
Programa
Fundamentos de Hugging Face
12 h
Se você já usou o modo de voz do ChatGPT, sabe como é impressionante. Conversar com uma IA que escuta, entende e responde quase como uma pessoa de verdade pode soar surpreendentemente natural. A experiência é conversacional, inteligente e ágil. Ainda assim, existe um gap: pequenos atrasos, limitação para lidar com interrupções e aquela sensação de que você ainda está falando com um sistema — não com alguém.
Agora imagine algo melhor. É exatamente aí que o PersonaPlex entra.
Pense em um assistente de voz em tempo real que responde na hora, permite que você interrompa naturalmente, se adapta no meio da frase e chega muito mais perto de uma conversa humana. Sem latência perceptível. Sem pausas constrangedoras. Sem depender da nuvem. Só um diálogo local, em tempo real, fluido e vivo.
PersonaPlex é um sistema local de interação por voz em tempo real desenvolvido pela NVIDIA. Ele foi criado para levar a IA por voz além do pipeline básico de speech-to-text e text-to-speech. Em vez disso, ele viabiliza conversas em streaming, de baixa latência, em que o assistente fala, escuta e se adapta continuamente — como alguém faria em uma conversa cara a cara.
Neste tutorial, vou te guiar passo a passo pelo PersonaPlex. Vamos começar entendendo o que é o PersonaPlex e por que ele parece fundamentalmente diferente de assistentes de voz típicos. Depois, vamos configurar o ambiente local, instalar o PersonaPlex a partir do código-fonte e iniciar o servidor da WebUI. Em seguida, vamos interagir com o sistema pela interface web e, por fim, testar conversas de voz em tempo real usando um script em Python.
Recomendo conferir o curso Spoken Language Processing in Python para aprender alguns dos fundamentos por trás do PersonaPlex.
PersonaPlex é um novo sistema de IA conversacional que deixa as interações por voz realmente naturais, sem abrir mão de personalizar totalmente a voz e a persona.
Em vez de soar como um assistente típico, com pausas e turnos rígidos, ele permite conversas suaves e em tempo real, em que interrupções, timing e tom soam humanos.
No núcleo, o PersonaPlex usa uma arquitetura full-duplex — ou seja, ele consegue ouvir e falar ao mesmo tempo.
Em vez de encadear modelos separados para reconhecimento de fala, compreensão e síntese, ele se baseia em um único modelo unificado que se atualiza continuamente enquanto o usuário fala.
Prompts de voz definem como o assistente soa, enquanto prompts de texto definem quem ele é e como deve se comportar. Essa combinação permite que o PersonaPlex mantenha uma persona consistente enquanto responde de forma instantânea e natural.
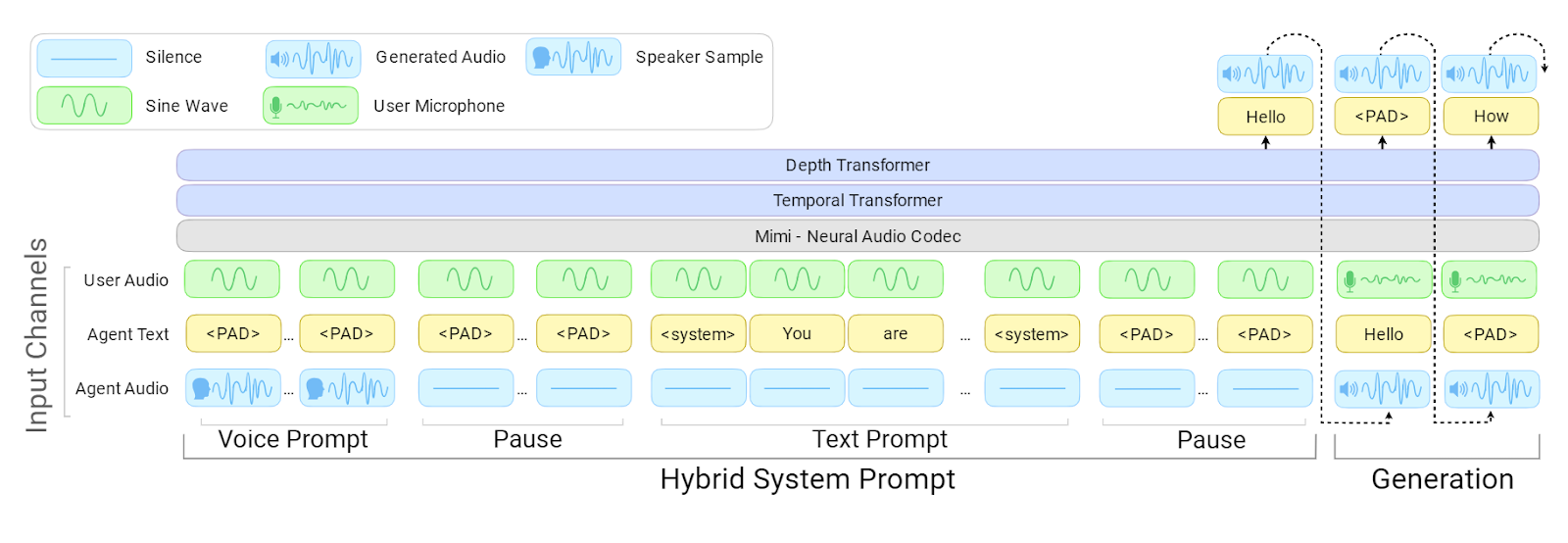
Arquitetura do PersonaPlex | Fonte: NVIDIA PersonaPlex
O PersonaPlex é avaliado com o FullDuplexBench e um benchmark estendido de atendimento ao cliente chamado ServiceDuplexBench.
