
Course
Building AI Agents with Google ADK
1 hr
6.5K
In the world of AI, the Model Context Protocol (MCP) has quickly become a hot topic. MCP is an open standard that gives AI models like Claude 4 a consistent way to connect with external tools, services, and real-time data sources. This connectivity is a game-changer as it allows large language models (LLMs) to deliver more relevant, up-to-date, and actionable responses by bridging the gap between AI and the systems.
In this tutorial, we will dive into FastMCP 2.0, a powerful framework that makes it easy to build our own MCP server with just a few lines of code. We will learn about the core components of FastMCP, how to build both an MCP server and client, and how to integrate them seamlessly into your workflow. If you’re new to MCP, check out our Model Context Protocol Guide with Demo Project to learn more.
FastMCP 2.0 is an open-source Python framework designed to make building Model Context Protocol (MCP) servers and clients both simple and efficient. With just a few lines of code, developers can create custom MCP servers and connect them to their AI applications, such as code editors or chatbot assistants.
FastMCP 2.0 is the successor to FastMCP 1.0, which is now known as MCP Python SDK, and it offers a complete toolkit for working within the MCP ecosystem.
What sets FastMCP 2.0 apart is its comprehensive feature set that goes well beyond the core MCP specification. It streamlines deployment, authentication, client and server proxying, and even allows for generating servers from REST APIs.
FastMCP 2.0 is built around three essential components: Tools, Resources, and Prompts.
Tools are Python functions exposed to LLMs via the MCP protocol. By decorating a function with @mcp.tool, you allow the AI model to call it during a conversation. This enables LLMs to perform real-world actions, such as querying databases, calling APIs, or running calculations.
from fastmcp import FastMCPmcp = FastMCP(name="UtilityServer")@mcp.tooldef convert_usd_to_eur(amount: float, rate: float = 0.91) -> float: """Converts a given amount in USD to EUR using the provided rate.""" return round(amount * rate, 2)Resources provide LLMs or client applications with read-only access to data, such as files, database records, configurations, or dynamically generated content. For example:
from fastmcp import FastMCPmcp = FastMCP(name="WeatherResourceServer")@mcp.resource("config://weather-settings")def get_weather_settings() -> dict: """Provides weather configuration.""" return { "default_units": "metric", "default_location": "Berlin", "features_enabled": ["forecast", "alerts"] }@mcp.resource("resource://welcome-message")def welcome_message() -> str: """Returns a dynamic greeting for users based on time of day.""" from datetime import datetime hour = datetime.now().hour if hour < 12: return "Good morning! Here's your weather update." elif hour < 18: return "Good afternoon! Need a forecast?" else: return "Good evening! Let's check the weather."Prompts are reusable, parameterized message templates that guide LLM responses. By defining prompts as functions, you ensure consistent, context-rich instructions that can be invoked by clients.
These are necessary for executing multiple tools in sequence and guiding the LLM to perform certain tasks using the available tools and resources.
from fastmcp import FastMCPfrom fastmcp.prompts.prompt import PromptMessage, TextContentmcp = FastMCP(name="TutorPromptServer")@mcp.promptdef explain_math_concept(concept: str) -> PromptMessage: """Creates a message asking an AI tutor to explain a math concept simply.""" text = f"Can you explain the math concept of '{concept}' in a way that's easy for a 12-year-old to understand?" return PromptMessage(role="user", content=TextContent(type="text", text=text))In this section, we will build an "ArXiv Explorer" MCP server. This server will consist of two tools: one for extracting the links and titles of research papers, and the second for summarizing the research papers. In addition to these tools, the server will also include resources and prompts to help create a comprehensive report on the chosen topic.
