Graphiques de probabilité en R
Cette section décrit la création de diagrammes de probabilité dans R à des fins didactiques et pour l'analyse de données.
Graphiques de probabilité pour l'enseignement et la démonstration
Lorsque j'enseignais les statistiques à l'université, je devais dessiner des distributions normales à la main. Ils ressemblaient toujours à des lapins. Qu'est-ce que je peux dire ?
Avec R, il est facile de tracer des distributions de probabilités et de démontrer des concepts statistiques. Vous trouverez ci-dessous quelques-unes des distributions de probabilités les plus courantes disponibles dans R.
| distribution | Nom R | distribution | Nom R |
| Beta | beta | Lognormal | lnorm |
| Binôme | binôme | Binôme négatif | nbinom |
| Cauchy | cauchy | Normal | norme |
| Chisquare | chisq | Poisson | pois |
| Exponentiel | exp | Étudiant t | t |
| F | f | Uniforme | unif |
| Gamma | gamma | Tukey | tukey |
| Géométrique | geom | Weibull | weib |
| Hypergeometric | hyper | Wilcoxon | wilcox |
| Logistique | logis |
Pour une liste complète, voir Distributions statistiques sur le wiki R. Les fonctions disponibles pour chaque distribution suivent ce format :
| nom | description |
| d nom( ) | fonction de densité ou de probabilité |
| p nom( ) | fonction de densité cumulative |
| q nom( ) | fonction quantile |
| R_name_( ) | écarts aléatoires |
Par exemple, pnorm(0) = 0,5 (l'aire sous la courbe normale standard à gauche de zéro). qnorm(0,9) = 1,28 (1,28 est le 90e percentile de la distribution normale standard). rnorm(100) génère 100 écarts aléatoires à partir d'une distribution normale standard.
Chaque fonction a des paramètres spécifiques à cette distribution. Par exemple, rnorm(100, m=50, sd=10) génère 100 écarts aléatoires à partir d'une distribution normale avec une moyenne de 50 et un écart-type de 10.
Vous pouvez utiliser ces fonctions pour démontrer divers aspects des distributions de probabilités. Deux exemples courants sont donnés ci-dessous.
# Display the Student's t distributions with various
# degrees of freedom and compare to the normal distribution
x <- seq(-4, 4, length=100)
hx <- dnorm(x)
degf <- c(1, 3, 8, 30)
colors <- c("red", "blue", "darkgreen", "gold", "black")
labels <- c("df=1", "df=3", "df=8", "df=30", "normal")
plot(x, hx, type="l", lty=2, xlab="x value",
ylab="Density", main="Comparison of t Distributions")
for (i in 1:4){
lines(x, dt(x,degf[i]), lwd=2, col=colors[i])
}
legend("topright", inset=.05, title="Distributions",
labels, lwd=2, lty=c(1, 1, 1, 1, 2), col=colors)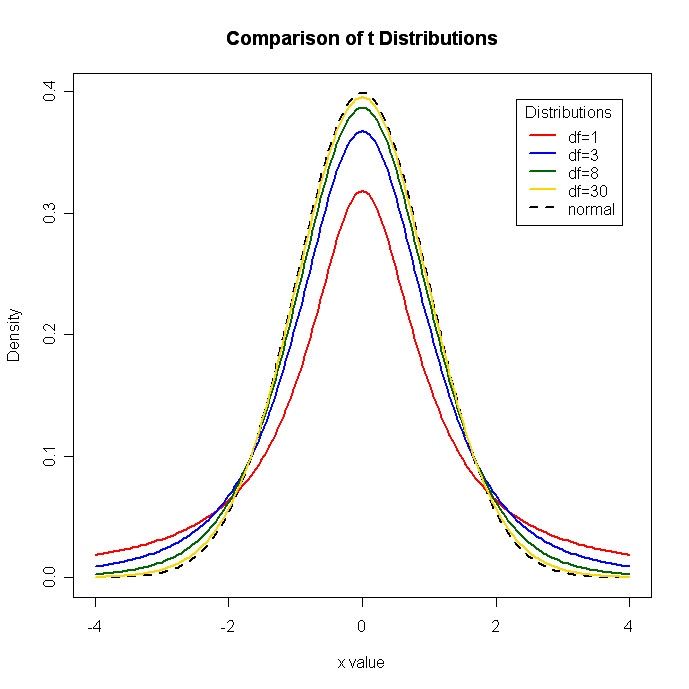