Ele supera outros sistemas open source e comerciais em dinâmica conversacional, baixa latência, tratamento de interrupções e aderência a tarefas, tanto em cenários de assistente quanto de atendimento.
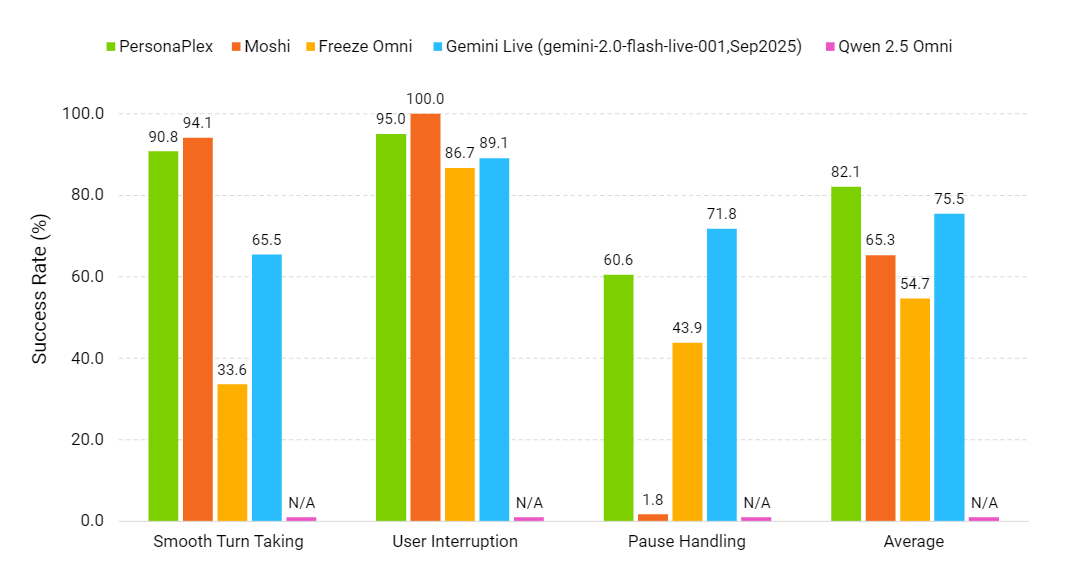
Dinâmica de conversa (quanto maior, melhor) | Fonte: NVIDIA PersonaPlex
No vídeo de demonstração abaixo, dá para ver claramente a pessoa tendo uma conversa fluida com o modelo, trocando brincadeiras e piadas em tempo real.
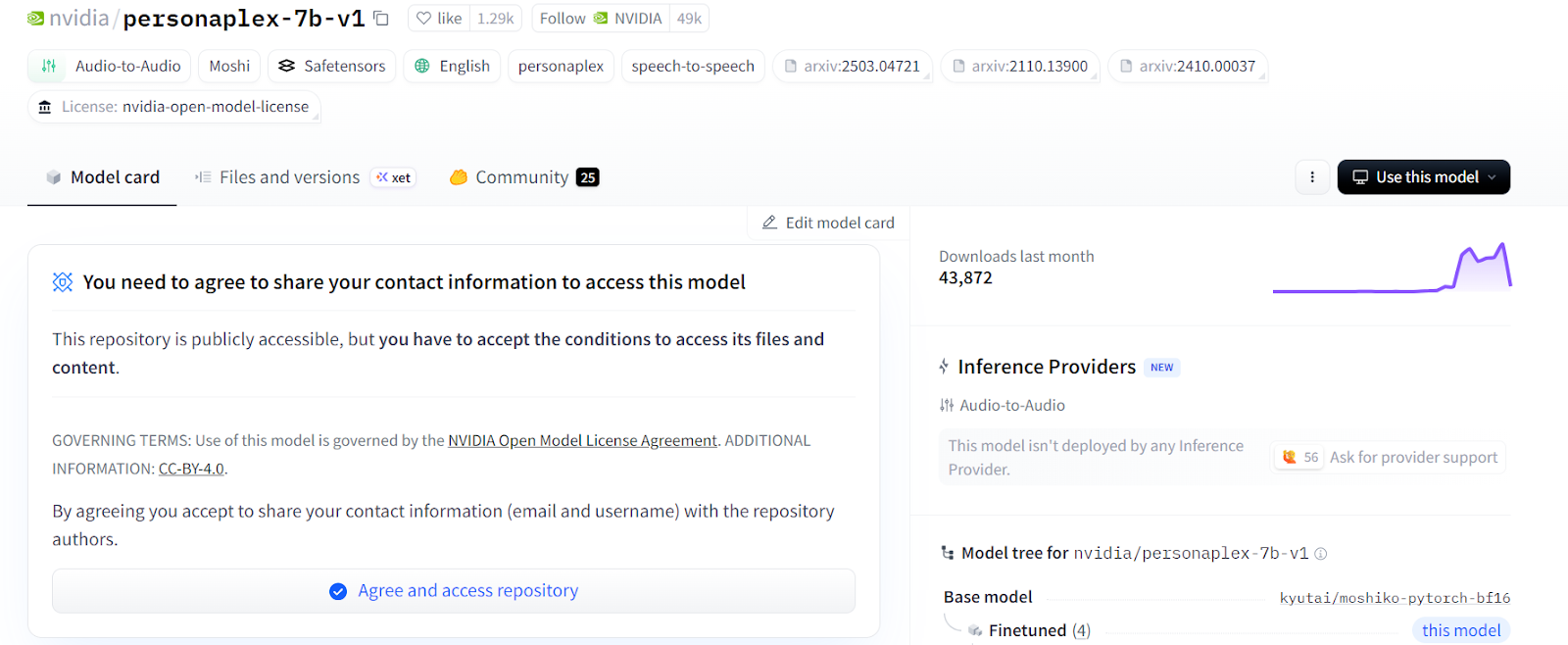
Antes de começar, visite a página do modelo na Hugging Face para nvidia/personaplex-7b-v1 e aceite as condições de uso do modelo.
