Course
Introduction to Python
4 hr
6.9M
An important set of metrics in text mining relates to the frequency of words (or any token) in a certain corpus of text documents. However, you can also use an additional set of metrics in cases where each document has an associated numeric value describing a certain attribute of the document.
Some examples:
In this tutorial,
collections module's defaultdict data structure for the heavy lifting, as well as pandas DataFrames to manage the final output.Let's assume that you have two tweets and that their content and number of impressions (views) are as follows:
| Tweet Text | Views |
|---|---|
| spain | 800 |
| france | 200 |
It is simple to do the basic analysis and find out that your words are split 50:50 between 'france' and 'spain'. In many cases, this is all you have, and you can only measure the absolute frequency of words, and try to infer certain relationships. In this case, you have some data about each of the documents.
The weighed frequency here, is clearly different, and the split is 80:20. In other words, although 'spain' and 'france' both appeared once each in your tweets, from your readers' perspective, the former appeared 800 times, while the latter appeared 200 times. There's a big difference!
defaultdictNow consider this slightly more involved example for a similar set of documents:
| Document | Views |
|---|---|
| france | 200 |
| spain | 180 |
| spain beaches | 170 |
| france beaches | 160 |
| spain best beaches | 160 |
You now loop through the documents, split them into words, and count the occurrences of each of the words:
from collections import defaultdict
import pandas as pd
text_list = ['france', 'spain', 'spain beaches', 'france beaches', 'spain best beaches']
word_freq = defaultdict(int)
for text in text_list:
for word in text.split():
word_freq[word] += 1
pd.DataFrame.from_dict(word_freq, orient='index') \
.sort_values(0, ascending=False) \
.rename(columns={0: 'abs_freq'})| abs_freq | |
|---|---|
| spain | 3 |
| beaches | 3 |
| france | 2 |
| best | 1 |
In the loop above, the first line loops through text_list one by one. The second line (within each document) loops through the words of each item, split by the space character (which could have been any other character ('-', ',', '_', etc.)).
When you try to assign a value to word_freq[word] there are two possible scenarios:
word exists: in which case the assignment is done (adding one)word is not in word_freq, in this case defaultdict calls the default function that it was assigned to when it was first defined, which is int in this case.When int is called it returns zero. Now the key exists, its value is zero, and it is ready to get assigned an additional 1 to its value.
Although the top word was 'france' in the first table, after counting all the words within each document we can see that 'spain' and 'beaches' are tied for the first position. This is important in uncovering hidden trends, especially when the list of documents you are dealing with, is in the tens, or hundreds, of thousands.
Now that you have counted the occurences of each word in the corpus of documents, you want to see the weighted frequency. That is, you want to see how many times the words appeared to your readers, compared to how many times you used them.
In the first table, the absolute frequency of the words was split evenly between 'spain' and 'france', but 'spain' had clearly much more weight, because its value was 800, versus 200 or 'france'.
But what would be the weighted word frequency for the second, slightly more complex, table?
Let's find out!
You can re-use some of the code that you used above, but with some additions:
# default value is now a list with two ints
word_freq = defaultdict(lambda: [0, 0])
# the `views` column you had in the first DataFrame
num_list = [200, 180, 170, 160, 160]
# looping is now over both the text and the numbers
for text, num in zip(text_list, num_list):
for word in text.split():
# same as before
word_freq[word][0] += 1
# new line, incrementing the numeric value for each word
word_freq[word][1] += num
columns = {0: 'abs_freq', 1: 'wtd_freq'}
abs_wtd_df = pd.DataFrame.from_dict(word_freq, orient='index') \
.rename(columns=columns) \
.sort_values('wtd_freq', ascending=False) \
.assign(rel_value=lambda df: df['wtd_freq'] / df['abs_freq']) \
.round()
abs_wtd_df.style.background_gradient(low=0, high=.7, subset=['rel_value'])| abs_freq | wtd_freq | rel_value | |
|---|---|---|---|
| spain | 3 | 510 | 170 |
| beaches | 3 | 490 | 163 |
| france | 2 | 360 | 180 |
| best | 1 | 160 | 160 |
Some observations:
rel_value is a simple division to get the value per occurrence of each word.rel_value, you also see that, even though 'france' is quite low on the wtd_freq metric, there seems to be potential in it, because the value per occurence is high. This might hint at increasing your content coverage of 'france' for example.You might also like to add some other metrics that show the percentages and cumulative percenatages of each type of frequency so that you can get a better perspective on how many words form the bulk of the total, if any:
abs_wtd_df.insert(1, 'abs_perc', value=abs_wtd_df['abs_freq'] / abs_wtd_df['abs_freq'].sum())
abs_wtd_df.insert(2, 'abs_perc_cum', abs_wtd_df['abs_perc'].cumsum())
abs_wtd_df.insert(4, 'wtd_freq_perc', abs_wtd_df['wtd_freq'] / abs_wtd_df['wtd_freq'].sum())
abs_wtd_df.insert(5, 'wtd_freq_perc_cum', abs_wtd_df['wtd_freq_perc'].cumsum())
abs_wtd_df.style.background_gradient(low=0, high=0.8)| abs_freq | abs_perc | abs_perc_cum | wtd_freq | wtd_freq_perc | wtd_freq_perc_cum | rel_value | |
|---|---|---|---|---|---|---|---|
| spain | 3 | 0.333333 | 0.333333 | 510 | 0.335526 | 0.335526 | 170 |
| beaches | 3 | 0.333333 | 0.666667 | 490 | 0.322368 | 0.657895 | 163 |
| france | 2 | 0.222222 | 0.888889 | 360 | 0.236842 | 0.894737 | 180 |
| best | 1 | 0.111111 | 1 | 160 | 0.105263 | 1 | 160 |
More can be analyzed, and with more data you would typically get more surprises.