Before you begin, you will need to get the Tavily API key. You can get a free key with 1,000 monthly requests at tavily.com. Then, install the necessary Python libraries:
pip install fastmcp tavily-pythonWe will first create the server Python file. The file consists of:
@mcp.resource decorator exposes our arxiv_topics function as a read-only data source. An AI client can fetch these topics to get ideas for what to research, if the user is not sure.@mcp.tool decorator turns regular Python functions into actions an LLM can execute.qna_search, which is optimized to provide direct, concise answers, perfect for generating a summary.@mcp.prompt decorator creates a reusable template. This isn't just a simple prompt; it's a strategic plan that instructs an LLM on how to use the server's tools in a sequence to perform a complex task.mcp.run(transport="http") is a critical line. Instead of using “stdio” for local processes, this starts a web server. This allows any client on the network (or on the same machine) to connect to our server via a URL, making it a truly remote and shareable tool.server.py:
import osfrom typing import Dict, Listfrom fastmcp import FastMCPfrom tavily import TavilyClient# --- Configuration ---TAVILY_API_KEY = os.environ.get("TAVILY_API_KEY")if not TAVILY_API_KEY: raise ValueError("Please set the TAVILY_API_KEY environment variable.")tavily = TavilyClient(api_key=TAVILY_API_KEY)mcp = FastMCP(name="ArxivExplorer")print("✅ ArxivExplorer server initialized.")# --- Dynamic Resource: Suggested AI research topics ---@mcp.resource("resource://ai/arxiv_topics")def arxiv_topics() -> List[str]: return [ "Transformer interpretability", "Efficient large-scale model training", "Federated learning privacy", "Neural network pruning", ]print("✅ Resource 'resource://ai/arxiv_topics' registered.")# --- Tool: Search ArXiv for recent papers ---@mcp.tool(annotations={"title": "Search Arxiv"})def search_arxiv(query: str, max_results: int = 5) -> List[Dict]: """ Queries ArXiv via Tavily, returning title + link for each paper, and *only* ArXiv results. """ resp = tavily.search( query=f"site:arxiv.org {query}", max_results=max_results ) return [ {"title": r["title"].strip(), "url": r["url"]} for r in resp.get("results", []) ]# --- Tool: Summarize an ArXiv paper ---@mcp.tool(annotations={"title": "Summarize Paper"})def summarize_paper(paper_url: str) -> str: """ Returns a one-paragraph summary of the paper at the given URL. """ prompt = f"Summarize the key contributions of this ArXiv paper: {paper_url}" return tavily.qna_search(query=prompt)print("✅ Tools 'Search Arxiv' and 'Summarize Paper' registered.")# --- Prompt Template: Explore a topic thoroughly ---@mcp.promptdef explore_topic_prompt(topic: str) -> str: return ( f"I want to explore recent work on '{topic}'.\n" f"1. Call the 'Search Arxiv' tool to find the 5 most recent papers.\n" f"2. For each paper URL, call 'Summarize Paper' to extract its key contributions.\n" f"3. Combine all summaries into an overview report." )print("✅ Prompt 'explore_topic_prompt' registered.")if __name__ == "__main__": print("\n🚀 Starting ArxivExplorer Server...") mcp.run(transport="http")We need to test the MCP server features and endpoints before integrating it into the AI application. For this, FastMCP has provided a simple API to connect the MCP server and test all its functions.
The client file consists of:
StreamableHttpTransport is specifically designed to connect to a FastMCP server running in HTTP mode.arxiv_topics resource and correctly parses the result.search_arxiv tool and uses the helper function to unwrap the list of papers.summarize_paper tool.explore_topic_prompt, showing the final, ready-to-use instructions that would be sent to an LLM.client.py:
import astimport asyncioimport pprintfrom fastmcp import Clientfrom fastmcp.client.transports import StreamableHttpTransport# --- Configuration ---SERVER_URL = "http://localhost:8000/mcp" # adjust if hosted elsewherepp = pprint.PrettyPrinter(indent=2, width=100)def unwrap_tool_result(resp): """ Safely unwraps the content from a FastMCP tool call result object. """ if hasattr(resp, "content") and resp.content: # The content is a list containing a single content object content_object = resp.content[0] # It could be JSON or plain text if hasattr(content_object, "json"): return content_object.json if hasattr(content_object, "text"): try: # Use ast.literal_eval for safely evaluating a string containing a Python literal return ast.literal_eval(content_object.text) except (ValueError, SyntaxError): # If it's not a literal, return the raw text return content_object.text return respasync def main(): transport = StreamableHttpTransport(url=SERVER_URL) client = Client(transport) print("\n🚀 Connecting to FastMCP server at:", SERVER_URL) async with client: # 1. Ping to test connectivity print("\n🔗 Testing server connectivity...") await client.ping() print("✅ Server is reachable!\n") # 2. Discover server capabilities print("🛠️ Available tools:") pp.pprint(await client.list_tools()) print("\n📚 Available resources:") pp.pprint(await client.list_resources()) print("\n💬 Available prompts:") pp.pprint(await client.list_prompts()) # 3. Fetch the topics resource print("\n\n📖 Fetching resource: resource://ai/arxiv_topics") res = await client.read_resource("resource://ai/arxiv_topics") topics = ast.literal_eval(res[0].text) print("Today's AI topics:") for i, t in enumerate(topics, 1): print(f" {i}. {t}") # 4. Test the search tool print("\n\n🔍 Testing tool: search_arxiv") raw_search = await client.call_tool( "search_arxiv", {"query": "Transformer interpretability", "max_results": 3}, ) search_results = unwrap_tool_result(raw_search) for i, paper in enumerate(search_results, 1): print(f" {i}. {paper['title']}\n {paper['url']}") # 5. Test the summarize tool on the first result if search_results: first_url = search_results[0]["url"] print("\n\n📝 Testing tool: summarize_paper") raw_summary = await client.call_tool( "summarize_paper", {"paper_url": first_url} ) summary = unwrap_tool_result(raw_summary) print("\nSummary of first paper:\n", summary) # 6. Test the prompt generator print("\n\n🚀 Testing prompt: explore_topic_prompt") prompt_resp = await client.get_prompt( "explore_topic_prompt", {"topic": "Transformer interpretability"} ) print("\nGenerated prompt for an LLM:") for msg in prompt_resp.messages: print(f"{msg.role.upper()}: {msg.content.text}\n")if __name__ == "__main__": asyncio.run(main())All the files and configurations are available at kingabzpro/FastMCP-Project GitHub repository. You can use it if you are facing any issues. I also included the setup guide to run it locally.