O PersonaPlex é um modelo com acesso controlado, então você vai precisar de um token de API da Hugging Face. Gere o token na sua conta e deixe-o à mão, pois vamos adicioná-lo às variáveis de ambiente depois para permitir o acesso ao modelo.
Em seguida, acesse o RunPod e inicie um novo pod com GPU A40. Selecione a imagem mais recente do PyTorch e clique em Edit para personalizar o ambiente.
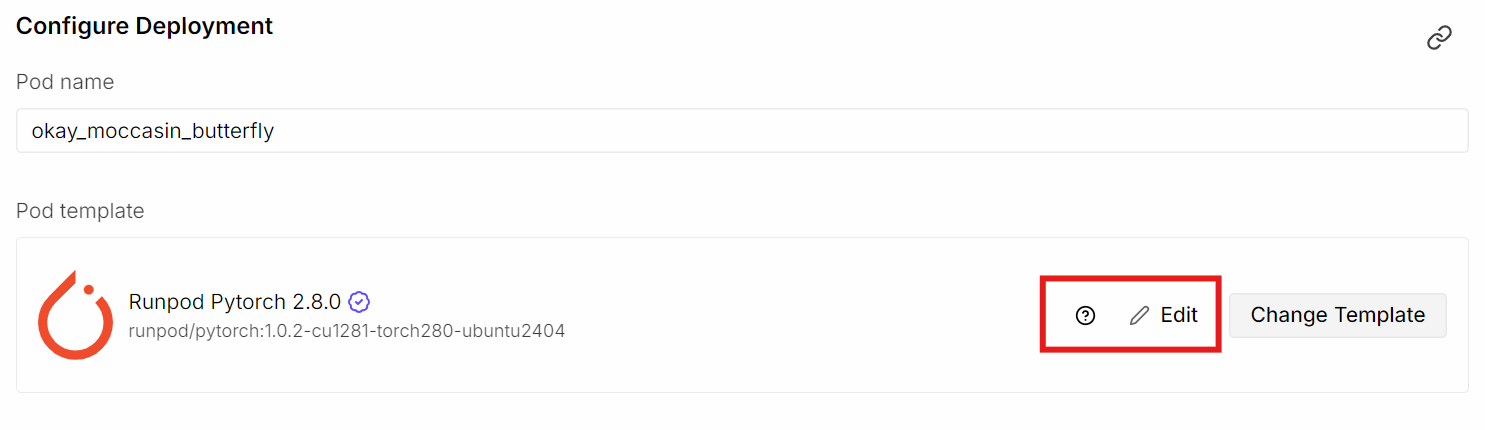
Aumente o tamanho do disco do contêiner para 50 GB, já que o modelo tem cerca de 20 GB e dependências adicionais também serão baixadas. Na seção de portas HTTP expostas, adicione a porta 8998. Em variáveis de ambiente, adicione HF_TOKEN e cole seu token da Hugging Face.