So how might this look in a real-world setting with some real data?
You will take a look at movie titles, see which words are most used in the titles -which is the absolute frequency-, and which words are associated with the most revenue, or the weighted frequency.
Boxoffice Mojo has a list of more than 15,000 movies, together with their associated gross revenue and ranks. Start by scraping the data using requests and BeautifulSoup - You can already explore the Boxoffice Mojo here if you'd like:
import requests
from bs4 import BeautifulSoup final_list = []
for i in range(1, 156):
if not i%10:
print(i)
page = 'http://www.boxofficemojo.com/alltime/domestic.htm?page=' + str(i) + '&p=.htm'
resp = requests.get(page)
soup = BeautifulSoup(resp.text, 'lxml')
# trial and error to get the exact positions
table_data = [x.text for x in soup.select('tr td')[11:511]]
# put every 5 values in a row
temp_list = [table_data[i:i+5] for i in range(0, len(table_data[:-4]), 5)]
for temp in temp_list:
final_list.append(temp)10
20
30
40
50
60
70
80
90
100
110
120
130
140
150
boxoffice_df = pd.DataFrame.from_records(final_list)
boxoffice_df.head(10)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | Star Wars: The Force Awakens | BV | $936,662,225 | 2015 |
| 1 | 2 | Avatar | Fox | $760,507,625 | 2009^ |
| 2 | 3 | Black Panther | BV | $681,084,109 | 2018 |
| 3 | 4 | Titanic | Par. | $659,363,944 | 1997^ |
| 4 | 5 | Jurassic World | Uni. | $652,270,625 | 2015 |
| 5 | 6 | Marvel's The Avengers | BV | $623,357,910 | 2012 |
| 6 | 7 | Star Wars: The Last Jedi | BV | $620,181,382 | 2017 |
| 7 | 8 | The Dark Knight | WB | $534,858,444 | 2008^ |
| 8 | 9 | Rogue One: A Star Wars Story | BV | $532,177,324 | 2016 |
| 9 | 10 | Beauty and the Beast (2017) | BV | $504,014,165 | 2017 |
boxoffice_df.tail(15)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 15485 | 15486 | The Dark Hours | N/A | $423 | 2005 |
| 15486 | 15487 | 2:22 | Magn. | $422 | 2017 |
| 15487 | 15488 | State Park | Atl | $421 | 1988 |
| 15488 | 15489 | The Magician (2010) | Reg. | $406 | 2010 |
| 15489 | 15490 | Skinless | PPF | $400 | 2014 |
| 15490 | 15491 | Cinemanovels | Mont. | $398 | 2014 |
| 15491 | 15492 | Hannah: Buddhism's Untold Journey | KL | $396 | 2016 |
| 15492 | 15493 | Apartment 143 | Magn. | $383 | 2012 |
| 15493 | 15494 | The Marsh | All. | $336 | 2007 |
| 15494 | 15495 | The Chambermaid | FM | $315 | 2015 |
| 15495 | 15496 | News From Planet Mars | KL | $310 | 2016 |
| 15496 | 15497 | Trojan War | WB | $309 | 1997 |
| 15497 | 15498 | Lou! Journal infime | Distrib. | $287 | 2015 |
| 15498 | 15499 | Intervention | All. | $279 | 2007 |
| 15499 | 15500 | Playback | Magn. | $264 | 2012 |
You will see that some numeric values have some special characters, ($, , , and ^), and some values are actually N/A. So you need to change those:
na_year_idx = [i for i, x in enumerate(final_list) if x[4] == 'n/a'] # get the indexes of the 'n/a' values
new_years = [1998, 1999, 1960, 1973] # got them by checking online