We will now run both the MCP server and client.
First, set the Tavily API key as an environment variable on your local system:
export TAVILY_API_KEY='your_tavily_api_key'Next, run the server:
python server.pyWithin seconds, you will see that the FastMCP server is running at http://localhost:8000/mcp.
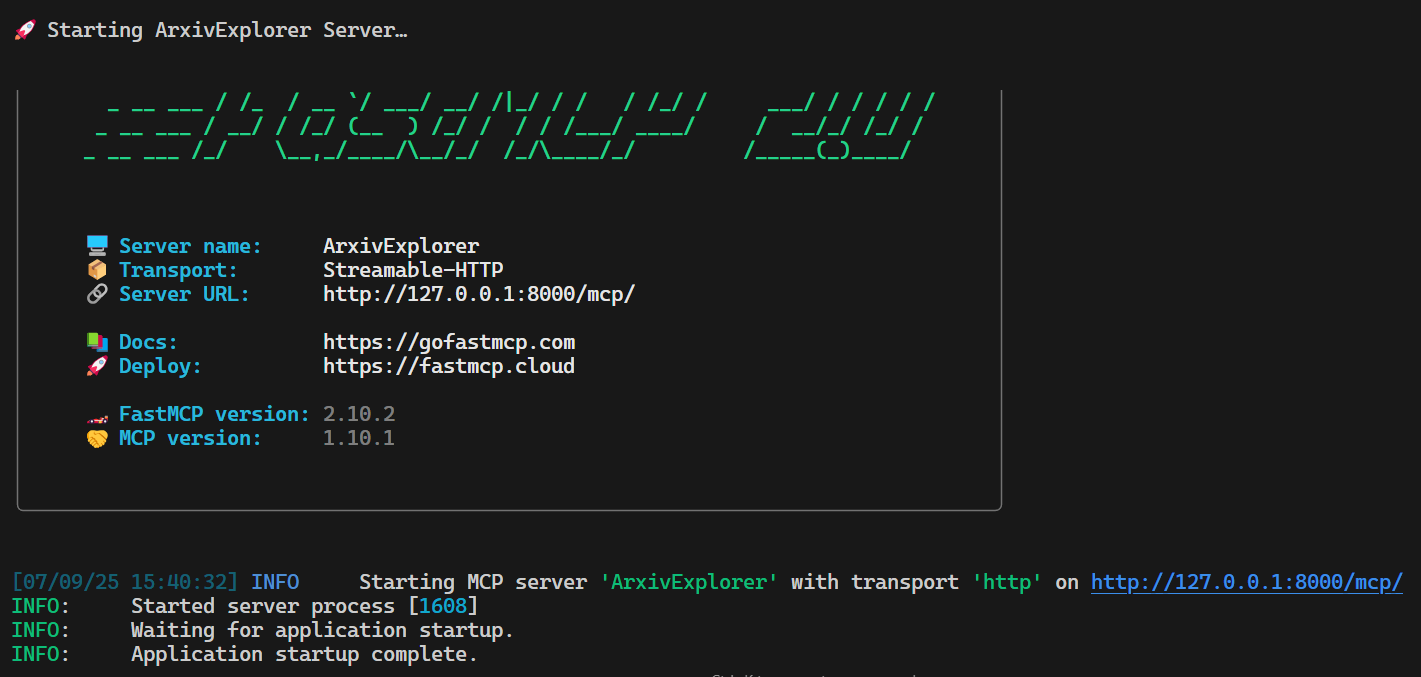
Open a new terminal and run the client script to test if everything is working properly:
python client.pyAs we can see, all the functions, resources, tools, and prompts are working perfectly. Our MCP server is performing well, even with multiple Tavily API requests.