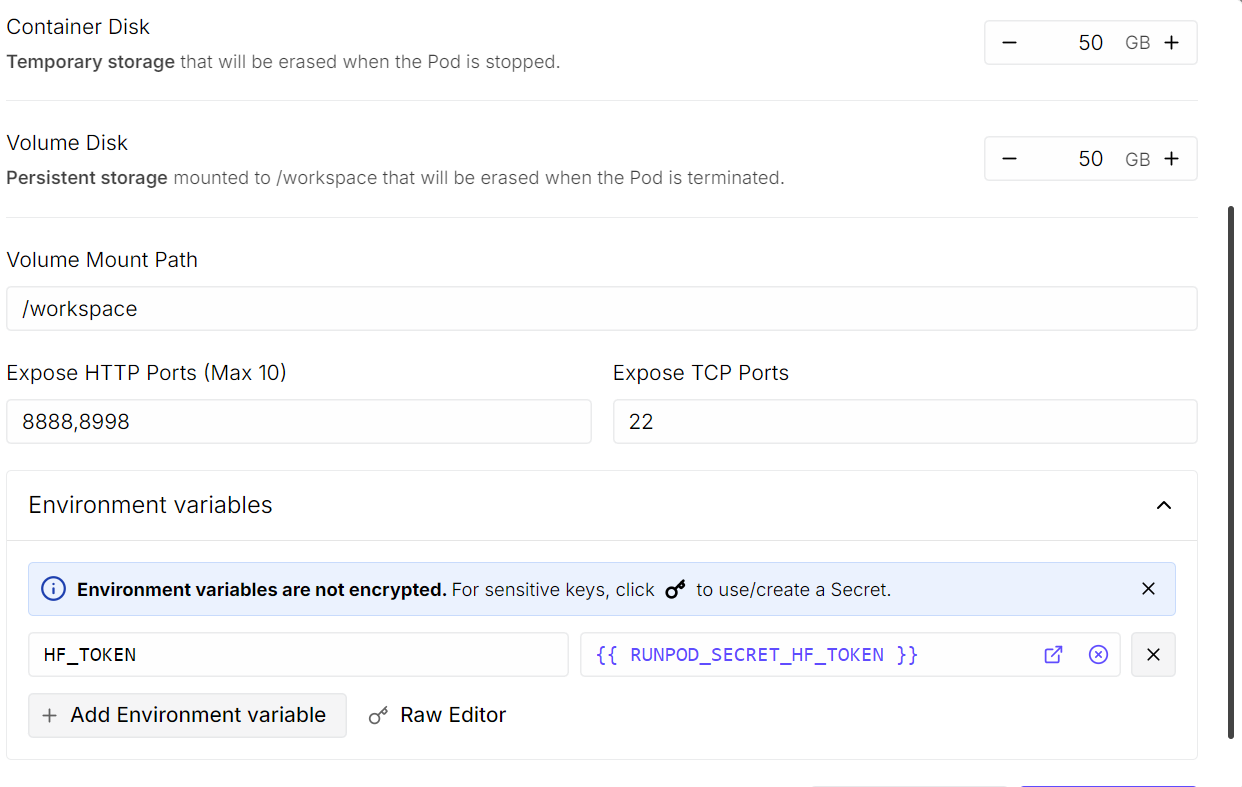
Quando tudo estiver configurado, salve as alterações e faça o deploy do pod.
Depois que o pod iniciar, você verá um link para a instância do JupyterLab. Abra-o e inicie um terminal. Você pode acessar a máquina por SSH ou pelo terminal web, mas usar o terminal do Jupyter é a opção mais simples.
