
Track
Data Engineer in Python
40 hr
The data architecture landscape is evolving, driven by the increasing use of cloud technologies and the adoption of the modern data stack. As a result, ELT processes are becoming more widely used. But what exactly is involved in this process?
In this article, we will explore ELT and its role in advanced data architecture.
ELT stands for Extract, Load, Transform. It is a data integration process that involves extracting data from various sources, loading it into a data storage system, and transforming it into a format that can be easily analyzed.
The ELT process is largely used in modern data stack architecture, where data is stored, transformed, and analyzed in a data lake or warehouse.
As its name suggests, ELT involves three main steps: Extract, Load, and Transform. Let's examine each step in more detail.
The first step in the ELT process is extracting data from various sources such as databases, files, APIs, or web services. This can be done using tools like ELT software or custom scripts written by developers.
Some examples of data extraction platforms include Airbyte and Fivetran. For writing custom scripts, Apache Spark and Python are widely used.
The extracted data can be structured, semi-structured, or unstructured and may come from different types of systems, such as relational databases, NoSQL databases, or cloud storage.
Once the data has been extracted, it is loaded into a centralized data storage system like a data lake or a data warehouse. This step involves organizing and storing the extracted data in its raw format without any transformation.
Data engineers are typically involved in this step, where they load the data to platforms like:
These data platforms allow for the fast loading of large amounts of data and provide a single source of truth for all the different types of data collected from various sources.
The final step in the ELT process is transforming the raw data into a format optimized for analysis and reporting. This involves cleaning, filtering, aggregating, and structuring the data in a way suitable for business intelligence and analytics tools to work with.
Data engineers or data scientists are usually responsible for this step, and they may use tools such as:
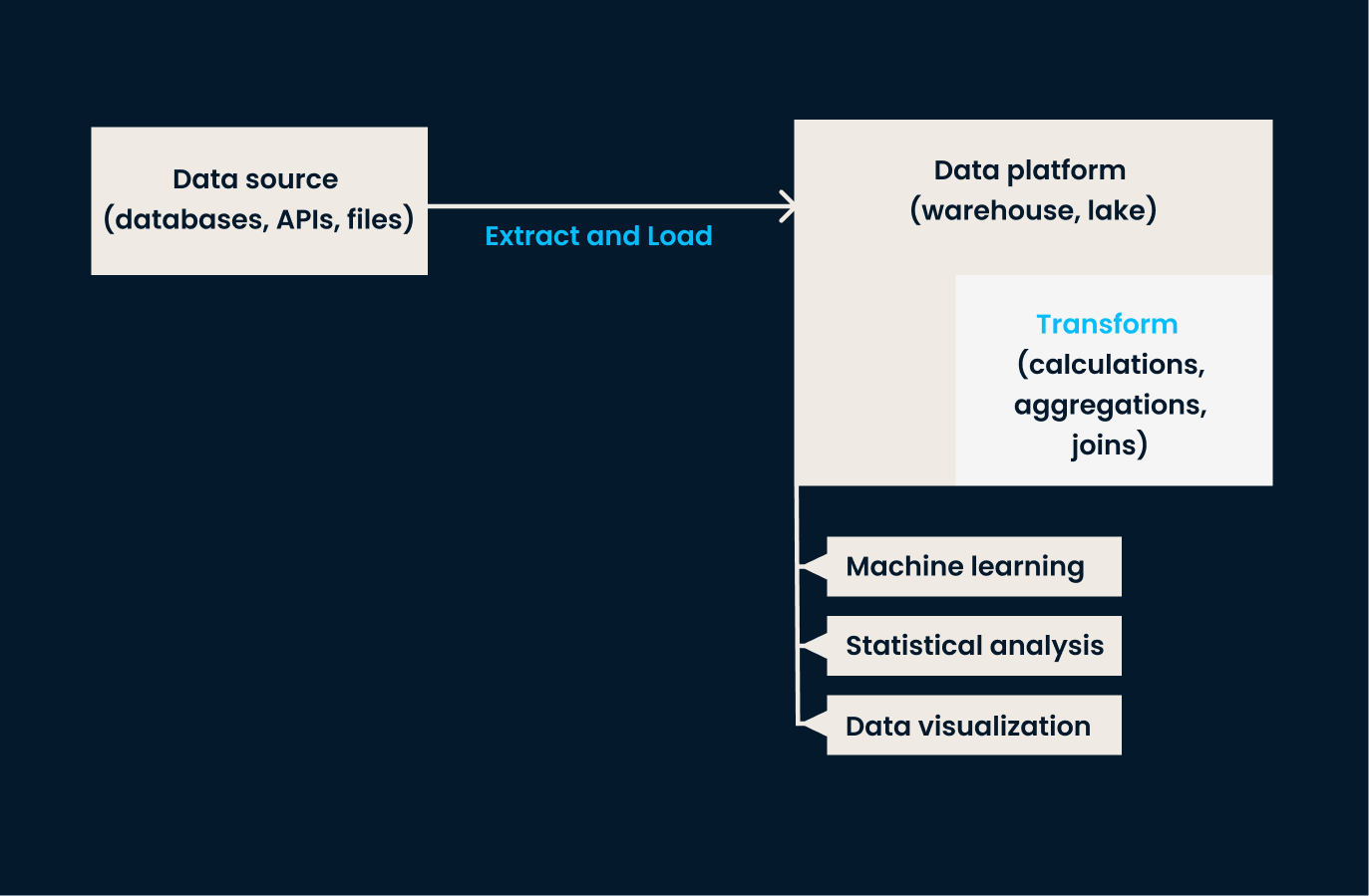
ELT data pipeline: The extract and loading phases happen before any transformation is applied to the data. The transformation step is performed within the data platform.
Data transformation is done within the data warehouse or data lake, which allows for easier handling of large volumes of data. With modern cloud technologies, this process can be done in near real-time, providing organizations access to fresh and accurate data for analysis.
Want to learn more about using Python for ELT? The ETL and ELT in Python course may be exactly what you need.
ELT comes with many benefits, and here are some notable ones:
Let's now compare the differences between ELT and ETL.
As previously mentioned, ELT is a newer approach to data processing where data is first loaded into a central repository, allowing transformations to occur post-loading.
Conversely, ETL (Extract, Transform, Load) is a traditional methodology in which data is transformed before being loaded into the destination system. These fundamental differences impact not only the process but also the speed, costs, and security.
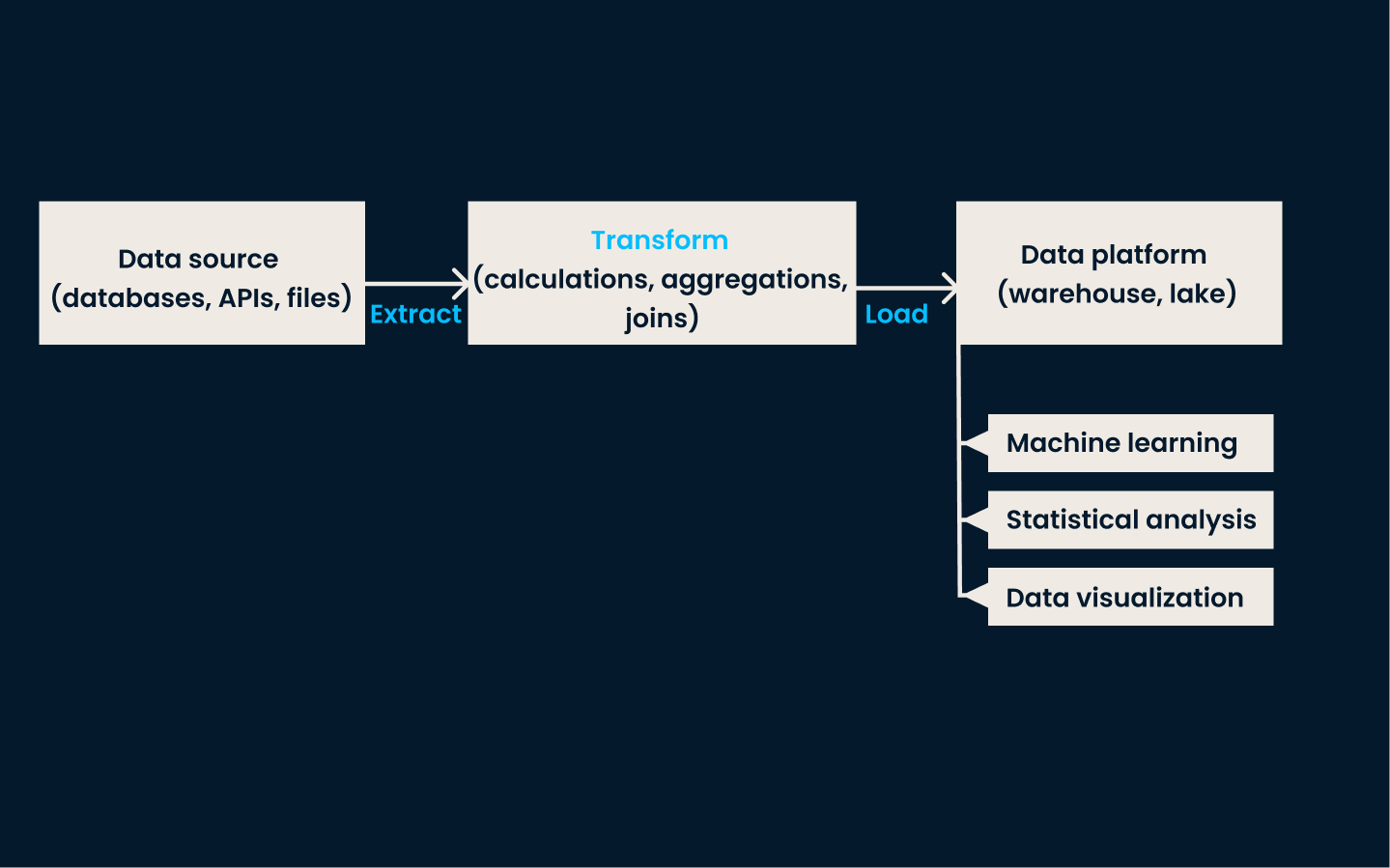
ETL pipeline: The transformation step occurs before loading the data to a destination platform. Typically, transformation occurs on a separate server rather than in the data platform itself.
ELT follows a 'load-first, transform-later' approach where data is loaded into a storage system in its raw form and then transformed for analysis.
On the other hand, ETL follows an 'extract-transform-load' approach where data is extracted from various sources, then transformed, and finally loaded into a data warehouse.
The ELT approach is known for its faster data processing speed, as it eliminates the need for an intermediate staging area. This allows for real-time or near-real-time data analysis.
Conversely, ETL can often take longer due to the multiple steps involved in transforming and loading the data.
Additionally, ELT eliminates the need for expensive ETL software, as transformations can be done using SQL queries or other open-source tools.