🚀 Connecting to FastMCP server at: http://localhost:8000/mcp🔗 Testing server connectivity...✅ Server is reachable!🛠️ Available tools:[ Tool(name='search_arxiv', title='Search Arxiv', description='Queries ArXiv via Tavily, returning title + link for each paper,\nand *only* ArXiv results.', inputSchema={'properties': {'query': {'title': 'Query', 'type': 'string'}, 'max_results': {'default': 5, 'title': 'Max Results', 'type': 'integer'}}, 'required': ['query'], 'type': 'object'}, outputSchema={'properties': {'result': {'items': {'additionalProperties': True, 'type': 'object'}, 'title': 'Result', 'type': 'array'}}, 'required': ['result'], 'title': '_WrappedResult', 'type': 'object', 'x-fastmcp-wrap-result': True}, annotations=ToolAnnotations(title='Search Arxiv', readOnlyHint=None, destructiveHint=None, idempotentHint=None, openWorldHint=None), meta=None), Tool(name='summarize_paper', title='Summarize Paper', description='Returns a one-paragraph summary of the paper at the given URL.', inputSchema={'properties': {'paper_url': {'title': 'Paper Url', 'type': 'string'}}, 'required': ['paper_url'], 'type': 'object'}, outputSchema={'properties': {'result': {'title': 'Result', 'type': 'string'}}, 'required': ['result'], 'title': '_WrappedResult', 'type': 'object', 'x-fastmcp-wrap-result': True}, annotations=ToolAnnotations(title='Summarize Paper', readOnlyHint=None, destructiveHint=None, idempotentHint=None, openWorldHint=None), meta=None)]📚 Available resources:[ Resource(name='arxiv_topics', title=None, uri=AnyUrl('resource://ai/arxiv_topics'), description=None, mimeType='text/plain', size=None, annotations=None, meta=None)]💬 Available prompts:[ Prompt(name='explore_topic_prompt', title=None, description=None, arguments=[PromptArgument(name='topic', description=None, required=True)], meta=None)]📖 Fetching resource: resource://ai/arxiv_topicsToday's AI topics: 1. Transformer interpretability 2. Efficient large-scale model training 3. Federated learning privacy 4. Neural network pruning🔍 Testing tool: search_arxiv 1. Transformer Interpretability Beyond Attention Visualization https://arxiv.org/abs/2012.09838 2. A Practical Review of Mechanistic Interpretability for ... https://arxiv.org/abs/2407.02646 3. Mechanistic Interpretability of Fine-Tuned Vision ... https://arxiv.org/abs/2503.18762📝 Testing tool: summarize_paperSummary of first paper: The paper proposes a novel method for interpreting Transformer networks beyond attention visualization, introducing a new way to compute relevancy. It aims to enhance interpretability in vision tasks. The method is shown to provide more accurate insights into model decisions.🚀 Testing prompt: explore_topic_promptGenerated prompt:USER: type='text' text="I want to explore recent work on 'Transformer interpretability'.\n1. Call the 'Search Arxiv' tool to find the 5 most recent papers.\n2. For each paper URL, call 'Summarize Paper' to extract its key contributions.\n3. Combine all summaries into an overview report." annotations=None meta=NoneKeep the MCP server running, as we are about to integrate it into the Cursor AI code editor.
{ "mcpServers": { "ArxivExplorer": { "url": "http://127.0.0.1:8000/mcp/" } }}Once you save the mcp.json file with the above configurations, you will see the new MCP server listed in the “Tools & Integrations” section, which will display two tools as shown below.
Now comes the fun part. Let’s see how our MCP server performs with the Cursor AI code editor. We will learn how to use prompts to invoke tools, access resources, and execute custom prompts, all within the code editor.
Start by checking if your MCP server can provide useful data through its resources.
Prompt: “what are the some popular arxiv topics”
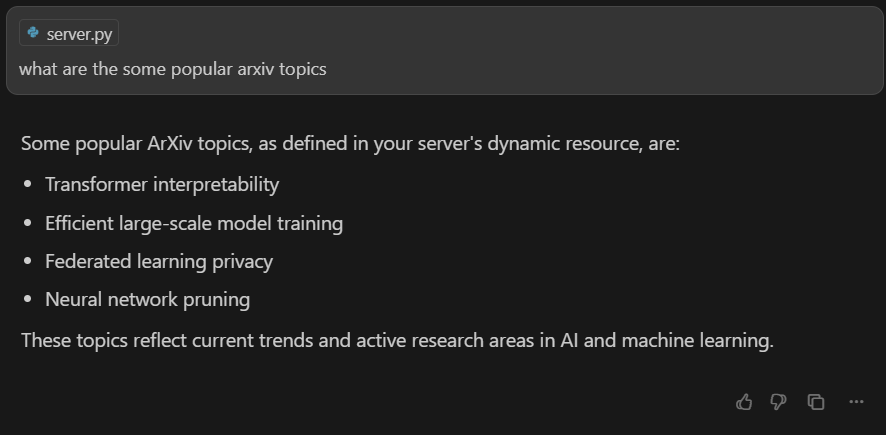
If everything is set up correctly, the AI model will understand your request and automatically retrieve the list of topics from your MCP server’s resource endpoint.
