
Cursus
Si vous avez déjà utilisé ChatGPT en mode vocal, vous savez à quel point l’expérience est bluffante. Parler à une IA qui écoute, comprend et répond presque comme une vraie personne paraît étonnamment naturel. La conversation semble fluide, intelligente et réactive. Mais il reste un écart : de légers délais, une gestion des interruptions perfectible, et l’impression de s’adresser à un système plus qu’à une personne.
Imaginez maintenant mieux. C’est précisément là que PersonaPlex intervient.
Imaginez un assistant vocal temps réel qui répond instantanément, accepte les interruptions naturellement, s’adapte en cours de phrase et se rapproche bien davantage d’une vraie conversation humaine. Aucune latence perceptible. Pas de blancs maladroits. Aucune dépendance au cloud. Juste un dialogue fluide, local et temps réel qui paraît vivant.
PersonaPlex est un système d’interaction vocale temps réel et local développé par NVIDIA. Il vise à dépasser les chaînes classiques reconnaissance vocale → texte et texte → voix. Il permet au contraire des échanges en streaming, à faible latence, où l’assistant peut parler, écouter et s’adapter en continu, comme dans une conversation en face à face.
Dans ce tutoriel, je vais vous guider pas à pas. Nous commencerons par comprendre ce qu’est PersonaPlex et pourquoi il se distingue fondamentalement des assistants vocaux classiques. Puis nous configurerons l’environnement local, installerons PersonaPlex depuis les sources et lancerons le serveur WebUI PersonaPlex. Ensuite, nous interagirons avec le système via l’interface web et, pour finir, nous testerons des conversations vocales temps réel avec un script Python.
Je vous recommande de consulter le cours Spoken Language Processing in Python pour découvrir certains des fondamentaux derrière PersonaPlex.
Qu’est-ce que PersonaPlex ?
PersonaPlex est un nouveau système d’IA conversationnelle qui rend les interactions vocales vraiment naturelles tout en vous permettant de personnaliser entièrement la voix et la persona.