print(*[(i, x) for i, x in enumerate(final_list) if i in na_year_idx], sep='\n')
print('new year values:', new_years)
(8003, ['8004', 'Warner Bros. 75th Anniversary Film Festival', 'WB', '$741,855', 'n/a'])
(8148, ['8149', 'Hum Aapke Dil Mein Rahte Hain', 'Eros', '$668,678', 'n/a'])
(8197, ['8198', 'Purple Moon (Re-issue)', 'Mira.', '$640,945', 'n/a'])
(10469, ['10470', 'Amarcord', 'Jan.', '$125,493', 'n/a'])
new year values: [1998, 1999, 1960, 1973]
for na_year, new_year in zip(na_year_idx, new_years):
final_list[na_year][4] = new_year
print(final_list[na_year], new_year)
['8004', 'Warner Bros. 75th Anniversary Film Festival', 'WB', '$741,855', 1998] 1998
['8149', 'Hum Aapke Dil Mein Rahte Hain', 'Eros', '$668,678', 1999] 1999
['8198', 'Purple Moon (Re-issue)', 'Mira.', '$640,945', 1960] 1960
['10470', 'Amarcord', 'Jan.', '$125,493', 1973] 1973
Now you turn the list into a pandas DataFrame by naming the columns with the appropriate names, and converting to the data types that you want.
import re
regex = '|'.join(['\$', ',', '\^'])
columns = ['rank', 'title', 'studio', 'lifetime_gross', 'year']
boxoffice_df = pd.DataFrame({
'rank': [int(x[0]) for x in final_list], # convert ranks to integers
'title': [x[1] for x in final_list], # get titles as is
'studio': [x[2] for x in final_list], # get studio names as is
'lifetime_gross': [int(re.sub(regex, '', x[3])) for x in final_list], # remove special characters and convert to integer
'year': [int(re.sub(regex, '', str(x[4]))) for x in final_list], # remove special characters and convert to integer
})
print('rows:', boxoffice_df.shape[0])
print('columns:', boxoffice_df.shape[1])
print('\ndata types:')
print(boxoffice_df.dtypes)
boxoffice_df.head(15)rows: 15500
columns: 5
data types:
lifetime_gross int64
rank int64
studio object
title object
year int64
dtype: object
| lifetime_gross | rank | studio | title | year | |
|---|---|---|---|---|---|
| 0 | 936662225 | 1 | BV | Star Wars: The Force Awakens | 2015 |
| 1 | 760507625 | 2 | Fox | Avatar | 2009 |
| 2 | 681084109 | 3 | BV | Black Panther | 2018 |
| 3 | 659363944 | 4 | Par. | Titanic | 1997 |
| 4 | 652270625 | 5 | Uni. | Jurassic World | 2015 |
| 5 | 623357910 | 6 | BV | Marvel's The Avengers | 2012 |
| 6 | 620181382 | 7 | BV | Star Wars: The Last Jedi | 2017 |
| 7 | 534858444 | 8 | WB | The Dark Knight | 2008 |
| 8 | 532177324 | 9 | BV | Rogue One: A Star Wars Story | 2016 |
| 9 | 504014165 | 10 | BV | Beauty and the Beast (2017) | 2017 |
| 10 | 486295561 | 11 | BV | Finding Dory | 2016 |
| 11 | 474544677 | 12 | Fox | Star Wars: Episode I - The Phantom Menace | 1999 |
| 12 | 460998007 | 13 | Fox | Star Wars | 1977 |
| 13 | 459005868 | 14 | BV | Avengers: Age of Ultron | 2015 |
| 14 | 448139099 | 15 | WB | The Dark Knight Rises | 2012 |
The word 'star' is one of the top, as it appears in five of the top fifteen movies, and you also know that the Star Wars series has even more movies, several of them in the top as well.