Next, let’s try out the tools you’ve exposed via MCP. We will first test the search_arxiv tool by asking the AI model to list the top ten research papers on large language models.
Prompt: “Please search for the top 10 research papers on large language models.”
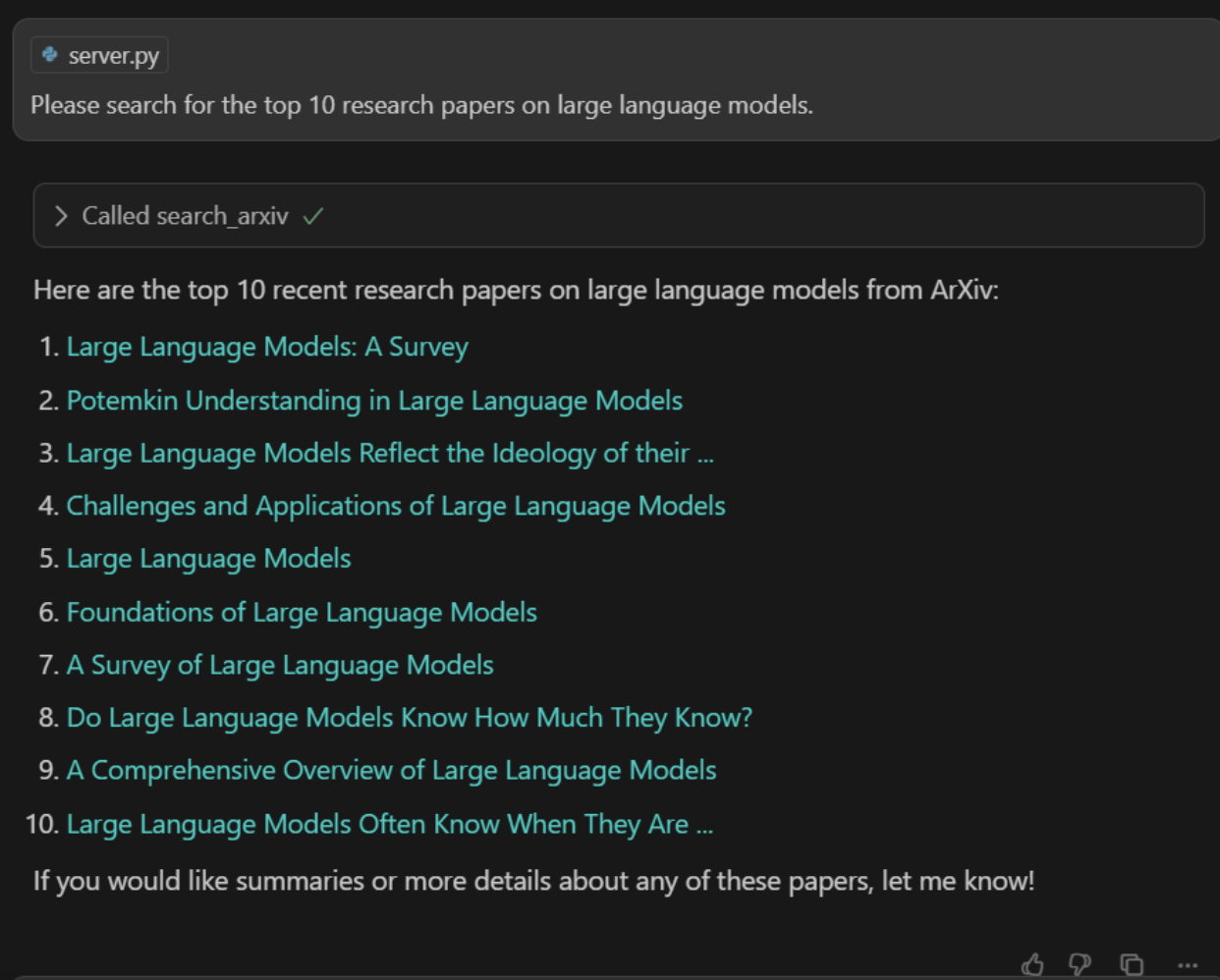
The AI will call the search_arxiv tool, and you should see a fast, accurate list of relevant papers, pulled directly from arXiv.