In contrast, traditional ETL processes tend to fit better in on-premises infrastructure, where data sources are limited, and hardware resources are less scalable than in cloud-based environments. On-premises infrastructure often has higher costs than cloud infrastructure.
Finally, ELT allows data encryption and data masking of personally identifiable information (PII) during the load process since it is done in a secure central repository.
ETL processes must ensure data security throughout the extraction and transformation process. However, that proves difficult, given that the data has to move to additional staging storage and is often processed in separate servers.
With its faster data processing speed and cloud computing analytics, the ELT process has seen some use cases where it shines compared to ETL.
Here are some common uses of the ELT process:
There are various tools and technologies available for organizations to implement ELT processes. These include:
In the loading step of the ELT process, data lakes and data warehouses are essential to providing a centralized data storage space within a company.
Here are the most popular cloud data platforms:
Many organizations also leverage open-source tools for their ELT processes for their cost-effectiveness.
These tools can help with different stages of the ELT process:
Open-source tools are an excellent match for ELT processes because they provide flexibility, developer support, and many integration options.
Developers can also choose to use scripts built using programming languages for added customizability. These tend to involve using packages and libraries to process and transform data.
Some common programming languages used for these scripts include:
In conclusion, ELT is a new and emerging trend in data processing that offers many advantages over traditional ETL methods. It allows faster and more efficient data transformation and provides greater flexibility and scalability.
If you’re thinking about learning more about ELT or other data engineering concepts, you might like our Data Engineer Certification or our Data Engineer in Python Career Track.
Learn more about data engineering and data processing with these courses!
Track
Course
Course
blog
Julia Winn
6 min
blog
Oluseye Jeremiah
6 min
blog
Vahab Khademi
11 min
blog
DataCamp Team
12 min
Tutorial
Jake Roach
code-along
Jake Roach