Au lieu de sonner comme un assistant classique avec des pauses et des tours de parole rigides, il permet des conversations fluides et temps réel où interruptions, rythmes et intonations paraissent humains.
Au cœur du système, PersonaPlex utilise une architecture full duplex, c’est-à-dire qu’il peut écouter et parler simultanément.
Plutôt que d’enchaîner des modèles séparés pour la reconnaissance vocale, la compréhension du langage et la génération vocale, il s’appuie sur un modèle unifié qui se met à jour en continu pendant que l’utilisateur parle.
Des prompts vocaux définissent le timbre de l’assistant, tandis que des prompts textuels définissent qui il est et comment il doit se comporter. Cette combinaison permet à PersonaPlex de conserver une persona cohérente tout en répondant instantanément et naturellement.
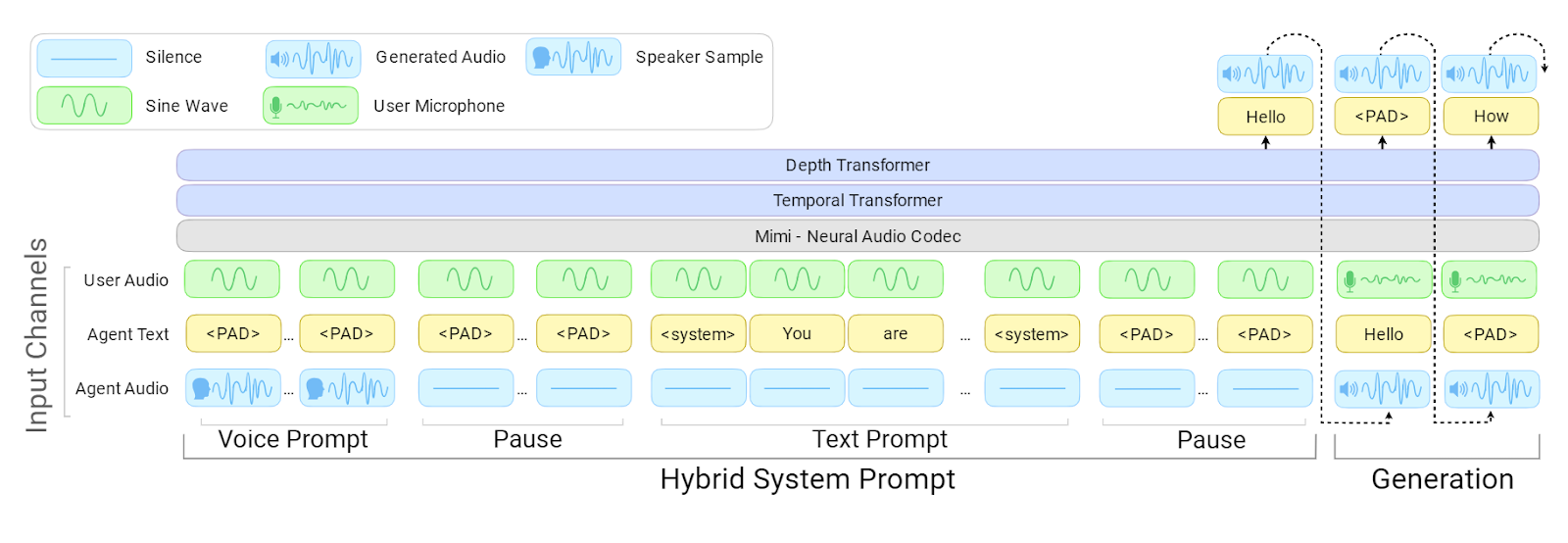
Architecture PersonaPlex | Source : NVIDIA PersonaPlex
PersonaPlex est évalué avec FullDuplexBench et un benchmark de service client étendu, ServiceDuplexBench.
Il surpasse d’autres systèmes open source et commerciaux en dynamique conversationnelle, réponses à faible latence, gestion des interruptions et respect des consignes, tant en scénarios d’assistant que de service client.
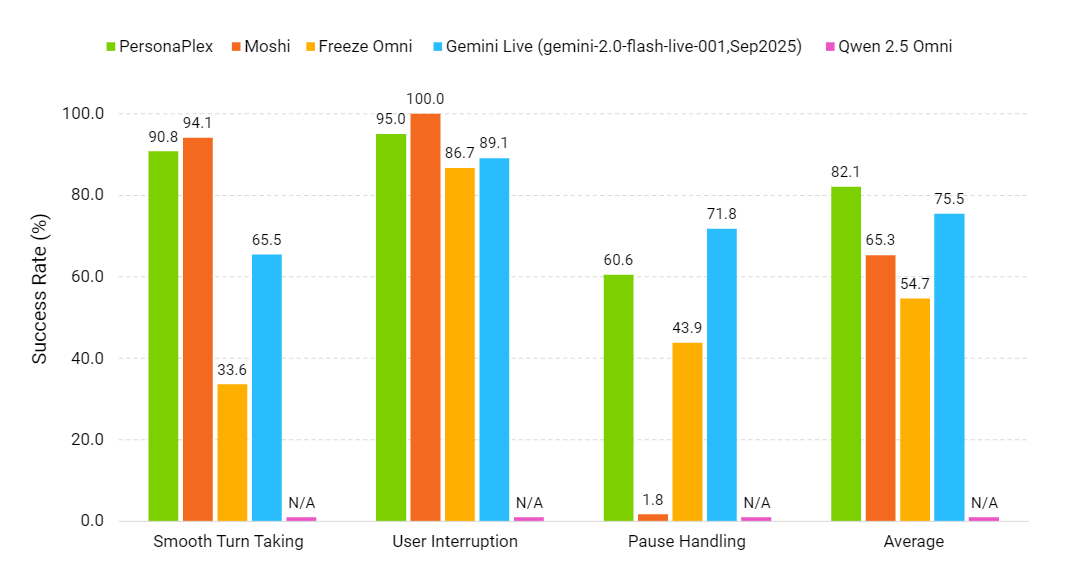
Dynamique de conversation (plus c’est élevé, mieux c’est) | Source : NVIDIA PersonaPlex
Dans la démo vidéo ci-dessous, on voit très clairement une personne tenir une conversation fluide avec le modèle, échanger des plaisanteries et des répliques en temps réel.
Configuration de l’environnement
Avant de commencer, rendez-vous sur la page du modèle Hugging Face pour nvidia/personaplex-7b-v1 et acceptez les conditions d’utilisation du modèle.
PersonaPlex est un modèle restreint : vous aurez donc besoin d’un jeton API Hugging Face. Générez ce jeton depuis votre compte Hugging Face et gardez-le à portée de main, car nous l’ajouterons ensuite aux variables d’environnement pour permettre l’accès au modèle.