Let's now utilize the code you developed and see how it works on this data set. There's nothing new in the code below, you simply put it all in one function:
def word_frequency(text_list, num_list, sep=None):
word_freq = defaultdict(lambda: [0, 0])
for text, num in zip(text_list, num_list):
for word in text.split(sep=sep):
word_freq[word][0] += 1
word_freq[word][1] += num
columns = {0: 'abs_freq', 1: 'wtd_freq'}
abs_wtd_df = (pd.DataFrame.from_dict(word_freq, orient='index')
.rename(columns=columns )
.sort_values('wtd_freq', ascending=False)
.assign(rel_value=lambda df: df['wtd_freq'] / df['abs_freq']).round())
abs_wtd_df.insert(1, 'abs_perc', value=abs_wtd_df['abs_freq'] / abs_wtd_df['abs_freq'].sum())
abs_wtd_df.insert(2, 'abs_perc_cum', abs_wtd_df['abs_perc'].cumsum())
abs_wtd_df.insert(4, 'wtd_freq_perc', abs_wtd_df['wtd_freq'] / abs_wtd_df['wtd_freq'].sum())
abs_wtd_df.insert(5, 'wtd_freq_perc_cum', abs_wtd_df['wtd_freq_perc'].cumsum())
return abs_wtd_df
word_frequency(boxoffice_df['title'], boxoffice_df['lifetime_gross']).head()| abs_freq | abs_perc | abs_perc_cum | wtd_freq | wtd_freq_perc | wtd_freq_perc_cum | rel_value | |
|---|---|---|---|---|---|---|---|
| The | 3055 | 0.068747 | 0.068747 | 67518342498 | 0.081167 | 0.081167 | 22100930.0 |
| the | 1310 | 0.029479 | 0.098227 | 32973100860 | 0.039639 | 0.120806 | 25170306.0 |
| of | 1399 | 0.031482 | 0.129709 | 30180592467 | 0.036282 | 0.157087 | 21572975.0 |
| and | 545 | 0.012264 | 0.141973 | 12188113847 | 0.014652 | 0.171739 | 22363512.0 |
| 2 | 158 | 0.003556 | 0.145529 | 9032673058 | 0.010859 | 0.182598 | 57168817.0 |
Unsurprisingly, the 'stop words' are the top ones, which is pretty much the same for most collections of documents. You also have them duplicated, where some are capitalized and some are not. So you have two clear things to take care of:
Here is a simple update to the function (new rm_words parameter, as well as lines 6,7, and 8):
# words will be expanded
def word_frequency(text_list, num_list, sep=None, rm_words=('the', 'and', 'a')):
word_freq = defaultdict(lambda: [0, 0])
for text, num in zip(text_list, num_list):
for word in text.split(sep=sep):
# This should take care of ignoring the word if it's in the stop words
if word.lower() in rm_words:
continue
# .lower() makes sure we are not duplicating words
word_freq[word.lower()][0] += 1
word_freq[word.lower()][1] += num
columns = {0: 'abs_freq', 1: 'wtd_freq'}
abs_wtd_df = (pd.DataFrame.from_dict(word_freq, orient='index')
.rename(columns=columns )
.sort_values('wtd_freq', ascending=False)
.assign(rel_value=lambda df: df['wtd_freq'] / df['abs_freq']).round())
abs_wtd_df.insert(1, 'abs_perc', value=abs_wtd_df['abs_freq'] / abs_wtd_df['abs_freq'].sum())
abs_wtd_df.insert(2, 'abs_perc_cum', abs_wtd_df['abs_perc'].cumsum())
abs_wtd_df.insert(4, 'wtd_freq_perc', abs_wtd_df['wtd_freq'] / abs_wtd_df['wtd_freq'].sum())
abs_wtd_df.insert(5, 'wtd_freq_perc_cum', abs_wtd_df['wtd_freq_perc'].cumsum())