Next, we will test the summarizer tool that takes the research paper URL and returns a summary of the report.
Prompt: “Please summarize the following paper for me: https://arxiv.org/abs/2402.06196”
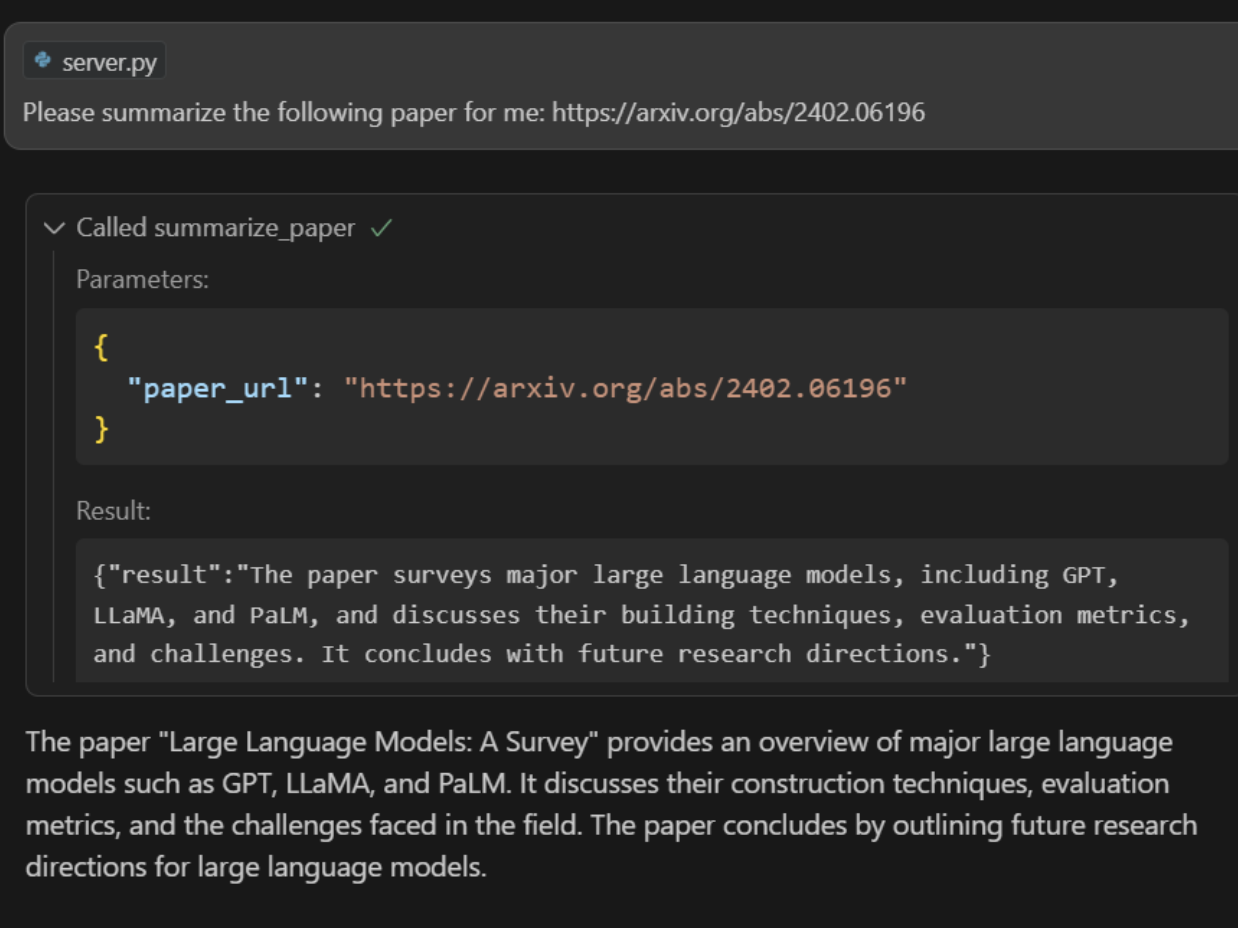
The summarizer tool will fetch the paper and return a concise summary.
We will now invoke a custom prompt from the MCP that will help us generate a report.
Prompt: “Create a report on Quantum computing using the latest work.”