Ensuite, allez sur RunPod et lancez un nouveau pod A40 GPU. Sélectionnez la dernière image PyTorch, puis cliquez sur Edit pour personnaliser l’environnement.
Augmentez la taille du disque du conteneur à 50 Go, car le modèle pèse environ 20 Go et des dépendances supplémentaires seront téléchargées. Dans la section des ports HTTP exposés, ajoutez le port 8998. Dans les variables d’environnement, ajoutez HF_TOKEN et collez votre jeton API Hugging Face.
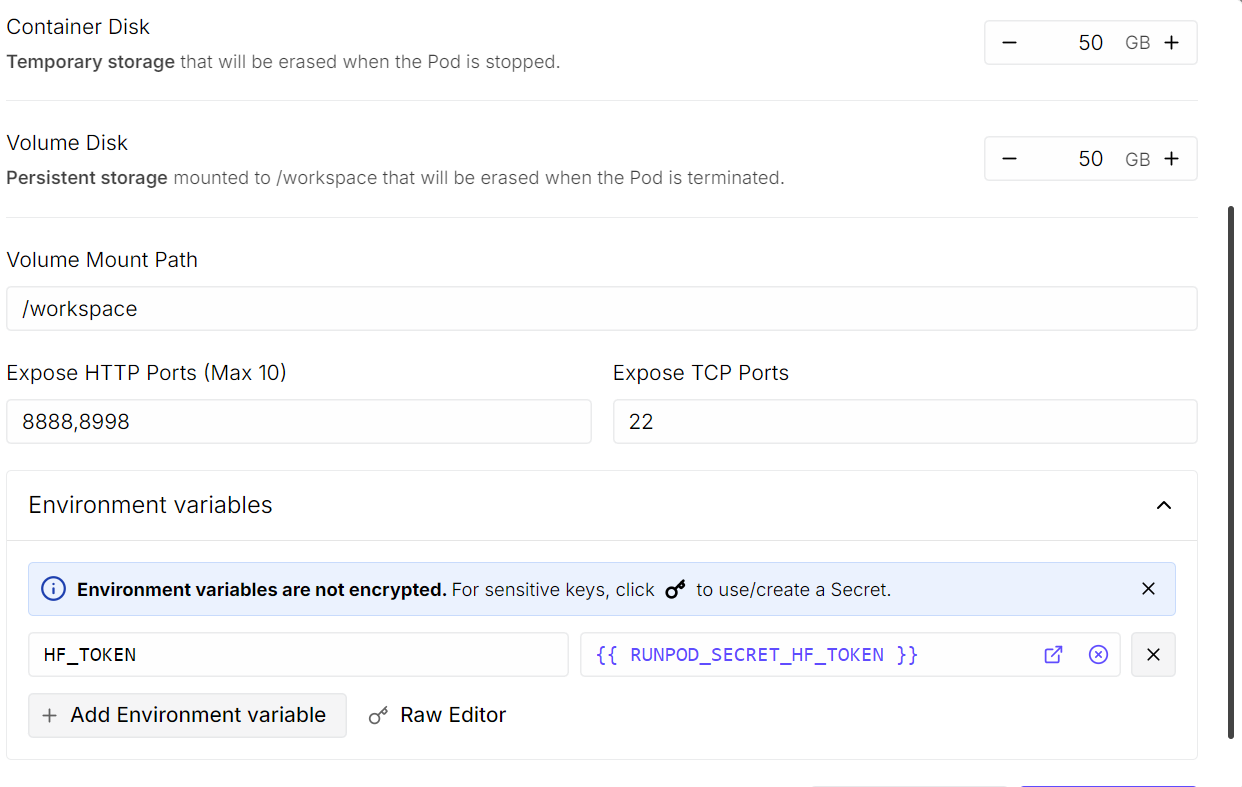
Une fois tout configuré, enregistrez les surcharges et déployez le pod.
Après le démarrage du pod, vous verrez un lien vers l’instance JupyterLab. Ouvrez-la, puis lancez un terminal. Vous pouvez accéder à la machine via SSH ou via le terminal web, mais le terminal Jupyter reste l’option la plus simple.