abs_wtd_df = abs_wtd_df.reset_index().rename(columns={'index': 'word'})
return abs_wtd_dffrom collections import defaultdict
word_freq_df = word_frequency(boxoffice_df['title'],
boxoffice_df['lifetime_gross'],
rm_words=['of','in', 'to', 'and', 'a', 'the',
'for', 'on', '&', 'is', 'at', 'it',
'from', 'with'])
word_freq_df.head(15).style.bar(['abs_freq', 'wtd_freq', 'rel_value'],
color='#60DDFF') # E6E9EB| word | abs_freq | abs_perc | abs_perc_cum | wtd_freq | wtd_freq_perc | wtd_freq_perc_cum | rel_value | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 158 | 0.00443945 | 0.00443945 | 9032673058 | 0.0137634 | 0.0137634 | 5.71688e+07 |
| 1 | star | 45 | 0.0012644 | 0.00570385 | 5374658819 | 0.00818953 | 0.0219529 | 1.19437e+08 |
| 2 | man | 195 | 0.00547907 | 0.0111829 | 3967037854 | 0.0060447 | 0.0279976 | 2.03438e+07 |
| 3 | part | 41 | 0.00115201 | 0.0123349 | 3262579777 | 0.00497129 | 0.0329689 | 7.95751e+07 |
| 4 | movie | 117 | 0.00328744 | 0.0156224 | 3216050557 | 0.00490039 | 0.0378693 | 2.74876e+07 |
| 5 | 3 | 63 | 0.00177016 | 0.0173925 | 3197591193 | 0.00487227 | 0.0427415 | 5.07554e+07 |
| 6 | ii | 67 | 0.00188255 | 0.0192751 | 3077712883 | 0.0046896 | 0.0474311 | 4.5936e+07 |
| 7 | wars: | 6 | 0.000168587 | 0.0194437 | 2757497155 | 0.00420168 | 0.0516328 | 4.59583e+08 |
| 8 | last | 133 | 0.003737 | 0.0231807 | 2670229651 | 0.00406871 | 0.0557015 | 2.00769e+07 |
| 9 | harry | 27 | 0.00075864 | 0.0239393 | 2611329714 | 0.00397896 | 0.0596805 | 9.67159e+07 |
| 10 | me | 140 | 0.00393369 | 0.027873 | 2459330128 | 0.00374736 | 0.0634279 | 1.75666e+07 |
| 11 | potter | 10 | 0.000280978 | 0.028154 | 2394811427 | 0.00364905 | 0.0670769 | 2.39481e+08 |
| 12 | black | 71 | 0.00199494 | 0.0301489 | 2372306467 | 0.00361476 | 0.0706917 | 3.34128e+07 |
| 13 | - | 49 | 0.00137679 | 0.0315257 | 2339484878 | 0.00356474 | 0.0742564 | 4.77446e+07 |
| 14 | story | 107 | 0.00300646 | 0.0345322 | 2231437526 | 0.00340011 | 0.0776565 | 2.08546e+07 |
Let's take a look at the same DataFrame sorted based on abs_freq:
(word_freq_df.sort_values('abs_freq', ascending=False)
.head(15)
.style.bar(['abs_freq', 'wtd_freq', 'rel_value'],
color='#60DDFF'))
| word | abs_freq | abs_perc | abs_perc_cum | wtd_freq | wtd_freq_perc | wtd_freq_perc_cum | rel_value | |
|---|---|---|---|---|---|---|---|---|
| 26 | love | 211 | 0.00592863 | 0.069542 | 1604206885 | 0.00244438 | 0.111399 | 7.60288e+06 |
| 2 | man | 195 | 0.00547907 | 0.0111829 | 3967037854 | 0.0060447 | 0.0279976 | 2.03438e+07 |
| 24 | my | 191 | 0.00536668 | 0.0618994 | 1629540498 | 0.00248298 | 0.106478 | 8.53163e+06 |
| 15 | i | 168 | 0.00472043 | 0.0392526 | 2203439786 | 0.00335745 | 0.081014 | 1.31157e+07 |
| 0 | 2 | 158 | 0.00443945 | 0.00443945 | 9032673058 | 0.0137634 | 0.0137634 | 5.71688e+07 |
| 10 | me | 140 | 0.00393369 | 0.027873 | 2459330128 | 0.00374736 | 0.0634279 | 1.75666e+07 |
| 31 | life | 134 | 0.0037651 | 0.0764822 | 1534647732 | 0.00233839 | 0.123297 | 1.14526e+07 |