No terminal, instale a biblioteca de desenvolvimento do codec de áudio Opus, necessária para o processamento de áudio:
sudo apt update
sudo apt install libopus-dev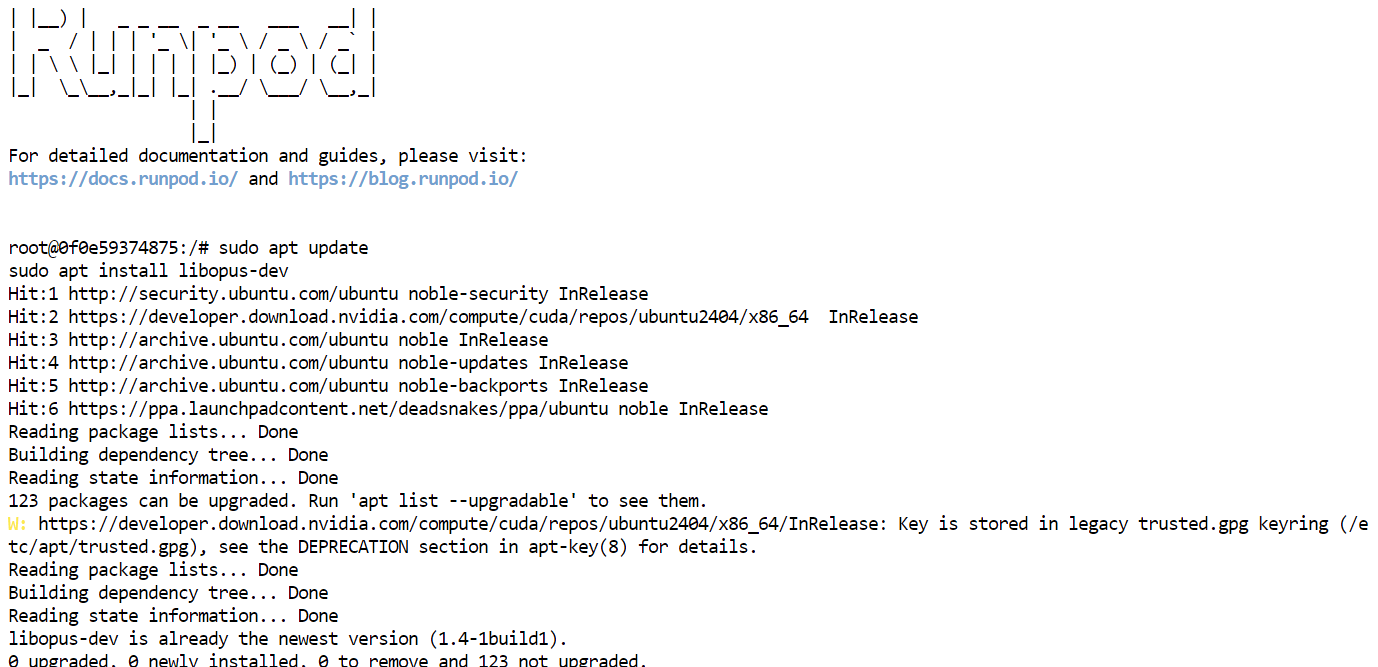
O código do PersonaPlex foi aberto pela NVIDIA e está disponível no GitHub (NVIDIA/personaplex: PersonaPlex code), facilitando explorar, personalizar e rodar localmente.
Instalar a partir do fonte te dá controle total sobre a configuração e garante compatibilidade com as atualizações mais recentes do repositório.
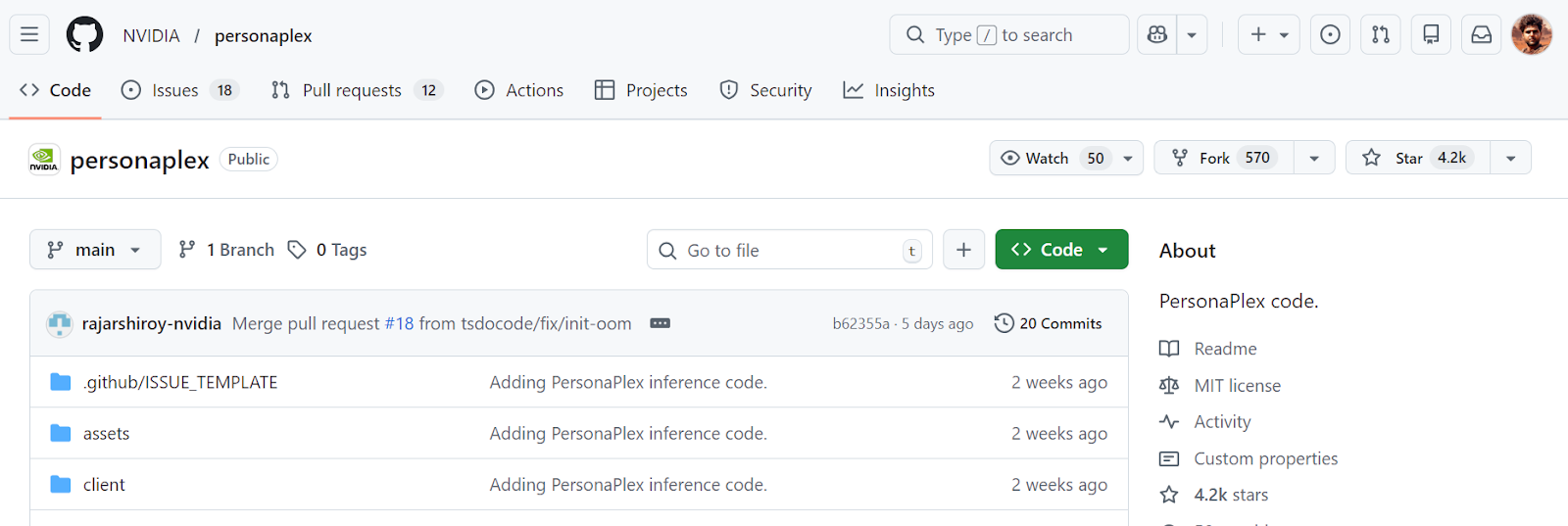
Para começar, clone o repositório do PersonaPlex:
git clone https://github.com/NVIDIA/personaplex.git
cd personaplex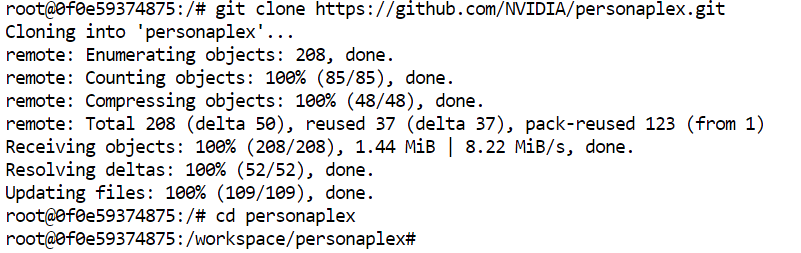
Depois, instale o Moshi, o modelo de fala full-duplex central em que o PersonaPlex é baseado.