Dans le terminal, installez la bibliothèque de développement du codec audio Opus, nécessaire au traitement audio :
sudo apt update
sudo apt install libopus-dev
Installer PersonaPlex depuis les sources
Le code de PersonaPlex est open source chez NVIDIA et disponible sur GitHub (NVIDIA/personaplex : PersonaPlex code), ce qui facilite l’exploration, la personnalisation et l’exécution en local.
L’installation depuis les sources vous donne un contrôle total sur la configuration et garantit la compatibilité avec les dernières mises à jour du dépôt.
Pour commencer, clonez le dépôt PersonaPlex :
git clone https://github.com/NVIDIA/personaplex.git
cd personaplex
Installez ensuite Moshi, le modèle vocal full duplex cœur sur lequel repose PersonaPlex.
Moshi gère l’écoute et la parole en temps réel, permettant à PersonaPlex de gérer interruptions, pauses et rythme conversationnel naturel sans pipeline ASR → LLM → TTS traditionnel.
L’installer depuis les sources garantit que tous les composants audio, streaming et conversationnels sont correctement configurés pour une exécution locale.
pip install moshi/.Une fois Moshi installé, votre environnement est prêt pour démarrer le serveur PersonaPlex et interagir en temps réel avec le modèle.
Démarrer le serveur WebUI PersonaPlex
Avec l’environnement et les dépendances en place, vous pouvez maintenant lancer le serveur WebUI PersonaPlex. Dans le terminal, exécutez la commande suivante pour démarrer le serveur Moshi qui alimente PersonaPlex :
python -m moshi.server --host 0.0.0.0 --port 8998Au premier lancement, le serveur téléchargera automatiquement le modèle PersonaPlex et les fichiers requis. Cette étape peut prendre quelques minutes selon votre débit, car le modèle est volumineux.
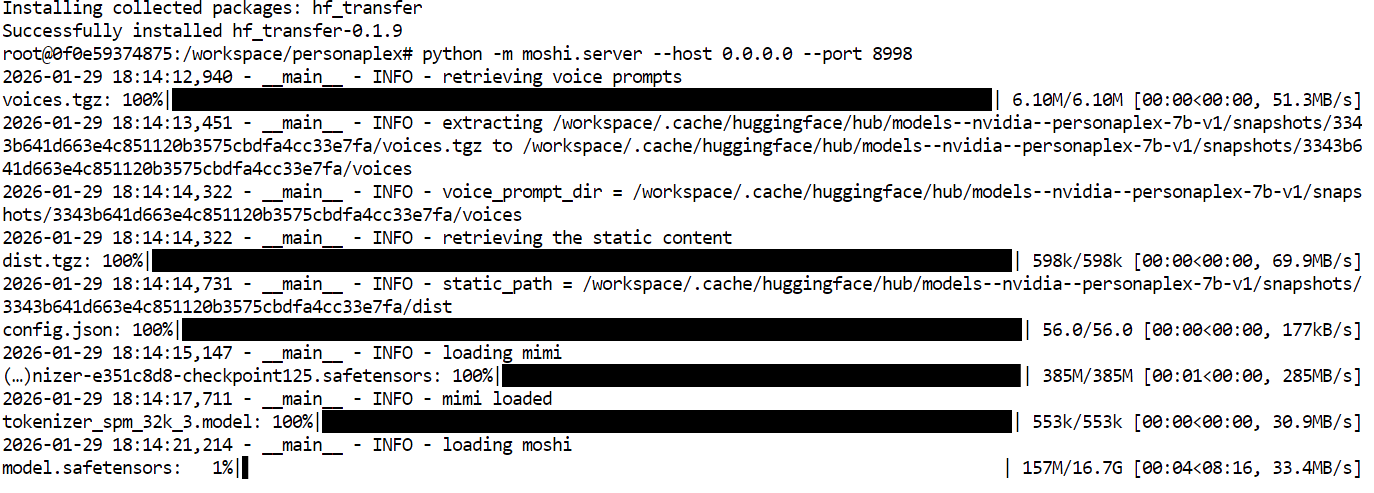
Une fois le téléchargement terminé, le serveur écoutera sur le port 8998.