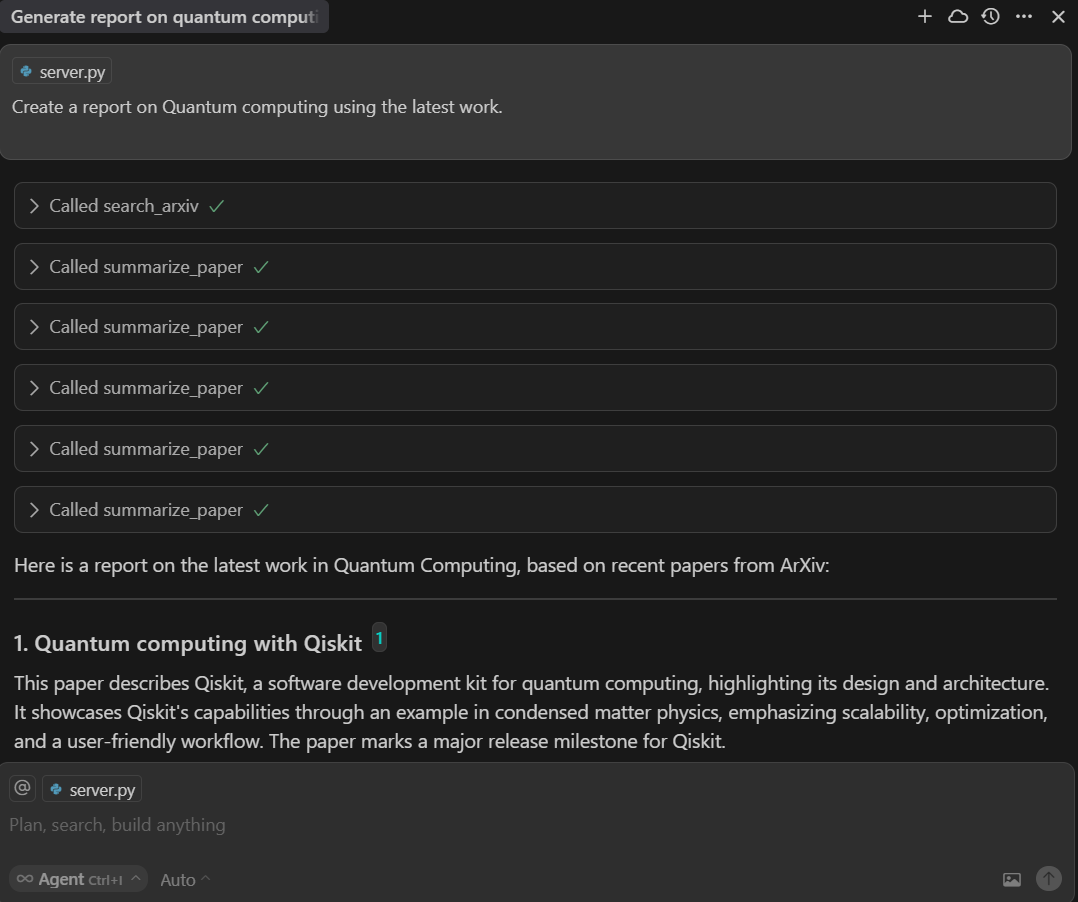
If you examine the server code, you will see that the AI model understands the task and uses the explore_topic_prompt function.
@mcp.promptdef explore_topic_prompt(topic: str) -> str: return ( f"I want to explore recent work on '{topic}'.\n" f"1. Call the 'Search Arxiv' tool to find the 5 most recent papers.\n" f"2. For each paper URL, call 'Summarize Paper' to extract its key contributions.\n" f"3. Combine all summaries into an overview report." )First, it will call the 'Search Arxiv' tool to find links to the papers.