O Moshi é responsável por escutar e falar em tempo real, permitindo que o PersonaPlex lide com interrupções, pausas e timing natural de conversa sem depender do pipeline tradicional ASR → LLM → TTS.
Instalá-lo a partir do fonte garante que todos os componentes de áudio, streaming e conversa estejam corretamente configurados para execução local.
pip install moshi/.Com o Moshi instalado, seu ambiente está pronto para iniciar o servidor do PersonaPlex e começar a interagir com o modelo em tempo real.
Com o ambiente e as dependências no lugar, você já pode iniciar o servidor WebUI do PersonaPlex. No terminal, execute o comando abaixo para lançar o servidor Moshi que impulsiona o PersonaPlex:
python -m moshi.server --host 0.0.0.0 --port 8998Na primeira execução, o servidor baixará automaticamente o modelo do PersonaPlex e outros arquivos necessários. Esse passo pode levar alguns minutos, dependendo da sua conexão, já que o modelo é bem grande.
Quando o download terminar, o servidor começará a escutar na porta 8998.

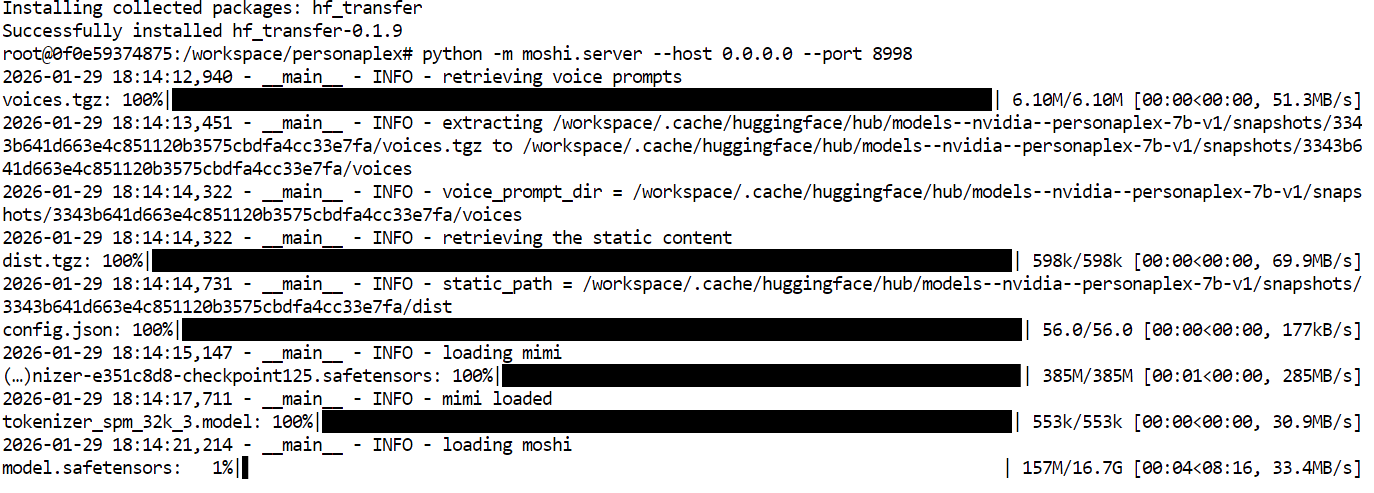
Para acessar a WebUI, volte ao seu painel do RunPod.
Na seção Connect, encontre a porta 8998 exposta e clique no link. Isso abrirá a WebUI do PersonaPlex no seu navegador, onde você pode começar a interagir com o modelo em conversas de voz em tempo real.
A WebUI do PersonaPlex já vem com alguns prompts de exemplo para você começar, e você também pode criar prompts personalizados para definir o papel e o comportamento do assistente.
Você pode selecionar uma voz antes de conectar — isso define como a persona vai soar durante a conversa.
Para este tutorial, o ideal é começar com as configurações padrão para sentir o sistema.