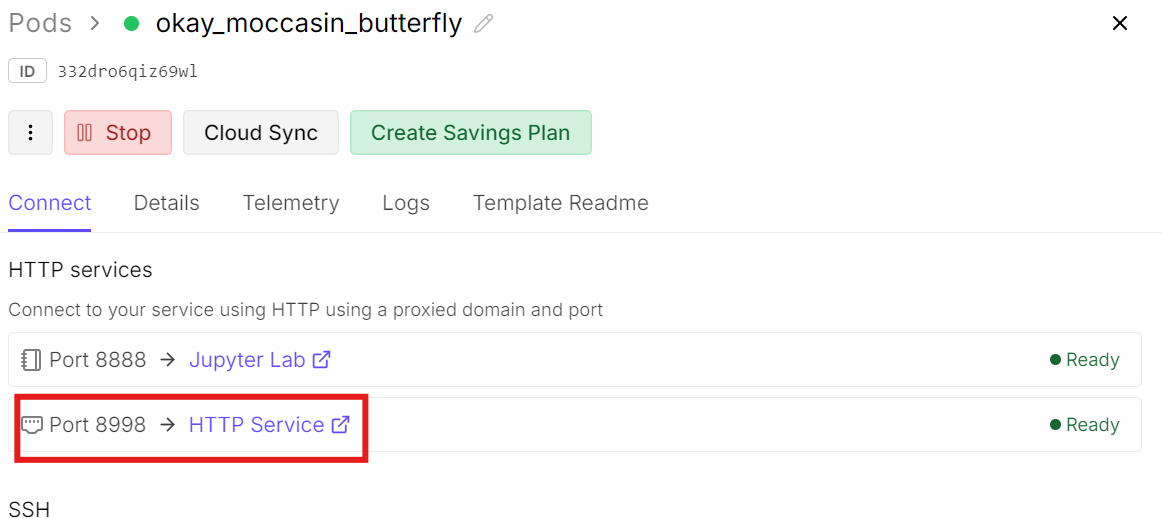
Pour accéder au WebUI, retournez sur votre tableau de bord RunPod.
Dans la section Connect, trouvez le port exposé 8998 et cliquez sur le lien proposé. Le WebUI PersonaPlex s’ouvrira dans votre navigateur, où vous pourrez commencer à interagir avec le modèle en conversation vocale temps réel.
Tester PersonaPlex via le WebUI
Le WebUI PersonaPlex propose plusieurs prompts d’exemple pour vous lancer, et vous pouvez aussi créer votre propre prompt personnalisé pour définir le rôle et le comportement de l’assistant.
Vous pouvez sélectionner une voix avant de vous connecter, ce qui détermine le rendu vocal de la persona pendant la conversation.
Pour ce tutoriel, mieux vaut commencer avec les paramètres par défaut pour prendre en main le système.
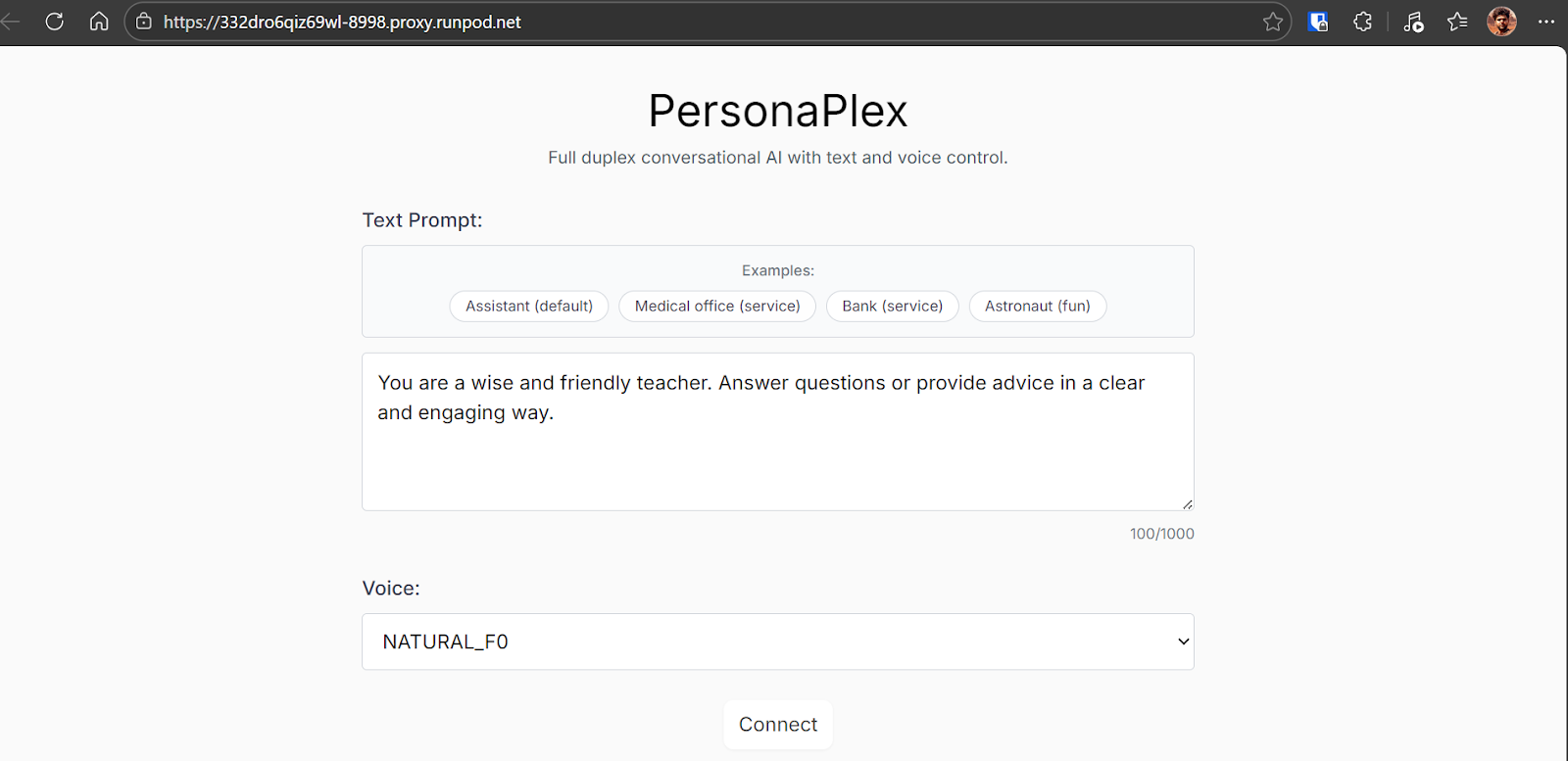
Après avoir cliqué sur le bouton Connect, vous accéderez à la session interactive. Vous pourrez y parler directement au modèle, entendre ses réponses en temps réel et voir la transcription s’afficher en direct.
L’expérience est fluide, avec un rythme naturel et la possibilité d’interrompre ou de rebondir rapidement.
Lors de mes tests, l’interaction m’a paru étonnamment naturelle et engageante.
