Gráficos de probabilidade no R
Esta seção descreve a criação de gráficos de probabilidade no R, tanto para fins didáticos quanto para análise de dados.
Gráficos de probabilidade para ensino e demonstração
Quando eu era professor universitário de estatística, costumava desenhar distribuições normais à mão. Eles sempre saíam parecendo coelhinhos. O que posso dizer?
O R facilita o desenho de distribuições de probabilidade e a demonstração de conceitos estatísticos. Algumas das distribuições de probabilidade mais comuns disponíveis no R são apresentadas a seguir.
| distribuição | Nome da R | distribuição | Nome da R |
| Beta | beta | Lognormal | lnorma |
| Binomial | binômio | Binomial negativo | nbinom |
| Cauchy | cauchy | Normal | norma |
| Chisquare | chisq | Poisson | pois |
| Exponencial | exp | Estudante t | t |
| F | f | Uniform | unif |
| Gamma | gamma | Tukey | tukey |
| Geométrico | geom | Weibull | weib |
| Hipergeométrico | hiper | Wilcoxon | wilcox |
| Logística | logis |
Para obter uma lista abrangente, consulte Distribuições estatísticas no wiki do R. As funções disponíveis para cada distribuição seguem este formato:
| nome | descrição |
| d name( ) | função de densidade ou probabilidade |
| p name( ) | função de densidade cumulativa |
| q name( ) | função quantil |
| R_name_( ) | desvios aleatórios |
Por exemplo, pnorm(0) =0,5 (a área sob a curva normal padrão à esquerda de zero). qnorm(0,9) = 1,28 (1,28 é o 90º percentil da distribuição normal padrão). rnorm(100) gera 100 desvios aleatórios de uma distribuição normal padrão.
Cada função tem parâmetros específicos para essa distribuição. Por exemplo, rnorm(100, m=50, sd=10) gera 100 desvios aleatórios de uma distribuição normal com média 50 e desvio padrão 10.
Você pode usar essas funções para demonstrar vários aspectos das distribuições de probabilidade. Dois exemplos comuns são apresentados a seguir.
# Display the Student's t distributions with various
# degrees of freedom and compare to the normal distribution
x <- seq(-4, 4, length=100)
hx <- dnorm(x)
degf <- c(1, 3, 8, 30)
colors <- c("red", "blue", "darkgreen", "gold", "black")
labels <- c("df=1", "df=3", "df=8", "df=30", "normal")
plot(x, hx, type="l", lty=2, xlab="x value",
ylab="Density", main="Comparison of t Distributions")
for (i in 1:4){
lines(x, dt(x,degf[i]), lwd=2, col=colors[i])
}
legend("topright", inset=.05, title="Distributions",
labels, lwd=2, lty=c(1, 1, 1, 1, 2), col=colors)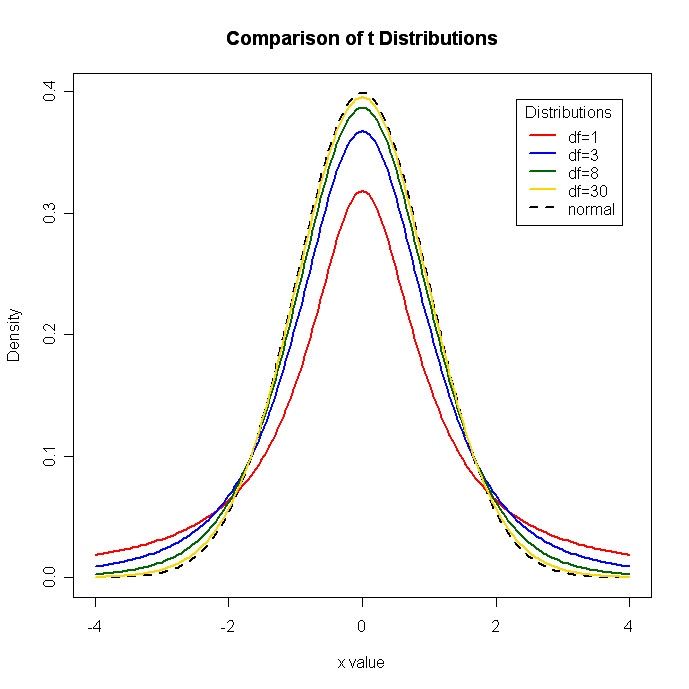