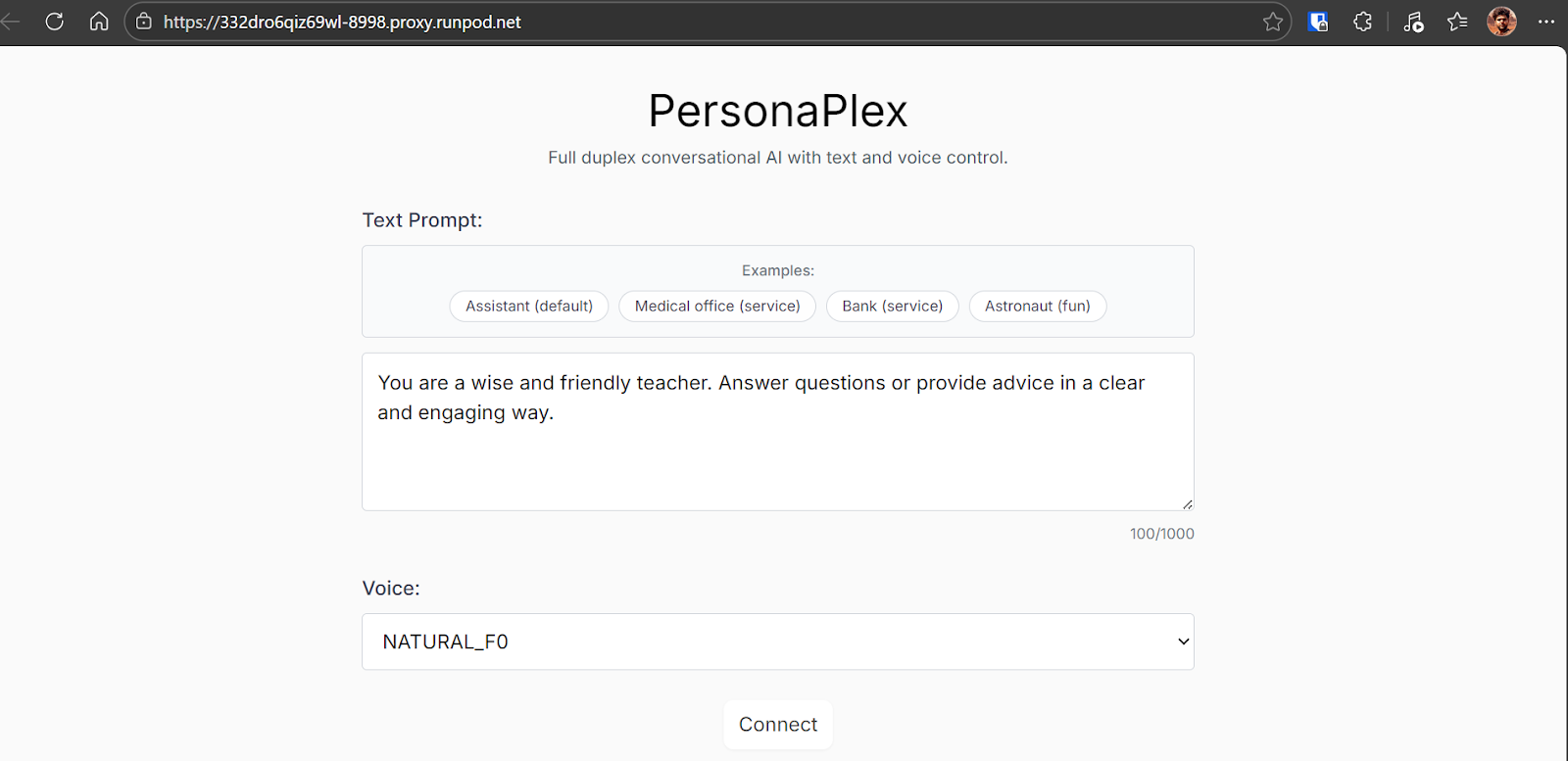
Depois de clicar em Connect, você será levado à sessão interativa. Aqui, dá para falar diretamente com o modelo, ouvir as respostas em tempo real e ver a transcrição ao vivo da conversa enquanto ela acontece.
A experiência é fluida, com timing natural e possibilidade de interromper ou responder rapidamente.
Nos meus testes, a interação soou surpreendentemente natural e envolvente.
Notei alguns engasgos ocasionais — provavelmente por carga do navegador ou do sistema, não do modelo em si. Fora isso, a conversa ficou muito próxima de falar com uma pessoa real.
Quando estiver confortável, experimente diferentes prompts e vozes. O PersonaPlex traz uma ampla variedade de embeddings de voz prontos, incluindo vozes mais naturais para conversa e variações mais expressivas:
Trocar vozes e prompts é uma ótima forma de explorar como o PersonaPlex mantém personalidade, tom e fluidez da conversa em diferentes papéis e estilos de fala.
A WebUI é ótima para conversas em tempo real, mas você também pode rodar o PersonaPlex offline a partir do Python. Isso é útil quando você quer resultados reproduzíveis, testar diferentes prompts rapidamente ou gerar arquivos de áudio para reutilizar em demos e experimentos.
