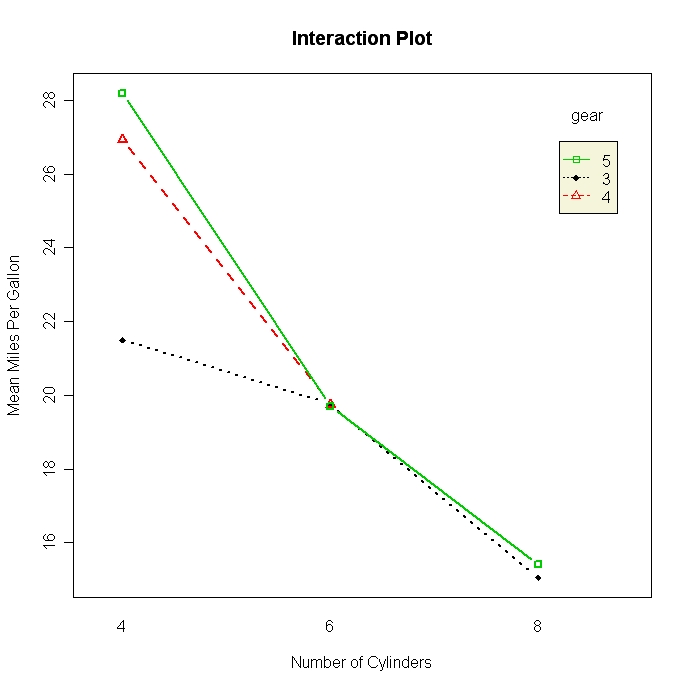
# Plot Means with Error Bars
library(gplots)
attach(mtcars)
cyl <- factor(cyl)
plotmeans(mpg~cyl,xlab="Number of Cylinders",
ylab="Miles Per Gallon", main="Mean Plot\nwith 95% CI")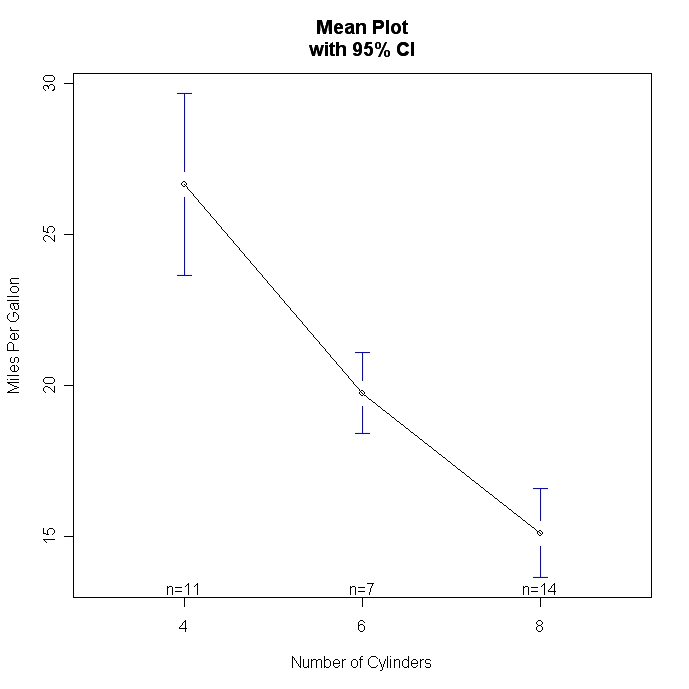
MANOVA
S'il y a plus d'une variable dépendante (résultat), vous pouvez les tester simultanément à l'aide d'une analyse de variance multivariée (MANOVA). Dans l'exemple suivant, prenons Y comme matrice dont les colonnes sont les variables dépendantes.
# 2x2 Factorial MANOVA with 3 Dependent Variables.
Y <- cbind(y1,y2,y3)
fit <- manova(Y ~ A*B)
summary(fit, test="Pillai")Les autres options de test sont "Wilks", "Hotelling-Lawley" et "Roy". Utilisez summary.aov( ) pour obtenir des statistiques univariées. TukeyHSD( ) et plot( ) ne fonctionneront pas avec un ajustement MANOVA. Exécutez chaque variable dépendante séparément pour les obtenir. Comme pour l'ANOVA, les résultats de la MANOVA dans R sont basés sur le Type I SS. Pour obtenir un SS de type III, modifiez l'ordre des variables dans le modèle et relancez les analyses. Par exemple, ajustez y~A*B pour l'effet de type III B et y~B*A pour l'effet de type III A.</span>.
Aller plus loin
R dispose d'excellents outils pour ajuster les modèles linéaires et les modèles linéaires généralisés à effets mixtes. La dernière implémentation se trouve dans le paquet lme4. Consultez l'article de R News sur l'ajustement des modèles linéaires mixtes dans R</a > pour plus de détails.