# Children's IQ scores are normally distributed with a
# mean of 100 and a standard deviation of 15. What
# proportion of children are expected to have an IQ between
# 80 and 120?
mean=100; sd=15
lb=80; ub=120
x <- seq(-4,4,length=100)*sd + mean
hx <- dnorm(x,mean,sd)
plot(x, hx, type="n", xlab="IQ Values", ylab="",
main="Normal Distribution", axes=FALSE)
i <- x >= lb & x <= ub
lines(x, hx)
polygon(c(lb,x[i],ub), c(0,hx[i],0), col="red")
area <- pnorm(ub, mean, sd) - pnorm(lb, mean, sd)
result <- paste("P(",lb,"< IQ <",ub,") =",
signif(area, digits=3))
mtext(result,3)
axis(1, at=seq(40, 160, 20), pos=0)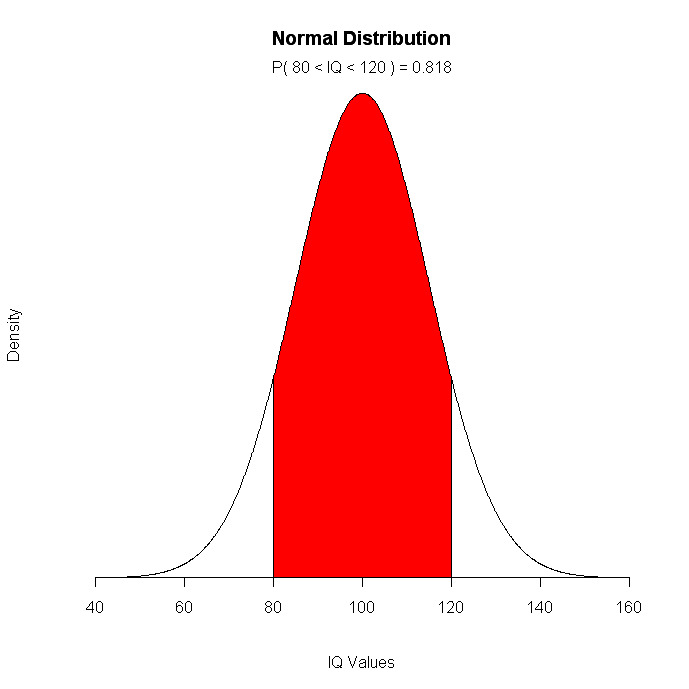
Para obter uma visão abrangente da plotagem de probabilidade no R, consulte Distribuições de probabilidade de Vincent Zonekynd.
Ajuste de distribuições
Há vários métodos de ajuste de distribuições no R. Aqui estão algumas opções.
Você pode usar a função qqnorm( ) para criar um gráfico Quantile-Quantile avaliando a adequação dos dados de amostra à distribuição normal. De modo mais geral, a função qqplot( ) cria um gráfico de quantil-quantil para qualquer distribuição teórica.
# Q-Q plots
par(mfrow=c(1,2))
# create sample data
x <- rt(100, df=3)
# normal fit
qqnorm(x);
qqline(x)
# t(3Df) fit
qqplot(rt(1000,df=3), x, main="t(3) Q-Q Plot",
ylab="Sample Quantiles")
abline(0,1)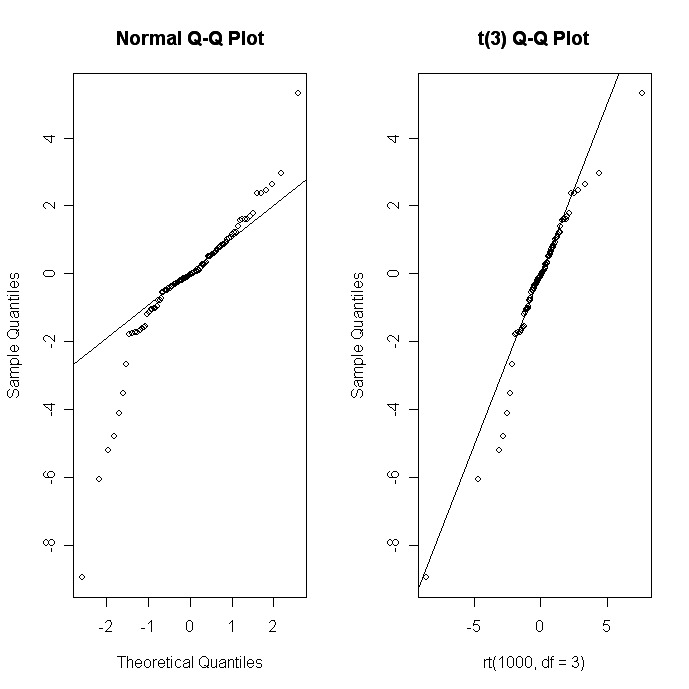
A função fitdistr( ) do pacote MASS fornece o ajuste de máxima verossimilhança de distribuições univariadas. O formato é fitdistr(x, densityfunction), em que x são os dados de amostra e densityfunction é uma das seguintes opções: "beta", "cauchy", "chi-squared", "exponential", "f", "gamma", "geometric", "log-normal"lognormal", "logistic", "negative binomial", "normal", "Poisson", "t" ou "weibull".
# Estimate parameters assuming log-Normal distribution
# create some sample data
x <- rlnorm(100)
# estimate paramters
library(MASS)
fitdistr(x, "lognormal")Por fim, o R tem uma ampla gama de testes de adequação para avaliar se é razoável supor que uma amostra aleatória seja proveniente de uma distribuição teórica especificada. Entre eles estão o qui-quadrado, Kolmogorov-Smirnov e Anderson-Darling.
Para obter mais detalhes sobre o ajuste de distribuições, consulte o artigo Fitting Distributions with R, de Vito Ricci.
Para praticar
Experimente este curso interativo sobre análise exploratória de dados.