O fluxo offline é simples: você fornece (1) um prompt de voz, (2) um prompt de texto e (3) um arquivo WAV de entrada. O PersonaPlex então gera um áudio de resposta e um arquivo JSON com a transcrição do modelo.
Comece um novo notebook no Jupyter e mude o diretório para o repositório clonado:
%cd personaplexExecute o seguinte em uma nova célula. Isso chama o runner offline e grava tanto o áudio gerado quanto a transcrição em disco:
%%capture
!python -m moshi.offline \
--voice-prompt "NATF2.pt" \
--text-prompt "You are a wise and friendly teacher. Answer questions in a clear, engaging way." \
--input-wav "assets/test/input_assistant.wav" \
--seed 42424242 \
--output-wav "out_teacher.wav" \
--output-text "out_teacher.json"O que cada flag faz:
--voice-prompt seleciona o embedding de voz (aqui, uma voz feminina natural).--text-prompt define o papel e o comportamento do assistente.--input-wav é o áudio gravado do usuário ao qual o modelo vai responder.--seed deixa a saída mais reproduzível entre execuções.--output-wav é a resposta falada gerada.--output-text salva a transcrição em JSON.Quando o comando terminar, você pode tocar o áudio da resposta diretamente:
from IPython.display import Audio
Audio("out_teacher.wav")Você deve ouvir uma resposta clara e natural na voz selecionada, alinhada com a persona definida no seu prompt de texto.

A transcrição em JSON às vezes pode conter artefatos de tokenização, como espaços extras em torno de pontuação ou pedaços de palavras separados. O helper abaixo carrega o JSON e limpa o texto para ficar legível.
import json
import re
with open("out_teacher.json") as f:
data = json.load(f)
def detokenize(tokens):
# 1) drop padding-like tokens
drop = {"PAD", "EPAD", "<pad>", "</s>", "<s>"}
toks = [t for t in tokens if t not in drop]
# 2) join with spaces first
s = " ".join(toks)
# 3) fix spacing around punctuation
s = re.sub(r"\s+([.,!?;:])", r"\1", s)
# 4) fix common split contractions: "it ' s" -> "it's"
s = s.replace(" ' s", "'s").replace(" n't", "n't").replace(" 're", "'re").replace(" 'm", "'m").replace(" 've", "'ve").replace(" 'd", "'d")
# 5) fix stray spaces around apostrophes
s = re.sub(r"\s+'\s+", "'", s)
# 6) fix cases like "for k" -> "fork" and "fl uff" -> "fluff"
# (general rule: merge single-letter fragments if they look like split wordpieces)
s = re.sub(r"\b([A-Za-z])\s+([A-Za-z]{1,3})\b", r"\1\2", s)
# 7) collapse multiple spaces
s = re.sub(r"\s{2,}", " ", s).strip()
return s
clean_text = detokenize(data) # replace with your list variable
clean_textAgora você deve ver uma string de transcrição legível, compatível com o áudio gerado. Se sua saída ainda contiver divisões estranhas (por exemplo, “fl uff” ou “afor k”), isso é normal em algumas execuções e pode ser limpo com regras adicionais — mas o conteúdo principal já deve estar compreensível.
"Hey, let me know if you have any questions.
Hmm, first rinse the rice a couple of times until the water runs clear, that cuts down on starch, then use apot with a tight fitting lid, bring to a boil,
give it a quick stir, then turn the heat down low and cover, let it s immer without lifting it, and when it'done fl uff it with afor k, that usually
You could to ss the hot rice with a nice handful of chopped fresh herbs like basil or par sley, or you could sprinkle a little g rated cheese,
a squeeze of lemon or lime, adr izzle of olive oil, some chopped fresh herbs, or even some to ast ed nuts, that adds color and flavor."Testar o PersonaPlex me surpreendeu de verdade. Desde a primeira interação, a sensação foi menos de estar “brincando com um modelo” e mais de ter uma conversa real. Poder interromper naturalmente, obter respostas instantâneas e manter uma personalidade consistente ao longo do bate-papo o coloca bem à frente da maioria dos sistemas de voz que já experimentei. Rodar tudo localmente torna a experiência ainda mais impressionante, sem atraso perceptível ou perda de controle.
Ainda há alguns pontos a melhorar. Notei engasgos ocasionais e, quando a conversa avança, nem sempre ele retoma um tópico anterior com tanta fluidez.
Ele também ainda não entende totalmente sotaques não nativos de inglês, o que pode levar a nomes mal pronunciados ou transcrições imperfeitas. Isso parece mais caso de borda do que um problema estrutural — e tenho confiança de que vai evoluir rápido.
Tenho certeza de que, no futuro, esses pontos serão resolvidos e teremos uma IA conversacional ainda melhor, totalmente local e em tempo real, combinando o raciocínio do GPT-5.2 com a qualidade de voz do ElevenLabs.
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Dr Ana Rojo-Echeburúa
9 min
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Matt Crabtree