J’ai constaté quelques légers hésitations, sans doute dues au navigateur ou à la charge système plutôt qu’au modèle lui-même. En dehors de cela, la conversation était très proche d’un échange avec une vraie personne.
Une fois à l’aise, essayez différents prompts et voix. PersonaPlex prend en charge un large éventail d’empreintes vocales préintégrées, incluant des voix de conversation naturelles et des variantes plus expressives :
- Naturelle (féminin) : NATF0, NATF1, NATF2, NATF3
- Naturelle (masculin) : NATM0, NATM1, NATM2, NATM3
- Variété (féminin) : VARF0, VARF1, VARF2, VARF3, VARF4
- Variété (masculin) : VARM0, VARM1, VARM2, VARM3, VARM4
Changer de voix et de prompt est un excellent moyen d’explorer comment PersonaPlex conserve la personnalité, le ton et le flux conversationnel selon les rôles et styles d’élocution.
Exécuter PersonaPlex hors ligne avec Python
Le WebUI est idéal pour les conversations en direct, mais vous pouvez aussi exécuter PersonaPlex hors ligne depuis Python. C’est utile pour obtenir des sorties répétables, tester rapidement différents prompts ou générer des fichiers audio réutilisables dans des démos et expériences.
Le flux hors ligne est simple : vous fournissez (1) un prompt vocal, (2) un prompt textuel et (3) un fichier WAV en entrée. PersonaPlex génère ensuite une réponse audio et un fichier JSON contenant la transcription du modèle.