# Children's IQ scores are normally distributed with a
# mean of 100 and a standard deviation of 15. What
# proportion of children are expected to have an IQ between
# 80 and 120?
mean=100; sd=15
lb=80; ub=120
x <- seq(-4,4,length=100)*sd + mean
hx <- dnorm(x,mean,sd)
plot(x, hx, type="n", xlab="IQ Values", ylab="",
main="Normal Distribution", axes=FALSE)
i <- x >= lb & x <= ub
lines(x, hx)
polygon(c(lb,x[i],ub), c(0,hx[i],0), col="red")
area <- pnorm(ub, mean, sd) - pnorm(lb, mean, sd)
result <- paste("P(",lb,"< IQ <",ub,") =",
signif(area, digits=3))
mtext(result,3)
axis(1, at=seq(40, 160, 20), pos=0)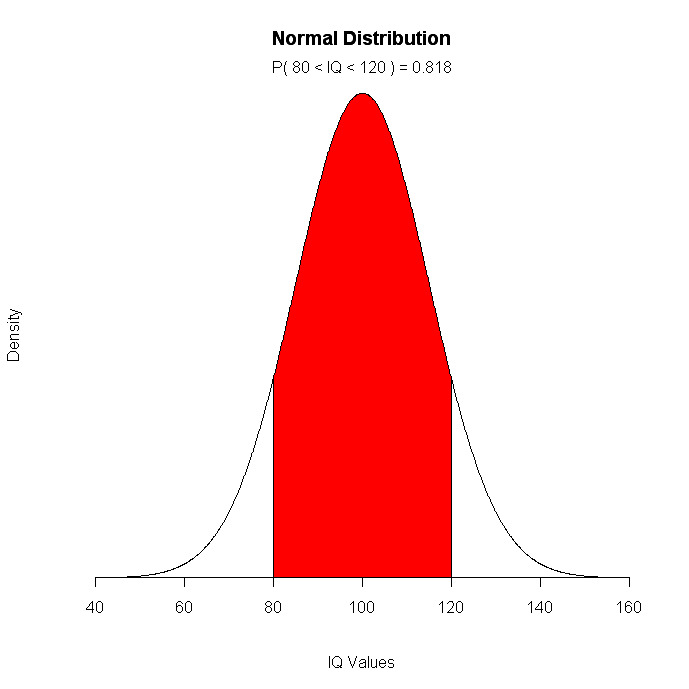
Pour une vue d'ensemble de la représentation graphique des probabilités en R, consultez l'ouvrage de Vincent Zonekynd intitulé Probability Distributions.
Ajustement des distributions
Il existe plusieurs méthodes d'ajustement des distributions dans R. Voici quelques options.
Vous pouvez utiliser la fonction qqnorm( ) pour créer un graphique Quantile-Quantile évaluant l'adéquation des données de l'échantillon à la distribution normale. Plus généralement, la fonction qqplot( ) crée un graphique Quantile-Quantile pour n'importe quelle distribution théorique.
# Q-Q plots
par(mfrow=c(1,2))
# create sample data
x <- rt(100, df=3)
# normal fit
qqnorm(x);
qqline(x)
# t(3Df) fit
qqplot(rt(1000,df=3), x, main="t(3) Q-Q Plot",
ylab="Sample Quantiles")
abline(0,1)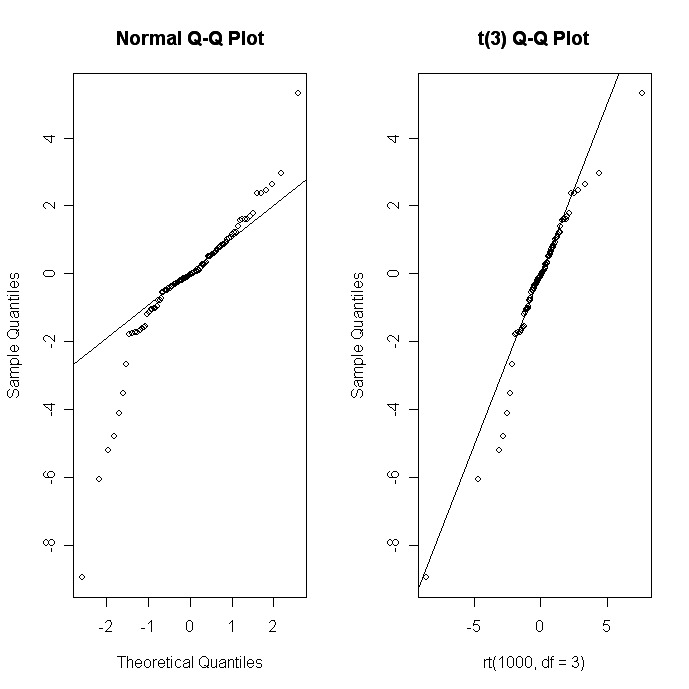
La fonction fitdistr( ) du progiciel MASS permet d'ajuster des distributions univariées selon le principe du maximum de vraisemblance. Le format est fitdistr(x, densityfunction) où x est l'échantillon de données et densityfunction est l'un des suivants : beta", "cauchy", "chi-carré", "exponentiel", "f", "gamma", "géométrique", "log-normal", "lognormal", "logistique", "binomial négatif", "normal", "normal", "normal", "normal", "normal", "normal", etc.log-normal", "lognormal", "logistique", "binomial négatif", "normal", "Poisson", "t" ou "weibull".
# Estimate parameters assuming log-Normal distribution
# create some sample data
x <- rlnorm(100)
# estimate paramters
library(MASS)
fitdistr(x, "lognormal")Enfin, R dispose d'un large éventail de tests d'adéquation permettant d'évaluer s'il est raisonnable de supposer qu'un échantillon aléatoire provient d'une distribution théorique donnée. Il s'agit notamment du chi-carré, de Kolmogorov-Smirnov et d'Anderson-Darling.
Pour plus de détails sur l'ajustement des distributions, voir Fitting Distributions with R de Vito Ricci.
Pratiquer
Essayez ce cours interactif sur l'analyse exploratoire des données.