| 8 | last | 133 | 0.003737 | 0.0231807 | 2670229651 | 0.00406871 | 0.0557015 | 2.00769e+07 |
| 23 | you | 126 | 0.00354032 | 0.0565327 | 1713758853 | 0.00261131 | 0.103995 | 1.36013e+07 |
| 4 | movie | 117 | 0.00328744 | 0.0156224 | 3216050557 | 0.00490039 | 0.0378693 | 2.74876e+07 |
| 14 | story | 107 | 0.00300646 | 0.0345322 | 2231437526 | 0.00340011 | 0.0776565 | 2.08546e+07 |
| 33 | night | 104 | 0.00292217 | 0.0814555 | 1523917360 | 0.00232204 | 0.127946 | 1.46531e+07 |
| 19 | american | 93 | 0.00261309 | 0.0478505 | 1868854192 | 0.00284763 | 0.0932591 | 2.00952e+07 |
| 117 | girl | 90 | 0.0025288 | 0.151644 | 842771661 | 0.00128416 | 0.26663 | 9.36413e+06 |
| 16 | day | 87 | 0.00244451 | 0.0416971 | 2164198760 | 0.00329766 | 0.0843116 | 2.48758e+07 |
Now let's visualize to compare both and see the hidden trends:
import matplotlib.pyplot as plt
plt.figure(figsize=(20,8))
plt.subplot(1, 2, 1)
word_freq_df_abs = word_freq_df.sort_values('abs_freq', ascending=False).reset_index()
plt.barh(range(20),
list(reversed(word_freq_df_abs['abs_freq'][:20])), color='#288FB7')
for i, word in enumerate(word_freq_df_abs['word'][:20]):
plt.text(word_freq_df_abs['abs_freq'][i], 20-i-1,
s=str(i+1) + '. ' + word + ': ' + str(word_freq_df_abs['abs_freq'][i]),
ha='right', va='center', fontsize=14, color='white', fontweight='bold')
plt.text(0.4, -1.1, s='Number of times the word was used in a movie title; out of 15500 movies.', fontsize=14)
plt.text(0.4, -1.8, s='Data: boxofficemojo.com Apr. 2018. Feedback: @eliasdabbas', fontsize=14)
plt.vlines(range(0, 210, 10), -1, 20, colors='gray', alpha=0.1)
plt.hlines(range(0, 20, 2), 0, 210, colors='gray', alpha=0.1)
plt.yticks([])
plt.xticks([])
plt.title('Words Most Used in Movie Titles', fontsize=22, fontweight='bold')
# =============
plt.subplot(1, 2, 2)
# plt.axis('off')
plt.barh(range(20),
list(reversed(word_freq_df['wtd_freq'][:20])), color='#288FB7')
for i, word in enumerate(word_freq_df['word'][:20]):
plt.text(word_freq_df['wtd_freq'][i], 20-i-1,
s=str(i+1) + '. ' + word + ': ' + '$' + str(round(word_freq_df['wtd_freq'][i] / 1000_000_000, 2)) + 'b',
ha='right', va='center', fontsize=14, color='white', fontweight='bold')
plt.text(0.4, -1.1, s='Alltime boxoffice revenue of all movies whos title contained the word. (Top word is "2") ', fontsize=14)
plt.text(0.4, -1.8, s='Data collection & methodology: http://bit.ly/word_freq', fontsize=14)
plt.vlines(range(0, 9_500_000_000, 500_000_000), -1, 20, colors='gray', alpha=0.1)
plt.hlines(range(0, 20, 2), 0, 10_000_000_000, colors='gray', alpha=0.1)
plt.xlim((-70_000_000, 9_500_000_000))
plt.yticks([])
plt.xticks([])
plt.title('Words Most Associated With Boxoffice Revenue', fontsize=22, fontweight='bold')
plt.tight_layout(pad=0.01)
plt.show()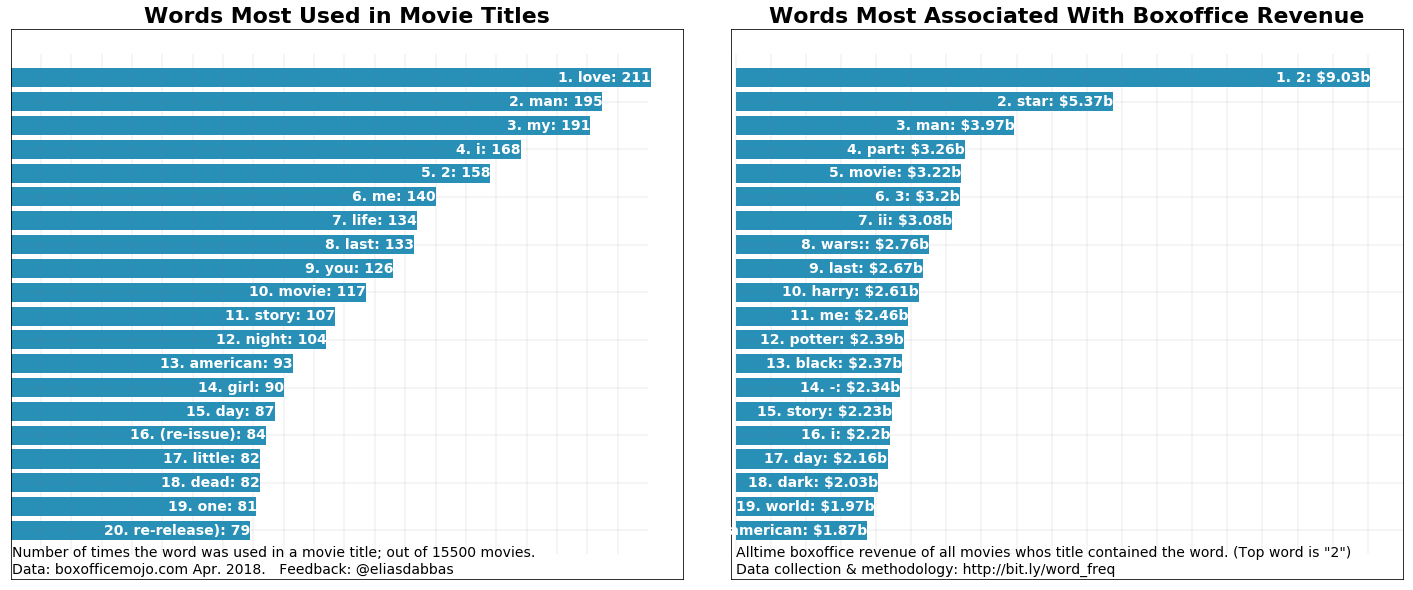
It seems that in the minds of producers and writers at least, love does conquer all! It is the most used word in all of the movie titles. It is not that high when it comes to weighted frequency (box-office revenue), though.