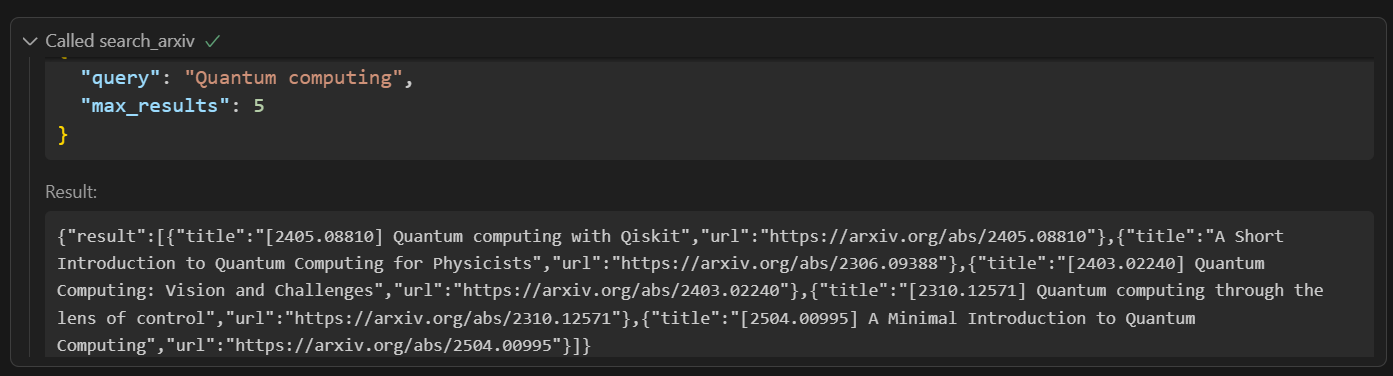
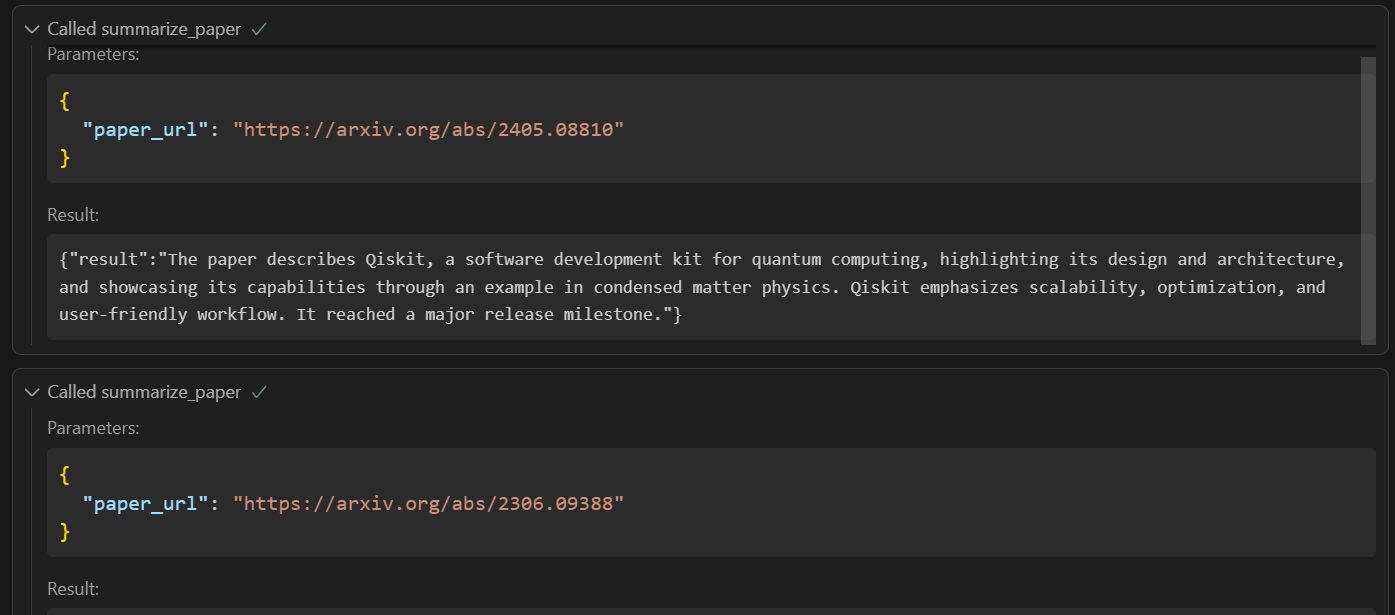
Then, it will provide the links to the 'Summarize Paper' tool one by one to generate the summaries. Finally, I will create the report.
FastMCP 2.0 offers far more than just a simple way to create MCP servers. It provides a robust framework for building secure, modular, and scalable AI integrations. With features like authentication, advanced proxying (allowing one FastMCP server to act as a frontend for another), and the ability to combine multiple FastMCP servers into a single application using mounting and importing, you can architect complex, maintainable systems with ease.
Middleware support lets you add cross-cutting functionality, such as logging or request modification, across all MCP requests and responses. You can also send log messages and progress updates back to clients through the MCP context, making it easy to monitor and manage long-running operations.
In this tutorial, we have learned how to build a fully functional MCP server and test its features. These tools and the MCP protocol are becoming essential components of modern AI applications, enabling LLMs to perform more advanced tasks and automate workflows more effectively.
To keep learning about MCP Servers, be sure to check out our other resources:
Top DataCamp Courses
Course
Course
Course
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
6 min
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Aryan Irani
Tutorial
Nikhil Adithyan