Démarrez un nouveau notebook dans Jupyter et placez-vous dans le référentiel cloné :
%cd personaplexExécutez ce qui suit dans une nouvelle cellule. Cela appelle l’exécuteur hors ligne et écrit sur disque l’audio généré ainsi que la transcription :
%%capture
!python -m moshi.offline \
--voice-prompt "NATF2.pt" \
--text-prompt "You are a wise and friendly teacher. Answer questions in a clear, engaging way." \
--input-wav "assets/test/input_assistant.wav" \
--seed 42424242 \
--output-wav "out_teacher.wav" \
--output-text "out_teacher.json"Rôle de chaque indicateur :
--voice-promptsélectionne l’empreinte vocale (ici, une voix féminine naturelle).--text-promptdéfinit le rôle et le comportement de l’assistant.--input-wavcorrespond à l’audio utilisateur auquel le modèle répondra.--seedrend la sortie plus reproductible entre les exécutions.--output-wavest la réponse vocale générée.--output-textenregistre la transcription au format JSON.
Une fois la commande terminée, vous pouvez lire l’audio de réponse directement :
from IPython.display import Audio
Audio("out_teacher.wav")Vous devriez entendre une réponse claire et naturelle dans la voix sélectionnée, conforme à la persona définie par votre prompt textuel.

La transcription JSON peut parfois contenir des artefacts de tokenisation, comme des espaces en trop autour de la ponctuation ou des morceaux de mots coupés. Le helper ci-dessous charge le JSON et le nettoie pour produire un texte lisible.
import json
import re
with open("out_teacher.json") as f:
data = json.load(f)
def detokenize(tokens):
# 1) drop padding-like tokens
drop = {"PAD", "EPAD", "<pad>", "</s>", "<s>"}
toks = [t for t in tokens if t not in drop]
# 2) join with spaces first
s = " ".join(toks)
# 3) fix spacing around punctuation
s = re.sub(r"\s+([.,!?;:])", r"\1", s)
# 4) fix common split contractions: "it ' s" -> "it's"
s = s.replace(" ' s", "'s").replace(" n't", "n't").replace(" 're", "'re").replace(" 'm", "'m").replace(" 've", "'ve").replace(" 'd", "'d")
# 5) fix stray spaces around apostrophes
s = re.sub(r"\s+'\s+", "'", s)
# 6) fix cases like "for k" -> "fork" and "fl uff" -> "fluff"
# (general rule: merge single-letter fragments if they look like split wordpieces)
s = re.sub(r"\b([A-Za-z])\s+([A-Za-z]{1,3})\b", r"\1\2", s)
# 7) collapse multiple spaces
s = re.sub(r"\s{2,}", " ", s).strip()
return s
clean_text = detokenize(data) # replace with your list variable
clean_textVous devriez maintenant voir une chaîne de transcription lisible correspondant à l’audio généré. Si votre sortie contient encore des séparations étranges (par exemple, « fl uff » ou « afor k »), c’est normal pour certaines exécutions et cela peut se corriger davantage avec des règles supplémentaires, mais le fond devrait déjà être compréhensible.
"Hey, let me know if you have any questions.
Hmm, first rinse the rice a couple of times until the water runs clear, that cuts down on starch, then use apot with a tight fitting lid, bring to a boil,
give it a quick stir, then turn the heat down low and cover, let it s immer without lifting it, and when it'done fl uff it with afor k, that usually
You could to ss the hot rice with a nice handful of chopped fresh herbs like basil or par sley, or you could sprinkle a little g rated cheese,
a squeeze of lemon or lime, adr izzle of olive oil, some chopped fresh herbs, or even some to ast ed nuts, that adds color and flavor."Conclusion
Tester PersonaPlex m’a vraiment surpris. Dès les premiers échanges, on a moins l’impression d’expérimenter un modèle que de tenir une vraie conversation. Pouvoir interrompre naturellement, obtenir des réponses instantanées et conserver une personnalité cohérente place ce système bien au-dessus de la plupart des solutions vocales que j’ai testées. Le fait de tout exécuter en local renforce encore cette impression, sans délai perceptible ni perte de contrôle.
Il subsiste quelques limites. J’ai relevé des hésitations occasionnelles, et lorsque la discussion évolue, le retour à un sujet antérieur n’est pas toujours géré avec fluidité.
Il ne comprend pas encore parfaitement les accents non anglophones, ce qui peut entraîner des noms mal prononcés ou des transcriptions imparfaites. Cela ressemble à des cas limites plutôt qu’à des problèmes fondamentaux, et je suis confiant quant à des améliorations rapides.
Je suis persuadé que ces points seront résolus à l’avenir, et que nous bénéficierons d’une IA conversationnelle encore meilleure, entièrement locale et temps réel, alliant le raisonnement de GPT-5.2 à la qualité vocale d’ElevenLabs.