In other words, if you look at all the titles of movies, the word 'love' would be the one you would most find. But estimating which word appeared the most in the eyes of the viewers (using gross revenue as a metric), then '2', 'star', and 'man' would be the most viewed, or associated with the most revenue.
Just to be clear: these are very simple calculations. When you say that the weighted frequency of the word 'love' is 1,604,106,767, it simply means that the sum of the lifetime gross of all movies who's title included the word 'love' was that amount.
It's also interesting that '2' is the top word. Obviously, it is not a word, but it's an indication that the second parts of movie series amount to a very large sum. So is '3', which is in the fifth position. Note that 'part' and 'ii' are also in the top ten, confirming the same fact.
'American', and 'movie', have high relative value.
A quick note on the stop words used in this function
Usually, you would supply a more comprehensive list of stop words than the one here, especially if you are dealing with articles, or social media posts. For example the nltk package provides lists of stop words in several languages, and these can be downloaded and used.
The words here were chosen after a few checks on the top movies. Many of these are usually considered stop words, but in the case of movie titles, it made sense to keep some of them as they might give some insight. For example, the words 'I', 'me', 'you' might hint at some social dynamics. Another reason is that movie titles are very short phrases, and we are trying to make as much sense as we can from them.
You can definitely try it with your own set of words, and see slightly different results.
Looking back at the original list of movie titles, we see that some of the top words don't even appear in the top ten, and this is exactly the kind of insight that we are trying to uncover by using this approach.
boxoffice_df.head(10)
| lifetime_gross | rank | studio | title | year | |
|---|---|---|---|---|---|
| 0 | 936662225 | 1 | BV | Star Wars: The Force Awakens | 2015 |
| 1 | 760507625 | 2 | Fox | Avatar | 2009 |
| 2 | 681084109 | 3 | BV | Black Panther | 2018 |
| 3 | 659363944 | 4 | Par. | Titanic | 1997 |
| 4 | 652270625 | 5 | Uni. | Jurassic World | 2015 |
| 5 | 623357910 | 6 | BV | Marvel's The Avengers | 2012 |
| 6 | 620181382 | 7 | BV | Star Wars: The Last Jedi | 2017 |
| 7 | 534858444 | 8 | WB | The Dark Knight | 2008 |
| 8 | 532177324 | 9 | BV | Rogue One: A Star Wars Story | 2016 |
| 9 | 504014165 | 10 | BV | Beauty and the Beast (2017) | 2017 |
Next, I think it would make sense to further explore the top words that are interesting. Let's filter the movies that contain '2' and see:
(boxoffice_df[boxoffice_df['title']
.str
.contains('2 | 2', case=False)] # spaces used to exclude words like '2010'
.head(10))
| lifetime_gross | rank | studio | title | year | |
|---|---|---|---|---|---|
| 15 | 441226247 | 16 | DW | Shrek 2 | 2004 |
| 30 | 389813101 | 31 | BV | Guardians of the Galaxy Vol. 2 | 2017 |
| 31 | 381011219 | 32 | WB | Harry Potter and the Deathly Hallows Part 2 | 2011 |
| 35 | 373585825 | 36 | Sony | Spider-Man 2 | 2004 |
| 38 | 368061265 | 39 | Uni. | Despicable Me 2 | 2013 |
| 64 | 312433331 | 65 | Par. | Iron Man 2 | 2010 |
| 79 | 292324737 | 80 | LG/S | The Twilight Saga: Breaking Dawn Part 2 | 2012 |
| 87 | 281723902 | 88 | LGF | The Hunger Games: Mockingjay - Part 2 | 2015 |
| 117 | 245852179 | 118 | BV | Toy Story 2 | 1999 |
| 146 | 226164286 | 147 | NL | Rush Hour 2 | 2001 |
Let's also take a peek at the top 'star' movies:
boxoffice_df[boxoffice_df['title'].str.contains('star | star', case=False)].head(10)
| lifetime_gross | rank | studio | title | year | |
|---|---|---|---|---|---|
| 0 | 936662225 | 1 | BV | Star Wars: The Force Awakens | 2015 |
| 6 | 620181382 | 7 | BV | Star Wars: The Last Jedi | 2017 |
| 8 | 532177324 | 9 | BV | Rogue One: A Star Wars Story | 2016 |
| 11 | 474544677 | 12 | Fox | Star Wars: Episode I - The Phantom Menace | 1999 |
| 12 | 460998007 | 13 | Fox | Star Wars | 1977 |
| 33 | 380270577 | 34 | Fox | Star Wars: Episode III - Revenge of the Sith | 2005 |
| 65 | 310676740 | 66 | Fox | Star Wars: Episode II - Attack of the Clones | 2002 |
| 105 | 257730019 | 106 | Par. | Star Trek | 2009 |
| 140 | 228778661 | 141 | Par. | Star Trek Into Darkness | 2013 |
| 301 | 158848340 | 302 | Par. | Star Trek Beyond | 2016 |
And, lastly, the top 'man' movies:
boxoffice_df[boxoffice_df['title'].str.contains('man | man', case=False)].head(10)
| lifetime_gross | rank | studio | title | year | |
|---|---|---|---|---|---|
| 18 | 423315812 | 19 | BV | Pirates of the Caribbean: Dead Man's Chest | 2006 |
| 22 | 409013994 | 23 | BV | Iron Man 3 | 2013 |
| 35 | 373585825 | 36 | Sony | Spider-Man 2 | 2004 |
| 48 | 336530303 | 49 | Sony | Spider-Man 3 | 2007 |
| 53 | 330360194 | 54 | WB | Batman v Superman: Dawn of Justice | 2016 |
| 59 | 318412101 | 60 | Par. | Iron Man | 2008 |
| 64 | 312433331 | 65 | Par. | Iron Man 2 | 2010 |
| 82 | 291045518 | 83 | WB | Man of Steel | 2013 |
| 176 | 206852432 | 177 | WB | Batman Begins | 2005 |
| 182 | 202853933 | 183 | Sony | The Amazing Spider-Man 2 | 2014 |
As a first step, you might try to get more words: movie titles are extremely short and many times don't convey the literal meaning of the words. For example, a godfather is supposed to be a person who whitnesses a child's christening, and promises to take care of that child (or maybe a mafioso who kills for pleasure?!).
A further exercise might be to get more detailed descriptions, in addition to the movie title. For example:
"A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers."
tells us much more about the movie, than 'The Matrix'.
Alternatively, you could also take one of the below paths to enrich your analysis:
You might be interested in exploring the data yourself as well as other data:
Ok, so now you have explored the counts of words in movie titles, and seen the difference between the absolute and weighted frequencies, and how letting one out might miss a big part of the picture. You have also seen the limitations of this approach, and have some suggestions on how to improve your analysis.
You went through the process of creating a special function that you can run easily to analyze any similar text data set with numbers, and know how this can improve your understanding of this kind of data set.
Try it out by analyzing your tweets' performance, your website's URLs, your Facebook posts, or any other similar data set you might come across.
It might be easier to just clone the repository with the code and try for yourself.
The word_frequency function is part of the advertools package, which you can download and try using in your work / research.
Check it out and let me know! @eliasdabbas
Take a look at DataCamp's Python Dictionaries Tutorial to learn how to create word frequency, and Web Scraping & NLP in Python tutorial to learn how to plot word frequency distributions.
Learn more about Python
Course
Course
Course
Tutorial
Aditya Sharma
Tutorial
DataCamp Team
Tutorial
Duong Vu
Tutorial
Hugo Bowne-Anderson
Tutorial
Avinash Navlani
Tutorial
Kurtis Pykes